# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
Richard Sutton 在 「The Bitter Lesson」中做过这样的评价:「从70年的人工智能研究中可以得出的最重要教训是,那些利用计算的通用方法最终是最有效的,而且优势巨大。」
自我博弈(self play)就是这样一种同时利用搜索和学习从而充分利用和扩大计算规模的方法。
今年年初,加利福尼亚大学洛杉矶分校(UCLA)的顾全全教授团队提出了一种自我博弈微调方法 (Self-Play Fine-Tuning, SPIN),可不使用额外微调数据,仅靠自我博弈就能大幅提升 LLM 的能力。
最近,顾全全教授团队和卡内基梅隆大学(CMU)Yiming Yang教授团队合作开发了一种名为「自我博弈偏好优化(Self-Play Preference Optimization, SPPO)」的对齐技术,这一新方法旨在通过自我博弈的框架来优化大语言模型的行为,使其更好地符合人类的偏好。左右互搏再显神通!

技术背景与挑战
大语言模型(LLM)正成为人工智能领域的重要推动力,凭借其出色的文本生成和理解能力在种任务中表现卓越。尽管LLM的能力令人瞩目,但要使这些模型的输出行为更符合实际应用中的需求,通常需要通过对齐(alignment)过程进行微调。
这个过程关键在于调整模型以更好地反映人类的偏好和行为准则。常见的方法包括基于人类反馈的强化学习(RLHF)或者直接偏好优化(Direct Preference Optimization,DPO)。
基于人类反馈的强化学习(RLHF)依赖于显式的维护一个奖励模型用来调整和细化大语言模型。换言之,例如,InstructGPT就是基于人类偏好数据先训练一个服从Bradley-Terry模型的奖励函数,然后使用像近似策略优化(Proximal Policy Optimization,PPO)的强化学习算法去优化大语言模型。去年,研究者们提出了直接偏好优化(Direct Preference Optimization,DPO)。
不同于RLHF维护一个显式的奖励模型,DPO算法隐含的服从Bradley-Terry模型,但可以直接用于大语言模型优化。已有工作试图通过多次迭代的使用DPO来进一步微调大模型 (图1)。
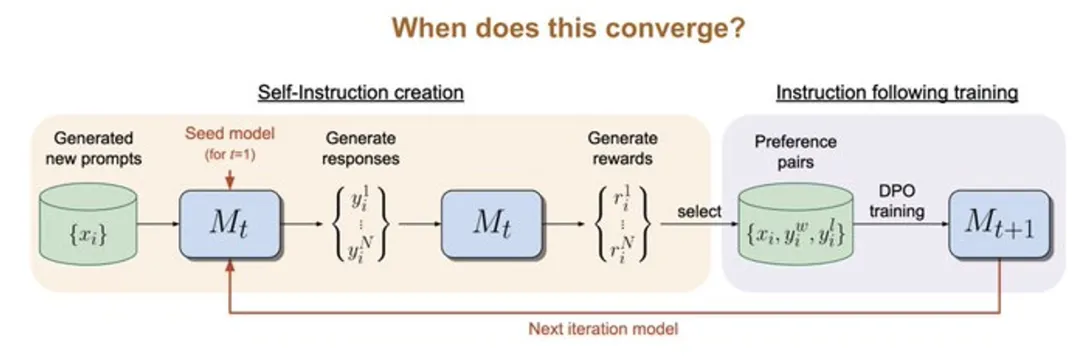
图1.基于Bradley-Terry模型的迭代优化方法缺乏理论理解和保证
如Bradley-Terry这样的参数模型会为每个选择提供一个数值分数。这些模型虽然提供了合理的人类偏好近似,但未能完全捕获人类行为的复杂性。
这些模型往往假设不同选择之间的偏好关系是单调和传递的,而实证证据却常常显示出人类决策的非一致性和非线性,例如Tversky的研究观察到人类决策可能会受到多种因素的影响,并表现出不一致性。
SPPO的理论基础与方法
图2.假想的两个语言模型进行常和博弈。
在这些背景下,作者提出了一个新的自我博弈框架 SPPO,该框架不仅具有解决两玩家常和博弈(two-player constant-sum game)的可证明保证,而且可以扩展到大规模的高效微调大型语言模型。
具体来说,文章将RLHF问题严格定义为一个两玩家常和博弈 (图2)。该工作的目标是识别纳什均衡策略,这种策略在平均意义上始终能提供比其他任何策略更受偏好的回复。
为了近似地识别纳什均衡策略,作者采用了具有乘法权重的经典在线自适应算法作为解决两玩家博弈的高层框架算法。
在该框架的每一步内,算法可以通过自我博弈机制来近似乘法权重更新,其中在每一轮中,大语言模型都在针对上一轮的自身进行微调,通过模型生成的合成数据和偏好模型的注释来进行优化。
具体来说,大语言模型在每一轮回会针对每个提示生成若干回复;依据偏好模型的标注,算法可以估计出每个回复的胜率;算法从而可以进一步微调大语言模型的参数使得那些胜率高的回复拥有更高的出现概率(图3)。

