# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
2024 年,为何期待已久的 AGI 应用大爆发迟迟没有来临?
这一波 AI 创业真的值得投身其中吗?
关于这个问题,在 6 月底的 AGI Playground 2024 上,极客公园创始人&总裁张鹏在开场的演讲,部分解答了 AGI 创业值不值得做,以及应该怎么开始创业的思考。
还有创新工场联合创始人汪华的演讲,从国内的大模型公司的现状和技术趋势、以及国内应用的现状,回答了为什么国内 AI 应用还没有爆发的原因所在。
今天这篇对话文章,则从海外市场的AI 应用现状、巨头的发展情况等,解释了海外市场AI 应用迟迟还没爆发的原因所在。
GPT-4 已经诞生一年多了,但 AI 应用的爆发速度显然低于所有人的预期,直到今天,严格意义上只有 Perplexity 真正实现了 PMF。在这次对谈中,我们围绕“为什么 AGI 应用还没有大爆发”给出了自己的思考。
AI-native 应用的 PMF 是 Product-Model-Fit。模型能力的解锁是渐进式的,AI 应用的探索也会经历从组合性创造、到探索性创造再到变革性创造的跃迁。Perplexity 的 AI 问答引擎是第一阶段组合型创造的代表,随着 GPT-4o、Claude-3.5 Sonnet 的先后发布,多模态、推理能力的提升,我们已经来的 AI 应用爆发的前夜,也许 GPT-5 发布后的半年,我们就会大概率迎来 AI-native 应用的井喷。
成本下降也会是应用爆发的关键。假如 OpenAI 的 GPT-4o 给开发者的 API 成本大幅下降、甚至下降到可以忽略成本,会哪些应用可以爆发?欢迎大家在评论区留下自己的猜想。
在本次讨论中,我们也分享了对 Nvidia、 Apple、Amazon、Tesla 等科技巨头在 AI 投入上的观察。今天,绝大多数 AI 应用站在巨头的核心战场上,巨头如何去构建自己的 AI 产品组合也影响着 AI-native 应用的发展和天花板,AI 不会颠覆巨头,反而会依附于巨头。这也是我们推出 AGIX Index 的原因:巨头们从 AI 浪潮中受益的确定性极强,如果要真正在新一轮技术浪潮中获得收益,除了寻找挑战巨头的破坏式创新者,识别出那些能够贯穿周期的价值王者同样重要。
对谈嘉宾:
李广密:拾象科技 CEO
张小珺:商业科技深度报道作者
以下为本文目录,建议结合要点进行针对性阅读。
01 搜索是 LLM 初期最大的 Killer App
02 AI-native 应用爆发了吗?
03 GPT-5 与模型格局变化
04 大模型是一个好的商业模式吗?
05 科技巨头们的 AI 进展
张小珺:你今年依然在美国花的时间非常的多,整个上半年最大的感受是什么?
Guangmi Li:GPT-4 出来一年多了但 AI 应用还没大爆发,从结果上看是比较无聊的。抛开 ChatGPT 这种大模型公司自己的应用,硅谷主流 VC 投资的、已经跑出来且发展到一定估值的,我可能只能想到 Perplexity 一家,这家公司现在已经有 2000 多万月活、2000 多万美金的 ARR,预计今年年底可能有 1 个亿左右的月活和一亿美金 ARR。其他很多公司可能还在 PMF 之前的阶段。
张小珺:可以给我们展开介绍下 Perplexity 这家公司吗?关于这家公司的 CEO 、创业团队和创业过程。
Guangmi Li:Perplexity 是 2022 年 8 月份成立的, CEO 是一名印度裔、是 Berkeley 的 CS PhD,他最早在 OpenAI 和 Deepmind 都实习过,毕业后就加入了 OpenAI,一年后又出来创立了 Perplexity。
Perplexity 的 CTO 最早是微软 Bing 的搜索工程师,后来加入美国的知乎,Quora, 创立 Perplexity 前他在 Meta AI 工作。Perplexity 整个团队现在大约有 50 个人。
我印象很深的是团队刚开始创业时,硅谷最核心 AI 圈子的人几乎都投了他们,比如 Google 的 SVP Jeff Dean、 Meta 的 Yann LeCun,还有 OpenAI 早期团队的 Pieter Abbeel、Andrej Karpathy、知名的 Solo GP Elad Gil、GitHub 的前 CEO Nat Friedman、Databricks 的 Co-founder Reynold Xin、Hugging Face 的 CEO 等等,Amazon 的创始人 Bezos 个人也参与了投资,并且 Bezos 还是 Google 的天使投资人,对搜索还是比较懂的。
Perplexity 是 2023 年初完成的 A 轮融资,最近又完成了第四轮融资,Bessemer 领投的,最新估值达到了 30 亿美金。
张小珺:Perplexity 在 ChatGPT 发布之前就成立了,他当时为什么出来从 OpenAI 出来创业?为什么他能拿到几乎整个硅谷核心圈子的投资?
