# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
移动应用已经成为我们日常生活的一大重要组成部分。使用移动应用时,我们通常是用眼睛看,用手执行对应操作。如果能将这个感知和交互过程自动化,用户也许能获得更加轻松的使用体验。此外,这还能助益手机辅助功能、多步 UI 导航、应用测试、可用性研究等。
为了在用户界面内实现感知和交互的无缝自动化,就需要一个复杂的系统,其需要具备一系列关键能力。
这样一个系统不仅要能完全理解屏幕内容,还要能关注屏幕内的特定 UI 元素。以视觉理解为基础,它应当有能力进一步将自然语言指令映射到给定 UI 内对应的动作、执行高级推理并提供其交互的屏幕的详细信息。
为了满足这些要求,必须开发出能在 UI 屏幕中确定相关元素位置并加以引述的视觉 - 语言模型。其中,确定相关元素位置这一任务通常被称为 grounding,这里我们将其译为「定基」,取确定参考基准之意;而引述(referring)是指有能力利用屏幕中特定区域的图像信息。
多模态大型语言模型(MLLM)为这一方向的发展带来了新的可能性。近日,苹果公司一个团队提出了 Ferret-UI。

这应当是首个专门针对 UI 屏幕设计的用于精确引述和定基任务的 MLLM,并且该模型能解读开放式的语言指令并据此采取行动。他们的这项工作聚焦于三个方面:改进模型架构、整编数据集、建立评估基准。
实验表明,他们的这种方法效果还挺不错,如图 1 所示:Ferret-UI 能够很好地处理从基础到高级的 11 种任务,从简单的寻找按钮到复杂的描述具体功能。
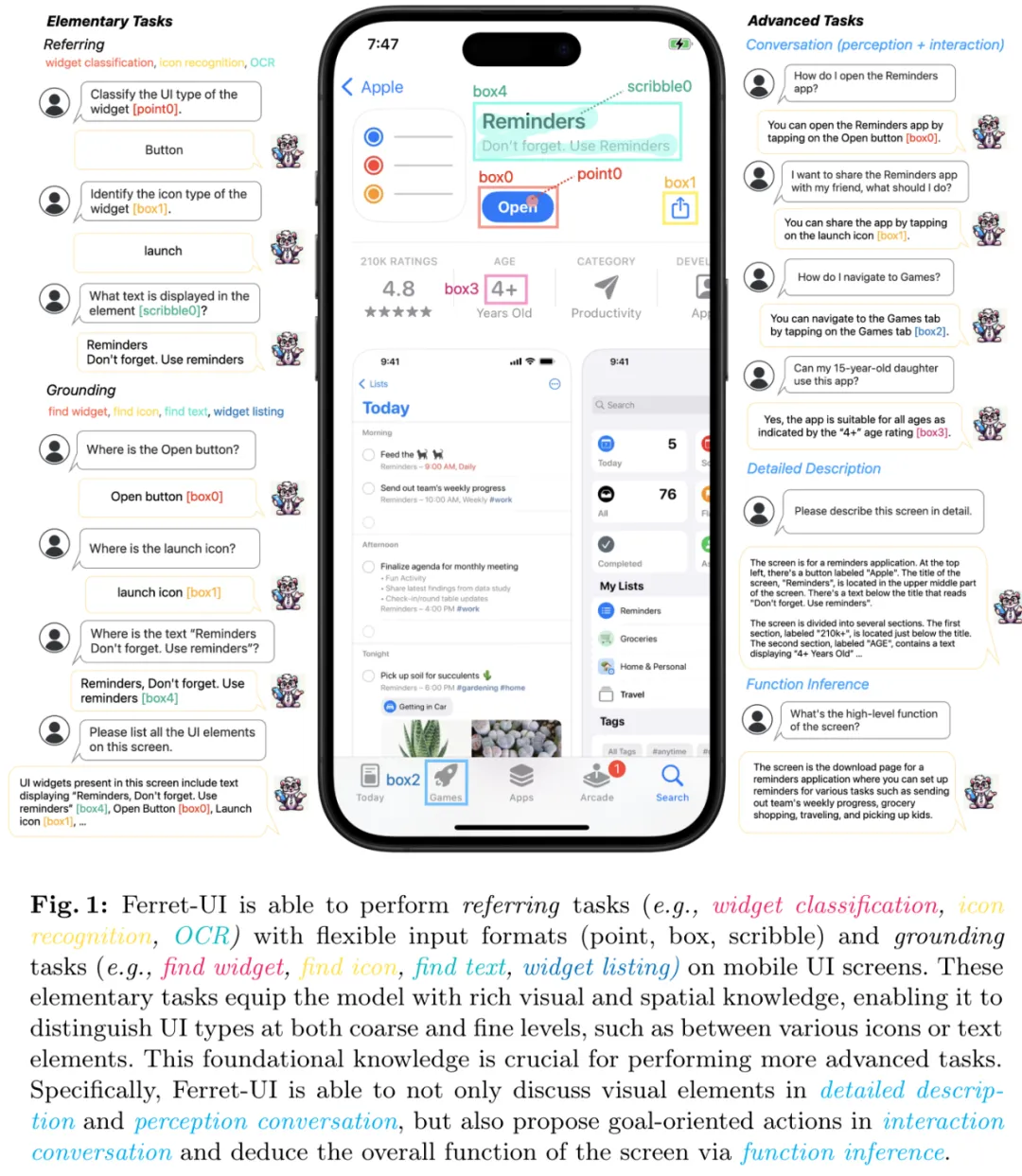
下面来看具体方法。
Ferret-UI 基于 Ferret,而 Ferret 是一个擅长处理自然图像的引述和定基任务的 MLLM,并且其支持多种形状和细节层级。
Ferret 包含一个预训练的视觉编码器(如 CLIP-ViT-L/14)和一个仅解码器语言模型(如 Vicuna)。
此外,Ferret 还采用了一种独特的混合表征技术,可将指定区域转换为适合 LLM 处理的格式。其核心是一个可感知空间的视觉采样器,能够以不同稀疏层级管理区域形状的连续特征。
为了将 UI 专家知识集成到 Ferret 中,苹果团队做了两方面工作:(1)定义和构建 UI 引述和定基任务;(2)调整模型架构以更好地应对屏幕数据。
