# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在大型语言模型的训练过程中,数据的处理方式至关重要。
传统的方法通常通过将大量文档拼接并切分成等同于模型的上下文长度的训练序列。这虽然提高了训练效率,但也常导致文档的不必要截断,损害数据完整性,导致关键的上下文信息丢失,进而影响模型学习到的内容的逻辑连贯性和事实一致性,并使模型更容易产生幻觉。
AWS AI Labs 的研究人员针对这一常见的拼接-分块文本处理方式进行了深入研究, 发现其严重影响了模型理解上下文连贯性和事实一致性的能力。这不仅影响了模型在下游任务的表现,还增加了产生幻觉的风险。
针对这一问题,他们提出了一种创新的文档处理策略——最佳适配打包 (Best-fit Packing),通过优化文档组合来消除不必要的文本截断,并显著地提升了模型的性能且减少模型幻觉。这一研究已被ICML 2024接收。

文章标题:Fewer Truncations Improve Language Modeling
论文链接:https://arxiv.org/pdf/2404.10830
在传统的大型语言模型训练方法中,为了提高效率,研究人员通常会将多个输入文档拼接在一起,然后将这些拼接的文档分割成固定长度的序列。
这种方法虽然简单高效,但它会造成一个重大问题——文档截断(document truncation),损害了数据完整性(data integrity)。文档截断会导致文档包含的信息丢失 (loss of information)。
此外,文档截断减少了每个序列中的上下文量,可能导致下一个词的预测与上文不相关,从而使模型更容易产生幻觉 (hallucination)。
以下的例子展示了文档截断带来的问题:
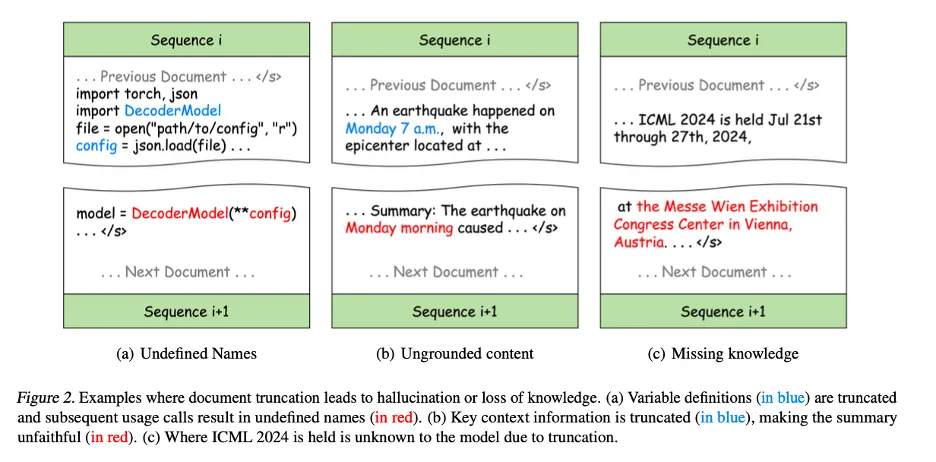
针对这一问题,研究者提出了最佳适配打包 (Best-fit Packing)。
该方法使用长度感知的组合优化技术,有效地将文档打包到训练序列中,从而完全消除不必要的截断。这不仅保持了传统方法的训练效率,而且通过减少数据的片段化,实质性地提高了模型训练的质量。
作者首先先将每个文本分割成一或多个至多长为模型上下文长度L的序列。这一步限制来自于模型,所以是必须进行的。
现在,基于大量的至多长为L的文件块,研究者希望将它们合理地组合,并获得尽量少的训练序列。这个问题可以被看作一个集装优化(Bin Packing)问题。集装优化问题是NP-hard的。如下图算法所示,这里他们采用了最佳适配递减算法(Best-Fit-Decreasing, BFD) 的启发式策略。
接下来从时间复杂度 (Time Complexity) 和紧凑性 (Compactness) 的角度来讨论BFD的可行性。

