# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
极限量化,把每个参数占用空间压缩到1.1bit!
IEEE Spectrum专栏,一种名为BiLLM的训练后量化(PTQ)方法火了。
通俗来讲,随着LLM参数规模越来越大,模型计算的内存和资源也面临着更大的挑战。如何把模型变得小巧经济实惠,能塞进手机等设备中?
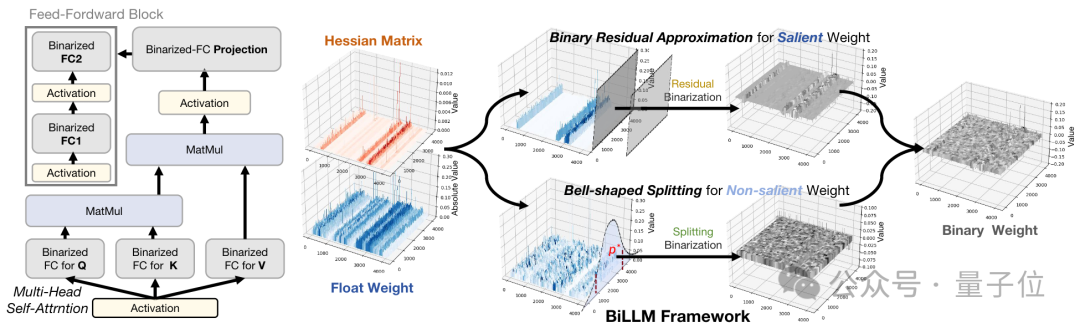
BiLLM解决的正是这样的一个问题。它使用1bit来近似网络中的大多数参数,使用2bit来表示一些对性能最有影响的权重。
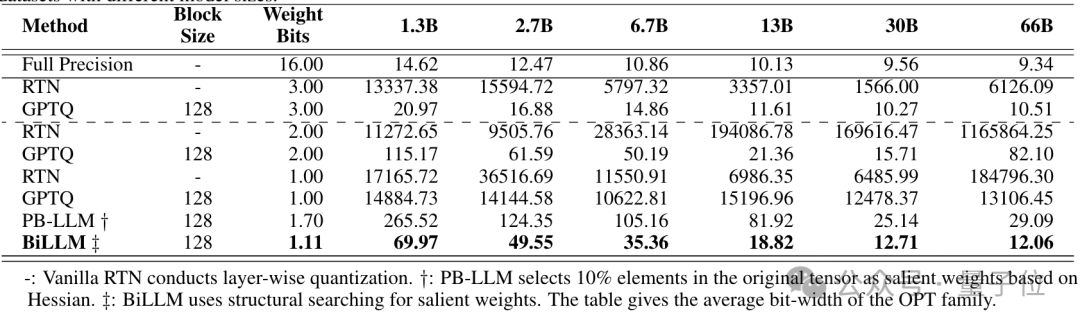
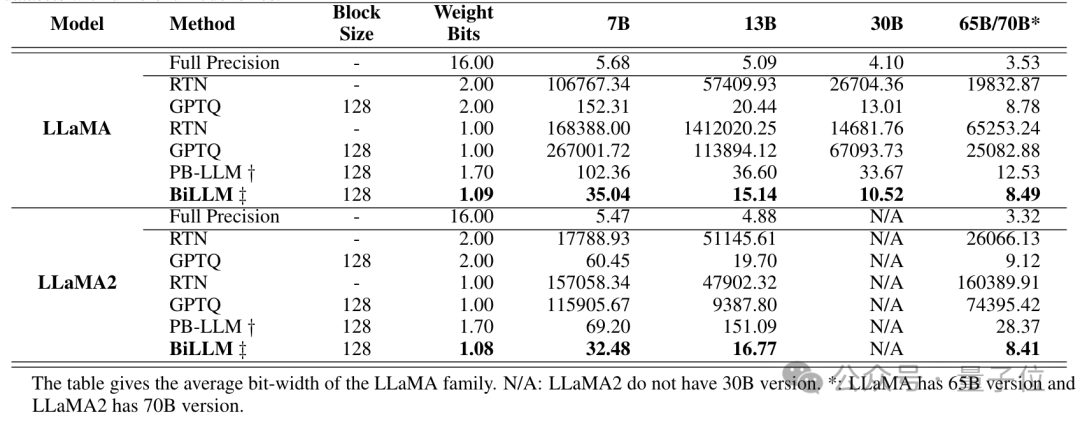
实验测试中,研究人员对OPT模型、Llama系列进行了二值化。
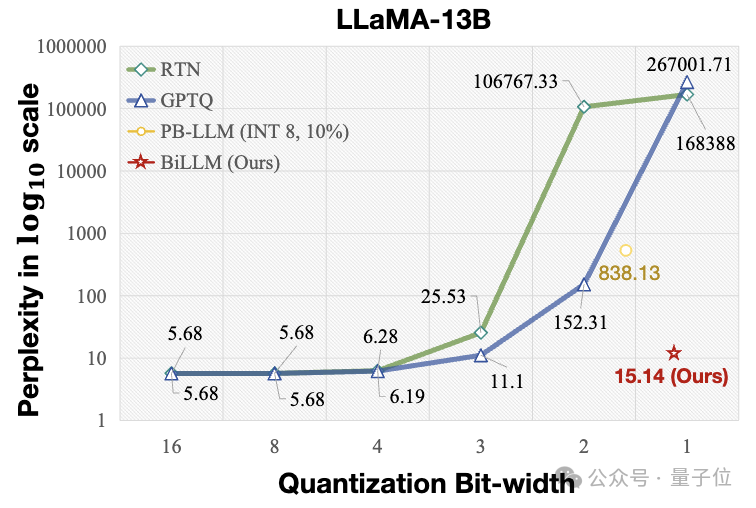
在OPT模型家族上,BiLLM以1.1bit的平均权重大小实现了目前最极限的LLM训练后压缩;在Llama系列模型上,BiLLM在1.08bit下的表现甚至超过了使用全精度的OPT-66B模型。
效率方面,BiLLM能够在单个GPU上半小时内完成7B LLM的二值化。
BiLLM发布当天,便引发了网友对大模型优化的热议,有网友就表示:
量化不是没有代价。Llama3模型的量化效果比Llama2模型要差,量化过程中的质量损失更大。
直觉是,一个训练不足的模型受到量化的影响较小,因为其训练过程并没有充分利用每一个权重。关于Llama的一个关键发现,以及它为何能在其大小范围内表现出色,是因为它们在比文献中所谓的“最佳”状态更大的数据集上训练了更长时间。
综合这些因素,似乎可以得出以下结论:小型模型、大量数据、长时间训练>大型模型+量化。基本上,量化是一种用于缩短长时间训练的损失性的捷径。数据的数量和质量,一如既往是所有这些中最重要。

这项研究由香港大学、苏黎世联邦理工学院、北京航空航天大学联合推出,目前已被ICML 2024接收。

量子位也联系到了作者,给大伙儿解读一下。
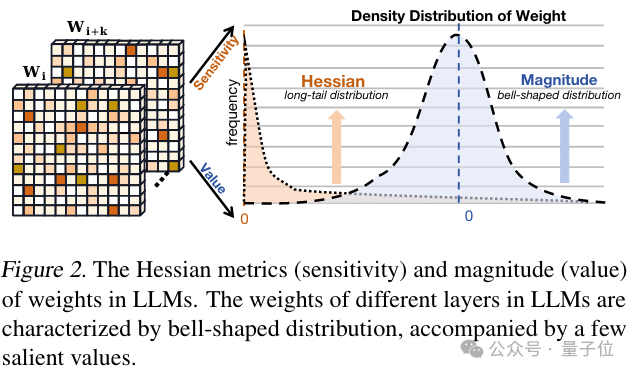
为了应对超低位宽下大语言模型的能力崩溃问题,研究人员对多个预训练大语言模型的权重和其Hessian矩阵(损失的二阶梯度)分布情况进行了初步研究,得到以下观察:
首先,研究人员发现大语言模型的Hessian矩阵表现出极端的长尾分布特性。
这也意味着大多数位置权重的变化对模型的输入输出并不敏感,而少部分元素对于权重的输出非常敏感。
其次,大语言模型中的权重密度遵循不均匀的钟形分布形式。
这种钟形分布在特征方面与高斯分布或拉普拉斯分布非常相似,即大多数权重集中在0附近,整体呈现非均匀的钟形分布。
