# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
DynRefer 通过模拟人类视觉认知过程,显著提升了区域级多模态识别能力。通过引入人眼的动态分辨率机制,DynRefer 能够以单个模型同时完成区域识别、区域属性检测和区域字幕生成(region-level captioning)任务,并在上述任务都取得 SOTA 性能。其中在 RefCOCOg 数据集的 region-level captioning 任务上取得了 115.7 CIDEr,显著高于 RegionGPT,GlaMM,Osprey,Alpha-CLIP 等 CVPR 2024 的方法。


区域级多模态任务致力于将指定的图像区域转换为符合人类偏好的语言描述。人类完成区域级多模态任务时具有一种分辨率自适应能力,即关注区域是高分辨率的,非关注区域是低分辨率的。然而,目前的区域级多模态大语言模型往往采用固定分辨率编码的方案,即对整张图像进行编码,然后通过 RoI Align 将区域特征提取出来。这种做法缺乏人类视觉认知系统中的分辨率自适应能力,对关注区域的编码效率和能力较低。为了实现高精度的区域级多模态理解,我们提出了一种动态分辨率方案来模拟人类视觉认知系统,如下图所示。
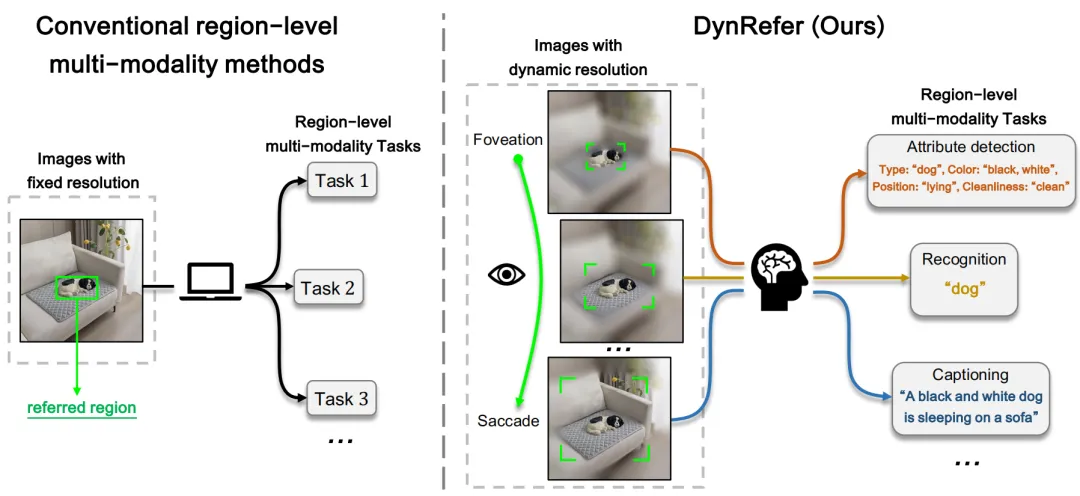
图 1:传统的区域级多模态方法(左)与 DynRefer 方法(右)的比较。

