# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

真正的恐怖谷效应是什么?
快看,下面这个女生做出了各种生动丰富的表情,挤眼,挑眉,嘟嘴....

再来看这个男孩,不停地变化嘴型,再加上细微的眼神动作,丝毫看不出来和我们有何区别。

然而,谁能想到,他们竟不是真人!
网友纷纷称其为AGI,简直逼真到可怕。

如此厉害的3D头像生成,完全不输小扎此前带着Quest 3 Pro做客「元宇宙」播客的逼真数字化身。

那么,这项研究竟出自哪位民间高手?
最近,来自德国慕尼黑工业大学、伦敦大学学院等研究团队提出了全新算法——NPGA,可生成高质量3D头像。

论文地址:https://arxiv.org/pdf/2405.19331
这是一种基于数据驱动的方法,从多视角的视频中创建出高保真、可控的虚拟化身。
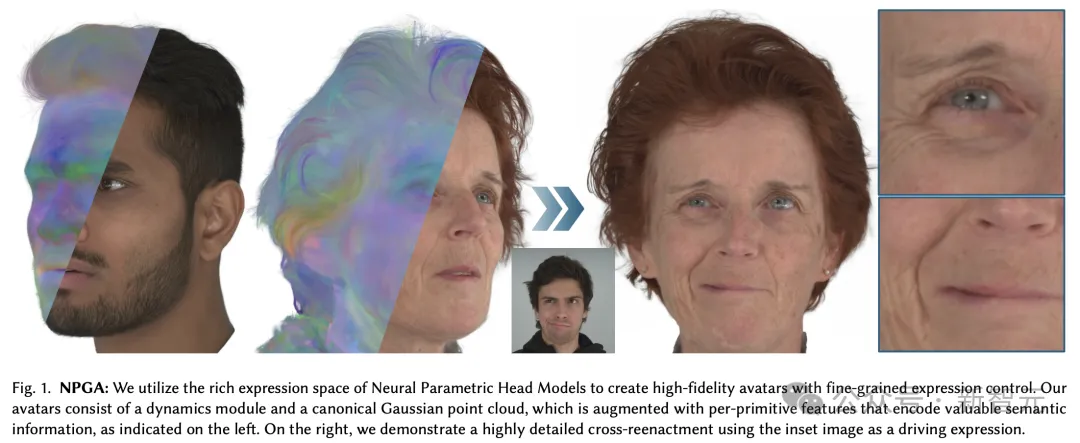
传统上,往往会用网格3DMM去生成渲染的头像,但效果一般。
而NPGA的创新在于,采用了高斯点云的方式,即通过无数个点组成3D人像形状,让渲染更加高效、逼真。

另外,研究的另一个创新在于,利用了神经网络模型——「神经参数化头模型」(NPHM)来捕捉人脸细微表情的变化,由此3D数字化身可以更真实模拟人类表情。
最后,为了增强数字化身的表现力,研究人员还对潜在特征和预测动态提出了「拉普拉斯项」(Laplacian terms)。
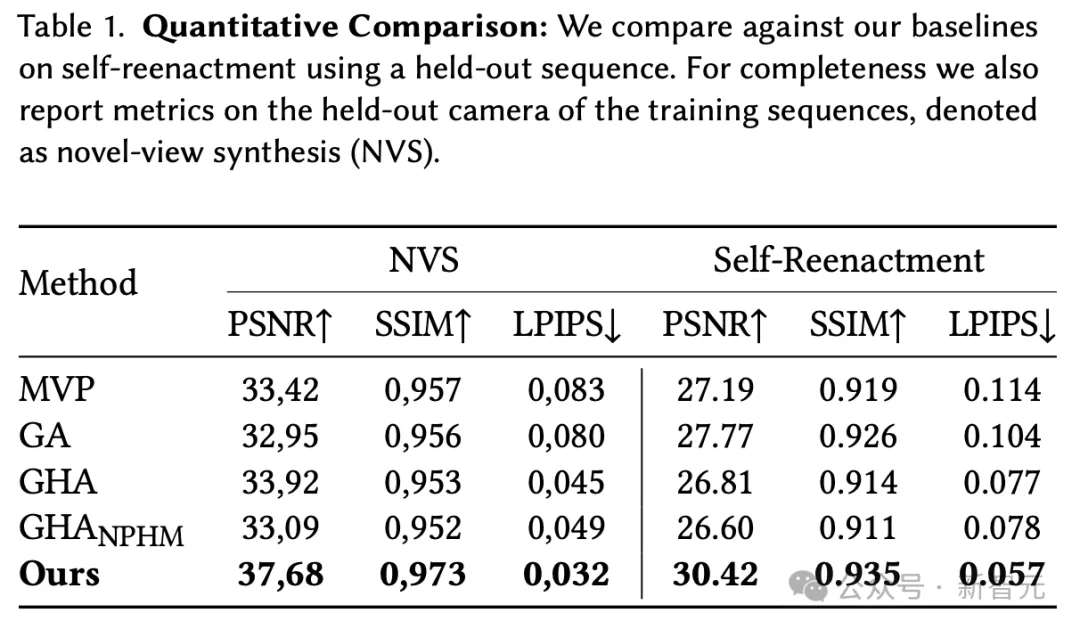
实验评估结果显示,NPGA比起之前SOTA模型,在自我重现任务中,大约有2.6PSNR提升。
有人惊呼,这简直离诈骗又近了一步。

