# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
雷嘉晖,美国宾夕法尼亚大学计算机系博士生 (2020 - 今), 导师为 Kostas Daniilidis 教授,目前主要研究方向为四维动态场景几何的建模表示和算法以及应用。他在计算机视觉和机器学习顶会 (CVPR、NeurIPS、ICML、ECCV) 以第一或共一作者身份发表文章 7 篇。此前他本科 (2016-2020) 以专业第一名的成绩毕业于浙江大学控制系,竺可桢学院混合班。
从任意单目视频重建可渲染的动态场景是计算机视觉研究领域的一个圣杯。本文中,宾夕法尼亚大学和斯坦福大学研究团队尝试向这一目标迈进一小步。
互联网上有海量单目视频,其中蕴含了大量物理世界的信息,但三维视觉仍缺乏行之有效的手段,将三维动态信息从这些视频中提取出来,从而支撑未来三维大模型建模及理解动态物理世界。尽管重要,这个反问题极具挑战性。
本文提出了一种新颖的神经信息处理系统 —— 摩斯卡 (MoSca),只需提供一连串视频帧图片,无需任何额外信息,即可从 SORA 生成的视频、电影电视剧片段、互联网视频和公开数据集的单目野生 (in-the-wild) 视频中重建可渲染的动态场景。

以下为两个视频Demo。


方法概览
为了克服上述的困难,摩斯卡首先利用了存储在计算机视觉基石模型 (foundation models) 中的强先验知识将问题解空间缩小。
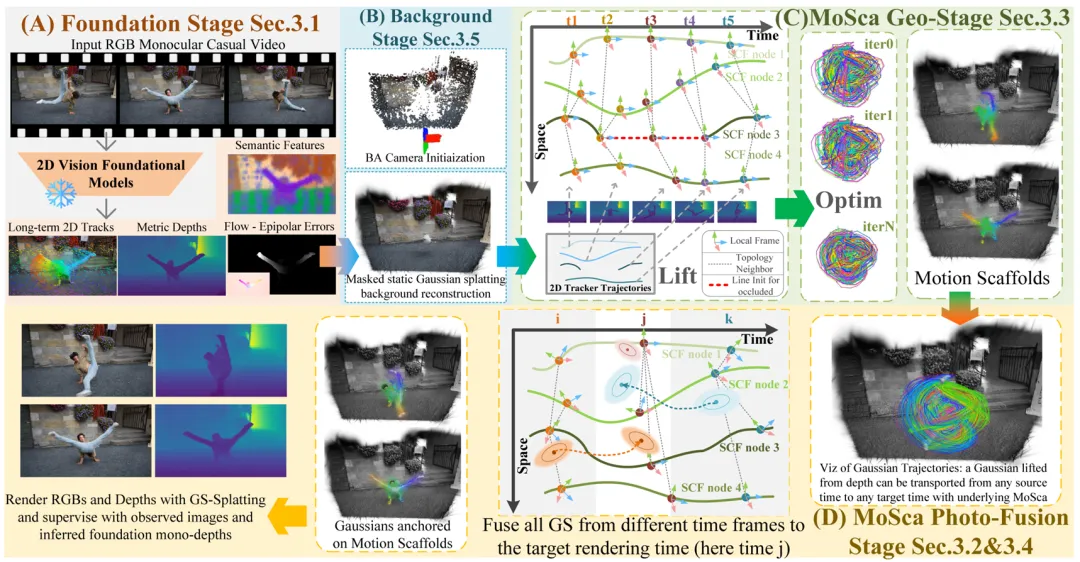
具体而言,摩斯卡利用了单目有尺度的深度估计 (mono metric-depth) 模型 UniDepth、 视频任一点长时间跟踪 (track any point) 模型 CoTracker、光流估计 (optical flow) 模型 RAFT 计算出的对极几何误差 (epipolar error), 以及预训练语义模型 DINO-v2 提供的语义特征。详参论文 3.1 章节.
我们观察到,大多数真实世界的动态变形本质上都是紧凑和稀疏的,其复杂度往往远低于真实几何结构的复杂度。比如,一个硬物体的运动可以用旋转和平移表示,一个人的运动大致可以用多个关节的旋转平移近似。
基于这一观察,本文提出了一种新颖的紧凑动态场景表示 —— 四维运动脚手架 (4D Motion Scaffold),将上述基石模型输出从二维提升至四维并进行融合,同时也融入物理启发的变形正则化 (ARAP) 。
四维运动脚手架是一个图,图的每一个节点是一串刚体运动 (SE (3)) 轨迹,图的拓扑结构是全局考虑刚体运动轨迹曲线距离而构建的最近邻边。通过使用对偶四元数 (dual-quaternion) 在时空中平滑插值图上节点的刚体轨迹,可表示空间中任意一点的变形。这一表示大大简化了需解的运动参数。(详见论文 3.2 章节)。