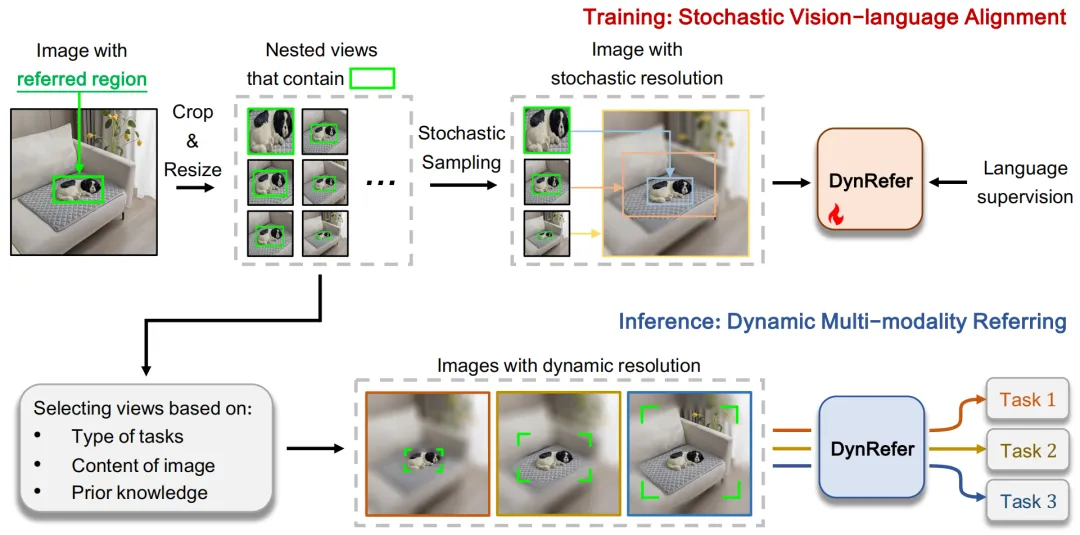
图 2:DynRefer 训练(上)与 推理(下)。

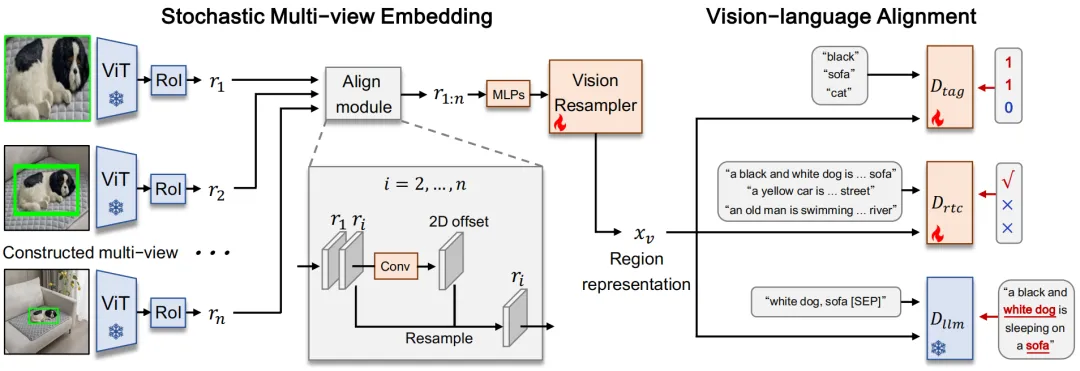
图 3:DynRefer 网络结构

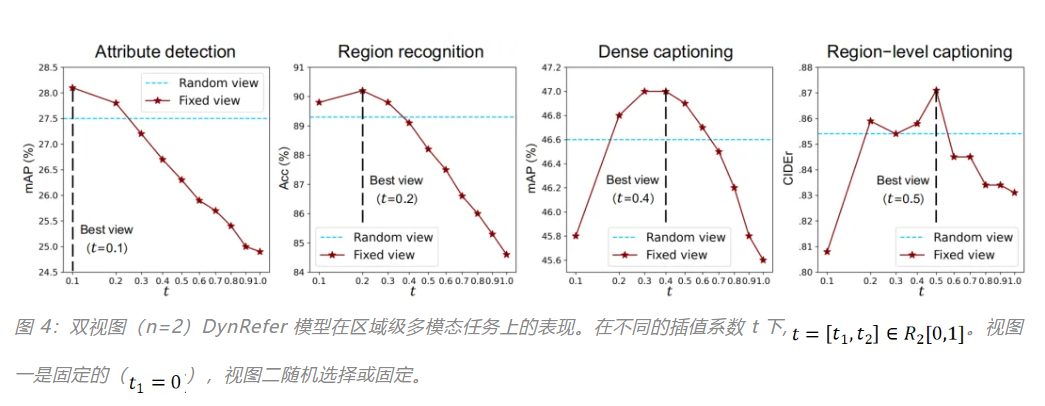

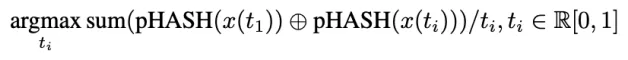

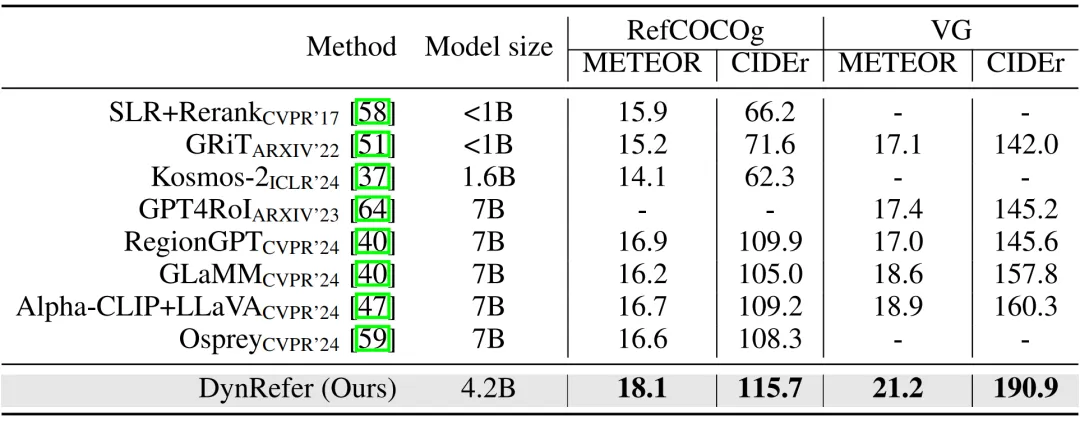
在区域字幕生成任务,DynRefer 以更小的模型(4.2B v.s. 7B),在 RefCOCOg 和 VG 两个数据集上、在 