此时的网友还不忘调侃,谷歌最近放出的一个不可思议的视频。


看这奇怪的画风,再加上虚拟化身不稳定性,简直无法和NPGA竞争。

这是谷歌团队新提出的ChatDirector算法,按谷歌宣传的话称,3D虚拟头像可以让在线会议更具「沉浸感」
NPGA:神经参数高斯化身
这项技术可以应用在很多场景,比如电影、游戏、AR/VR远程会议,以及小扎心心念念的元宇宙。
虽然视频的效果看起来如此逼真,但其实,从现实世界捕获图像并重建3D头像是一个极具挑战性的课题。既需要计算机视觉(CV)准确的识别功能,也需要计算机图形学(CG)的高保真和实时渲染性能。
近年来这两项技术的交叉,让虚拟世界的3D化身越来越逼真。然而,有一个核心问题还没被解决——如何实现控制性。
谷歌ChatDirector的视频之所以十分奇怪,主要原因不在画面渲染,而在面部动作和表情的控制性差,说话时嘴动了但其他部位没有动,有「皮笑肉不笑」的感觉。
Reddit评论区有网友发问,「我什么时候能看到这个模型的开源版本,这样只需要几张照片就能生成类似的3D化身了?」
很遗憾,目前的技术应该还做不到通过几张图片就能进行3D重建。
团队使用的训练集NeRSemble是一个视频数据集,用16个机位拍摄了220多个人体头部的4700多个高分辨率、高帧率的多视图视频,包含了各种丰富头部运动、情绪、表情和口语。
这个数据集同样由NPGA的作者团队发表于2023年,并被SIGGRAPH 2023和ACM TOG接收。

论文地址:https://tobias-kirschstein.github.io/nersemble/
温馨提示,想点进去看示例视频的话可能需要比较强大的心理素质,里面收录的各种夸张表情可以称之为人类抽象行为大赏。

