# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
全球AIGC应用浪潮下,怎样将大模型产品以一种更贴近消费者的形式融入生产力工具?
这,或许是AI在生产力场景延伸过程中,入场玩家们所要思考的一个重要问题。
中国AIGC产业峰会上,美图公司创始人、董事长兼CEO吴欣鸿从美图视频大模型的探索之路出发,讲述了美图在图像、视频和设计领域深耕16年而获得的经验与感悟以及对未来的预判。

为了完整体现吴欣鸿的思考,在不改变原意的基础上,量子位对演讲内容进行了编辑整理,希望能给你带来更多启发。
中国AIGC产业峰会是由量子位主办的行业峰会,20位产业代表与会讨论。线下参会观众近千人,线上直播观众300万,获得了主流媒体的广泛关注与报道。
以下为吴欣鸿演讲全文:
一眨眼,美图已成立16年。最早,我们做影像工具,像美图秀秀。此外很长一段时间,美图也探索了不同业务,踩了很多坑。
从2021年开始,我们基于订阅的商业模式,取得了非常好的经营状态,并重新聚焦于影像和设计产品。现在,我们已经从过去的工具自卑转变成越来越有信心。
我们正逐步往生产力场景延伸,从最初的拍摄、修图、修视频、社交分享到现在新增的视觉创作、专业摄影、专业视频编辑、商业设计等等。
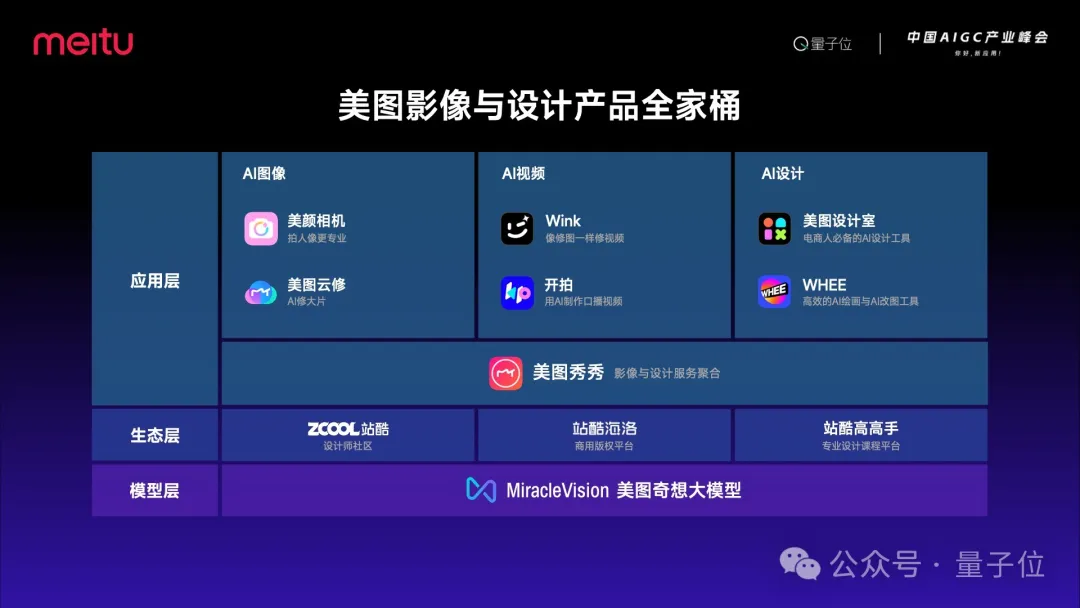
美图现在拥有了影像与设计产品全家桶。产品主要分为AI图像、视频和设计三个大类。
同时,在生态层,美图今年初收购了站酷,为我们提供了优秀的设计师共创、商用版权销售和专业课程设计等服务。
在模型层,去年6月发布的美图奇想大模型为我们以上产品提供了强大的模型能力支撑。
前两天,我们使用美图生产力全家桶制作了一部短片。我想邀请大家观看这个一分钟的短片。
谢谢大家观看。
我想重点介绍这个60秒的短片是怎么制作出来的。
其实只用半天时间,就能做出同样惊艳的效果。
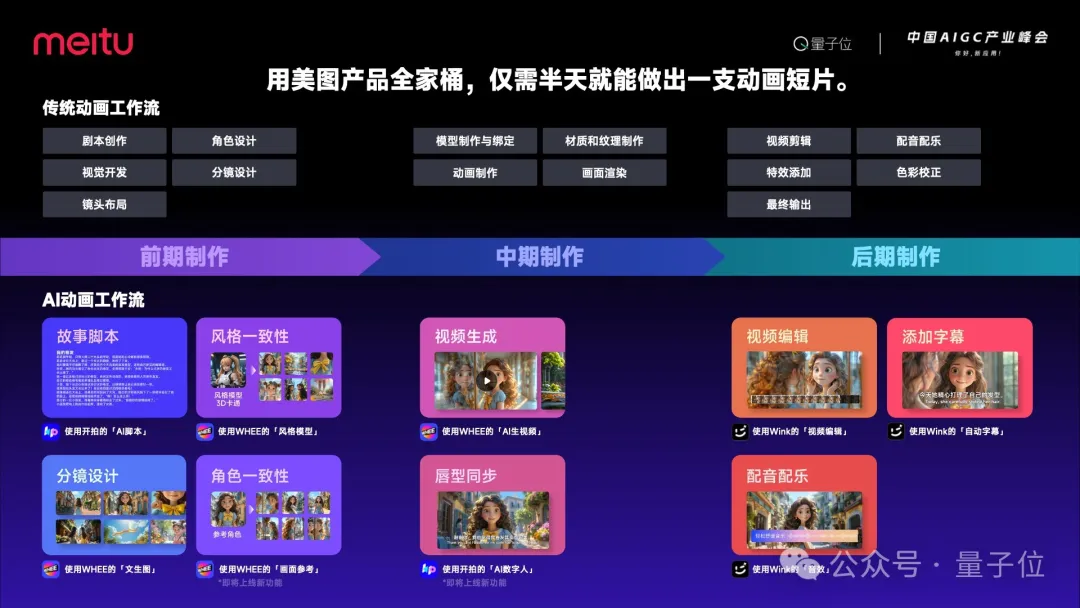
在前期制作中,我们使用了开拍AI脚本以及美图WHEE进行风格和角色的一次性约束,确保短片中人物形象和画面风格的一致性。同时,我们还使用WHEE的文生图进行了关键的分镜设计。