METEOR 和 CIDEr 两个指标上都显著超过了 CVPR 2024 中的众多方法,如 RegionGPT,GlaMM,Alpha-CLIP 和 Osprey 等,展现出 DynRefer 巨大的性能优势。
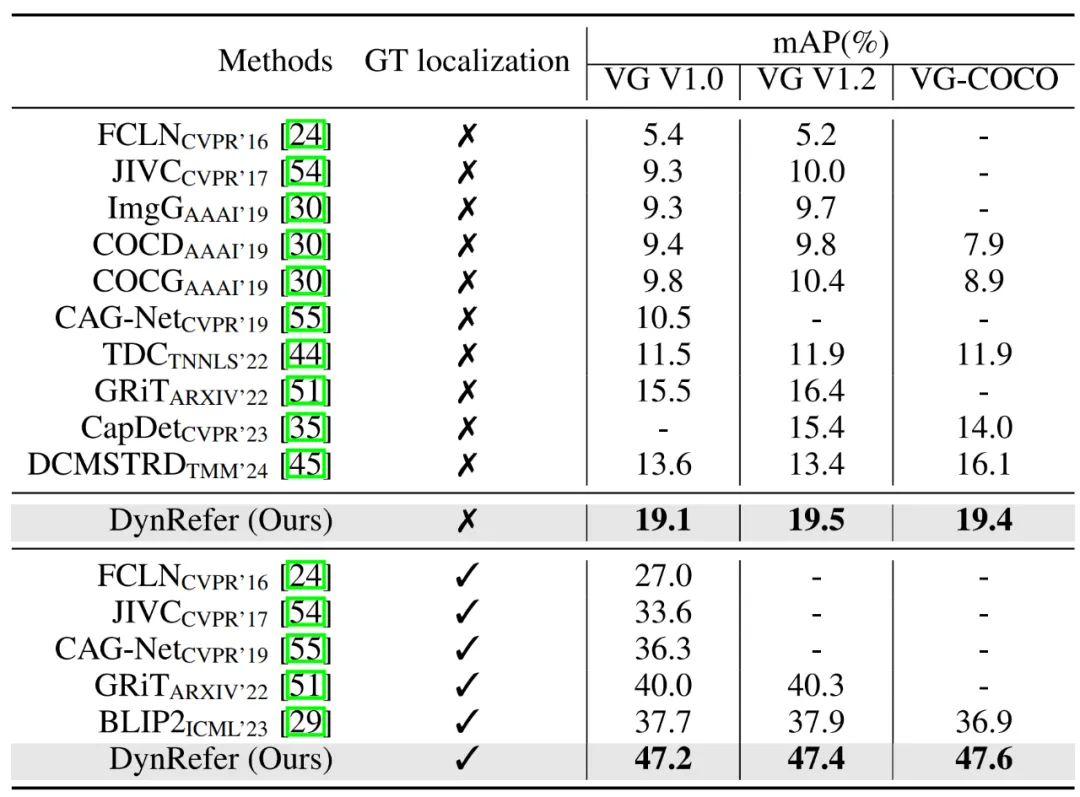
在密集字幕生成任务,在 VG1.2 数据集,DynRefer 相较之前的 SOTA 方法 GRiT 提升了 7.1% mAP。
Open Vocabulary Attribute Detection
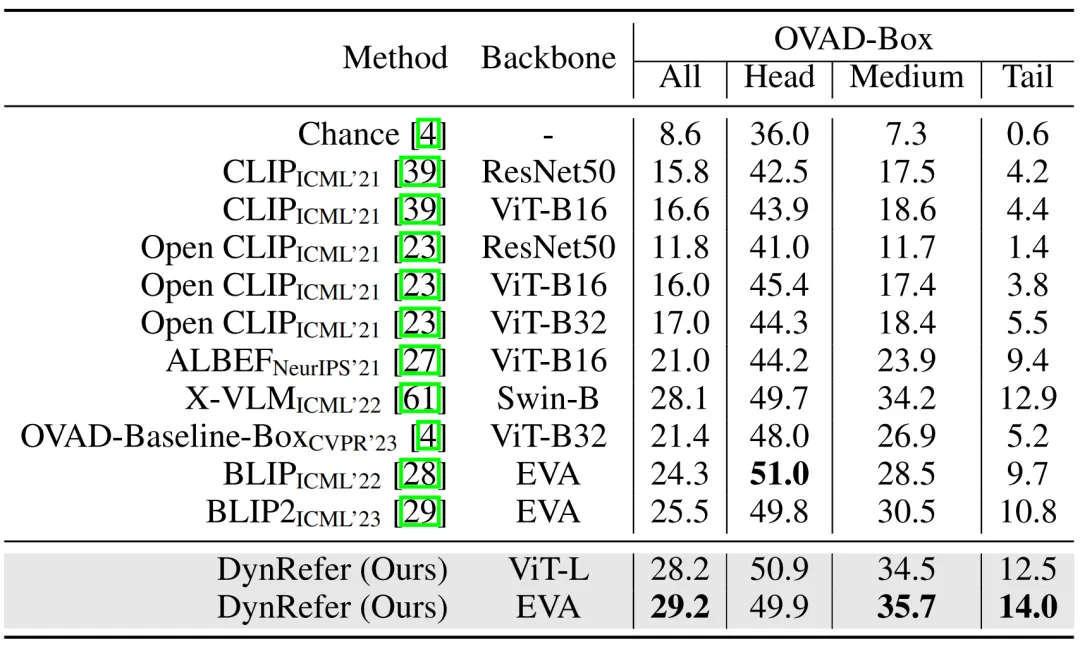
在区域属性检测任务,DynRefer 也取得了 SOTA 的性能。
