# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
黄志恒拥有爱丁堡大学博士和加州大学伯克利博士后研究经历。志恒曾在微软、百度、Facebook、腾讯和亚马逊等 IT 公司工作。志恒在亚马逊 AWS 担任首席科学家领导了 Amazon Kendra 和 Amazon Q。志恒现在是 Denser.ai 的创始人。截至 2024 年 5 月,Google Scholar 引用次数超过 13,300 次。
李万钧是一位资深全栈工程师,同时具备设计师和运维工程师的专长。他曾在多个大型项目中担任核心工程师和架构师,拥有丰富的实战经验。目前在 denser.ai 担任全栈工程师,专注于将 AI 技术深度融合到软件开发的各个阶段。
检索增强生成 (RAG) 是将检索模型与生成模型结合起来,以提高生成内容的质量和相关性的一种有效的方法。RAG 的核心思想是利用大量文档或知识库来获取相关信息。各种工具支持 RAG,包括 Langchain 和 LlamaIndex。
AI Retriever 是 RAG 框架的基础,确保 AI 应用中的准确和无缝体验。Retriever 大致分为两类:关键词搜索和向量搜索。关键词搜索依赖于关键词匹配,而向量搜索则关注语义相似性。流行的工具包括用于关键词搜索的 Elasticsearch 和用于向量搜索的 Milvus、Chroma 和 Pinecone。
在大语言模型时代,从工程师和科学家到市场营销等各个领域的专业人士,都热衷于开发 RAG AI 应用原型。像 Langchain 这样的工具对此过程至关重要。例如,用户可以使用 Langhian 和 Chroma 快速构建一个用于法律文档分析的 RAG 应用。
本文中,DenserAI 团队推出的 Denser Retriever 在快速原型设计方面表现突出。用户可以通过一个简单的 Docker Compose 命令快速安装 Denser Retriever 及其所需工具。Denser Retriever 不仅仅止步于此,它还提供了自托管解决方案,支持企业级生产环境的部署。
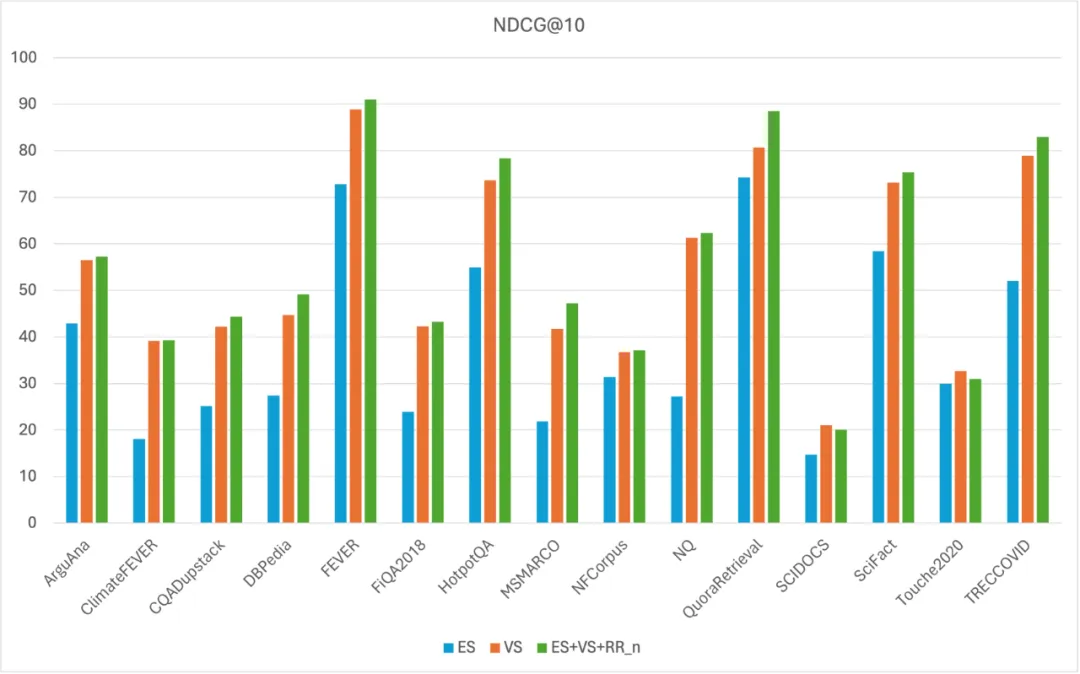
此外,Denser Retriever 在 MTEB 检索数据集上提供了全面的检索基准测试,以确保部署中的最高准确性。用户不仅可以享受 Denser Retriever 的易用性,还可以享受其最先进的准确性。