时间复杂度:
BFD的排序和打包的时间复杂度均为O(N log N),其中N是文档块的数量。在预训练数据处理中,由于文档块的长度是整数并且是有限的 ([1, L]),可以使用计数排序 (count sort) 来实现将排序的时间复杂度降低到O(N)。
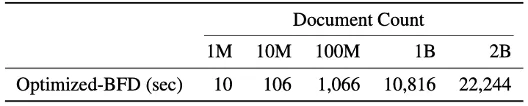
在打包阶段,通过使用段树(Segment Tree)的数据结构,使得每次寻找最佳适配容器的操作只需对数时间,即O(log L)。又因为L<<N, 使得总时长约为 O(N),进而整体算法与数据大小呈线性关系,确保对大规模数据集的适用性:处理大型预训练语料库如Falcon RefinedWeb (约十亿文档) 只需要3小时。
紧凑性 :
紧凑性是衡量打包算法效果的另一个重要指标,在不破坏原文档完整性的同时需要尽可能减少训练序列的数量以提高模型训练的效率。
在实际应用中,通过精确控制序列的填充和排布,最佳适配打包能够生成几乎与传统方法相当数量的训练序列,同时显著减少了因截断而造成的数据损失。
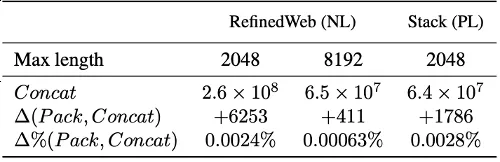
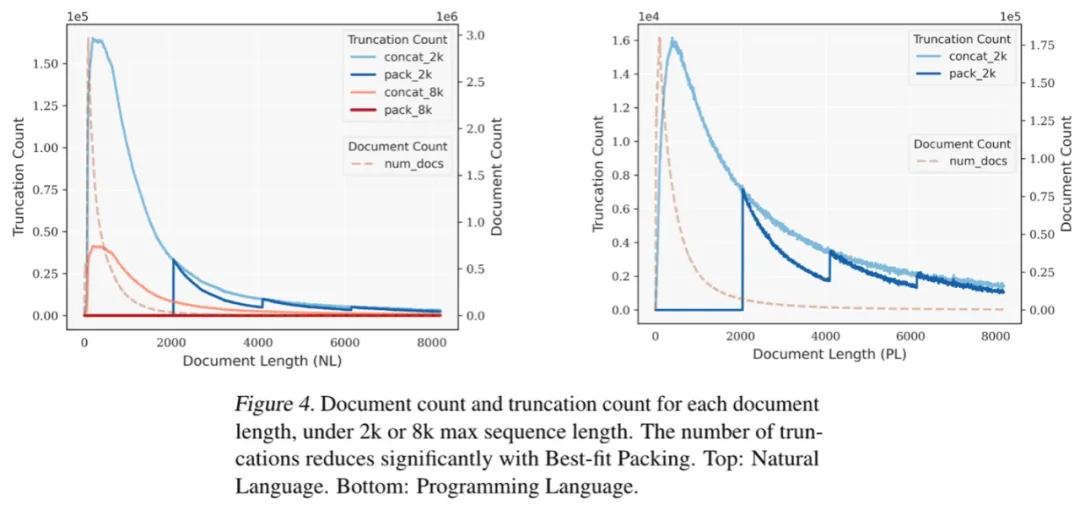
基于在自然语言(RefinedWeb) 和编程语言(The Stack) 数据集上的实验,我们发现最佳适配打包显著降低了文本截断。
值得注意的是,大多数文档包含的token数少于2048个;由于传统拼接-分块时造成的截断主要发生在这一范围内,而最佳适配打包不会截断任何长度低于L的文档,由此有效地保持了绝大多数文档的完整性。
研究人员详细报告了使用最佳适配打包与传统方法(即拼接方法)训练的语言模型在不同任务上的表现对比,包括:自然语言处理和编程语言任务,如阅读理解 (Reading Comprehension)、自然语言推理 (Natural Language Inference)、上下文跟随 (Context Following)、文本摘要 (Summarization)、世界知识 (Commonsense and Closed-book QA) 和程序合成 (Program Synthesis),总计22个子任务。
实验涉及的模型大小从70亿到130亿参数不等,序列长度从2千到8千令牌,数据集涵盖自然语言和编程语言。这些模型被训练在大规模的数据集上,如Falcon RefinedWeb和The Stack,并使用LLaMA架构进行实验。
实验结果表明,使用最佳适配打包在在一系列任务中提升了模型性能,尤其是在阅读理解 (+4.7%)、自然语言推理 (+9.3%)、上下文跟随 (+16.8%) 和程序合成 (+15.0%) 等任务中表现显著(由于不同任务的度量标准的规模各异,作者默认使用相对改进来描述结果。)
经过统计检验,研究者发现所有结果要么统计显著地优于基线(标记为s),要么与基线持平(标记为n),且在所有评测的任务中,使用最佳适配打包均未观察到性能显著下降。
这一一致性和单调性的提升突显了最佳适配打包不仅能提升模型的整体表现,还能保证在不同任务和条件下的稳定性。详细的结果和讨论请参考正文。