Guangmi Li:首先, CEO 本人就对 AI 搜索、信息分发感兴趣。当时投资人们也都有一个感觉是 ChatGPT 是一定会做搜索的,像 Perplexity 这种能做好搜索产品的团队是值得被 OpenAI 再收购回去的,作为投资人也有机会再换一些 OpenAI 的股票。
张小珺:Perplexity 的最新估值到了 30 亿美元,它的估值为什么这么高?
Guangmi Li:搜索还是互联网上最肥、最大的市场。微软 Bing 只有全球搜索 3.4% 的份额,但产生了 120 亿美金的年营收,AI 搜索只要抢到 Google 1%-2% 的份额,这个生意就很大。AI 搜索应该是大模型初期最大的 killer app,而且我们能看到 Perplexity 单个活跃用户每天搜索的 Query 量其实是 Google 的 3 倍多。
其实去年我们内部第一次讨论 Perplexity 的时候我问过一个问题:把 Perplexity 的这种形态和小红书做比较,会是什么样的?一个是 AIGC,一个是 UGC,其实本质都是在做好信息分发,帮用户解决问题,并且都是在抢传统搜索的生意。小红书抢了很多百度的搜索流量。
其次,我们把 Perplexity 和早期的头条做过对比,2013 年的时候,头条 APP 的次留有 46%,后面即便用户规模大了,反而留存还更好了。Perplexity 的留存其实和头条早期基本上是一样的,长期留存很高,我记得是显著比其他的 AI 产品是高的。Perplexity 的数据增长一直比较好,公司过去一年产品迭代很快,一直在稳定增长,月度环比增长都在 20%以上。
还有一点,站在今天复盘过去一年 AI 领域的进展,信息检索是匹配模型能力最重要的 use case,其次重要的可能是教育,这两个是真正匹配今天模型能力的场景。如果大家理解了今天的模型能力,再去理解这种产品是比较 match 的。
其实今天评价 PMF,最重要的还是两个要素:第一,留存好不好,第二,商业化模型好不好。留存肯定过关了,但是商业化上确实是没有广告平台这种效率高的。我感觉这也是 AI 产品今天面临的一个普遍问题,因为广告这个模式其实在 PC 时代就非常成熟了,所以移动的时候搬过来很容易。
Perplexity 的留存好,有一个很重要的原因是产品心智。之前我们的播客聊到过,其实 AI 产品今天还没有很强的网络效应、规模效应和数据飞轮,所以目前的产品重点就是用户心智。Perplexity 占到了 AI 搜索的心智, ChatGPT 占到了 Chat 的心智, Character AI 占到了陪伴的心智。
其实就像 Google 早年占到了搜索的心智一样。AI 搜索未来还是有想象空间的,Agent 落地以后,其实搜索还是最适合 Agent 落地后的一个场景,对用户的个性化的知识、复杂问题包括后面的 Action、执行落地等,这个对用户的决策帮助是比较大的。
张小珺:你觉得过去一年为什么是 Perplexity 跑出来了?
