# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
对于烟雾等动态三维物理现象的高效高质量采集重建是相关科学研究中的重要问题,在空气动力学设计验证,气象三维观测等领域有着广泛的应用前景。通过采集重建随时间变化的三维密场度序列,可以帮助科学家更好地理解与验证真实世界中的各类复杂物理现象。

然而,从真实世界中快速获取并高质量重建出动态三维密度场相当困难。首先,三维信息难以通过常见的二维图像传感器(如相机)直接测量。此外,高速变化的动态现象对物理采集能力提出了很高的要求:需要在很短的时间内完成对单个三维密度场的完整采样,否则三维密度场本身将发生变化。这里的根本挑战是如何解决测量样本和动态三维密度场重建结果之间的信息量差距。
当前主流研究工作通过先验知识弥补测量样本信息量不足,计算代价高,且当先验条件不满足时重建质量不佳。与主流研究思路不同,浙江大学计算机辅助设计与图形系统全国重点实验室的研究团队认为解决难题的关键在于提高单位测量样本的信息量。
该研究团队不仅利用 AI 优化重建算法,还通过 AI 帮助设计物理采集方式,实现同一目标驱动的全自动软硬件联合优化,从本质上提高单位测量样本关于目标对象的信息量。通过对真实世界中的物理光学现象进行仿真,让人工智能自己决定如何投射结构光,如何采集对应的图像,以及如何从采样样本中重建出动态三维密度场。最终,研究团队仅使用包含单投影仪和少量相机(1 或者 3 台)的轻量级硬件原型,把建模单个三维密度场(空间分辨率 128x128x128)的结构光图案数量降到 6 张,实现每秒 40 个三维密度场的高效采集。
值得一提的是,团队在重建算法中创新性地提出轻量级一维解码器,将局部入射光作为解码器输入的一部分,在不同相机所拍摄的不同像素下共用了解码器参数,大幅降低网络的复杂程度,提高计算速度。为融合不同相机的解码结果,又设计结构简单的 3D U-Net 聚合网络。最终重建单个三维密度场仅需 9.2ms,相对于 SOTA 研究工作 [2,3],重建速度提升 2-3 个数量级,实现三维密度场的实时高质量重建。相关研究论文《Real-time Acquisition and Reconstruction of Dynamic Volumes with Neural Structured Illumination》已被计算机视觉顶级国际学术会议 CVPR 2024 接收。

