# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
6 月 2 日,英伟达创始人黄仁勋在 Computex 2024(2024 台北国际电脑展)上发表主题演讲,分享了人工智能时代如何助推全球新产业革命,并且展示了最新的 Blackwell 芯片和后续的一系列更新节奏。
对于新发布的 Blackwell 芯片,老黄宣称这是「全世界迄今为止制造出来的最复杂、性能最高的计算机。」并且8 年内,1.8 万亿参数 GPT-4 的训练能耗,直接会降到 1/350;而推理能耗则直接降到 1/45000,老黄开始要打破「摩尔定律」了。

演讲开篇,老黄最先放出了一个Omniverse模拟世界中的演示。
他表示,「英伟达正处于计算机图形模拟和人工智能的交叉点上。这是我们的『灵魂』」。

这一切都是物理世界中的模拟,它的实现,得益于两项基本的技术——加速计算和人工智能,将重塑计算机产业。
到目前为止,计算机行业已有 60 多年的历史,而现在,一个全新的计算时代已然开始。
1964 年,IBM 的 System 360 首次引入了 CPU,通用计算通过操作系统将硬件和软件分离。架构兼容性、向后兼容性等等,所有我们今天所了解的技术,都是从这个时间点而来。
直到 1995 年,PC 革命开启让计算走进千家万户,更加民主化。2007 年,iPhone 推出直接把「电脑」装进了口袋,并实现了云端链接。
可以看出,过去60年里,我们见证了2-3个推动计算行业转变的重要技术节点。

而如今,我们将再一次见证历史。老黄表示,「有两个最基础的事情正发生」。
首先是处理器,性能扩展已经大大放缓,而我们所需的计算量、需要处理的数据都在呈指数级增长。
按老黄的话来说,我们正经历着「计算通货膨胀」。
过去的 20 年里,英伟达一直在研究加速计算。比如,CUDA 的出现加速了CPU 负载。事实上,专用的 GPU 效果会更好。

当我们运行一个应用程序,不希望是一个运行 100 秒,甚至是 100 个小时的APP。
因此,英伟达首创了异构计算,让 CPU 和 GPU 并行运行,将过去的 100 个时间单位,加速到仅需要 1 个时间单位。可见,它已经实现了 100 倍速率提升,而功耗仅增加的 3 倍,成本仅为原来的 1.5 倍。

英伟达同时为价值十亿美元的数据中心,配备了 5 亿美元的 GPU,让其变成了「AI工厂」。
有了加速计算,世界上许多公司可以节省数亿美元在云端处理数据。这也印证了老黄的「数学公式」,买得越多,省得越多。
除了 GPU,英伟达还做了业界难以企及的事,那就是重写软件,以加速硬件的运行。
如下图所示,从深度学习cuDNN、物理Modulus、通信Aerial RAN、基因序列Parabricks,到QC模拟cuQUANTUM、数据处理cuDF等领域,都有专用的CUDA软件。

也就是说,没有CUDA,就等同于计算机图形处理没有OpenGL,数据处理没有SQL。
而现在,采用CUDA的生态遍布世界各地。就在上周,谷歌宣布将cuDF加入谷歌云中,并加速世界上受欢迎的数据科学库Pandas。
而现在,只需要点击一下,就可以在CoLab中使用Pandas。就看这数据处理速度,简直快到令人难以置信。

老黄表示,要推行一个全新的平台是「蛋和鸡」的困境,开发者和用户,缺一不可。
但是经过20年的发展,CUDA已经打破了这个困境,通过全球500万开发者和无数领域的用户实现了良性循环。有越多人安装CUDA,运行的计算量越大,他们就越能据此改进性能,迭代出更高效、更节能的CUDA。

2012年,神经网络AlexNet的诞生,将英伟达第一次与AI联系起来。我们都知道,AI教父Hinton和高徒当时在2个英伟达GPU上完成AlexNet的训练。
深度学习就此开启,并以超乎想像的速度,扩展几十年前发明的算法。