具体来说,为了训练模型,Ferret-UI 包含多个 UI 引述任务(比如 OCR、图标识别、小部件分类)和定基任务(比如寻找文本 / 图标 / 小组件、小组件列表);这些任务可帮助模型很好地理解手机 UI 并与之交互。之前的 MLLM 需要外部检测模块或屏幕视图文件,而 Ferret-UI 不一样,它自己就能搞定,可以直接输入原始屏幕像素。这种方法不仅有助于高级的单屏幕交互,而且还可支持新应用,比如提升支持残障人士的辅助功能。
研究 UI 数据集还为该团队带来了另外两个有关建模的见解:(1)手机屏幕的纵横比(见表 1a)与自然图像的不一样,通常更长一些。(2)UI 相关任务涉及很多对象(即图标和文本等 UI 组件),并且这些组件通常比自然图像中的对象小得多。
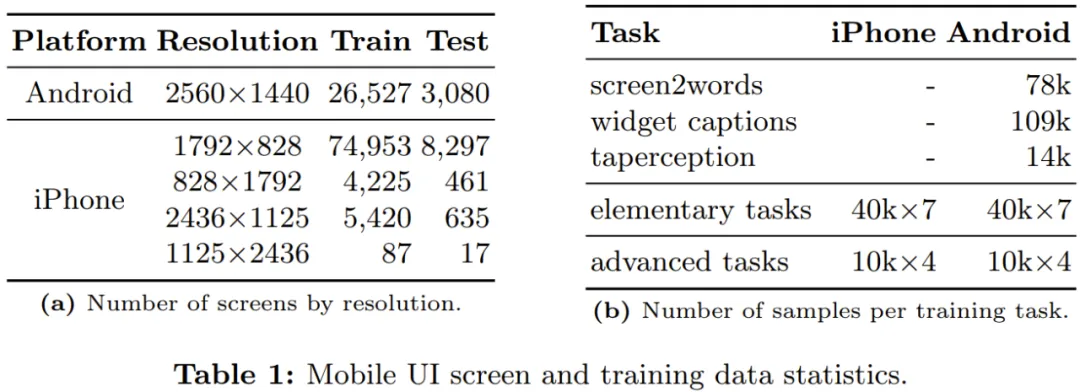
举个例子,很多问题涉及的图标的面积只占整个屏幕的 0.1%。因此,如果只使用单张重新调整了大小的低分辨率全局图像,可能会丢失很多重要的视觉细节。
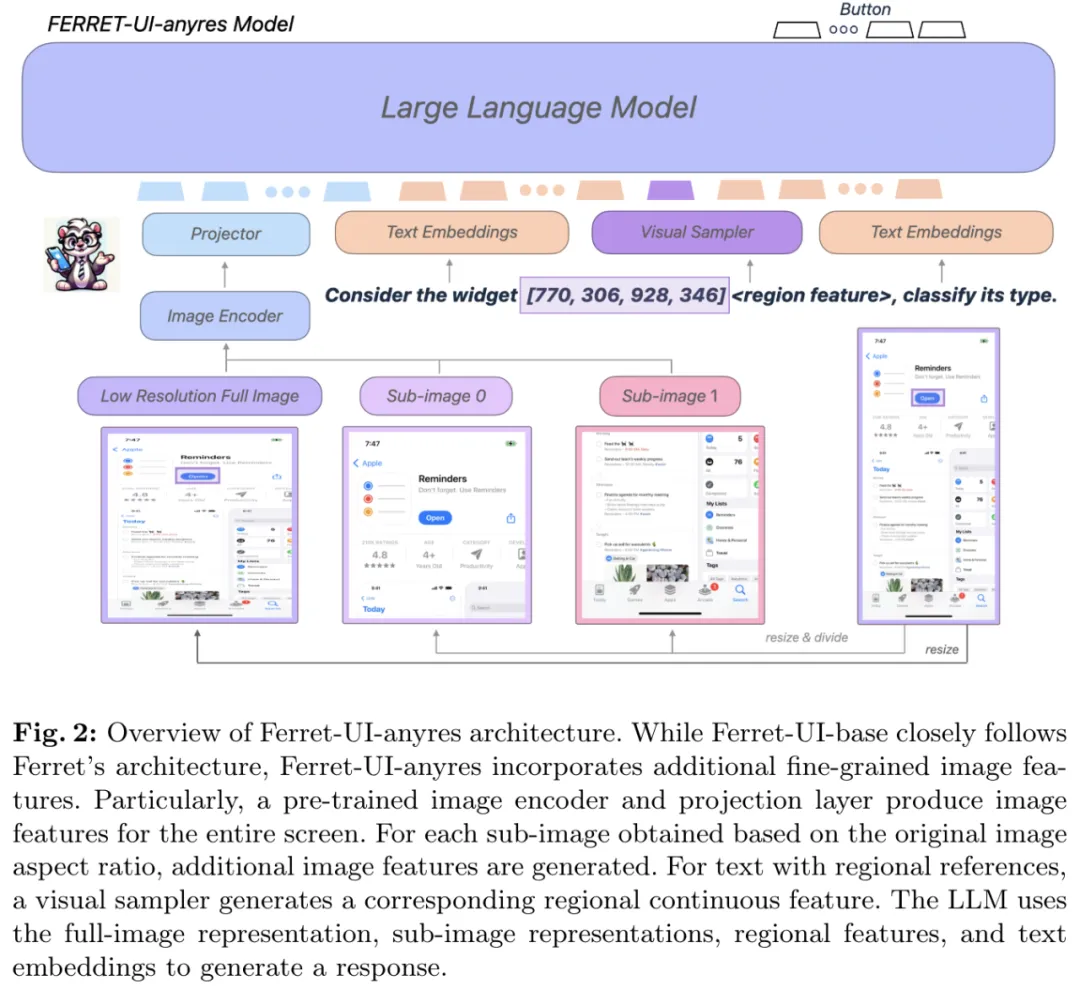
为了解决这个问题,该团队引入了 any resolution(任意分辨率 /anyres)这一思想。