根据采集过程中是否控制光照可以把相关工作分为以下两大类。
第一类基于非可控光照的工作不需要专门的光源,在采集过程中不控制光照,因此对采集条件要求较宽松 [2,3]。由于单视角相机拍摄到的是三维结构的二维投影,因此难以高质量区分不同的三维结构。对此,一种思路是增加采集视角采样数,如使用密集相机阵列或光场相机,这会导致高昂的硬件成本。另一种思路仍然在视角域稀疏采样,通过各类先验信息来填补信息量缺口,如启发式先验、物理规则或从现有数据中学习的先验知识。一旦先验条件在实际中不满足,这类方法的重建结果会质量下降。此外,其计算开销过于昂贵,无法支持实时重建。
第二类工作采用可控光照,在采集过程中对光照条件进行主动控制 [4,5]。此类工作对光照进行编码以更主动地探测物理世界,还减少对先验的依赖,从而获得更高的重建质量。根据同时使用单灯还是多灯,相关工作可以进一步分类为扫描方法和光照多路复用方法。对于动态的物理对象,前者必须通过使用昂贵的硬件来达到高扫描速度,或者牺牲结果的完整性来减少采集负担。后者通过同时对多个光源进行编程,显著提高了采集效率。但是对于高质量的快速实时密度场,已有方法的采样效率仍然不足 [5]。
浙大团队的工作属于第二类。和大多数现有工作不同的是,本研究工作利用人工智能来联合优化物理采集(即神经结构光)与计算重建,从而实现高效高质量动态三维密度场建模。
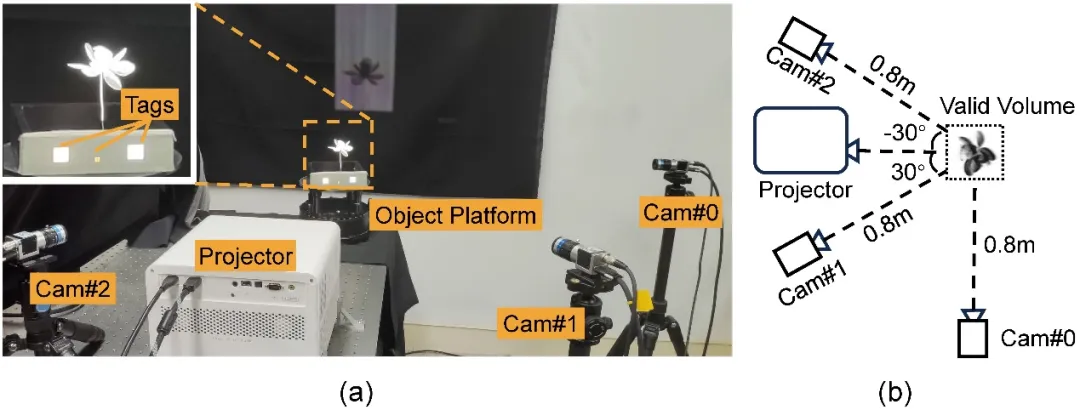
研究团队搭建由单个商用投影仪(BenQ X3000:分辨率 1920×1080, 速度 240fps)和三个工业相机(Basler acA1440-220umQGR:分辨率 1440×1080, 速度 240fps)组成的简单硬件原型(如图 3 所示)。通过投影仪循环投射 6 个预训练得到的结构光图案,三个相机同步进行拍摄,并基于相机采集到的图像进行动态三维密度场重建。四个设备相对于采集对象的角度是由不同仿真实验模拟后所选出的最优排布。