但由于,神经网络架构不断scaling,对数据、计算量「胃口」愈加庞大,这就不得不需要英伟达重新发明一切。
2012年之后,英伟达改变了Tensor Core,并发明了NvLink,还有TensorRT、Triton推理服务器等等,以及DGX超算。
当时,英伟达的做法没有人理解,更没人愿意为之买单。
由此,2016年,老黄亲自将英伟达首个DGX超算送给了位于旧金山的一家「小公司」OpenAI。

从那之后,英伟达在不断扩展,从一台超算、到一个超大型数据中心。
直到,2017年Transformer架构诞生,需要更大的数据训练LLM,以识别和学习一段时间内连续发生的模式。

之后,英伟达建造了更大的超算。2022年11月,在英伟达数万个GPU上完成训练的ChatGPT横空出世,能够像人类一样交互。
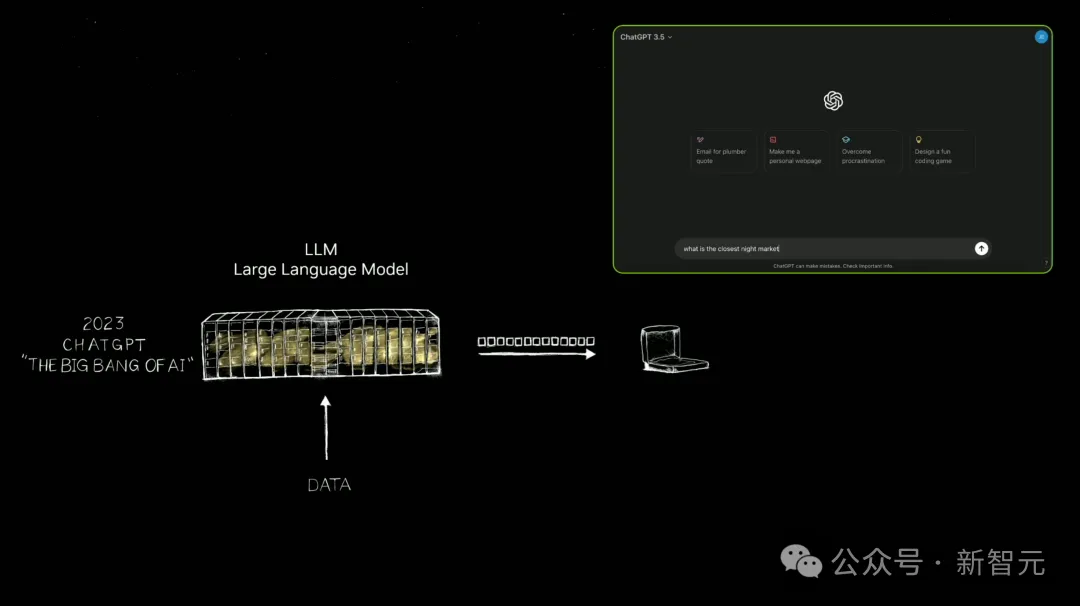
这是世界第一次看到了生成式AI。它会一次输出一个token,可以是图像、语音、文字、视频,甚至是天气token,全部都是关于生成。
老黄表示,「我们可以学习的一切,现在都可以生成。我们现在已经进入了一个全新的生成式AI时代」。
当初,那个作为超算出现的计算机,已经变成了数据中心。它可以输出token,摇身一变成为了「AI工厂」。
而这个「AI工厂」,正在创造和生产巨大价值的东西。
19世纪90年代末,尼古拉·特斯拉发明了AC Generator,而现在,英伟达正创造可以输出token的AI Generator。
英伟达给世界带来的是,加速计算正引领新一轮产业革命。人类首次实现了,仅靠3万亿美元的IT产业,创造出能够直接服务于100万亿美元产业的一切东西。

