# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
为了让大模型在特定任务、场景下发挥更大作用,LoRA这样能够平衡性能和算力资源的方法正在受到研究者们的青睐。
然而,以LoRA为代表的众多低秩微调方法(包括DoRA, MoRA, AdaLoRA等衍生方法)仍存在一个问题:
它们通常通常都更适合Linear层,Embedding层这类“直入直出”的低维度张量,忽略了对更高维度甚至N维张量的考虑。
尽管这些方法可以通过一定方式将高维度张量转化为2D张量来微调参数,如LoRA将Conv2D卷积层参数所具有的四维张量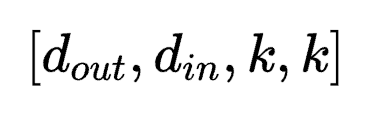 转化为二维张量
转化为二维张量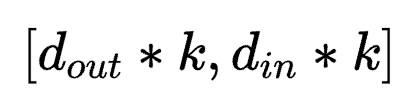 。但其存在两方面的挑战:
。但其存在两方面的挑战:
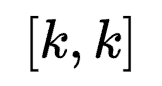 拆开分别reshape到
拆开分别reshape到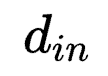 ,
,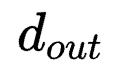 维度上的方法虽然避免了参数的大规模增加,但是破坏了卷积核本身的结构特性。这对于密集预测类任务所需要的局部归纳偏置是一种负向影响。
维度上的方法虽然避免了参数的大规模增加,但是破坏了卷积核本身的结构特性。这对于密集预测类任务所需要的局部归纳偏置是一种负向影响。
为了解决以上两个问题,来自上海交通大学、上海AI Lab的研究人员提出了FLoRA方法(flora意为植物群,具有广泛的寓意)。
以视觉任务为例,FLoRA能在比LoRA少80%参数的情况下,取得与之一致的效果。
作者认为,各维度参数的调整应该通过一个全局的低秩核心空间的子空间来进行,低秩核心空间本身则保留了原参数不同维度之间存在的拓扑关系以及交互性。
具体来说,作者通过应用Tucker分解来实现对低秩核心空间的构建,完成了以统一视角来推导N维张量低秩微调方法的适配,使得低秩微调方法扩大到如Conv2D层, Embedding层,Linear层等各类常见层上。同时,作者发现通过调整不同的参数,FLoRA可以退化为多个不同的低秩微调方法。
卷积具有局部学习的归纳偏置。若设置一个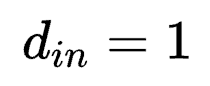 ,
,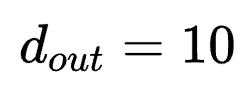 ,
,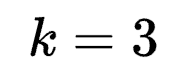 的卷积层,其参数形状应该为[10,1,3,3],后两维[3,3]构成了一个具有正方形结构的滤波器。
的卷积层,其参数形状应该为[10,1,3,3],后两维[3,3]构成了一个具有正方形结构的滤波器。
在按照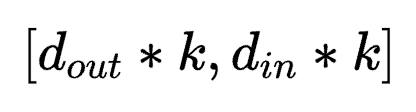 方式进行拆分过程中,既有permute的操作,也有reshape的操作,此时原本相邻的滤波器被打散。这增加了可学习参数来建模出原本的局部特性的难度。
方式进行拆分过程中,既有permute的操作,也有reshape的操作,此时原本相邻的滤波器被打散。这增加了可学习参数来建模出原本的局部特性的难度。
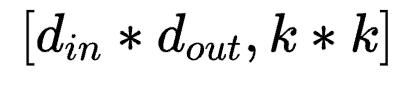 来避免破坏结构?