Denser Retriever 的初始版本提供了以下功能:
在这篇博客中,我们将展示如何安装 Denser Retriever,从文本文件或网页页面构建检索索引,并在此索引上进行查询。
由于篇幅限制,本文不会涵盖更多高级主题,如使用自定义数据集训练 Denser Retriever、在 MTEB 基准数据集上进行评估以及创建端到端 AI 应用(如聊天机器人)。有兴趣的用户可参考以下资源获取这些高级主题的信息。
安装 Denser Retriever
我们使用 Poetry 安装和管理 Denser Retriever 包。在仓库根目录下使用以下命令安装 Denser Retriever。

更多细节可以在 DEVELOPMENT 文档中找到:https://github.com/denser-org/denser-retriever/blob/main/DEVELOPMENT.md
运行 Denser Retriever 需要 Elasticsearch 和 Milvus,它们分别支持关键词搜索和向量搜索。我们按照以下指示在本地计算机(例如,您的笔记本电脑)上安装 Elasticsearch 和 Milvus。
要求:docker 和 docker compose,它们都包含在 Docker Desktop 中,适用于 Mac 或 Windows 用户。



在索引和查询用例中,用户提供一组文档,如文本文件或网页,以构建检索器。然后用户可以查询该检索器以从提供的文档中获取相关结果。此用例的代码可在 index_and_query_from_docs.py 中找到。
代码地址:https://github.com/denser-org/denser-retriever/blob/main/experiments/index_and_query_from_docs.py
要运行此示例,请导航到 denser-retriever 仓库并执行以下命令:

如果运行成功,我们预期会看到类似以下的输出。

在接下来的部分中,我们将解释其中的基础过程和机制。
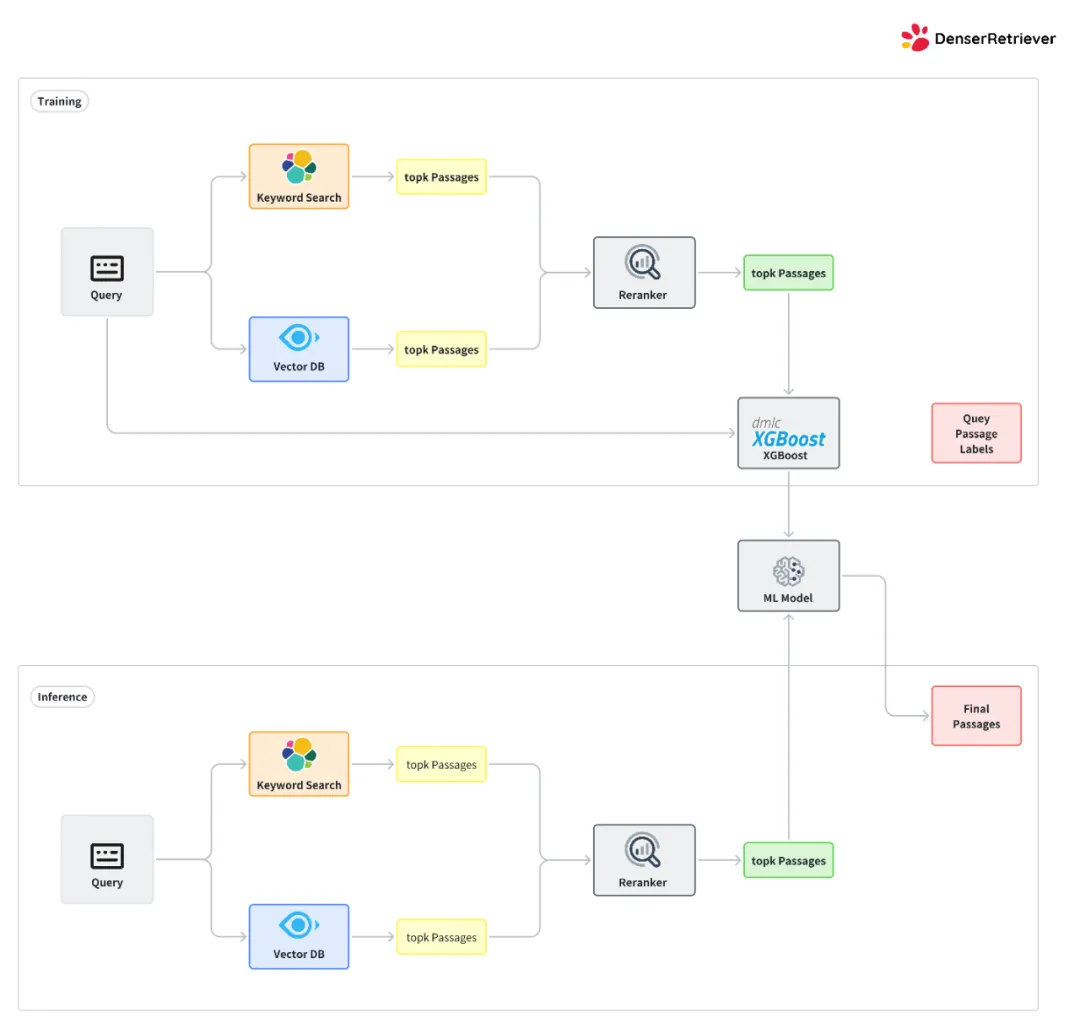
下图说明了 Denser Retriever 的结构,它由三个组件组成:
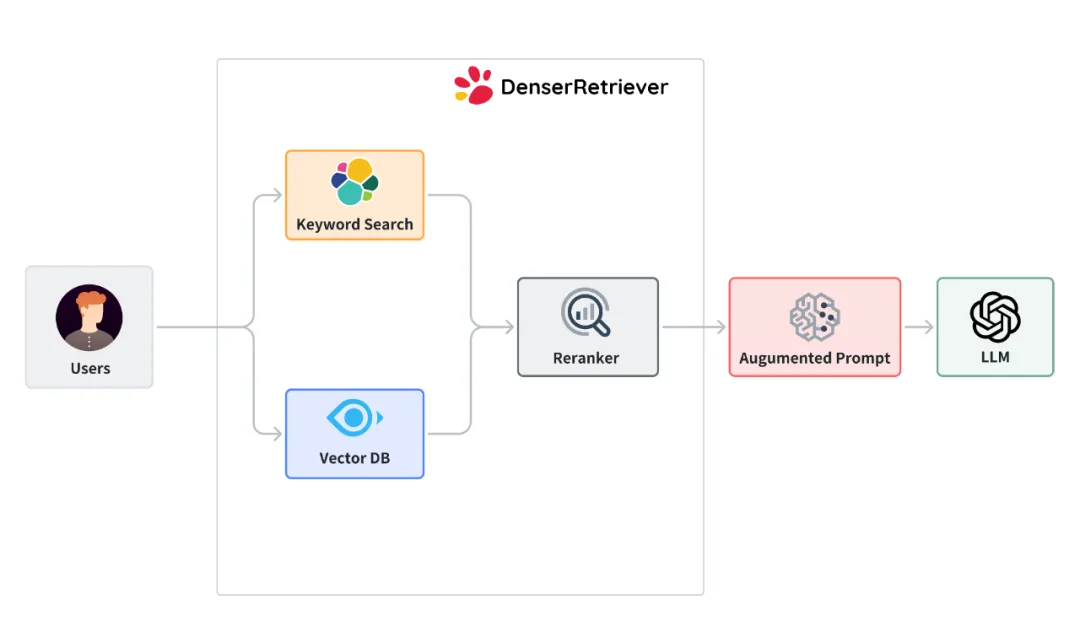
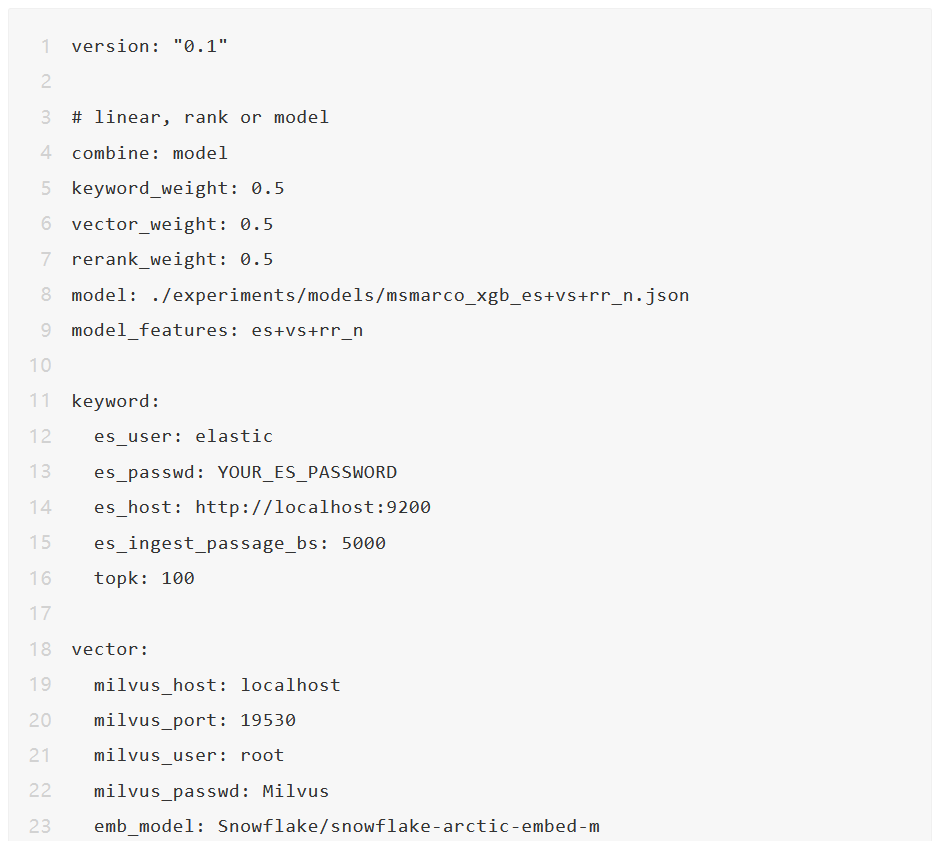
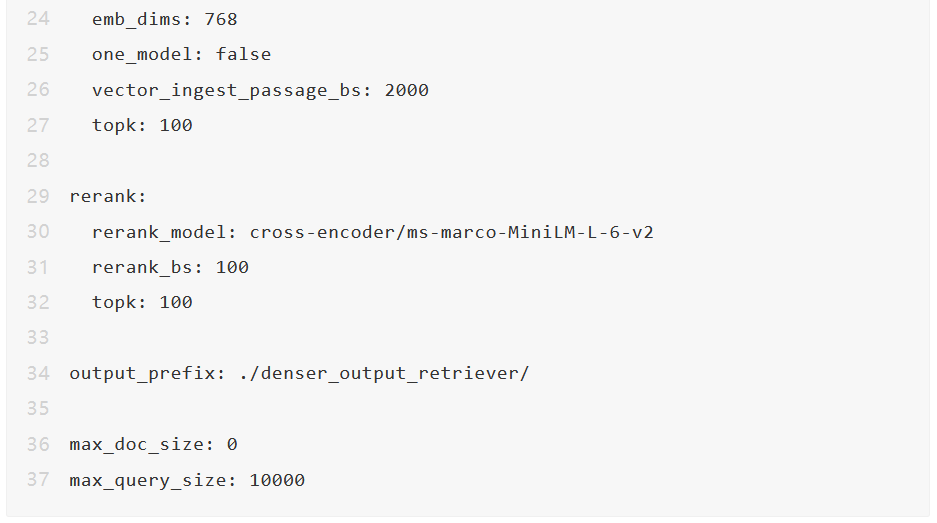
我们在以下 yam 文件中配置上述三个组件。大多数参数是不言自明的。关键字、向量、重排序的部分分别配置 Elasticsearch、Milvus 和重排序器。
我们使用 combine: model 通过一个 xgboost 模型(experiments/models/msmarco_xgb_es+vs+rr_n.json)来结合 Elasticsearch、Milvus 和重排序器,该模型是使用 mteb msmarco 数据集训练的(参见训练配方了解如何训练这样的模型)。