传统的软件工厂,到如今AI工厂的转变,实现了CPU到GPU,检索到生成,指令到大模型,工具到技能的升级。
可见,生成式AI推动了全栈的重塑。
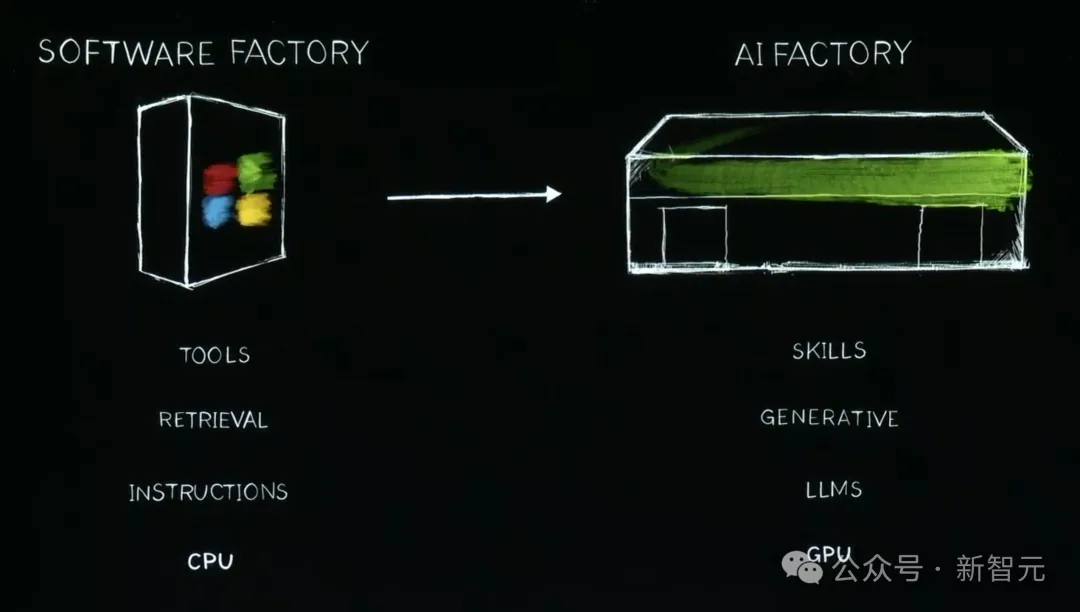
接下来就让我们看看,英伟达是如何将一颗颗地表最强的Blackwell芯片,变成一座座超级「AI工厂」的。



注意看,下面这块是搭载了Blackwell GPU的量产级主板。
老黄手指的这里是Grace CPU。

而在这里,我们可以清晰地看到,两个连在一起的Blackwell芯片。

在8年里,每一代英伟达芯片的Flops,都增长了1000倍。
与此同时,摩尔定律在这8年里,却似乎逐渐失效了。

即使和摩尔定律最好的时刻相比,Blackwell算力的提升也是惊人的。这将直接导致的结果,就是成本的显著下降。
比如,训练一个1.8万亿参数、8万亿token的GPT-4所用的能耗,直接降至1/350!
Pascal需要消耗的,是1000吉瓦时,这就意味着,它需要一个1000吉瓦的数据中心。(1吉瓦=1000兆瓦)
而且如果这样的数据中心真的存在的话,训练也GPT-4也需要整整一个月的时间。而100兆瓦的数据中心,大概需要一年。这也就是为什么,ChatGPT这样的LLM, 在八年前是根本不可能存在的。
如今有了Blackwell,过去的1000吉瓦时直接可以降到3吉瓦时。
可以说,Blackwell就是为了推理,为了生成token而生的。它直接将每token的能量降低了45000倍。
在以前,用Pascal产生1个token的消耗,相当于两个200瓦的灯泡运行2天。让GPT-4生成一个单词,大概需要3个token。这根本不可能让我们得到如今和GPT-4聊天的体验。
而现在,我们每个token可以只使用0.4焦耳,用很少的能量,就能产生惊人的token。