来避免破坏结构?在卷积结构中,一层网络的参数 具有四个维度。
具有四个维度。
若按照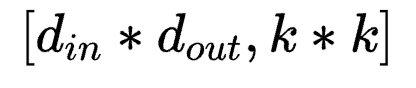 方式将参数拆成对应LoRA中AB的形式,则应该为
方式将参数拆成对应LoRA中AB的形式,则应该为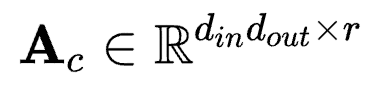 以及
以及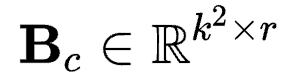
若按照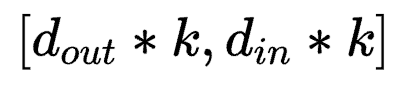 方式将参数拆成对应LoRA中AB的形式,则应该为
方式将参数拆成对应LoRA中AB的形式,则应该为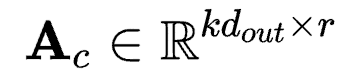 和
和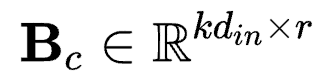 。
。
前者参数量为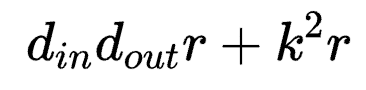 ,后者参数量为
,后者参数量为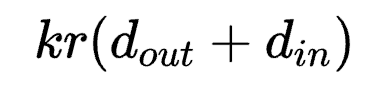 。
。
当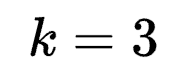 时,分别为
时,分别为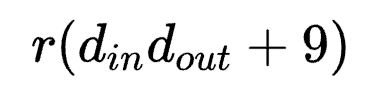 和
和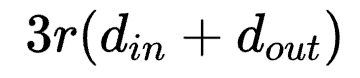 ,一般而言,
,一般而言,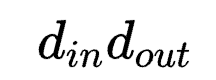 >>
>>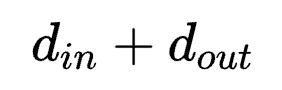 ,
,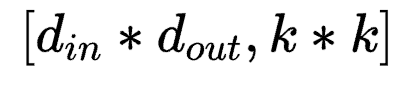 方式会引入超大量的参数。因此转而使用后者是一种以结构完整性换参数量的折中。
方式会引入超大量的参数。因此转而使用后者是一种以结构完整性换参数量的折中。
Tucker分解是一种矩阵分解方法。对于具有N维的张量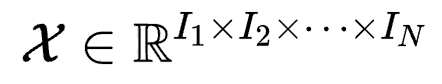 , Tucker分解可以将其表示为一个核张量(Core Tensor)与沿着每一维度得到的矩阵