去年刚发表数据集时,重建出来的动作和表情还比较僵硬,也没有丰富的面部细节。

短短一年时间就做到了如此逼真的效果,源于团队在方法上做出的改进。
方法概述
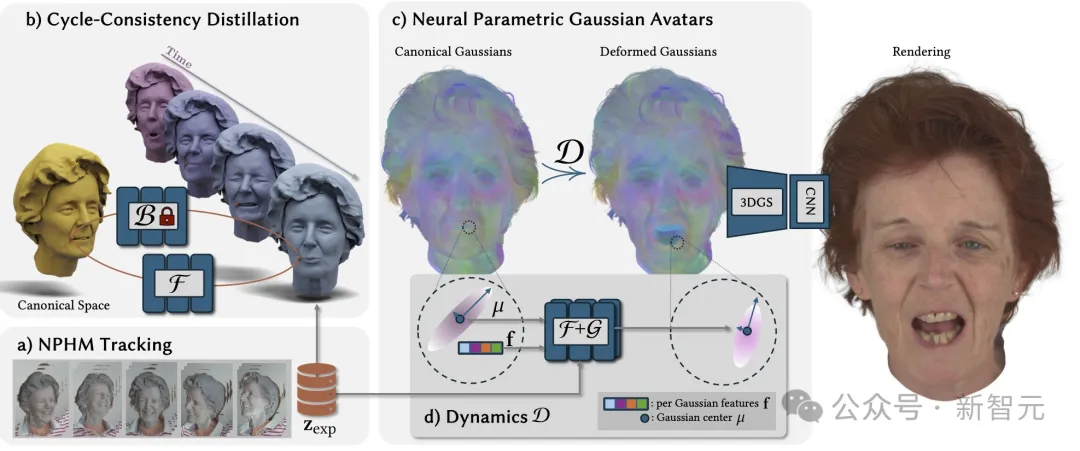
a) 以MonoNPHM模型为基础,在NeRSemble数据集上使用COLMAP计算的点云追踪MonoNPHM,从而实现几何精确的模型追踪。
b) 提出循环一致性目标来反转MonoNPHM的后向变形场,由此产生的前向变形场可以直接兼容基于光栅化的渲染。
c) NPGA由规范高斯点云和MLP组成,包含蒸馏过的先验网络F进行前向变形,以及网络G学习细粒度的动态细节。
d) 通过为每个基元(primitive)附加潜在特征,将变形场的输入提升到一个更高维的空间,从而可以更准确地描述每个基元的变形行为。
之前的头部重建工作大多会使用3D可形变模型(3D Morphable Model),使用主成分分析(PCA)学习人体几何图形的表示,将面部识别和表情变化的参数空间分开。
尽管3DMM的参数空间足够紧凑,但论文作者认为,其底层的线性本质限制了表达空间能够实现的保真度。
论文同时表示,底层表达空间对于虚拟人的质量有至关重要的作用,不仅影响可控性,而且决定细节清晰度的上限。如果底层的表达不充分,很有可能在优化模型时导致过拟合。
因此,团队使用了3DMM的改进版——NPHM(Neural Parametric Head Models,神经参数化头部模型),从多视角的图像序列中追踪并提取身份识别的隐向量z_id和表情代码z_exp。
之后,就可以用一个后向变形场B,将姿势空间中的点x_p转换为规范空间中的坐标x_c:
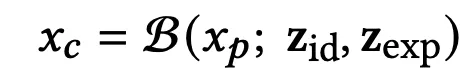
比较遗憾的是,这项研究只专注于重建头部,屏蔽了数据集中的躯干部分,因为没有包含在NPHM提取出的z_exp的表达空间内。
基于3DGS中的为每个基元定义的场景表示,作者额外添加了高斯特征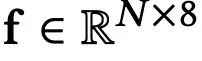 ,虽然它本身是一个静态特征,但可以为每个基元的动态行为提供语义信息,起到了一种类似于位置编码的作用。
,虽然它本身是一个静态特征,但可以为每个基元的动态行为提供语义信息,起到了一种类似于位置编码的作用。
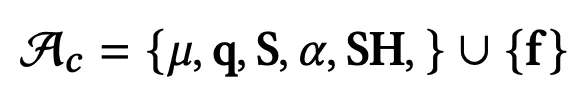
进行参数化表达后,论文提出的用于建模面部表情的动态模块D由2个多层感知器(MLP)组成:
- 基于粗略先验的网络F
- 超越先验知识、负责建模剩余细节的网络G
其中,模型F的训练和使用是这篇文章的核心创新之一。首先让F在NeRSemble数据集中20个人的图像序列上进行训练,之后会将这个网络运用在所有虚拟化身的重建中。
F的先验知识,则通过「循环一致性蒸馏」的方法,从后向变形场B中提取(实质上是B的逆元).
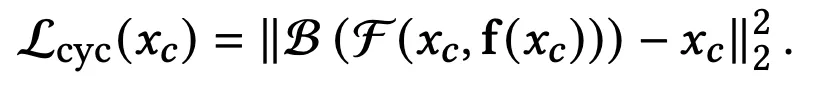
之后使用动态模型D,就可以得到重建的姿势空间中的高斯点云表示A_p:
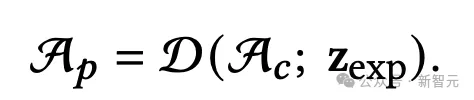
基于A_p完成屏幕空间的渲染后,团队还提出使用一个CNN网络提升潜在图像的细节表达,取代了用超分辨率处理。之后的消融实验也证明了CNN对性能提升的有效性。
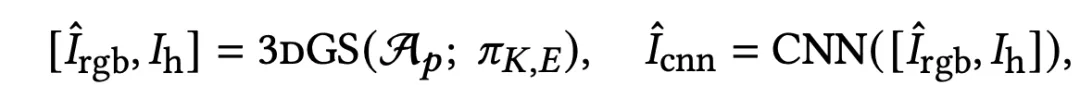
除了算法和架构的设计,团队也在优化策略上做了两处改进。
其一是对规范空间A_c与动态模型D进行基于KNN图算法的拉普拉斯平滑。
其二是自适应密度控制(Adaptive Density Control),这是3DGS成功的核心因素。使用启发式的方法,在静态场景下,对可能冗余的高斯点云密度进行剪枝处理。
实验评估
研究人员通过自我重现(Self-Reenactment)任务来评估NPGA算法的保真度。
自我重现会更准确地描绘出看不见的表情,并在头发区域等相对静态区域中,包含更清晰的细节。
有趣的是,GHA_NPHM的性能比GHA稍差,这表明仅使用MonoNPHM表达代码,并不能立即提升性能。

