# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
拯救4bit扩散模型精度,仅需时间特征维护——以超低精度量化技术重塑图像内容生成!
近日,北航、莫纳什、UT Austin联合推出了时间特征维护的扩散模型低精度无损量化方法TFMQ-DM。
不仅以4bit的权重大小实现了目前无损条件下最极限的扩散模型训练后压缩,同时还实现了超过2.38倍真实硬件加速。
这一发现再次将Diffusion压缩推向全新的高度。
目前,该工作已被CVPR 2024高分接收,并被接收为Highlight Poster (Top 2.8%)。

论文地址:https://arxiv.org/pdf/2311.16503
代码地址:https://github.com/ModelTC/TFMQ-DM
扩散模型由于引入了时间变量t,于是在模型中注入了时序信息,这正是扩散模型不同于以往传统视觉模型的一大特征。
同时该变量也通过将时序特征融入模型去控制去噪过程。研究人员首次定义了时间特征emb,同时发现现有量化算法对于这些特征将产生严重扰动,从而破坏图片生成质量:
1. 时间特征扰动:研究人员发现量化导致了明显的时间特征误差,并将这种特征错误内的扰动现象称为时间特征扰动;
2. 时间信息失配:时间特征扰动改变了原始嵌入的时间信息。具体来说,旨在对应于时间步长。然而,由于存在显著的误差,量化模型的不再准确地与相关联,倾向于与对应的时间特征更为接近,这导致了该方法所说的时间信息不匹配;
3. 去噪轨迹偏离:时间信息不匹配传递了错误的时间信息,因此导致图像在去噪轨迹中对应的时间位置发生了偏差,最终导致图片不再按原轨迹去噪:
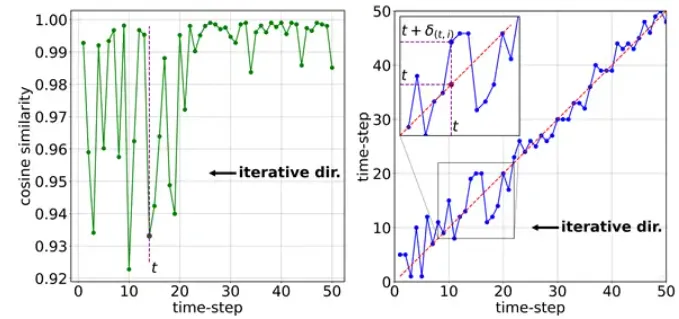