它诞生的背景,正是运算模型规模的指数级增长。
每一次指数级增长,都进入一种崭新的阶段。
当我们从DGX扩展到大型AI超算,Transformer可以在大规模数据集上训练。
而下一代AI,则需要理解物理世界。然而如今大多数AI并不理解物理规律。其中一种解决办法,是让AI学习视频资料,另一种,则是合成数据。
第三种,则是让计算机互相学习!本质上就和AlphaGo的原理一样。

巨量的计算需求涌来,如何解决?目前的办法就是——我们需要更大的GPU。
而Blackwell,正是为此而生。

Blackwell中,有几项重要的技术创新。
第一项,就是芯片的尺寸。
英伟达将两块目前能造出来的最大尺寸的芯片,用一条10TB/s的链路链接起来;然后再把它们放到同一个计算节点上,和一块Grace CPU相连。
在训练时,它被用于快速检查点;而在推理和生成的场景,它可以用于储存上下文内存。
而且,这种第二代GPU还有高度的安全性,我们在使用时完全可以要求服务器保护AI不受偷窃或篡改。
并且,Blackwell中采用的是第5代NVLink。它是第一代可信赖、可使用的引擎,通过该系统,我们可以测试每一个晶体管、触发器、片上内存和片外内存,因此我们可以当场确定某个芯片是否出现故障。
基于此,英伟达将拥有十万个GPU超算的故障间隔时间,缩短到了以分钟为单位。
因此,如果我们不发明技术来提高超算的可靠性,那么它就不可能长期运行,也不可能训练出可以运行数月的模型。
如果提高可靠性,就会提高模型正常的运行时间,而后者显然会直接影响成本。
最后,老黄表示,解压缩引擎的数据处理,也是英伟达必须做的最重要的事之一。
通过增加数据压缩引擎、解压缩引擎,就能以20倍的速度从存储中提取数据,比现在的速度要快得多。
Blackwell是一个重大的跃进,但对老黄来说,这还不够大。
英伟达不仅要做芯片,还要制造搭载最先进芯片的服务器。拥有Blackwell的DGX超算,在各方面都实现了能力跃升。

集成了Blackwell芯片的最新DGX,能耗仅比上一代Hopper提升了10倍,但FLOPS量级却提升了45倍。
下面这个风冷的DGX Blackwell,里面有8个GPU。

而对应散热器的尺寸也很惊人,达到了15kW,并且是完全的风冷。

如果你喜欢部署液冷系统呢?英伟达也有新型号MGX。
单个MGX同时集成72个Blackwell GPU,且有最新的第五代NVLink每秒130TB的传输速度。NVLink将这些单独的GPU彼此连接起来,因此我们就得到了72个GPU的MGX
介绍完芯片,老黄特意提到了英伟达研发的NVLink技术,这也是英伟达的主板可以越做越大的重要原因。
由于LLM参数越来越多、越来越消耗内存,想要把模型塞进单个GPU已经几乎是不可能的事情,必需搭建集群。其中,GPU通信技术的重要性不亚于计算能力。
英伟达的NVLink,是世界上最先进的GPU互连技术,数据传输速率可以堪称疯狂!
因为如今的DGX拥有72个GPU,而上一代只有8个,让GPU数直接增加了9倍。而带宽量,则直接增加了18倍,AI FLops增加了45倍,但功率仅仅增加了10倍,也即100千瓦。
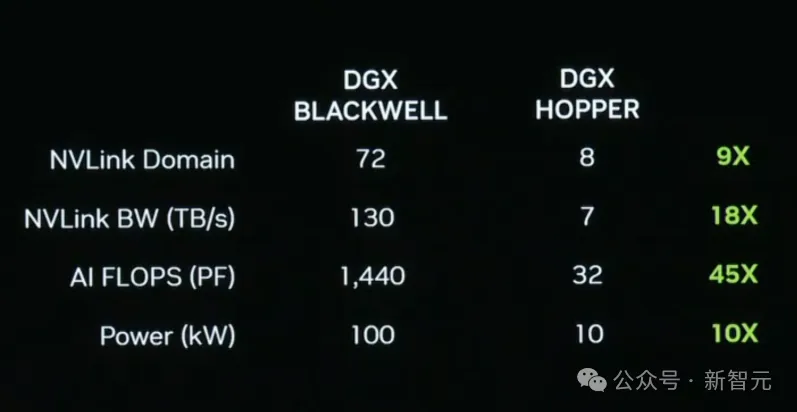
下面这个NVLink芯片,也堪称是奇迹。
人们之所以意识到它的重要性,是因为它将所有这些不同的GPU连接在一起,从而能够让十万亿参数的LLM运行起来。
500亿个晶体管,74个端口,每个端口400GB,7.2TB每秒的横截面带宽,这本身就是个奇迹。
而更重要的是,NVLink内部还具有数学功能,可以实现归约。对于芯片上的深度学习,这尤其重要。