图3.自我博弈算法的目标是微调自身从而胜过上一轮的语言模型
实验设计与成果
在实验中,研究团队采用了一种Mistral-7B作为基线模型,并使用了UltraFeedback数据集的60,000个提示(prompt)进行无监督训练。他们发现,通过自我博弈的方式,模型能够显著提高在多个评估平台上的表现,例如AlpacaEval 2.0和MT-Bench。这些平台广泛用于评估模型生成文本的质量和相关性。
通过SPPO方法,模型不仅在生成文本的流畅性和准确性上得到了改进,更重要的是:「它在符合人类价值和偏好方面表现得更加出色」。
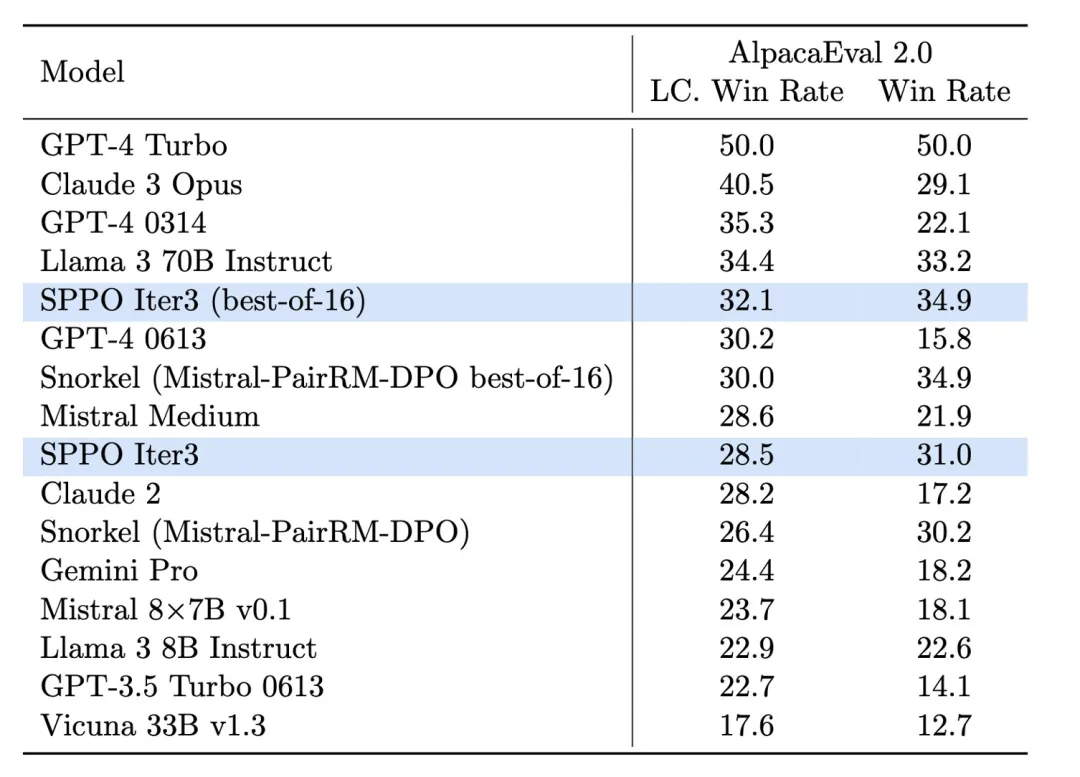
图4.SPPO模型在AlpacaEval 2.0上的效果提升显著,且高于如 Iterative DPO 的其他基准方法。
在AlpacaEval 2.0的测试中(图4),经过SPPO优化的模型在长度控制胜率方面从基线模型的17.11%提升到了28.53%,显示了其对人类偏好理解的显著提高。经过三轮SPPO优化的模型在AlpacaEval2.0上显著优于多轮迭代的DPO, IPO和自我奖励的语言模型(Self-Rewarding LM)。
此外,该模型在MT-Bench上的表现也超过了传统通过人类反馈调优的模型。这证明了SPPO在自动调整模型行为以适应复杂任务方面的有效性。
结论与未来展望
自我博弈偏好优化(SPPO)为大语言模型提供了一个全新的优化路径,不仅提高了模型的生成质量,更重要的是提高了模型与人类偏好的对齐度。
随着技术的不断发展和优化,预计SPPO及其衍生技术将在人工智能的可持续发展和社会应用中发挥更大的作用,为构建更加智能和负责任的AI系统铺平道路。

文章来自于公众号机器之心



【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