除了模型组合,我们还可以使用线性或排名来结合 Elasticsearch、Milvus 和重排序器。在 MTEB 数据集上的实验表明,模型组合可以显著提高准确性,优于线性或排名方法。
一些参数,例如 es_ingest_passage_bs,仅在训练 xgboost 模型时使用(即查询阶段不需要)。
我们现在描述如何从给定的文本文件(state_of_the_union.txt)构建一个检索器。以下代码显示如何读取文本文件,将文件分割成文本块并将其保存为 jsonl 文件(passages.jsonl)。
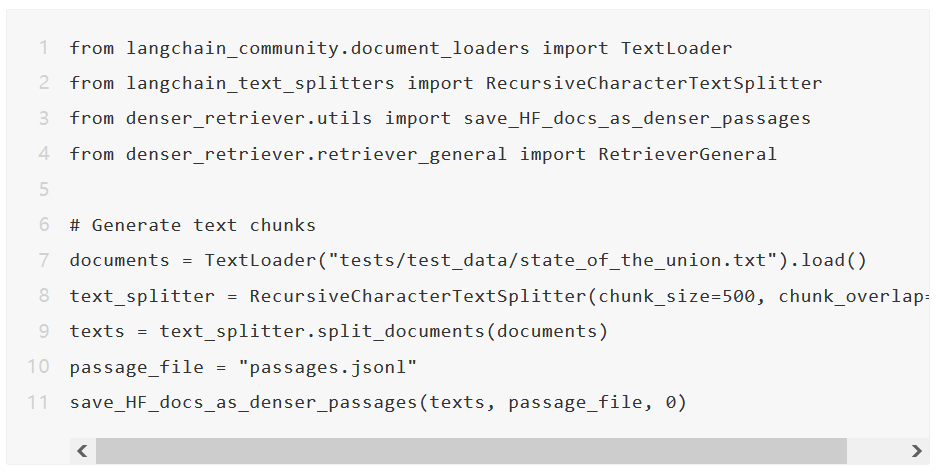
passages.jsonl 中的每一行都是一个段落,包含 source、title、text 和 pid(段落 ID)字段。
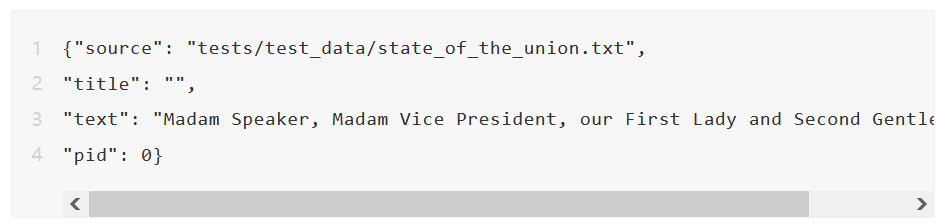
我们可以使用给定的 passages.jsonl 和 experiments/config_local.yaml 配置文件来构建 Denser 检索器。