有趣的是,NVLink技术,大大拓宽了我们对于GPU的想象。
比如在传统的概念中,GPU应该长成这样。

但有了NVLink,GPU也可以变成这么大。

支撑着72个GPU的骨架,就是NVLink的5000根电缆,能够在传输方面节省20kw的功耗用于芯片计算。

老黄拿在手里的,是一个NVLink的主干,用老黄的原话说,它是一个「电气机械奇迹」
NVLink做到的仅仅是将不同GPU芯片连接在一起,于是老黄又说了一句「这还不够宏大」。要连接超算中心内不同的主机,最先进的技术是「无限带宽」(InfiniBand)。但很多数据中心的基础设施和生态,都是基于曾经使用的以太网构建的,推倒重来的成本过高。
因此,为了帮助更多的数据中心顺利迈进AI时代,英伟达研发了一系列与AI超算适配的以太交换机。
网络级RDMA、阻塞控制、适应性路由、噪声隔离,英伟达利用自己在这四项技术上的顶尖地位,将以太网改造成了适合GPU之间点对点通信的网络。

由此也意味着,数百万GPU数据中心的时代,即将到来。

在英伟达的AI工厂中,运行着可以加速计算推理的新型软件——NIM。

老黄表示,「我们创建的是容器里的AI」。
这个容器里有大量的软件,其中包括用于推理服务的Triton推理服务器、优化的AI模型、云原生堆栈等等。

现场,老黄再一次展示了全能AI模型——可以实现全模态互通。有了NIM,这一切都不是问题。
它可以提供一种简单、标准化的方式,将生成式AI添加到应用程序中,大大提高开发者的生产力。

现在,全球2800万开发者都可以下载NIM到自己的数据中心,托管使用。未来,不再耗费数周的时间,开发者们可以在几分钟内,轻松构建生成式AI应用程序。
与此同时,NIM还支持Meta Llama 3-8B,可以在加速基础设施上生成多达3倍的token。这样一来,企业可以使用相同的计算资源,生成更多的响应。而基于NIM打造的各类应用,也将迸发涌现,包括数字人、智能体、数字孪生等等。

老黄表示,「NVIDIA NIM集成到各个平台中,开发人员可以随处访问,随处运行 —— 正在帮助技术行业使生成式 AI 触手可及」。
而智能体,是未来最重要的应用。老黄称,几乎每个行业都需要客服智能体,有着万亿美元的市场前景。
可以看到,在NIM容器之上,大多数智能体负责推理,去弄清任务并将其分解成多个子任务。还有一些,它们负责检索信息、搜索,甚至是使用工具等。
所有智能体,组成了一个team。未来,每家公司都将有大量的NIM智能体,通过连接起来组成一个团队,完成不可能的任务。
在人机交互这方面,老黄和Sam Altman可以说是想到一起了。他表示,虽然可以使用文字或语音形式的prompt给AI下达指令,但很多应用中,我们还是需要更自然的、更类人的交互方式。
这指向了老黄的一个愿景——数字人。相比现在的LLM,它们可以更吸引人,更有同理心。
GPT-4o虽是实现了无法比拟的类人交互,但缺少的是一个「躯体」。而这次,老黄都帮OpenAI想好了。
未来,品牌大使也不一定是「真人」,AI完全可以胜任。从客户服务,到广告、游戏等各行各业,数字人带来的可能将是无限的。

