# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大语言模型可谓是迄今为止对人类行为最大的建模,如何借助大语言模型工具,让科技发展更好地应用到真实人类社会中去?从哈佛物理系到大语言模型结合社会学和经济学的研究,朱科航的思考路径,聚焦在对人类行为的深度学习和理解。在开始今天阅读之前,大家不妨先猜一猜,大语言模型之前人类应用最广的 TOP2 机器学习是什么?Enjoy

《Automated Social Science: Language Models as Scientist and Subjects》
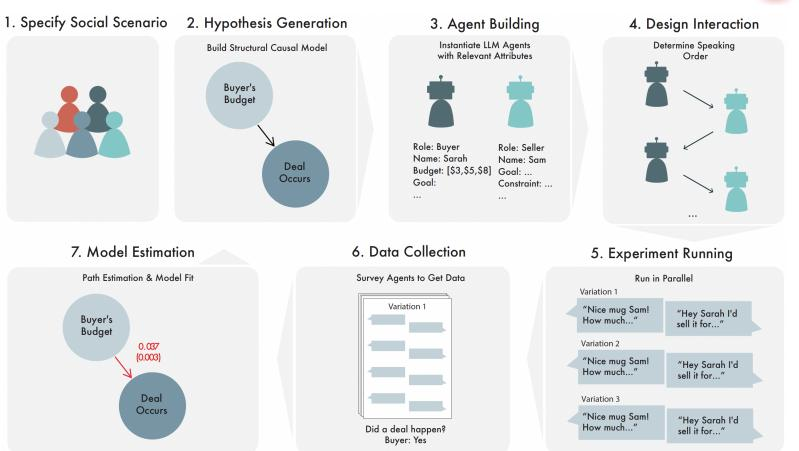
Automated Social Science实验流程
解决问题:在传统社会科学领域,进行面试、拍卖、产品测试、保释听证会等场景的模拟测试需要招募真人参与,过程费时费力且成本高昂,有的场景根本不能进行实验。团队利用 LLM-based Agent 作为人的近似模型,提出了一种通用的自动化实验方法,实现低成本高效的社会实验测试,最终能对公共政策等宏观测试有进一步促进作用
模型框架: 团队对科研人员和普通人进行建模,演示了社会科学问题的自动化探索。这个流水线由“科学家 Agent”提出因果假设,设计实验,建造符合实验设定的“普通人 Agent”替代真人进行实验,到完成各种场景的社会科学模拟实验,最终数据自动收集,并且检验假设
使用效果:论文的结果表明,完全自动化实验的方案可以快速地进行大量社会学实验,并且获得对于新的因果关系的洞见,这些新的知识反过来也可以改进大语言模型本身对于人类行为的理解
应用空间: 各种社会科学和经济学测试场景,论文展示了讨价还价、税务诈骗保释听证会、律师面试、私人藏品拍卖等场景
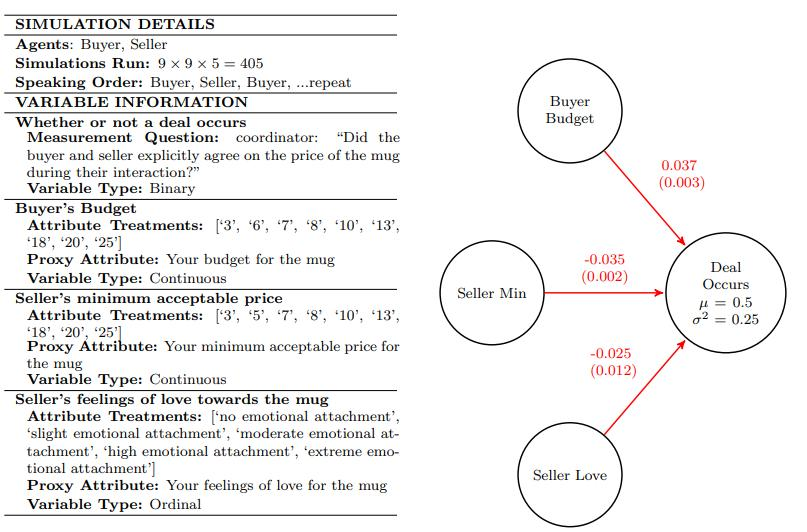
马克杯讨价还价案例展示
绿洲:你为什么从物理转向了机器学习的研究?