Guangmi Li:去年这个时候觉得 ChatGPT 应该做搜索,所以 Perplexity 在过去大家觉得是有收购价值的。今天 OpenAI 也真的决定做搜索了,那其实说明信息检索是匹配模型能力最重要的 use case。
这个过程中更重要的一个体会是理解大模型能力到底能匹配什么 use case。之前我们聊到模型能力是渐进式解锁的。我们作为一个知识工作者一般有几类的创造性任务:第一,组合性的创造。第二,探索性的创造,第三,变革性的创造。
信息检索就是一个组合性的工作,是最能匹配今天模型的能力的。像长距离推理工作,比如我们写一篇 Tesla 的投研报告,这是一个探索性的创造,需要规划、也需要各种推理。那比如像科学发现万有引力定律、发现摩擦力这种属于变革性的创造,而今天大模型还比较难做到这种举一反三的任务,也比较难处理没见到过的任务。
Perplexity 这个团队对现在的模型能力的边界理解是很深的,模型今天还没有自由探索的能力,目前更多的还是信息组合的能力。今天模型的能力刚好契合了 Perplexity 做复杂信息问答的 Use Case。
张小珺:Perplexity 是对“模型即产品”、“模型即应用”这种说法的反击吗?因为创始人说他是先思考产品,再思考模型,而不是像很多大模型公司提出的是先提高模型能力、再同步去想产品。二者之间的思考逻辑其实是反的。
Guangmi Li:其实 Perplexity 也 fine tuning 了一个 Mistral-7B 的模型,足够覆盖很多 query了。一方面是成本考虑,还有一方面是 Perpleixty 要向下改模型,但它不能要求 GPT 改、不能要求 Claude ,所以 Perplexity 自己也 fine tuning 了一个小模型,最后还是要端到端 full stack 来做优化。
张小珺:我们应该先思考模型再思考产品,还是先思考产品再思考模型?
Guangmi Li:这个没有标准答案。今天 OpenAI 也做搜索了,但 OpenAI 做搜索能不能做好我们是不知道的。SpaceX 有发射能力,能做 Starlink,那如果 SpaceX 的发射能力是开放的,别人借助它的能力能不能做好 Starlink?今天的 API 也都是开放的。
如果 Perplexity 能向下改模型,或者假如某一天 Anthropic 收购了 Perplexity,那我觉得他去跟 OpenAI 竞争是很好的一个组合,因为 Perplexity 往下走肯定是要跟模型更深结合,而改模型资源投入太大了。但收购这件事很难假设、也很难预测。
张小珺:海外独角兽翻译过一篇对 Perplexity CEO 的采访,里面提到 Perplexity 一开始坚决的用外部模型,因为目标是打造以产品为核心的公司,所以不要在训练模型上花费时间,而是先专注产品、做用户增长、做好留存,这是先解决的问题最重要的一步,Perplexity 接下来会再去训个自己的小模型吗?
Guangmi Li:这个很合理。如果今天我自己做一个应用,我肯定也是基于最好的模型的能力先做 PMF,之后我会想成本下降问题,再之后我要做端到端的优化,甚至蒸馏一个小的模型来 cover 特定、热门的 query 问答,我觉得这是一个很合适的路径。
如果今天我做一个特定领域的助理应用,我肯定是先用 GPT4 最强的模型先做 PMF,之后想办法降成本、想办法去做自己的模型,这样还能去改一些东西。其实今天我 distill 一个模型,比如 distill 1T 的数据,今天好像也花不了太多钱,其实比从头 train 一个模型成本是低很多的,那我可以 own 一个自己的模型,有可能未来很多的应用公司也会 own 自己的小模型。
张小珺:如果按照我们之前说的“渐进式解锁”,即模型能力在提高期间会解锁出不同的应用的逻辑。那未来比如 GPT-4 到了 GPT-5 的水平,现有产品的护城河是什么?拥有更大、更强模型的公司会不会抄一个它的产品形态就把它碾压了呢?
Guangmi Li:其实是有可能的。只能说过去一年 ChatGPT 做即时性的信息检索效果太差了,所以是留有这个窗口的。所以 Perplexity 必须要提高自己的模型能力,甚至跟一个模型公司深度合作、一个巨头深度合作。
张小珺:Perplexity 能够冒出来有哪些因素很关键?
Guangmi Li:我觉得有一个关键角色:Nvidia 投了它,所以老黄帮 Perplexity 带了很多量。有一次老黄公开提到用的最多的一个产品就是 Perplexity,老黄给它代言了,并且 Perplexity 的 CEO 自己也常常出来分享自己的思考。
其实在知识工作者这个群体,Perplexity 一开始占位是比较好的。两个因素比较重要:第一,CEO 持续布道,占住了 AI 搜索的心智。第二,公司在增长的动作上也做了很多工作,因为这个产品的核心就是增长。
张小珺:问一个 VC 经常问的问题:Perplexity 怎么和 Google 竞争?怎么和 OpenAI 竞争?