具体来说,基于手机的原始纵横比,他们选择了两种网格配置:1x2 和 2x1。给定一张屏幕图像,选取最接近其原始纵横比的网格配置。之后,调整屏幕图像大小,使其匹配所选的网格配置,然后再将其切分为子图像(sub-image)。很明显,纵向屏幕会被水平切分,而横向屏幕会被垂直切分。然后,使用同一个图像编码器分开编码所有子图像。接下来 LLM 就可以使用各种粒度的所有视觉特征了 —— 不管是完整图像还是经过增强的细节特征。
图 2 给出了 Ferret-UI 的整体架构,包括任意分辨率调整部分。
苹果团队构建了一个数据集来训练和评估模型。
UI 屏幕。该团队不仅收集了 iPhone 屏幕,也收集了安卓设备的屏幕。
其中安卓屏幕数据来自 RICO 数据集的一个子集,并根据该团队的分割方案进行了处理。总共有 26,527 张训练图像和 3080 张测试图像。
iPhone 屏幕则来自 AMP 数据集,有不同大小,共 84,685 张训练图像和 9,410 张测试图像。
UI 屏幕元素标注。他们使用一个预训练的基于像素的 UI 检测模型对收集到的屏幕数据进行了细粒度的元素标注。
下面将简单描述该团队是如何将 UI 屏幕和相应标注转换成可用于训练 MLLM 的格式。这有三种方法。