科航:我本科在中科大做量子物理研究,目前在哈佛大学物理系三年级博士。刚来哈佛的时候,师从诺贝尔奖得主 Frank Wilczek 一起做复杂材料的建模,用量子场论里的模型做近似理论预测。但哈佛是一个人文气氛很浓重的学校,在这里的学习,让我觉得我研究的内容与这个社会产生了脱节,我想去研究人与人之间在社会关系中的变化与链接,研究兴趣也更多转向对人类社会进行建模,因此有了一个大的研究方向转变。也感谢哈佛的自由度,让我直接转到 MIT 斯隆商学院教授 John J. Horton 门下,目前跟他做大语言模型结合经济学和社会学的研究。
绿洲:请问做物理材料建模和社会关系建模有什么互通之处?
科航:我觉得原理是差不多的。New Yorker 上有一篇通俗的文章《How Much of the World Is It Possible to Model?》,讲述建模的对象从最初简单的宏观物质运动,例如地球绕着太阳转,到当今十分复杂的天气系统、材料、人脑,已经是对于万亿量级的微观物体建模。举个例子,我们现在用来视频通话的电脑电池里有几万万亿个原子,从微观的角度去预测电池材料的性质是极其复杂的建模。当时我和 Frank 一起研究材料的时候,只能用理论描述一小部分,做了很多近似,写了很多数学公式,最后还是需要用高性能计算机做模拟数值求解。
在对于人类行为的建模领域,单个人的大脑也有几万万亿量级的神经元,这些神经元如何产生神经信号,如何最终决定人类的情绪、行为,同样是一个很复杂的系统。由几亿人组成的人类社会,目前有限的数学或计算机求解手段都很难实现很好的建模。大语言模型的出现打破了这一限制。LLM 本质上是一个有千亿数量级参数的数学模型,我在 MIT 的导师可能是最早一批意识到这是迄今为止对人类行为最大的建模的 人之一。早在 ChatGPT 横空出世前,他就是最早的 Homo Silicus(学术界中支持硅基人类的大模型)的提出者。
绿洲:这篇论文在 4 月中发布之后,我们看到 Paul Graham 转发了,Twitter 的阅读也超了百万。能否帮我们解释一下论文的主要架构以及 SCM 方式(Structural Causal Model)?
科航:论文主要分为两部分,第一部分是将 LLM 及 Agent 用于帮助科研人员(Scientist)建模,另一部分用于普通人(Human Subjects)建模。
社会学的一个经典范式是, 针对特定的问题,提出假设,根据假设设计一系列控制变量实验。研究者可以检索历史数据、寻找真人进行调研或者做实验干预。最终根据收集的数据来验证假设。社会科学里从假设,到实验设置,再到最后的数据收集,统计学的分析验证方法都已经非常成熟了,是一套程序化的流程。
所以在第一部分,我们想用 LLM 来自动化整个流程。作为一个最初的方法论工作,我们具体关注一类特定的社会学研究 - 因果关系,也就是研究自变量 X 是否会影响因变量 Y(也成为结果)。为了规范化因果关系的表述,我们采用了由图灵奖得主 Judea Pearl 提出的因果结构模型。
举一个例子,比如绿洲与我这样一位研究员对谈,在这个过程中会产生有意思的自变量和因变量,自变量包括我论文的有趣程度,你们那边的天气等等,因变量结果就是你们三位对信息收集的满意程度。因果结构模型把每一个自变量和因变量都作为单一节点,用连线的方式表示他们之间的关系,自变量和因变量之间有连线就意味着两者存在因果关系。这种模型也可以用图的方式清楚地把它们之间的关系展现出来。同时它所具有的优良数学特性能让整体的实验框架变得更加严谨。
绿洲:在实验过程中如何设立 Agent 进行实验呢?