上述观察表明大多数权重在LLM当中是冗余的,而少部分权重发挥着极其重要的作用;同时,在极端的二值化压缩场景下,这种非均匀钟形分布会产生更大的量化误差。
对此,研究人员对少部分显著权重和大部分非显著权重分别提出了二阶残差逼近和最优钟形分组方法进行量化,在1.1bit的权重下首次实现了LLM的性能保证。
研究人员发现,显著权重往往积聚在特定的通道当中。
因此, BiLLM采用一种通道级别的分组方式来区分显著权重和非显著权重。这种结构化划分相比于非结构化处理引入的开销可以忽略不计,对硬件部署十分友好。
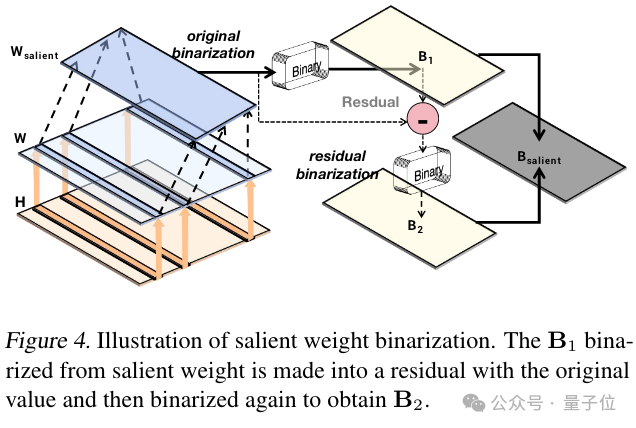
由于显著权重的重要性,先前工作往往直接将这部分权重保存为原精度或量化到8-bit来保证LLM的性能。然而,这种方式会导致整体位宽的增加。
为此,研究人员开发了一种用二值化残差逼近方法作用于显著通道的权重。
这一方法通过直接二值化和残差二值化有效降低了显著权重的极端量化误差。与直接保留显着权值为16位或者8位相比,该方法仅通过2位开销存储显着权值,同时有效保护了权重中的重要元素。
由于显着通道数量极低,剩余的大部分权重仍然保持着钟形分布。
同时,在排除显着权重影响的情况下变得更加对称。由于二进制量化代表均匀量化的极端形式,直接将钟形分布下的权重舍入到二值权重会带来巨大的的量化误差。
因此研究人员对这部分权重采用了分组二值化的方式,通过自动搜索策略寻找最优的分割点。