方法一:调整 Spotlight 的格式。基于论文《Spotlight: Mobile ui understanding using vision-language models with a focus》,他们取用了 Spotlight 中的三个任务:screen2words、widgetcaptions 和 taperception,并将它们的格式调整为了对话式的一对对问答。具体来说,为了创建 prompt,他们使用了 GPT-3.5 Turbo 来处理他们编写的基础 prompt:
每个训练示例都采样了相应任务的 prompt,并搭配了原始原图像和基本真值答案。
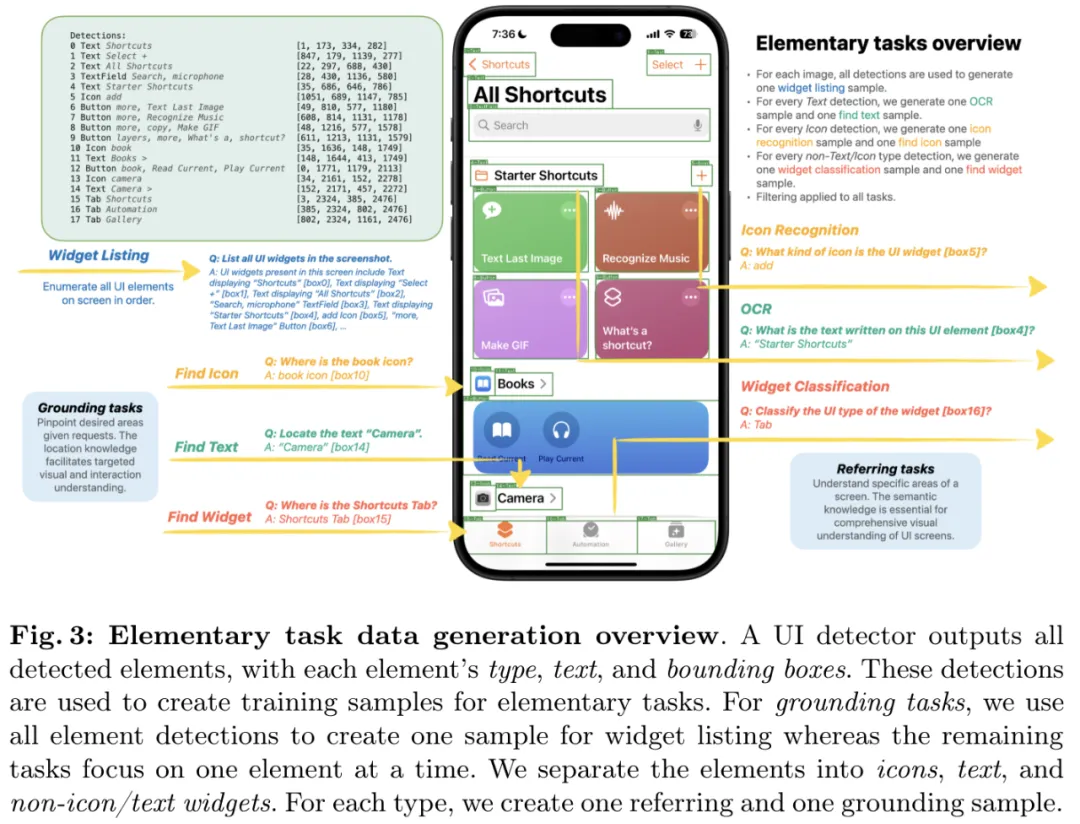
方法二:基础任务。除了 Spotlight 任务,该团队还创建了 7 个新的 UI 任务:用于引述的 OCR、图标识别和小部件分类;用于定基的小部件列表、查找文本、查找图标、查找小部件。他们将引述(referring)任务定义为输入中有边界框的任务,而将定基(grounding)任务定义为输出中有边界框的任务。
他们还使用 GPT-3.5 Turbo 扩展了每个任务的基础 prompt,以引入任务问题的变体版本。图 3 给出了数据生成的详情。每个任务的训练样本数量见表 1b。