Open Vocabulary Region Recognition
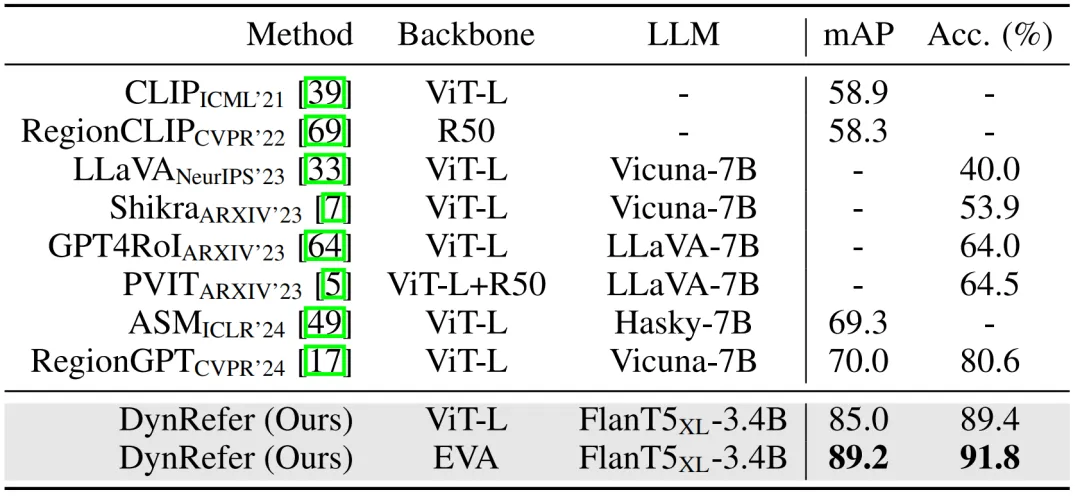
在区域识别任务,DynRefer 比 CVPR 24 的 RegionGPT 提升了 15% mAP 和 8.8% Accuracy,比 ICLR 24 的 ASM 高 15.7% mAP。
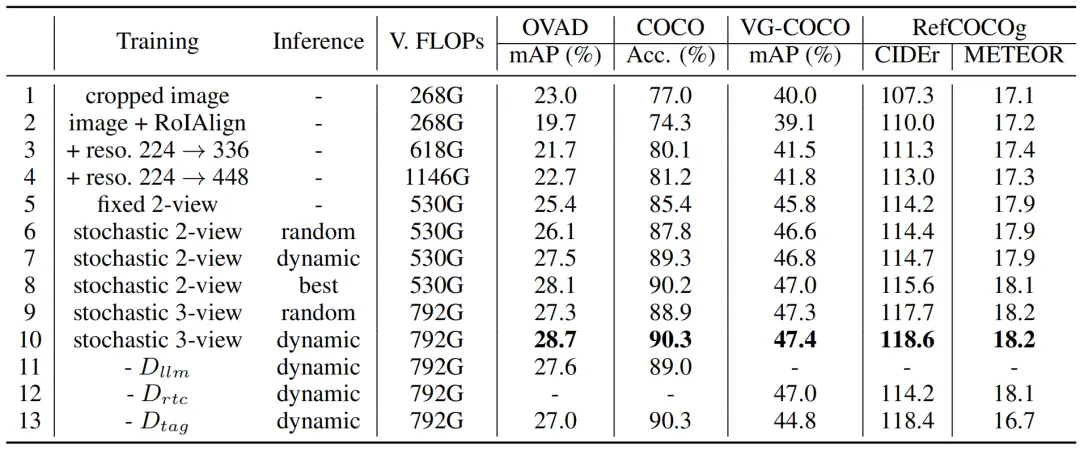
消融实验
下面几张图展示了 DynRefer 的推理结果,DynRefer 可以用一个模型同时输出区域字幕、标签、属性和类别。


文章来自于微信公众号 “机器之心”,作者 “机器之心”