, Tucker分解可以将其表示为一个核张量(Core Tensor)与沿着每一维度得到的矩阵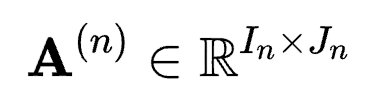 的乘积,其中Jn为第n维的通道大小。可以写为:
的乘积,其中Jn为第n维的通道大小。可以写为:
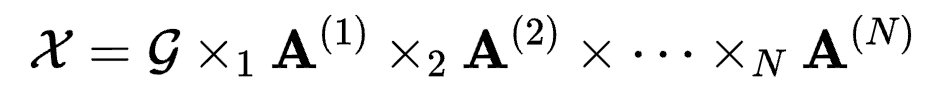
其中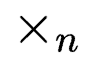 为模乘,表示一个张量(tensor)和一个矩阵(matrix)的乘法。
为模乘,表示一个张量(tensor)和一个矩阵(matrix)的乘法。
在Tucker分解中,核张量代表了不同维度之间的交互,而矩阵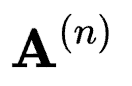 则类似于每一个维度的主成分。通过这种形式,依靠核张量去学习不同维度之间的关系,依靠各维度矩阵学习本维度的内在特性,可以在保留N维张量拓扑结构的基础上更好的优化学习过程。
则类似于每一个维度的主成分。通过这种形式,依靠核张量去学习不同维度之间的关系,依靠各维度矩阵学习本维度的内在特性,可以在保留N维张量拓扑结构的基础上更好的优化学习过程。
基于以上对Tucker分解的介绍,作者便将这种分解方式引入到参数高效微调中。具体来说,相比于LoRA中
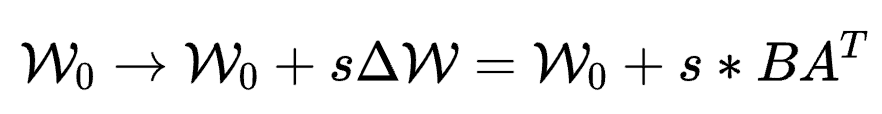
其中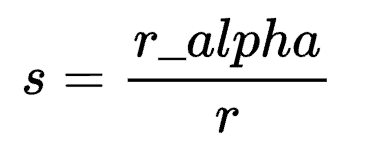 。
。
FLoRA将N维张量分解统一设计为:
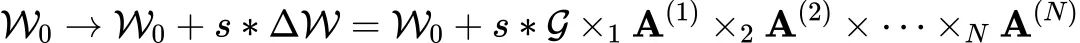
其中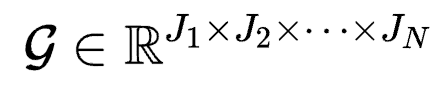 为核张量,s为可调的scale系数,
为核张量,s为可调的scale系数,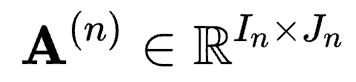 为第n维的低秩矩阵,这里的Jn就是低秩r,且Jn<<In。
为第n维的低秩矩阵,这里的Jn就是低秩r,且Jn<<In。
对应于具有4个维度的卷积核参数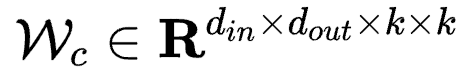 则有
则有
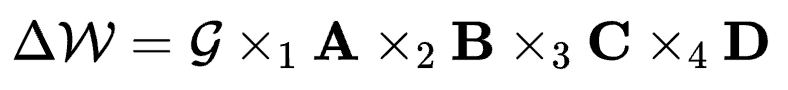
其中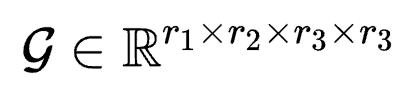 ,