Guangmi Li:我感觉竞争的问题其实 Perplexity 创业第一天回答不了, A 轮也很难回答,今天估值到了 30 亿美金的时候其实也很难回答,有可能后面走到百亿美金、甚至几百亿美金的时候还是很难回答,其实头条在一开始也很难回答怎么跟三大门户竞争的问题。所以竞争问题我也没什么好的答案。
但我自己感觉这个答案可能会是错位竞争,因为 perplexity 其实不是完全一样的产品和技术。错位竞争是比较重要的,创业公司应该好好理解一下错位竞争,和巨头直接硬碰硬是很难的。
Perplexity 找到的是 LLM 最匹配的一个能力的领域:知识工作者,use case 是信息问答,尤其是复杂的信息问答,围绕商业、本地生活等。Google 擅长的是网页的导航,包括交易信息的搜索。Perplexity 其实做的是对应传统搜索中差不多 5% 的复杂问题问答,这个是传统搜索没有做好的,也是搜索中皇冠上的明珠。
与 OpenAI 的竞争其实还是主要看 OpenAI 自身。因为 OpenAI 还是科研文化,接下来这种科研文化和产品文化能不能平衡好比较重要。如果 OpenAI 的技术交给头条,到今天产品和商业的收益可能是 OpenAI 的 3- 4 倍。做好产品、商业的文化可能还是属于字节或者Meta 的组织文化。
最简单一个例子,假设搜索产品团队觉得某个能力不行,想向下改模型的数据,想看模型团队同意不同意,我觉得 OpenAI 的模型团队可能是不同意的,是不想改动模型的基础数据的。OpenAI 可能就 10 个人做搜索,Perplexity 是 50 个人专注在这一个事上,我觉得不见得比他们差。
还有一个点是未来还有很多产品形态本身的变化。大家天然会觉得搜索和 Chat 就应该给即时性的答案,但其实我们很多工作上的任务都不是即时性的,比如我们和同事协作都要做多步规划,甚至一周以后再给一个结果。一个复杂问题拆成多步、多次的搜索得到一个更好的答案,这也是一个潜在的状态。未来用户很多的任务就在一个看板上,然后用户持续地 Prompt,那 workflow 就都跑在这样一个 AI 产品上了,这也是一个未来更有意思的形态,尤其是在 agent 落地以后。
张小珺:你觉得 Perplexity 今天构建的护城河是什么?
Guangmi Li:是先发效应带来的用户心智。
张小珺 :它未来是会独立长大还是被并购?终局会是什么样的?
Guangmi Li:80% 的可能性是被并购的,创业公司今天好像都在巨头的辐射之下,不知道怎么杀出来。最近我们团队都买了 Meta 眼镜,如果 Meta 眼镜上接入一个语音版的 Perplexity 其实挺好的,过去 Siri 的搜索没做好,接一个也蛮好的。微软的 Bing 好像做了半天 AI 口碑也没那么好,Perplexity 的口碑反而很好,所以感觉都是在巨头的辐射之下的,而且这是一个核心战场。

张小珺:对于 Perplexity 的出现,国外 Google、国内百度这类传统搜索公司有什么样的应对策略吗?
Guangmi Li:Google 出了一个 SGE 产品,包括 Overview,但好像口碑不是很好。百度好像还没有动作,国内好像有一个秘塔。但国内有个很现实的问题是内容是割裂的,因为中国过早的进入了移动互联网时代,小红书的内容很难检索、微信的内容也很难检索,甚至知乎的都不一定那么开放。高质量内容的有效性是比较少的。百度搜索出来的首页里,百度自己的内容占很大比例,所以中国的内容的割裂性和海外的这种 PC 形态主导模式的区别是比较大的。
张小珺:中国的 Perplexity 更有可能是巨头的菜,还是创业公司的菜?
Guangmi Li:我个人感觉肯定是巨头的菜。其实字节一年前就应该做一个这种产品去打百度,信息流就是对百度广告的一个很大的抢份额机会,只是感觉很多人还没意识到这是不是一个 PMF,有的人觉得 Perplexity 也还没有完全 PMF,以及长期面临大模型公司本身的竞争。
张小珺:Perplexity 今天的估值和国内的月之暗面是一样,都是 30 亿美金,这意味着两家公司是除了 ChatGPT 以外全球并驾齐驱的明星 AI 公司。他们两个在模型和产品形态上,你觉得本质区别有哪些?