此外,研究结果表明,尽管非显着权重并非理想的高斯分布或拉普拉斯分布,但搜索函数的误差曲线仍然表现出凸性,证实了最佳分割点的存在。
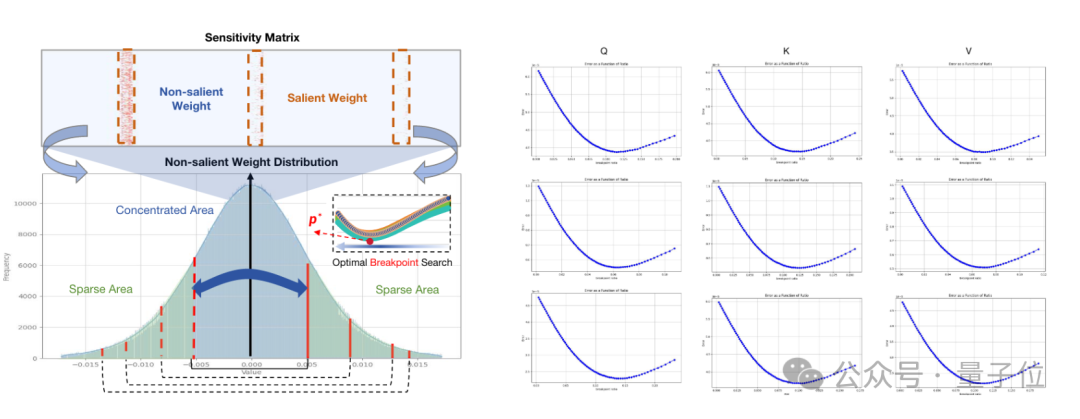
同时由于外侧分组的数值方差较大,搜索中总是以较小的比例出现(0.5%~3%)。可以进一步采用稀疏行压缩的策略来进行分组标识,进一步提升细粒度分组方案下的硬件友好性。
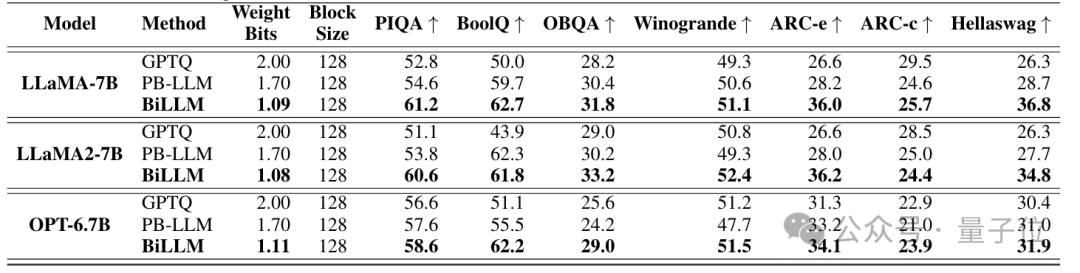
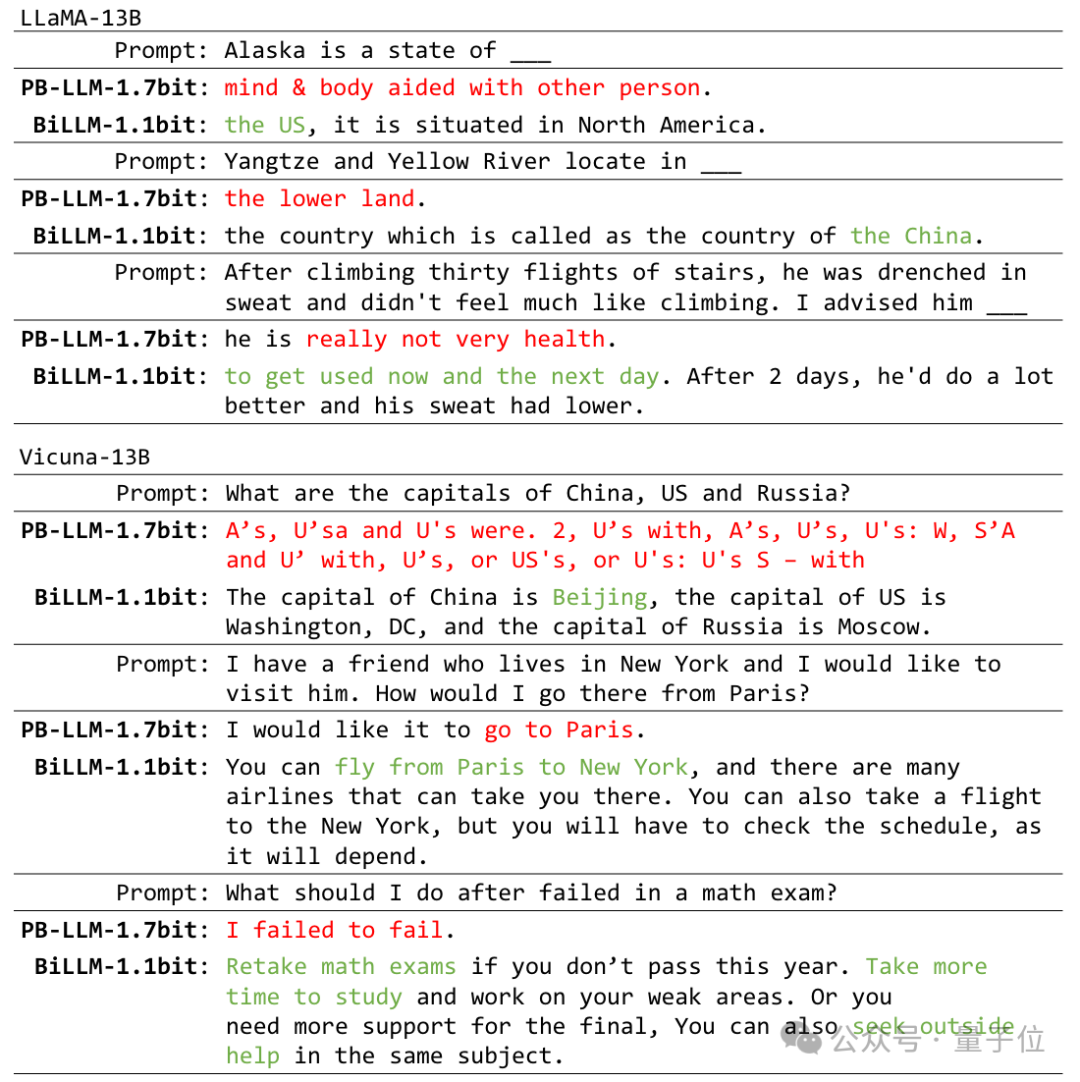
研究团队在OPT和Llama系列模型上验证了BiLLM性能。此外,考虑到LLM通常需要基于指令进行微调以适应不同的应用环境,实验还报告了Vicuna-7B和Vicuna-13B的量化结果。
BiLLM在平均1.1bit权重时,在多个评价指标上实现了超过GPTQ,PB-LLM等方法在2-bit时的性能,同时在部分模型体积上接近3-bit权重的性能。
结果表明, BiLLM 率先在接近1位的平均比特率下实现了LLM性能保证,推动了LLM无训练量化的边界。
BiLLM在Llama-13B和Vicuna-7B上实现了更好对话效果。
文章来源于“量子位”,作者“关注前沿科技”




【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