研发团队设计由编码器、解码器和聚合模块组成的深度神经网络。其编码器中的权重直接对应采集期间的结构光照亮度分布。解码器以单像素上测量样本为输入,预测一维密度分布并插值到三维密度场。聚合模块将每个相机所对应解码器预测的多个三维密度场组合成最终的结果。通过使用可训练结构光以及和轻量级一维解码器,本研究更容易学习到结构光图案,二维拍摄照片和三维密度场三者之间的本质联系,不容易过拟合到训练数据中。以下图 4 展示整体流水线,图 5 展示相关网络结构。
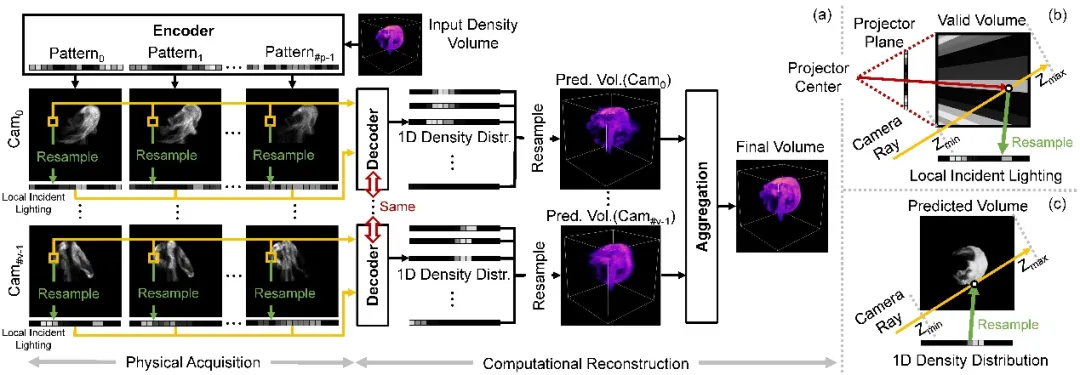
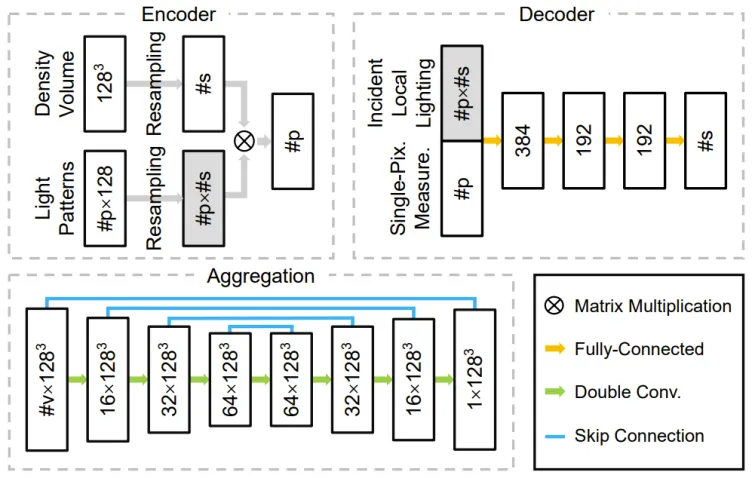
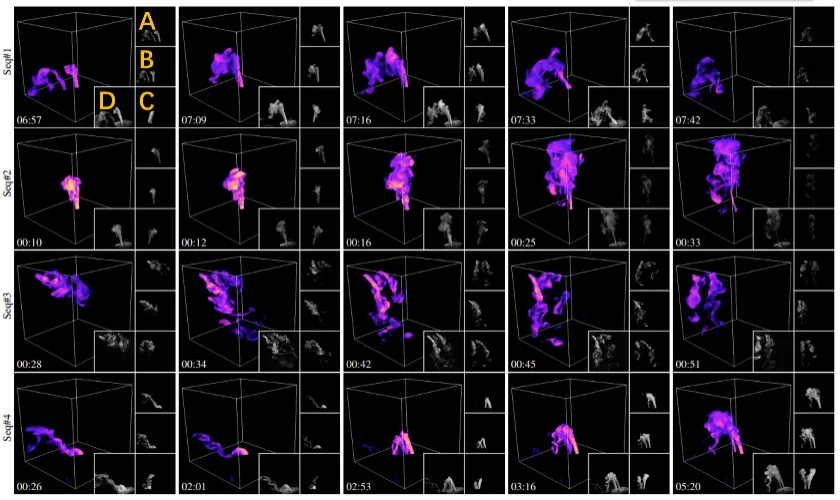
图 6 展示本方法对四个不同动态场景的部分重建结果。为生成动态水雾,研究人员将干冰添加到装有液态水的瓶子中制造水雾,并通过阀门控制流量,并使用橡胶管将其进一步引导至采集装置。
为了验证本研究的正确性和质量,研究团队在真实静态物体上把本方法和相关 SOTA 方法进行对比(如图 7 所示)。图 7 也同时对不同相机数量下的重建质量进行对比。所有重建结果在相同的未采集过的新视角下绘制,并由三个评价指标进行定量评估。由图 7 可知,得益于对采集效率的优化,本方法的重建质量优于 SOTA 方法。

研究团队也在动态仿真数据上对不同方法的重建质量进行定量对比。图 8 展示仿真烟雾序列的重建质量对比。详细的逐帧重建结果请参见论文视频。

研究团队计划在更先进的采集设备(如光场投影仪 [6])上应用本方法开展动态采集重建。团队也期望通过采集更丰富的光学信息(如偏振状态),从而进一步减少采集所需的结构光图案数量和相机数量。除此之外,将本方法与神经表达(如 NeRF)结合也是团队感兴趣的未来发展方向之一。最后,让 AI 更主动地参与对物理采集与计算重建的设计,不局限于后期软件处理,这可能能为进一步提升物理感知能力提供新的思路,最终实现不同复杂物理现象的高效高质量建模。
本文来自微信公众号“机器之心”