(Diffusion中的时间特征扰动)
研究人员发现该扰动主要由以下两个原因造成:
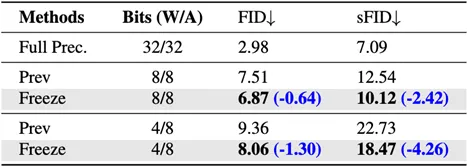
1. 不合适的重建对象:已有量化重建方法并未直接优化时间特征,同时时间特征将会受到有限的校准数据影响产生过拟合现象,如下图Prev所示,其中Freeze代表冻结相关量化参数;
2. 忽略了时间特征相关模块中的有限激活:由于输入是有限整数,因此产生时间特征的模块将仅产生有限且随时间变化的激活,而已有量化策略均考虑分布层级优化,忽略了对于此类有限激活的拟合近似。
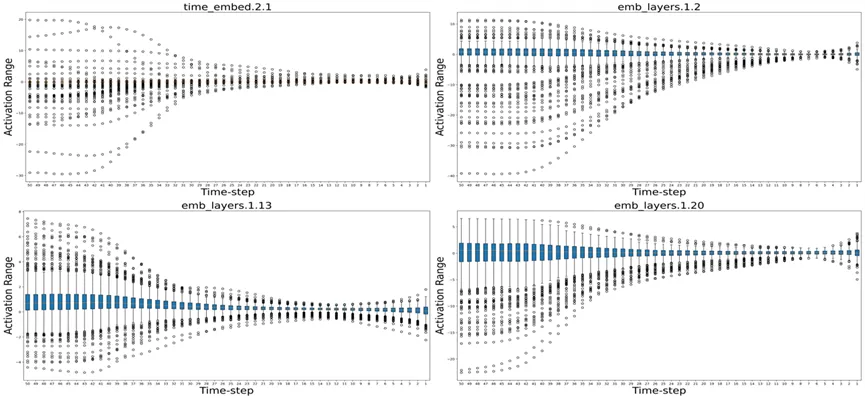
(Diffusion中时间特征相关模块有限激活)
基于以上的诱因分析研究人员提出了如下时间特征维护策略,在低bit量化下完美的保证了Diffusion模型的时间特征精度与图像生成质量。
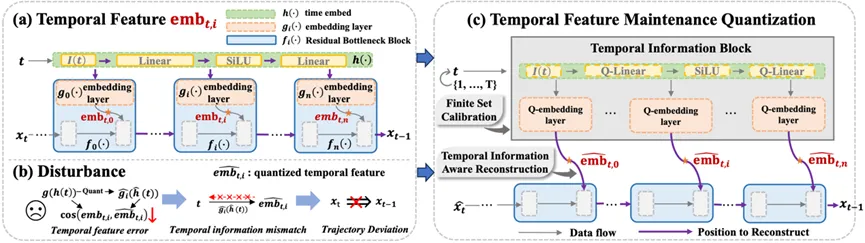
(TFMQDM整体压缩框架)
1. 时间信息块:将时间特征生成相关模块进行整合得到时间信息块(见框架图):
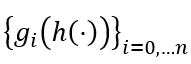
2. 时间信息感知重建:基于时间信息块,研究人员提出了时间信息感知重建 (TIAR) 来应对第一个诱因。在重构过程中,该块的优化目标如下:
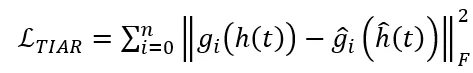
3. 有限集校准:为了解决第二个诱因中有限集内激活范围宽泛的挑战,研究人员提出了有限集校准 (FSC) 用于激活量化。这个策略为所有时间信息块内的每个激活使用T组量化参数,例如激活x的量化参数可为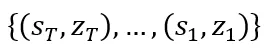 。在时间步长为t时,x的量化函数可以表示为:
。在时间步长为t时,x的量化函数可以表示为:
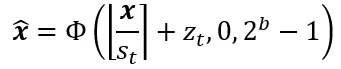
其中sT, zt分别为量化缩放因子和零偏移。
研究团队在DDIM,LDM以及Stable Diffusion系列模型上验证了无条件生成、分类条件生成、文本条件以及多种先进采样器生成下TFMQ-DM框架性能。
TFMQ-DM在平均4或8 bit权重,8或32 bit激活时,所有评价指标均超过Q-Diffusion,PTQD等已有最先进方法,且在大部分场景下,该方案使用4bit权重量化超越了已有技术在8-bit权重甚至于全精度权重的模型的性能。
结果表明,TFMQ-DM率先在4bit权重、8bit权重下实现了对于 Diffusion的无损压缩加速,推动了Diffusion无训练量化的边界。
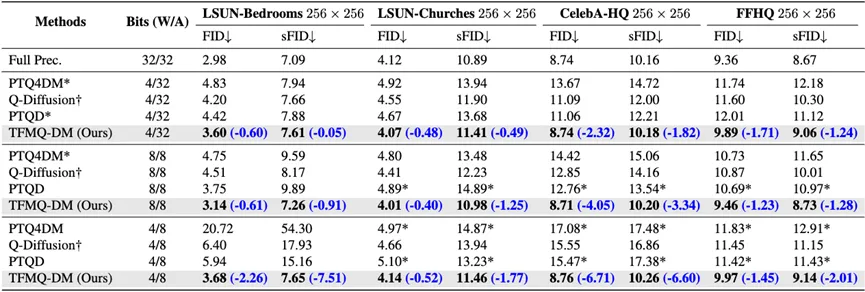
(LDM系列无条件生成对比结果)
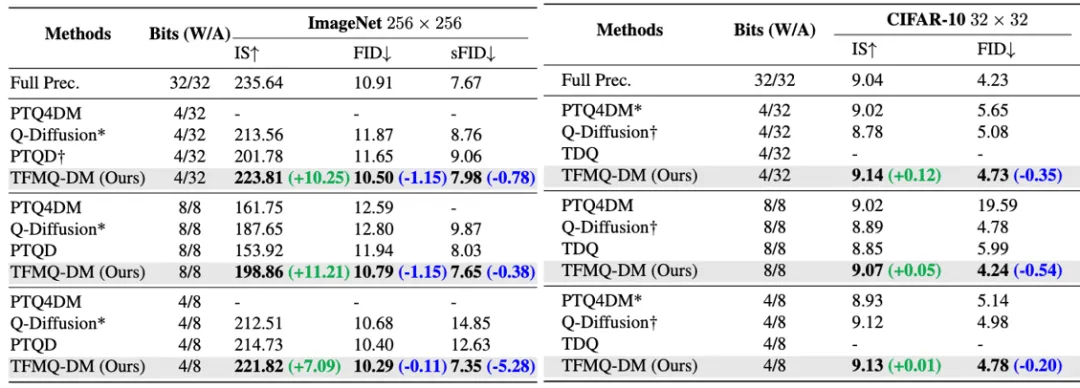
(左:LDM系列分类条件生成对比结果;右:DDIM系列无条件生成对比结果)
具体来说,在 CelebA-HQ 256 × 256 数据集上,与当前最先进的方法相比,该团队的方法在 w4a8 设置下将FID与sFID分别降低了 6.71和 6.60(越低越好)。
值得注意的是,现有方法,无论是4 bit还是8bit权重量化,在人脸数据集如 CelebA-HQ 256 × 256 和 FFHQ 256 × 256 上与 FP 模型相比都显示出明显的性能下降,而 TFMQ-DM 与全精度模型相比几乎没有性能损失。
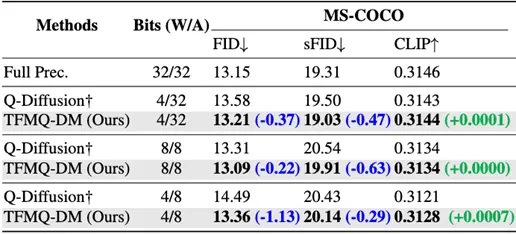
(Stable Diffusion系列文本条件生成对比结果)