连接Gen AI的CG技术,还可以实时渲染出逼真的人类面部。
低延迟的数字人处理,遍及全球超过100个地区。

这是由英伟达ACE提供的魔力,能够为创建栩栩如生的数字人,提供相应的AI工具。现在,英伟达计划在1亿台RTX AI个人电脑和笔记本电脑上,部署ACE PC NIM微服务。

这其中包括英伟达首个小语言模型——Nemotron-3 4.5B,专为在设备上运行而设计,具备与云端LLM相似的精度和准确性。

此外,ACE数字人类AI新套件还包括基于音轨生成身体手势——NVIDIA Audio2Gesture,即将推出。
老黄表示,「数字人类将彻底改变各个行业,ACE提供的多模态LLM和神经图形学的突破,使我们更接近意图驱动计算的未来,与计算机的交互将如同与人类的交互一样自然」。
Hopper和Blackwell系列的推出,标志着英伟达逐渐搭建起完整的AI超算技术栈,包括CPU、GPU芯片,NVLink的GPU通信技术,以及NIC和交换机组成的服务器网络。
如果你愿意的话,可以让整个数据中心都使用英伟达的技术。这足够大、足够全栈了吧。但是老黄表示,我们的迭代速度还要加快,才能跟上GenAI的更新速度。
英伟达在不久前就曾放出消息,即将把GPU的迭代速度从原来的两年一次调整为一年一次,要用最快的速度推进所有技术的边界。
今天的演讲中,老黄再次实锤官宣GPU年更。但是他又紧跟着叠了个甲,说自己可能会后悔。
无论如何,我们现在知道了,英伟达不久后就会推出Blackwell Ultra,以及明年的下一代的Rubin系列。

除了芯片和超算服务器,老黄还发布了一个所有人都没有想到的项目——数字孪生地球「Earth-2」。
这也许是世界范围内最有雄心的项目(甚至没有之一)。
而且根据老黄的口吻推测,Earth-2已经推进了数年,今年取得的重大突破才让他觉得,是时候亮出来了。
为什么要为建造整个地球的数字孪生?是要像小扎的元宇宙那样,把社交和互动都搬到线上平台吗?
不,老黄的愿景更宏伟一些。他希望在Earth-2的模拟,可以预测整个星球的未来,从而帮我们更好地应对气候变化和各种极端天气,比如可以预测台风的登陆点。

Earth-2结合了生成式AI模型CorrDiff,基于WRF数值模拟进行训练,能以12倍更高的解析度生成天气模型,从25公里范围提高到2公里。
不仅解析度更高,而且相比物理模拟的运行速度提高了1000倍,能源效率提高了3000倍,因此可以在服务器上持续运行、实时预测。
而且,Earth-2的下一步还要将预测精度从2公里提升到数十米,同时考虑城市内的基础设施,甚至可以预测到街道上什么时候会刮来强风。

而且,英伟达想数字孪生的,不止是地球,还有整个物理世界。
对于这个狂飙突进的AI时代,老黄大胆预测了下一波浪潮——物理AI,或者说是具身AI。

它们不仅需要有超高的认知能力,可以理解人类、理解物理世界,还要有极致的行动力,完成各种现实任务。
想象一下这个赛博朋克的未来:一群机器人在一起,像人类一样交流、协作,在工厂里创造出更多的机器人。而且,不仅仅是机器人。一切能移动的物体都会是自主的!