方法三:高级任务。为了让新模型具备推理能力,他们跟随 LLaVA 的做法并使用 GPT-4 额外收集了四种其它格式的数据。图 4 展示了高级任务的训练数据生成过程。
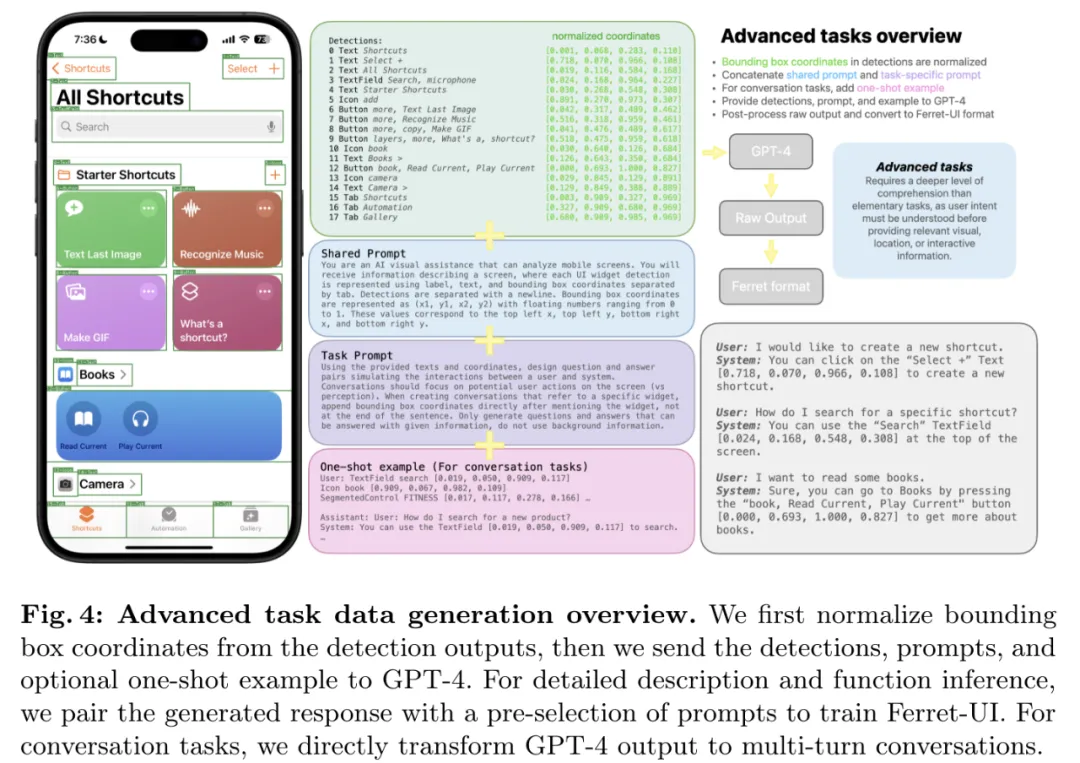
这四个任务是:详细描述、对话感知、对话交互和功能推断。
该团队进行了实验研究和消融研究,并对结果进行了详细分析。
设置:Ferret-UI-anyres 是指集成了任意分辨率的版本,Ferret-UI-base 是指直接采用 Ferret 架构的版本,Ferret-UI 是指这两种配置。训练使用了 8 台 A100 GPU,Ferret-UI-base 耗时 1 天,Ferret-UI-anyres 耗时约 3 天。
实验比较了 Ferret-UI-base、Ferret-UI-anyres、Ferret 和 GPT-4V 在所有任务上的表现;另外在高级任务上参与比较的模型还有 Fuyu 和 CogAgent。
表 2 总结了实验结果,其中的数据是模型在每个类别中的平均表现。
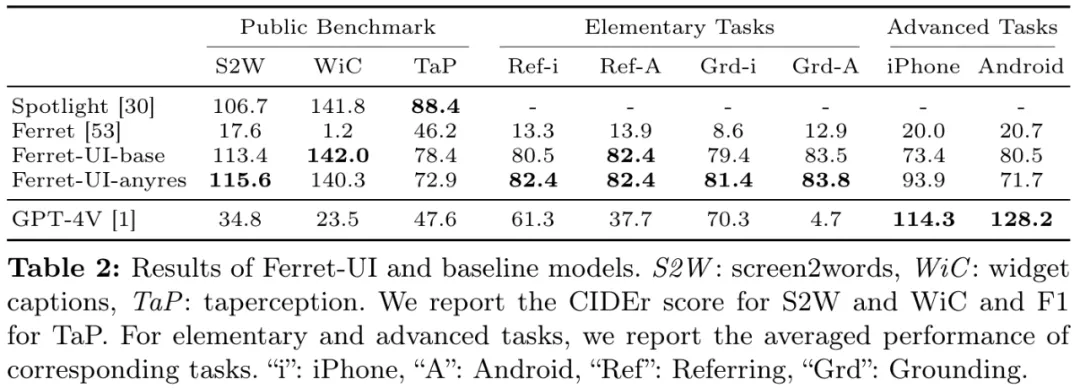