Guangmi Li:月之暗面还是基础大模型公司,但是他们的产品做的特别好。Kimi Chat 其实也抓了很多知识工作者的心智,用户画像和 Perplexity 也比较接近,有重合。
张小珺:Kimi 是一个从大模型到应用的公司,而 Perplexity 是一个从应用到模型的公司,先后顺序其实是不一样的。
Guangmi Li:应用公司是很难往下做模型的,只是做基础的模型的一些调优。我感觉中国的模型公司是必须得往上做应用的,所以美国出来哪些好的 use case ,我觉得大家都会借鉴的。
张小珺:如果我们画一个脑图,在海外市场,Perplexity 这类 30 亿美元估值的 AI native 的公司在第一梯队。那第二梯队、第三梯队的 AI 创业公司有哪些?
Guangmi Li:今天第一位肯定还是 OpenAI,ChatGPT 已经上亿的 DAU 了,还是很了不起的。The Information 曝出来 OpenAI 的 ARR 已经 34 亿美金了。我们盘了一下整个硅谷其他所有 AI 公司的 ARR 加起来应该还不到 15 亿美金,所以可能还不到 OpenAI 的一半。
Anthropic 是完全 To 企业端,ToC 很小。它可能是 OpenAI 今天的 1/10,大概 3 亿多美金。Character AI 有 600-700 万的 DAU,估值是 30-50 亿美金。最近比较火的 AI 程序员是 20 亿美金,还有很多想做 agent 的一些公司,比如新出来的 Reflection, 出来就几亿美金。迈到独角兽级别的感觉应该就 10 家公司,但都还是在 PMF 之前,有规模化的 ARR,比如 超过 10 million ARR 的其实还是非常少。
张小珺:看起来大模型公司要比 AI native 应用的公司估值都要高?
Guangmi Li:大模型公司的估值肯定是显著高的。OpenAI 是千亿美金量级,Anthropic 和 Elon Musk 的 xAI 都是 200 亿美金估值,再往后是 Mistral,50-60 亿美金,Character AI 是 30-50 亿美金, Cohere 也有 40-50 亿美金估值。AI-native 应用中跑出一定量级、故事比较好的有几个独角兽,但很多公司的估值都还是在小几亿美金。
张小珺:所以 Perplexity 是在 AI native 应用里面的估值第一?
Guangmi Li:纯应用的公司中是它的估值比较高的,不做模型的公司里面应该是估值最高的。
张小珺:我前段时间写了一个报道,叫大模型的扑克牌,讲的是中国资本在大模型领域的投资故事。海外大模型的扑克牌是什么样的?和中国资本参与的显著不同是什么?
Guangmi Li:海外更清晰一些,没有那么混沌。AWS 和 Anthropic 深度绑定,微软和 OpenAI 深度绑定,而 Elon Musk 是自成一派,靠自己的影响力融了 60 亿美金,未来可能还能融更多钱。Character AI 想再融几个 billion 美金的钱可能比较难,Mistral 最近刚融了 5-6 亿美金。
所以前面独立的公司只有三家:OpenAI、Anthropic、xAI。今年年内这三家公司都已经有了 3.2 万卡的集群,到明年都是奔着 10 万卡的集群去的。如果没有一个极强的大腿再支持几个 billion 美元量级的融资,其实挺难在大模型这里去卷的。
我比较期待未来 6-12 个月,Apple 和 Meta 这两个怎么选?巴菲特 push Apple 了 1100 亿美金的回购。如果是我的话,我觉得苹果应该去收购一家公司。Meta Llama 团队的人才密度感觉还是不够的,可能还是有船票的。Elon Musk 拿到了最后一张船票。
张小珺:这个取决于人才吗?
Guangmi Li:Meta 是有很多卡的,而且集群能力也是很强的,当其实人才上还是明显弱于前几家模型公司的。Elon Musk 的 xAI 其实像红杉美国、a16z 这些基金都参与了,每家应该都放了 5 亿美金左右,这对于 VC 基金还是挺大的一笔钱。
张小珺:我们刚才讲完了整个大模型和 AI native 应用到底有哪些公司,以及他们的估值。根据你的观察, AI 原生应用大爆发了吗?
Guangmi Li:还没有大爆发。GPT-4 出来一年了,大家也试了一年,其实是没有系统性的大爆发的。90% 的因素是只基于 GPT-4 的能力水平是不够的,只能做信息组合的创新,而没办法做长距离的推理、创造型工作,所以还是得卷下一代模型,尤其是推理能力和多模态能力。
还有 10% 的因素是时间问题,未来只基于 GPT-4o 的能力水平还是有概率能做出来大的应用的。NLP 已经出来 20 年了,也不算绝对成熟,但是也诞生了搜索这种 Killer App。电力发明以后很长时间也只有电灯泡这一个 killer app,但随着时间推移,各种消费电子也都发明出来了,各种家用电器也都有了。大家打磨了一年多,也快有一些 PMF 的意思了,这里需要年轻的产品天才。
张小珺:能不能举个模型能力和产品能力不够的例子?