(左:PLMS系列先进采样器无条件生成对比结果右:DPM++系列先进采样器无条件生成对比结果)
此外,对于当下最流行的文本条件生成类模型Stable Diffusion,TFMQ-DM在 w8a8 设置下的 FID 和在 w4a32 设置下的 sFID 甚至略低于全精度模型。
然而,虽然现有的指标无法充分评估生成图像的语义一致性以及物体细节,该团队提出的方法产生了更高质量的图像(见后文),具有更真实的细节,更好地展示了语义信息。
由于现有指标并不能完全反映生成图像效果的优劣,该团队研究人员提供了大量可视化效果对比图,体现出更加细腻和准确的生成质量:

(LDM上无条件图像生成效果图)

(LDM上分类条件图像生成效果图)

(Stable Diffusion上文本条件图像生成效果图,左提示词:“A digital illustration of the Babel tower, detailed, trending in artstation, fantasy vivid colors”。右提示词:“A beautiful castle beside a waterfall in the woods”。)
除测试集精度和可视化效果外,团队人员还在Intel® Xeon® Gold 6248R 处理器上验证框架的推理加速效果,相比原始浮点模型实现了 2.38 倍的显著速度提升。
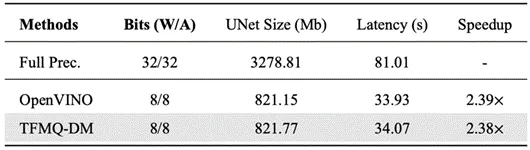
(Stable Diffusion在CPU上真实加速)
基于时间特征维护的校准量化可确保 Diffusion的量化参数准确保留原始时间信息。广泛的实验证明,TFMQ-DM 在 DDIM、LDM及Stable-Diffusion 系列中实现了令人信服的精度提升,尤其是在w4a8等极低比特设置下表现出了明显优势;同时该方案也实现了真实硬件部署加速。
其次TFMQ-DM 具有良好的兼容性,可与各种Diffusion量化框架无缝集成。总的来说,TFMQ-DM 提供的显著量化精度提升与其对于硬件的高度友好,有助于在资源受限的情况下进行实际部署,进一步促进了文生图模型的更广泛普及和应用。
TFMQ-DM 具有显著的兼容性,可与各种Diffusion量化框架无缝集成。TFMQ-DM 提供的显著量化精度,有助于在资源受限的情况下进行实际部署。
参考资料:
https://arxiv.org/pdf/2311.16503
文章来自于微信公众号 “新智元”,作者 “LRST 好困”




【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