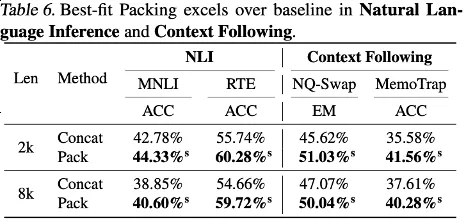


作者们重点研究了最佳适配打包对幻觉的影响。
在摘要生成中,使用QAFactEval度量发现采用最佳适配打包的模型在生成幻觉方面有显著降低。
更为显著的是,在程序合成任务中,使用最佳适配打包训练的模型生成代码时,“未定义名称”(Undefined Name)的错误减少了高达58.3%,这表明模型对程序结构和逻辑的理解更为完整,从而有效减少了幻觉现象。
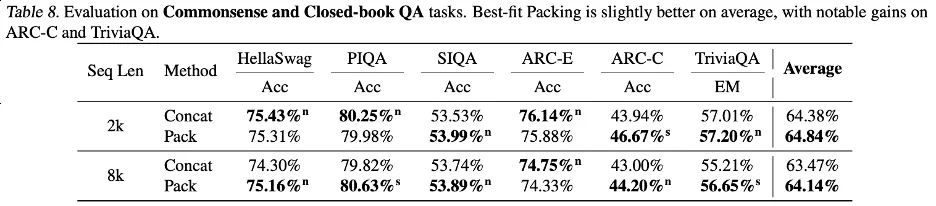
作者们还揭示了模型在处理不同类型知识时的表现差异。
如前所述,训练过程中的截断可能影响信息的完整性,从而妨碍知识的获取。但大多数标准评估集中的问题侧重于常见知识 (common knowledge),这类知识在人类语言中频繁出现。因此即使部分知识因截断而丢失,模型仍有很好的机会从文档片段中学习到这些信息。
相比之下,不常见的尾部知识(tail knowledge)更容易受到截断的影响,因为这类信息在训练数据中出现的频率本身就低,模型难以从其他来源补充丢失的知识。
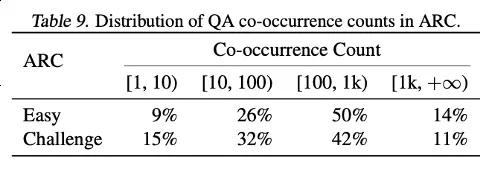
通过对ARC-C和ARC-E两个测试集的结果分析,研究者发现,相较于含有更多常见知识的ARC-E,使用最佳适配打包会使模型在含有更多尾部知识的ARC-C中有更显著的性能提升。
通过计算每对问题-答案组合在 Kandpal et al. (2023) 预处理的Wikipedia实体映射中的共现次数,这一发现得到了进一步验证。统计结果显示,挑战集(ARC-C)包含了更多罕见共现的对,这验证最佳适配打包能有效支持尾部知识学习的假设,也为为何传统的大型语言模型在学习长尾知识时会遇到困难提供了一种解释。
本文提出了大型语言模型训练中普遍存在的文档截断问题。
这种截断效应影响了模型学习到逻辑连贯性和事实一致性,并增加了生成过程中的幻觉现象。作者们提出了最佳适配打包(Best-fit Packing),通过优化数据整理过程,最大限度地保留了每个文档的完整性。这一方法不仅适用于处理数十亿文档的大规模数据集,而且在数据紧凑性方面与传统方法持平。
实验结果显示,该方法在减少不必要的截断方面极为有效,能够显著提升模型在各种文本和代码任务中的表现,同时有效减少封闭域的语言生成幻觉。尽管本文的实验主要集中在预训练阶段,最佳适配打包也可广泛应用于其他如微调阶段。这项工作为开发更高效、更可靠的语言模型做出了贡献,推动了语言模型训练技术的发展。
本文来自微信公众号”机器之心“




【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