相反,研究人员假设如果没有NPHM的运动作为初始化,NPHM的潜在表达分布可能会,提供比BFM的线性混合形状更复杂的训练信号。
如下是,不同方法对保留序列的定性比较。

这些方法的定量结果如下。
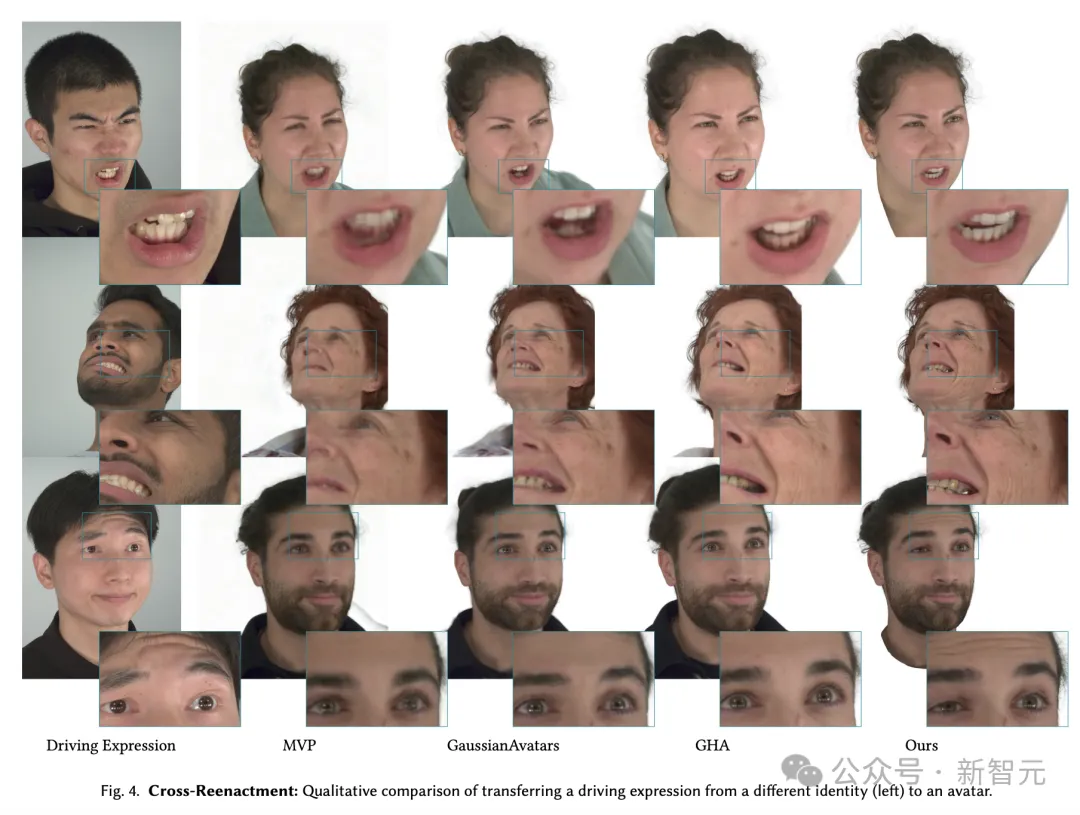
再来看,在交叉重现(cross-reenactment)任务中,全新算法的表现又如何?
交叉重现是指,将另一个人的表情转移到虚拟化身上。