科航:在科学家 Agent 方面,用 LLM 做假设生成、实验设计和数据分析的研究文章已经很多了,我们只不过把已有的一些技术和手段缝合在了一起。
普通人建模方面,我们会给 LLM 一些人的基本属性,例如姓名、年龄、教育程度、家乡等信息,然后让它扮演这个特定的人的角色去回答问题或者做决策。在我们的实验中,这些 Agent 还会被赋予关于实验变量的信息,比如上面提到的天气状况,论文的有意思程度等等。在我们的演示实验中,所有的 Agent 都是直接由 GPT-4 通过 Prompt 后得到的。
绿洲:能否帮我们展开一下论文中关于马克杯讨价还价的案例?
科航:在讨价还价的案例里,我们设置了三个自变量,卖方目标价格、买方预算、卖方对商品的情感依恋程度(这是一个行为变量)。对每一个自变量,都做了很多组对照实验。比如说不同的实验中,价格和预算分别会被设置成 5 美元、10 美元、20 美元、30 美元等,对马克杯的依赖程度分为一点都不喜欢马克杯到非常喜欢马克杯。我们会去看不同因素下,最后的结果变化(交易的发生)是否存在差异。对于数据的分析表明,顾客预算越多,交易越容易发生;卖方目标价格越低,交易也越容易发生;卖家感情依恋程度越低,交易越容易发生。
这个结果很符合我们的直觉,但有意义的点在于,LLM 居然可以很自然地就代入到角色扮演中,也可以反应人的现实偏好。因此,未来进行真正产品调研的时候,可能就让 Agent 来扮演目标客户群体,这样就再也不用发问卷等复杂低效的方式。去年,哈佛商学院的 Ayelet 教授发布了一篇专门做市场营销的论文,提出了用 Agent 做市场调研的实验框架。我们的这篇研究也是深受她的启发。
绿洲:为什么在论文中选择“讨价还价”、“律师面试”、“私人藏品拍卖”、”税务诈骗保释听证会”这几个场景进行实验呢?
科航:这是一个很有意思的问题。我导师之前主要研究计算社会学和劳动经济学。讨价还价是很经典的关于市场行为研究命题,买家和卖家的很多因素都能对于是否成交造成影响,过去在传统的经济学上很难去研究人的情绪。工作面试属于一个传统经济研究课题,我们加入了面试者身高这个因素,这是过去社会科学一直存在争议的问题,我们在这里也作为致敬;拍卖就是一个更加经典的社会科学和经济学的问题了,有大量的文献;法官裁决听证会的案例,Daniel Kahneman 写过一本书叫《思考,快与慢》,里面提到一个例子是法官在做判决的时候,有很多噪声会影响判决结果,包括天气等各种外界因素,这是系统 1 的因素,而其他深思熟虑和案件相关的是系统 2 的因素,因此我们在这个例子里也在致敬 Daniel Kahneman 的经典案例(本篇论文的另一位第一作者曾是 Daniel Kahneman 的学生)。
《思考,快与慢》书中表示,大脑有快与慢两种做决定的方式。常用的无意识的“系统1”依赖情感、记忆和经验迅速作出判断,它见闻广博,使我们能够迅速对眼前的情况作出反应。但系统1也很容易上当,它固守“眼见即为事实”的原则,任由损失厌恶和乐观偏见之类的错觉引导我们作出错误的选择。有意识的“系统2”通过调动注意力来分析和解决问题,并作出决定,它比较慢,不容易出错,但它很懒惰,经常走捷径,倾向于直接采纳系统1的直觉型判断结果
团队 Agent 框架在拍卖案例的实际运行示例
在大模型之前,机器学习在人类社会中应用最广泛的是信用分预测(信用卡公司在用户每申请一张信用卡的时候,都会利用机器学习算法来判断用户是否达到一定的偿还能力)和个性化的广告推荐,而并非更 Fancy 的生物医药或者自动驾驶,这说明机器学习过去最大的应用是在“被动场景”:人的信息被收集、传递到后端的算法,这些算法本质上也是对人的一个特定行为的建模。而大语言模型是对人一般行为的建模。
在今天 OpenAI 如此广为人知的情况下,即使在美国都还有大量人群从未使用过生成式 AI。主动学习存在使用门槛和成本问题。但上面说的两个被动的应用却基本覆盖了每一个美国人。
未来大模型在被动测试阶段,可以将某个用户行为数据收集起来,通过微调的方式建造该用户的 Agent 分身。那么这个 Agent 的行为或者偏好,可能很大程度上和真人相似。你们可以想象这种个人 Agent 可以被用来做很多事情,比如进行问卷调查/产品测试这类繁杂且高成本的工作,只需要调用几次个人 Agent API 就行。
当然现在的 Agent 还远远达不到这种程度,以及数据安全和隐私的问题会被成倍放大。
绿洲:将 Agent 架构用于产品测试和真人测试的差距在哪?