,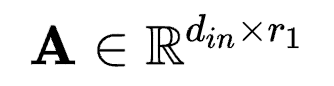 ,
,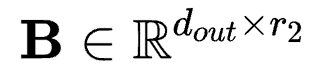 以及
以及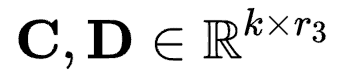 。
。
r3和r4一般取相同的比卷积核大小k更小的值。根据上式,作者认为在卷积参数微调中具有一个卷积核心(Convolution Core),而FLoRA负责找到了这个核心的值并且配置了不同维度的权重值。与LoRA相比,在相近参数量上FLoRA允许设置更大的秩r,在同等秩的情况下,FLoRA大大降低了参数量。
举例:若k=3,r3=r4=2, r1=r2=r=32, din=256, dout=512,
FLoRA的参数量为:
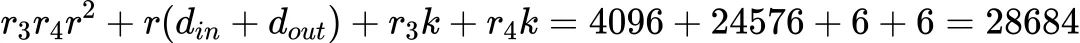
LoRA的参数量为: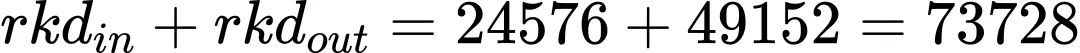
若FLoRA达到与LoRA相同的参数量,则r=70。
对应于具有2个维度的线性层参数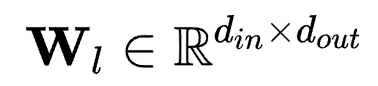 ,则有
,则有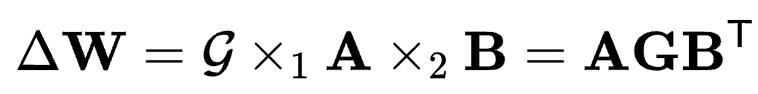 ,其中
,其中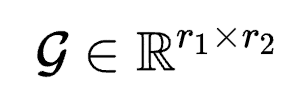 ,
,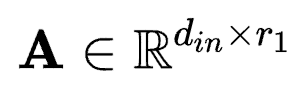 ,
,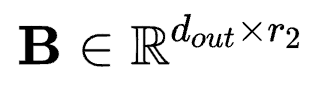 。与4维的卷积核参数类比,这里的G便是对应的线性核心。
。与4维的卷积核参数类比,这里的G便是对应的线性核心。
参考上边的例子,同等r的情况下,FLoRA参数量为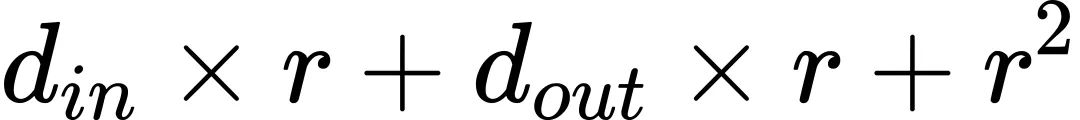 相比LoRA仅多出
相比LoRA仅多出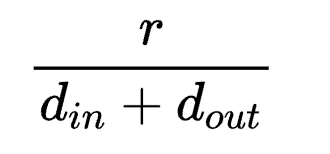 % 的参数,对应该例子为4.17%。
% 的参数,对应该例子为4.17%。
在实际应用中,由于核张量的存在,等效的r1,r2可以小于LoRA的r,从而实现同等规模甚至更少的参数量情况下,效果与LoRA一致甚至更好。