四维运动脚手架的另一个巨大优势在于可以直接被单目深度和视频二维点跟踪初始化,再通过高效的物理正则项优化求解出未知的遮挡点位置以及局部坐标系方向。详参论文 3.3 章节.
有了四维运动脚手架,任何时刻的任何一点都可以被变形到任意目标时刻,这让全局融合观测信息变得可能。具体而言,视频每一帧都可以利用估计的深度图反投影到三维空间并初始化三维高斯 (3DGS)。这些高斯被「绑定」在四维运动脚手架上,自由穿梭于任何时刻。想要渲染某一时刻的场景,只需将全局所有其他时刻的高斯通过四维脚手架传送到当前时刻融合即可。这一基于四维运动脚手架和高斯的动态场景表示可高效地被高斯渲染器优化(详见论文 3.4 章节)。
最后值得一提的是,摩斯卡是一个无需相机内外参的系统。通过利用上述基石模型输出的对极几何误差确定静态背景掩码,利用基石模型输出的深度和点跟踪,摩斯卡可以高效地优化重投影误差,求解全局集束优化 (bundle adjustment),从而直接输出相机内参和位姿,并通过后续的渲染持续优化相机(详见论文 3.5 章节)。
实验结果
摩斯卡可以在 DAVIS 数据集视频中重建动态场景。值得注意的是,摩斯卡可灵活支持多种基于高斯的渲染器。除了原生的 3DGS 渲染器,本文还测试了近期的高斯表面重建渲染器 GOF (Gaussian Opacity Field),如图中最右列的火车,GOF 可渲染出更高质量的 normal 和 depth。

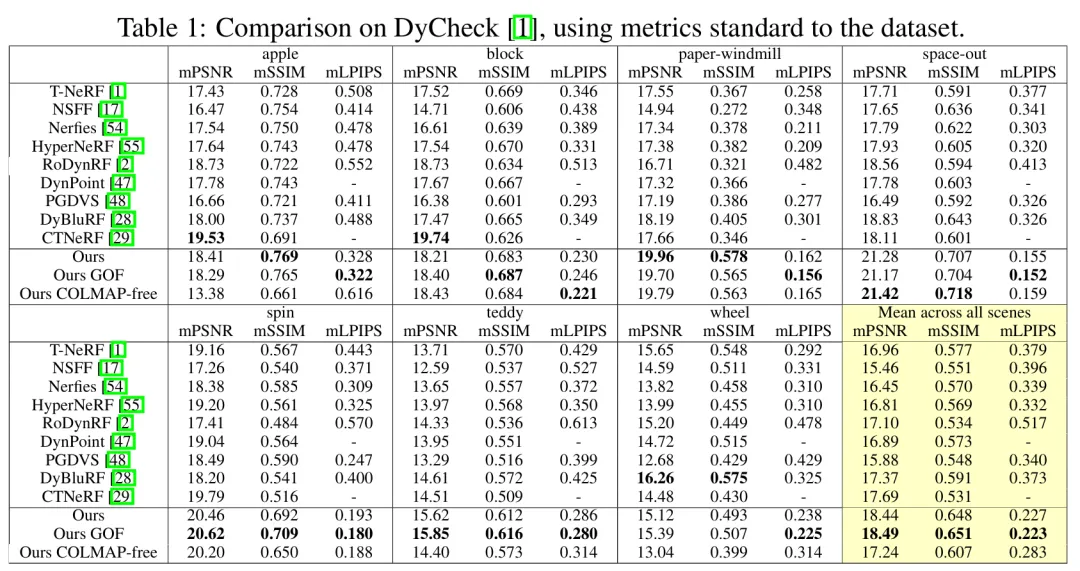
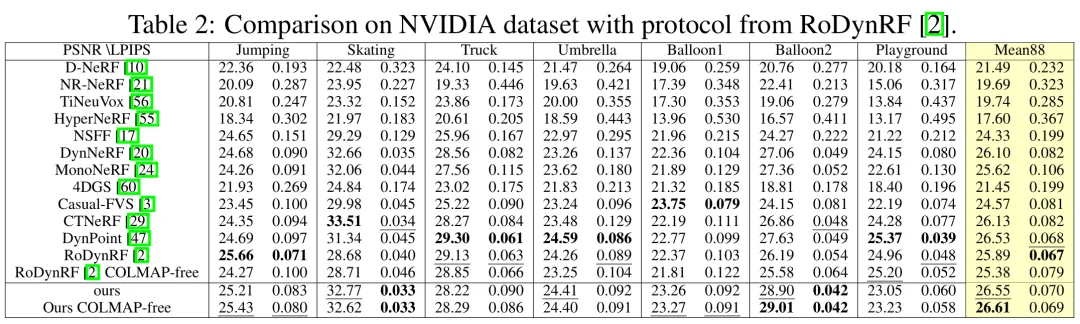
摩斯卡在极具挑战性的 IPhone DyCheck 数据集上取得了显著提升,同时也在广泛对比的 Nvidia 数据集上对比了其他方法。


文章来源于“机器之心”