在多模态AI的驱动下,它们可以学习、感知世界,理解人类指令,并进化出计划、导航以及动作技能,完成各种复杂任务。
那要怎样训练这些机器人呢?如果让他们在现实世界横冲直撞,代价要比训练LLM大得多。这时,数字孪生世界就大有用武之地了。

正像LLM可以通过RLHF进行价值观对齐一样,机器人也可以在遵循物理规律的数字孪生世界中不断试错、学习,模仿人类行为,最终达到通用智能。
Nvidia的Omniverse可以作为构建数字孪生的平台,集成Gen AI模型、物理模拟以及动态实时的渲染技术,成为「机器人健身房」。

志在做全栈的英伟达也不仅仅满足于操作系统。他们还会提供用于训练模型的超算,以及用于运行模型的Jetson Thor和Orin。
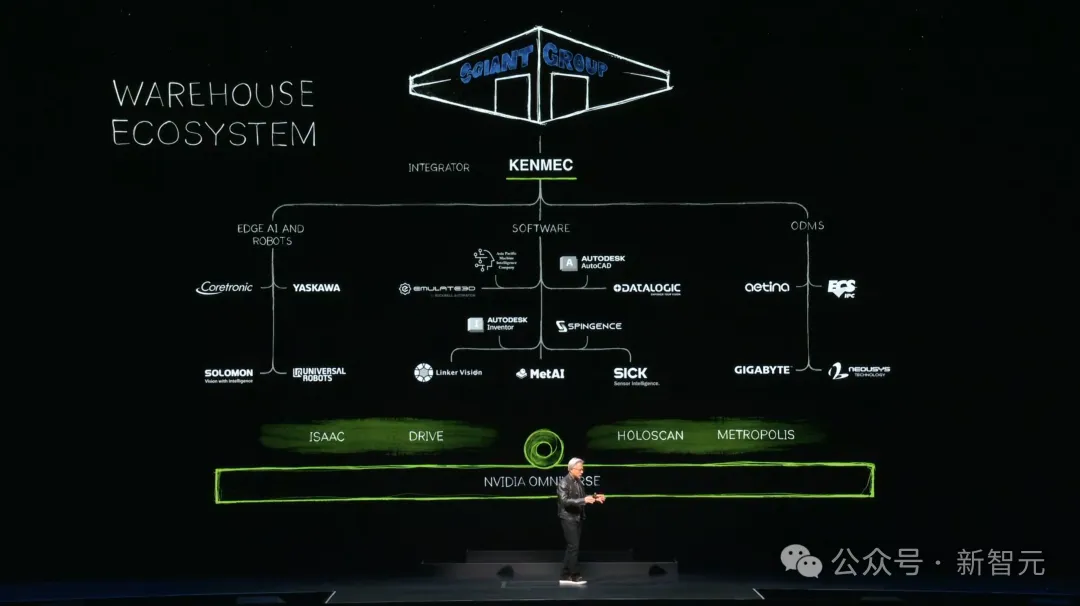
为了适应不同应用场景下的机器人系统,英伟达的Omniverse将逐步扩展为Warehouse生态系统。这个生态将无所不包,从搭配应用程序的SDK和API,到运行边缘AI计算的接口,再到最底层的可定制芯片。
在全栈产品方面,英伟达就是想要做自己的「全家桶」,让别人无路可走。
为了让这个 AI 机器人时代看起来更真实,演示的最后,9 个和老黄有同样身高的机器人再一次一同登场。

正如老黄所说的,「这不是未来,这一切都正在发生」。
参考资料:
https://www.nvidia.cn/events/computex/?ncid=so-wech-642406
文章来自于微信公众号新智元,作者新智元



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】Fay开源数字人框架是一个AI数字人项目,该项目可以帮你实现“线上线下的数字人销售员”,
“一个人机交互的数字人助理”或者是一个一个可以自主决策、主动联系管理员的智能体数字人。
项目地址:https://github.com/xszyou/Fay
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