在中期制作阶段,同样是美图WHEE,我们将这些分镜制作成视频化,相当于图生视频。
同时,我们还使用美图开拍的AI数字人进行了输入对话、唇形同步。
在后期制作环节,我们使用了美图的Wink进行视频编辑,并制作了自动字幕和添加音效。
所有这些产品都是由美图奇想大模型驱动的,与AI紧密相关。这展示了AI原生工作流的有益探索,与传统动画工作流相比,效率得到了很大提升,且门槛大幅降低。
去年12月,我们发布了MiracleVision 4.0版本,其中重点是AI视频和AI设计能力。刚才的视频就是使用去年12月的视频大模型生成的。
不过,这和最近我们正在训练的美图视频大模型2.0在能力上还有很大区别,我简要介绍一下进化的方向。
最早,我们采用了U-Net结构,在编码部分也只能进行空间域压缩。Sora发布后,我们发现在架构上有很多可以参考学习的地方,因此我们升级了视频大模型的架构,采用了Transformer结构,另外还实现了时空域同步压缩。
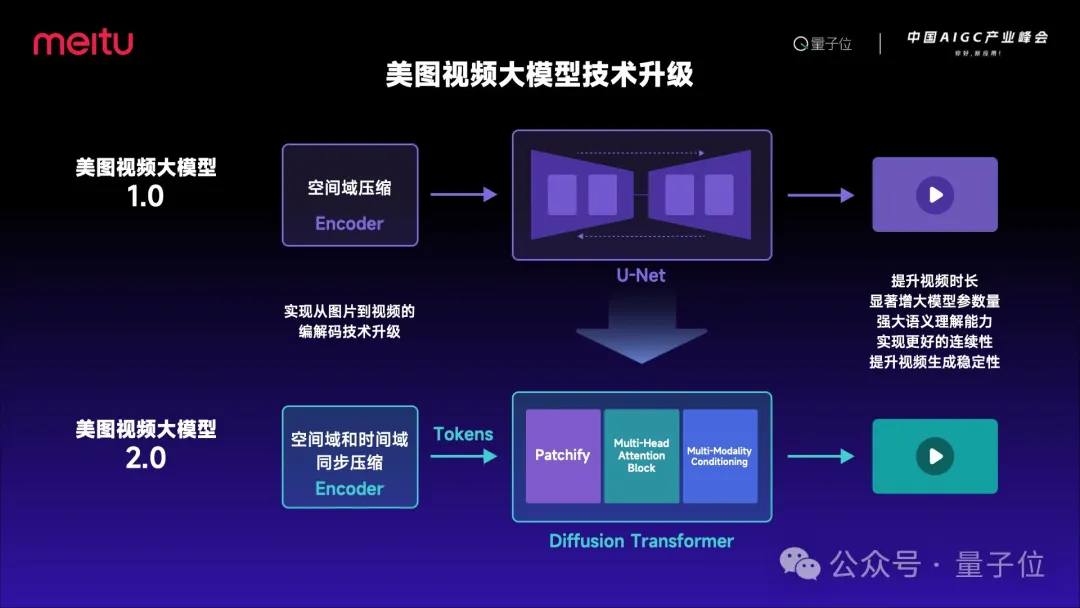
美图视频大模型目前正在从1.0向2.0的跨越,实现全方位的技术升级,模型参数量显著增大,同时将拥有更加强大的语义理解能力,大幅提升视频生成时长、稳定性与内容一致性。
上述的视频大模型2.0将于今年6月美图影像节正式亮相。
我们对未来也有一些预判。现在大家都在追赶Sora,预计今年下半年将会有很多国产Sora扎堆上市。美图的MiracleVision也是其中一家。
我们认为,面对越来越激烈的竞争,有三个点非常关键。
第一,创意超越现实。
众所周知,Sora拥有许多充满创意、奇思妙想的画面,这是实拍很难做到的。同时,如果将这些画面采用传统的视频特效方式制作,成本将非常高昂。
我们认为,视频大模型应与实拍相辅相成,生成一些超越现实的创意画面,成为一种全新的特效制作方式。以前的特效,比如前期做绿幕、后期要做动捕等等,时间长、成本高,而现在AI特效可以做到低成本、低门槛。
第二,工作流的整合。
如果只是单纯拼生成能力,比如文生视频,其实它的应用场景是相对有限的。我们正将美图现有的生产力工具能力进行整合,无论是AI能力还是传统视频技术相结合,形成类似刚才60秒短片的动画制作工作流。
第三,垂直场景的能力。
