# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
近年来,定制化的人物生成技术在社区中引起了广泛关注。一系列创新性的模型,如 IP-Adapter、Photomaker、InstantID 等,已在图像生成领域取得了令人瞩目的成果。这些定制化内容生成方法逐渐成为主流,其一个重要的优势便是即插即用,取代了那些需要逐例微调的 Dreambooth,LoRA 等方法。
然而,尽管在图像生成领域取得了巨大的成功,这些方法在视频生成领域却遇到了阻碍。相较于图像,视频生成模型的训练需要更大的算力投入。同时,在视频数据集方面,迄今为止仍缺乏类似图像生成领域高质量的文本 - 视频配对人脸数据集。此外,如何提取人物身份一致性的特征也是一个难题。
为了应对这些挑战,腾讯光子近期发布的工作 ID-Animator,提出了一种文本驱动的人物视频生成框架。该框架旨在根据给定的一张参考图片,生成一致性的角色 定制化视频。通过这一创新性技术,研究者可以期待在不久的将来,人们将能够更轻松地实现定制化的人物视频生成,从而为各种应用场景带来更加丰富的视觉体验。

首先,让我们直观感受一下 ID-Animator 生成的视频效果,能够轻松的让不同的角色做起丰富的动作:
ID-Animator 不仅能生成 ID 一致的人类视频,还具备人脸特征融合的能力:
研究团队提出的方法可以概括为三个核心组件,如图所示。这三个部分包括:面向 ID 的视频数据集重构流程、随机人脸参考的训练方法,以及 ID-Animator 模型框架。通过这三个关键组成部分,ID-Animator 成功实现了高保真的一致性人物视频生成。
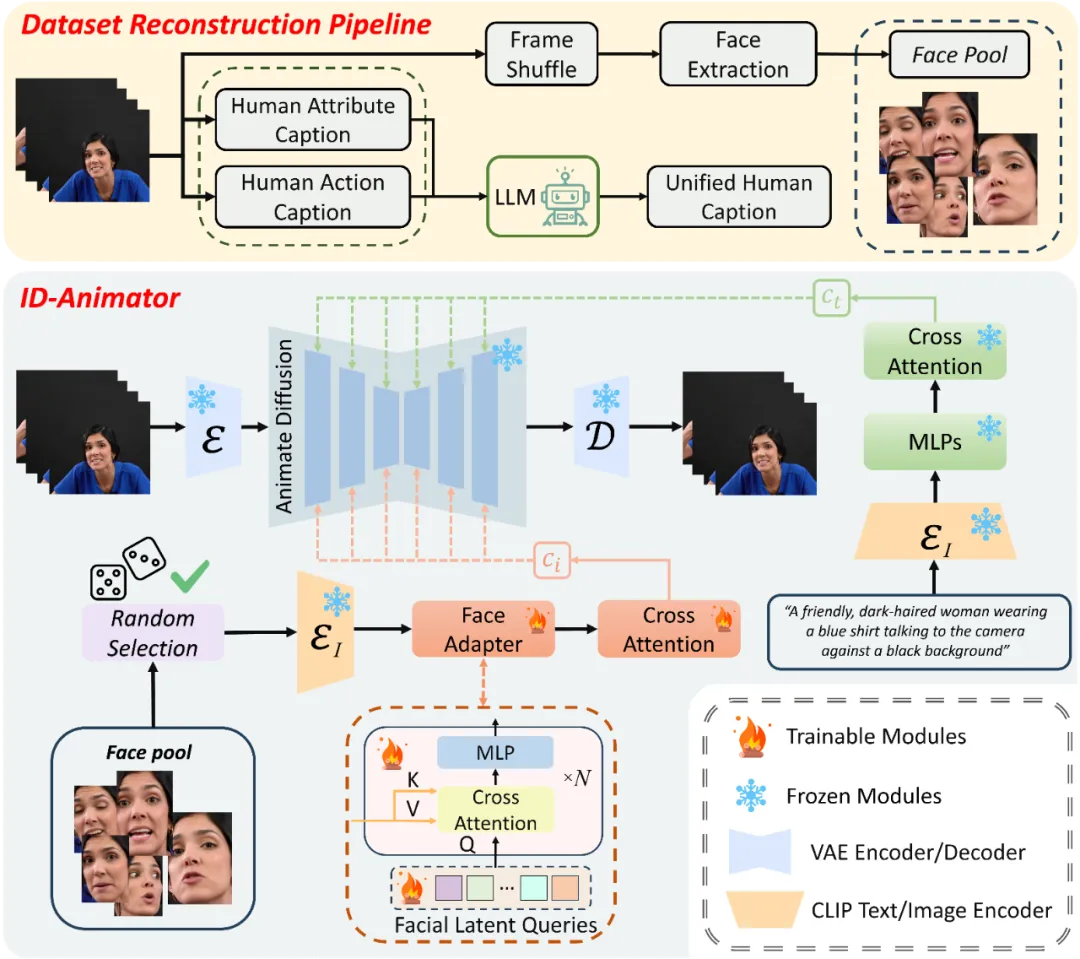
ID-Animator 框架由一个轻量级的人脸适配器模块和一个视频生成主干网络组成。其视频生成主干网络权重在训练过程中保持固定,无需微调。人脸适配器模块则由交叉注意力模块和可学习的面部特征查询组成,负责从 CLIP 编码的特征中提取与身份相关的表征,并将身份表征注入主干网络。利用这种轻量级的适配器模块,ID-Animator 只需要很小的训练开销就能实现人物一致性的视频生成。
为了应对以 ID 为核心的成对视频 - 文本数据集在视频生成领域的稀缺挑战,研究者们提出了一套巧妙的数据集重构策略。他们利用现有的 Celebv-HQ 数据集,将其重构为以 ID 为中心的人类视频数据集。这一策略分为两个主要步骤:文本重写和面部图像资源库构建。
现有的 Celebv 数据集的文本描述采用固定模板,主要关注人物表情的变化,却忽略了人物属性与所处环境,同时缺乏对动作的描述,因此不适用于文本生成视频的训练。为了解决这一问题,研究者们提出了一种新颖的文本重写方法,旨在生成更贴切的人类视频描述文本。考虑到视频整体特征和人物静态属性,他们采用了一种解耦式的文本重写方法,分别描述人物属性和环境,生成人类属性描述;同时描述视频中人物的整体动作,生成动作描述。最后,借助大型语言模型将两种描述整合,生成连贯且丰富的全新文本。
如图所示,重写后的文本描述更接近人类的语言风格,并能更好地描述人物的运动和属性。这一创新性方法为视频生成领域提供了一个更实用、更高质量的数据集基础。