在LoRA中,s的取值由r和另一超参r_alpha决定,通常固定s=2。
在FLoRA中,该值以超参形式设定为一个固定值,不需要引入r_alpha,本质上s代替了r_alpha,因此相比LoRA没有引入额外数量的超参。
对于s的选取,作者在实验过程中发现对于不同大小规模的参数量以及不同类型的模型(即不同维度的参数空间),取值不一,但呈现出了一定的特点。对于卷积模型来说,s的取值在一定范围内越大越好,在以ConvNext-L为backbone来微调时设置为4;对于线性模型来说,s的取值尽量较小,在微调InternViT-6B和LLaVA-7B时,s的值设置为0.04。
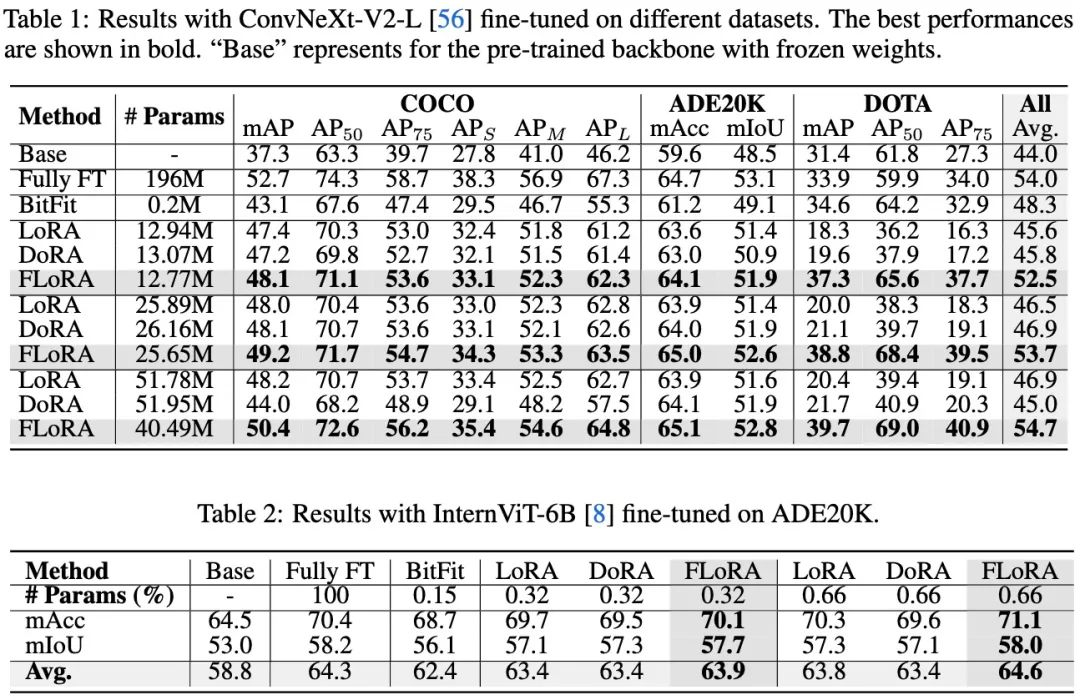
作者分别在视觉任务,语言任务,多模态任务上做了实验,涵盖了2种类型模型(Conv与ViT),4种参数规模(DeBERTav3-base: 184M,ConvNeXt-large: 196M, InternViT-6B, LLava-v1.5-7B),涉及18个数据集。
实验结果表明,FLoRA在各种视觉任务上都取得了明显的性能提升,甚至在比LoRA少80%参数的情况下,依然可以取得和LoRA一致的效果。实验结果说明了通过引入核张量来建模维度关系,从而避免破坏拓扑结构的方式是利于多维度参数微调的,并且可以取得很好的效果。
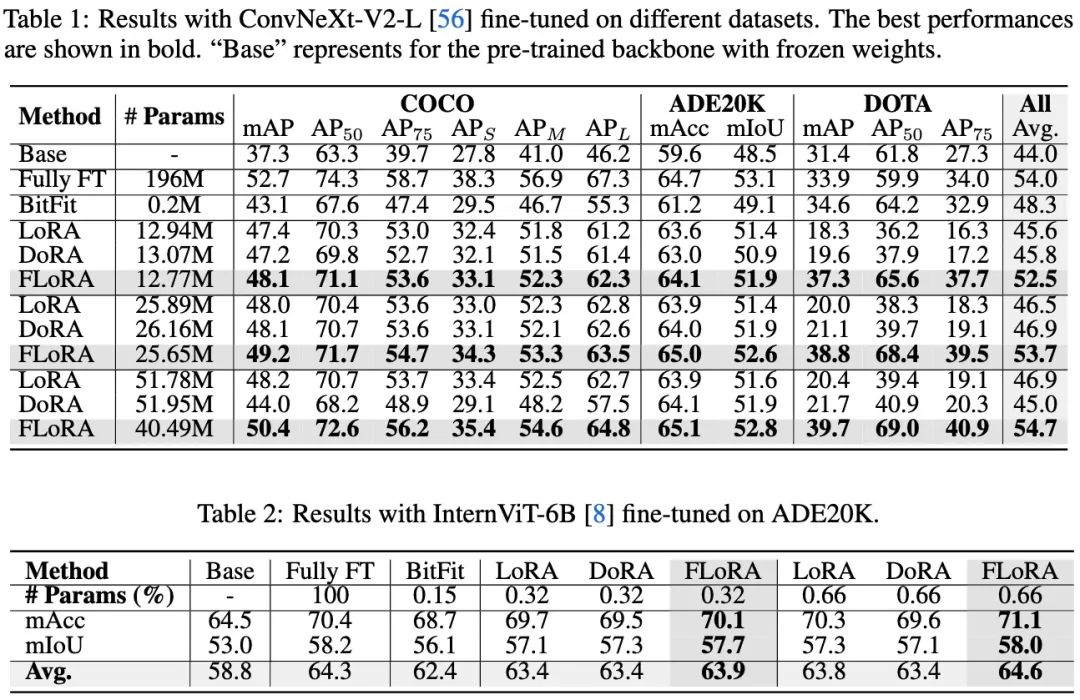
在语言任务上作者也相应的做了一些实验,并且在所有的可调参数规模下都实现了明显的性能增长。
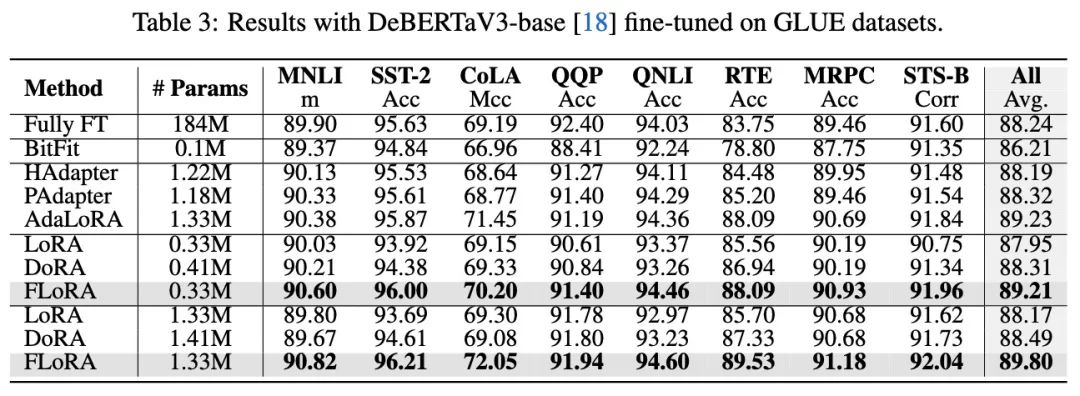
在多模态任务上作者也基于llava-v1.5-7b做了visual instruct tuning的测评。同样显示出了比LoRA更好的效果。

作者也做了扩散模型的微调,并给出了生成结果的对比。

对于FLoRA和LoRA相比在训练时间与显存开销上的区别,作者也给出了数据说明。
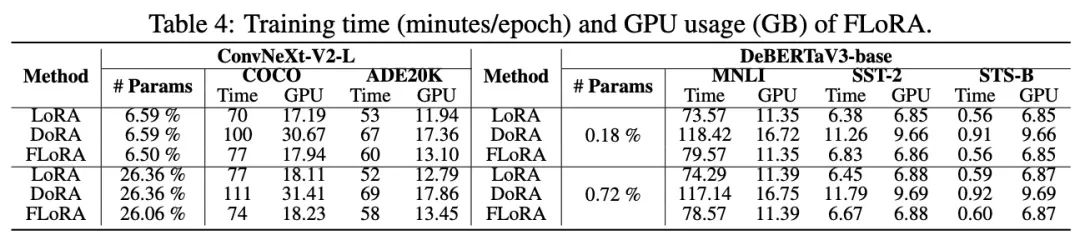
更多内容可以查看论文原文,作者反馈:核心实现代码以及不同任务完整代码也即将于近期陆续开源。
文章来源于“量子位”,作者“关注前沿科技”




【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