我们也在探索视频大模型未来能否在电商、广告、游戏、动漫、影视等场景进行深度应用和变现。因此,垂直场景的可用性同样是竞争的关键。
基于垂直创新模型的创新,我们认为有两年左右的窗口期。
在这里,我们对自己业务的要求是,不去做大而全的模型和场景,更关注垂直的图像和视频模型,以及电商、广告等垂直场景。同时,我们也将不断探索AI原生工作流,我们认为它是一种更能降本增效的实现方式。
刚才提到,文生视频将是视频大模型的标配,同时还有更多的视频生成方式,如图生视频、视频生视频、音频生视频等。

我们可以看到,无论是哪种视频生成方式,都将有广阔的应用场景。例如,图生视频,因为美图是从图片工具发展起来的,我们每天会产生两亿多张图片,如何让图片动起来?例如,美颜相机的AI写真就在探索AI视频写真,我认为这是一种更贴近消费者的形式。
视频生视频,我们可以理解为一种全新的视频渲染方式,视频风格化方式。音频生视频,我们现在在探索MV的生成,同样也是一个有趣的领域。同时,开拍的AI主播也可以用音频生成,我们录一段音就可以生成AI主播完整的口播视频。

去年,当然是视频大模型的早期阶段,我们去年12月发布的模型,基本上只能生成3-5秒的视频片段,世界、动作一致性和稳定性都较差。
今年2月,Sora的横空出世,我们看到确实有些对物理世界的理解,包括在创意、特效上有一定涌现的现象,视频的时长也显著提升。
我们也期待在明年,甚至更远的未来,视频大模型能够实现更深度的物理理解,拥有剧情设计、分镜、转场等更专业的能力,能够与视频制作工作流紧密结合。
也希望大家关注6月的美图影像节。除了全新的视频大模型,我们还将有一系列生产力工具全家桶陆续亮相。
今天我就分享到这,谢谢大家!
本文来自微信公众号“量子位”




【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】Fay开源数字人框架是一个AI数字人项目,该项目可以帮你实现“线上线下的数字人销售员”,
“一个人机交互的数字人助理”或者是一个一个可以自主决策、主动联系管理员的智能体数字人。
项目地址:https://github.com/xszyou/Fay
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