科航:这依赖于 Agent 替代真人的具体场景。如果是产品测试,那我觉得最大的问题是多模态能力仍不完善。物理的产品 Agent 肯定没办法体验。触觉,听觉,很多应用的交互形式也是目前的 LLM 不能做的。第二个不足是当前人类反馈强化学习(RLHF)对于预训练模型造成了过分微调,LLM 本身在预训练的过程中利用了海量平均人类水平的数据进行训练,但后期在大模型向人类价值观对齐的过程中,可能将原本数据中体现的人的非理性行为抹去了,毕竟很多消费出自人的非理性(笑)。
绿洲:下一步想解决哪些问题呢?
科航:首先作为一个学科,我觉得 LLM 应用在社会科学领域刚刚起步。目前 99% 的 LLM Agent 的工作都在往 AGI 方向努力,但实际上大量的模型已经被调教成了“四不像”(笑)。有的时候能做一些很复杂的工作,但又有的时候“连狗都不如”(出自图灵奖得主 Yann Lecun 的评价)。这些模型可能还是在通过类似死记硬背的方式进行学习。我们认为不需要用对齐来把大模型的所有缺陷和偏见全部消除,而是要让大模型反应真实的人类群体。
第二我们在思考代表性的问题。从训练资料来说,英语的语料占了绝大多数,但即使这样,大语言模型很大程度上代表了所谓的 W.E.I.R.D 群体(Western, Educated, Industrialized, Rich, Damocratic)。
所以这种 LLM 做出来的结果可能只能适用到这类特殊人群或者人类所共有的一些特质上,比如逻辑性的思考能力,逐利行为等。我们的工作也在探索到底在什么领域内,在人类的什么行为上,LLM 可以做一些比较好的替代。
怎么解决多模态也是一个很大的问题,但有很多进展。比如去年腾讯有一个组做了一个可以直接使用手机 APP 的 Agent。
绿洲:如何去掉大模型的对齐呢?
科航:做对齐才会产生各种各样的麻烦,去掉对齐反而很简单,直接不做就可以了。Llama-2 和 Llama-3 的预训练和微调之后的模型 Meta 都开源了,我们直接使用 Pre-trained Model 进行微调。微调分为两种,价值的微调和输出格式上的微调,我们目前只需要做输出格式上的微调就可以了。Llama-3 出来感受效果确实好了很多,具体体现在模拟人类行为更像了。
绿洲:AI 的发展对于你们科研和思考有什么影响?
科航:首先我个人很认可 AGI 这个方向。我们让 LLM 作为科学家实现更多的自动化实验。
但我个人认为目前大语言模型呈现的众多局限性,恰恰使得它更适合用来研究人类本身。不仅美国各个大学都开始跟进这个方向,一些专门研究公共舆论的机构也开始使用 Agent 在社交媒体进行模拟,例如针对网络言论对于硅谷银行倒闭的影响。
从远景来说,我们希望能借助 LLM 这个工具,让物质规律(比如计算机科学、物理学)的研究者和人类行为(社会学、经济学,公共政策等)的研究者更好地对话,从而让科技发展能更好地应用到真实的人类社会中去。
文章来源于“绿洲资本”




【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