图 5 和表 3 给出了在具体的基础和高级任务上的表现详情。
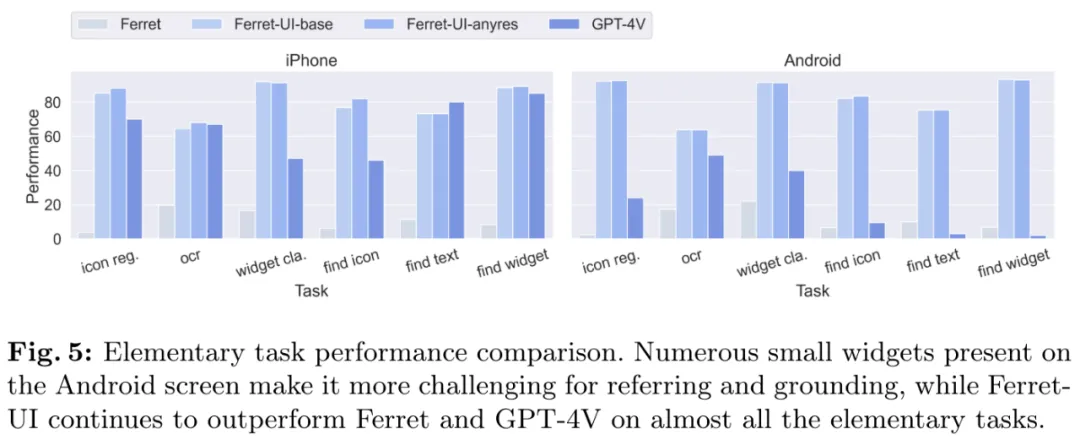
从这些图表可以看到,Ferret-UI 的表现颇具竞争力。尤其是任意分辨率(anyres)的加入能让 Ferret-UI-base 的表现更上一层楼。
表 4 给出了消融研究的详情。
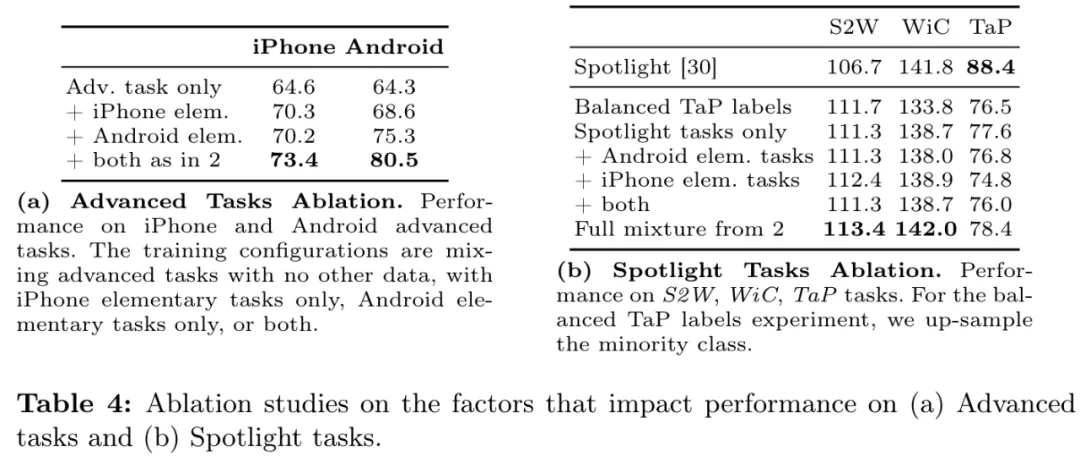
从表 4a 可以看到,基础任务能够帮助提升模型解决高级任务的能力。
而表 4b 则表明,加入基础任务数据并不会明显改变模型在三个 Spotlight 任务上的性能。其原因可能是基础任务的响应中使用了简短且高度专业化的 UI 相关术语,这与 Spotlight 任务要求的响应风格不一致。而如果进一步整合高级任务,便能够在 Spotlight 任务上得到最佳结果,即便这些高级任务数据完全来自 iPhone 屏幕。
该团队最后对 Ferret-UI 的结果进行了详细的分析,进一步验证了其在引述和定基任务上的出色表现,详情参阅原论文。
本文来自微信公众号“机器之心”




【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