我们可以简单地使用以下代码来查询检索器以获得相关段落。

每个返回的段落都会接收一个置信分数,以指示它与给定查询的相关性。我们得到类似以下的结果。

我们将所有代码整合如下。代码也可在 repo 中找到。

与上述方法类似,除了段落语料库的生成。index_and_query_from_webpage.py 源代码可以在这里找到。
要运行这个用例,请进入 denser-retriever repo 并运行:

poetry run python experiments/index_and_query_from_webpage.py
如果成功,我们预计会看到类似以下的内容。
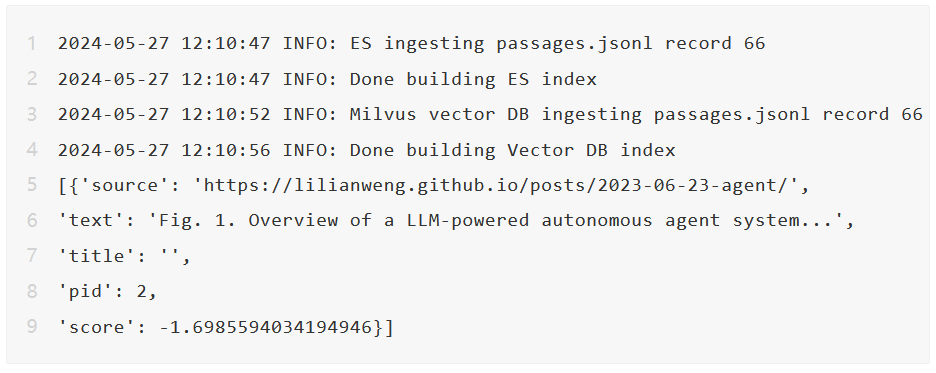
由于篇幅限制,我们在这篇博客中未包括以下主题。

Denser Retriever文档:https://retriever.denser.ai/docs
文章来自于微信公众号 “机器之心”,作者 “AIxiv专栏”



【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