如下图所示,所有的方法都成功将身份和表达信息分裂出来,从而实现了有效的交叉重现。
不过,NPGA的化身保留了更多驱动表情的大部分细节。
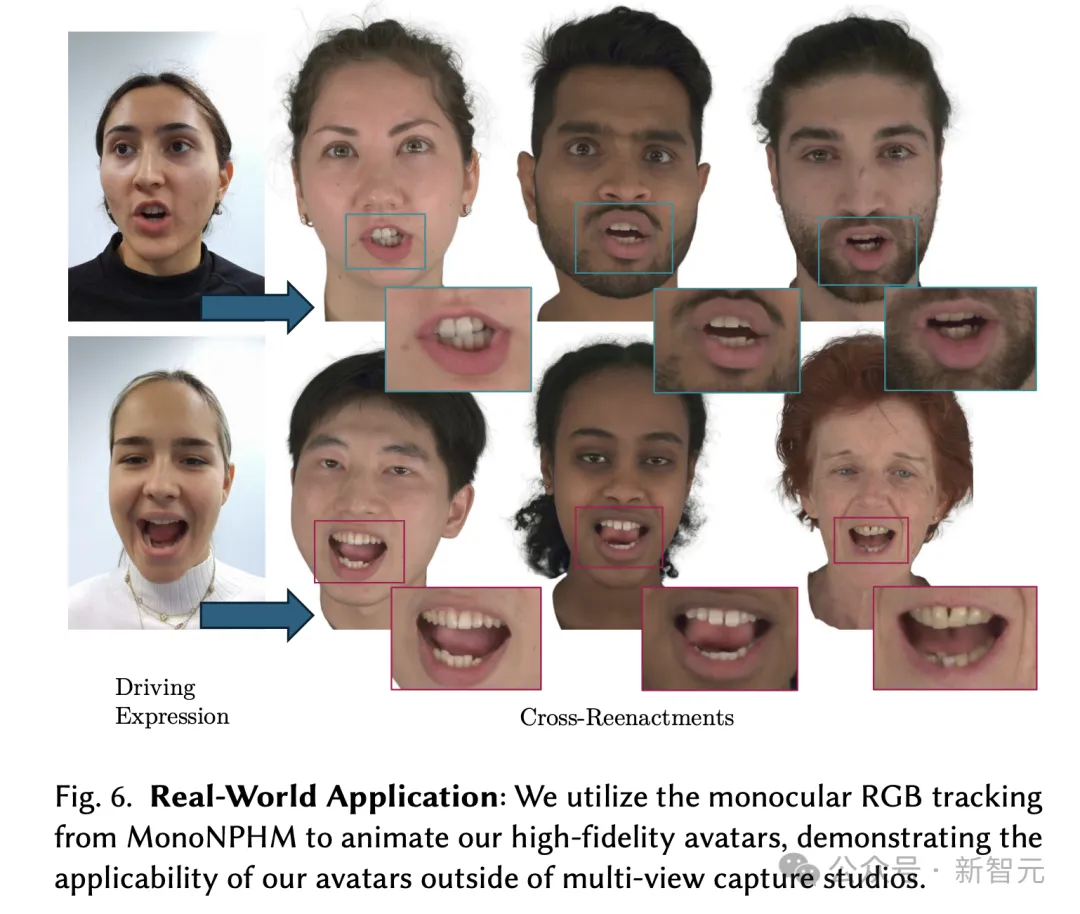
为了证明算法的现实世界适用性,图6显示了,研究人员利用MonoNPHM的单目RGB,来追踪高保真化身动画。
消融研究
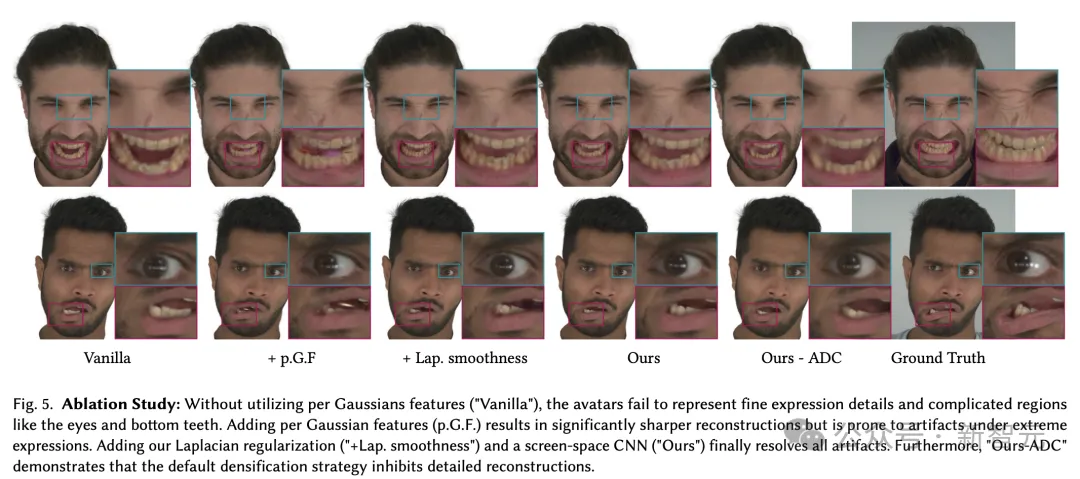
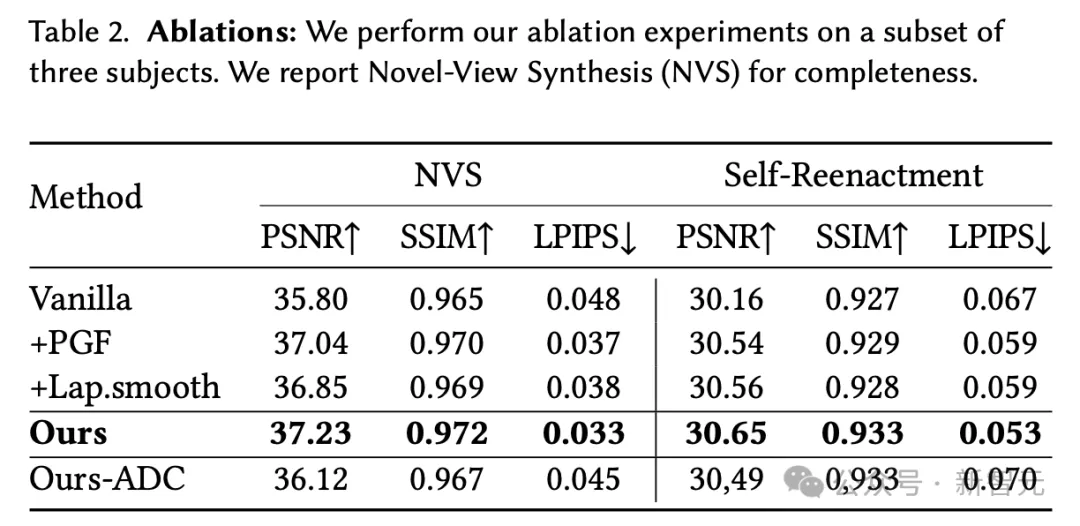
在最后的消融实验中,为了验证NPGA的几个重要组成部分,研究人员通过使用三个受试者进行了消融实验。消融的定量和定性结果分别见表2和图5。
如果不利用全高斯特征(Vanilla),3D头像就无法呈现出非常精细的表情,包括眼睛和下齿等复杂区域。
不过,在添加全高斯特征(p.G.F.)后,重建效果明显更清晰,但在极端表情下容易产生伪影。
当研究人员添加了拉普拉斯正则化和屏幕空间CNN,最终解决这一伪影问题。
此外,实验还证明了,默认的点云密集化策略,会抑制细节的重建,因此使用自适应密度控制(ADC)的策略非常必要。
下表说明了,使用正则化策略可以显著缩小训练序列(NVS)和测试序列(自我重现任务)之间的泛化差距。
局限性
研究人员表示,NPGA创建的虚拟化身的可控性、重建质量,从根本上讲,会受到底层3DMM表达空间的限制。
因此,包括颈部、躯干、舌头、眼珠旋转这些区域,无法用NPHM的表情代码来完全解释。
由此,算法无法可靠地进行动画处理,甚至可能因为过拟合而带来伪影。
目前可能的解决方案是,将底层3DMM扩展,提供对人类状态更详细的描述。
此外,NPGA作为一种数据驱动的头像创建方法,在一定程度上受限于可用的数据。
参考资料:
https://simongiebenhain.github.io/NPGA/
https://www.reddit.com/r/singularity/comments/1d41fgr/ngpa_new_high_quality_real_time_3d_avatar_from/
文章来源于“新智元”,作者“新智元”



【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