为了进一步提升生成视频的身份保持能力,研究者们引入了一种随机面部提取技术。这种技术的特点在于,它并不直接采用整个视频帧作为生参考图像,而是构建数据集时专门针对人脸区域进行随机采样,从而形成一个独立的面部图像资源库。这一策略有效地过滤了大量非身份决定性的视觉信息,如背景变化、衣着装饰等,使得生成模型能够更加专注于学习和重现个体的面部特征与表情细节。
随机参考人脸训练方法
利用数据集面部资源库,研究者们提出了一种随机参考人脸的训练方法。这种方法的核心在于利用与视频内容弱相关的参考图像作为条件输入,引导模型在生成视频内容时,更多地关注指令指导的动作和 ID 无关特征。
具体操作上,研究者们从人脸资源库中随机选取参考图像,使得每次训练迭代都能为模型提供一个新的、与目标视频序列关联较弱的面部图像作为参考。这种方法实现了视频内容与人脸参考图像的解耦,有助于模型更好地学习和生成符合指令的动作,同时减弱与身份无关的特征的影响。
与 IP-Adapter 对比
研究者们首先将 ID-Animator 与常用的零样本定制化图像生成模型 IP-Adapter 的变体进行对比。将零样本定制化图像生成模型直接应用于视频生成时,可能会导致指令跟随能力和 ID 一致性的降低。为了证明 ID-Animator 的优越性能,研究者们展示了在 3 个名人和普通人上的对比结果。
如图所示,ID-Animator 在视频场景下展现出了更强大的指令跟随能力和 ID 保真度。

应用展示




更多详细内容,请阅读原论文。
本文来自微信公众号“机器之心”



【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