Guangmi Li:比如我就想要一个幽默版的 ChatGPT,会讲段子、讨人开心,这个不是一个传统的产品经理能解决的,产品形态再怎么设计都很难,还是需要基础模型能力变强。
我一直比较相信高情商是建立在高智商的基础上的,首先模型要理解用户,理解用户的环境、背景、context。理解用户这个圈子在发生什么,还能举一反三。想实现幽默这一个点就不太容易,只有产品形态上的改变是不够的,也得向下改模型的性格、改数据。
张小珺:你觉得应用大爆发的关键条件有哪些?我们之前在元旦跨年的节目里面也提到了新摩尔定律,当时总结是有两条线:第一是能力上涨,第二是成本下降。今天你还维持这个判断吗?
Guangmi Li:这还是最重要的两条线。我们和用户、开发者和企业客户这三类用户做过访谈后发现他们会关注 2-3 个要素:第一是模型能力,第二是调用成本,第三是速度、latency。
假设模型能力不变,维持 GPT-4o 这个水平,如果未来一年速度再提升 3-5 倍,GPT-4o 比 GPT-4 Turbo 其实已经提了 3-4 倍的速度,如果成本还能再降 100 倍,是今天 GPT-4o 定价的 1%。那仅仅是速度提升 3 倍、成本再下降 100 倍,还是能催生很多东西的。
OpenAI 最近推出了 ChatGPT 桌面客户端,大家可以试试,非常方便,快捷键能直接调出来,我的信息检索基本上就不用再打开 Chrome 和 Google 了。ChatGPT 今天已经 1 亿多 DAU,如果客户端、手机端做得足够好,未来做到 3-5 亿 DAU 是很有希望的。到那个时候我觉得 OpenAI 是绝对可以掀翻 Google 一个墙角的。这里可以提一下,成本下降是高度确定的,但不一定是最重要的。最后还是取决于模型最后的经济价值。不是所有的 Token 都有同样的价值, Token 的质量决定了模型的商业模式,比如我今天问 ChatGPT 要买什么股票,它能告诉我买 AWS 还是 Meta,或者告诉我 Tesla 该买还是卖,那其实远比给我一大堆搜索结果、各种报告是有意义的。
单位 token 的价值是更重要的,这还是模型能力本身决定的,这个就代表着一个模型工资的高低。
张小珺:ChatGPT 告诉你买什么股票你敢买吗?
Guangmi Li:决策肯定会还是我做的。但有些基础分析我觉得慢慢可信度是在提升的。
张小珺:模型的未来会分不同的工种,不同工种的定价是不一样的?
Guangmi Li:比如我经常会问我们的分析师帮我研究一下几家公司的对比。之后交互更好其实就可以问 AI 了。模型肯定是会出错的,但是准确度和可信度都会经历持续提升的过程。
张小珺:那是需要模型在垂直领域有更深的见解、有更多的数据获取、能力更强,才能够这么定价吗?
Guangmi Li:所以 OpenAI 一定要把搜索做好才能满足更多人的检索准确度需求。比如 OpenAI 未来在金融领域的数据上再做很多的工作、做很多的 fine-tuning,那其实就能满足金融投研从业者的需求。
张小珺:未来 6-12 个月哪些是你觉得高确定性要发生的问题,哪些是高赔率问题?
Guangmi Li:高确定性的关键词就三个,第一是成本下降,第二是多模态改变交互,第三是端侧。
成本下降其实是一个时间和工程问题,而且下降的速度可能会大幅超越大家的预期。创业者其实应该按照免费的心态去想怎么构建应用?其实不惜用量,就应该用最好的模型的 API 去制定 PMF。其实未来一段时间我也想沿着成本下降这条路去看看新的机会,之前哪些场景因为成本快速下降就突然 work 了,感觉还是会出来很多的。
我预计企业级里面会比较多。比如企业有知识库、各种 Data Base。如果可以无限检索,那准确度就会提升。
多模态方面是下一代交互。Voice Agent 可能是今年最值得关注的一个方向,也就是新一代的交互界面。打字还是太消耗了,而声音大幅度降低了交互的能耗,就像触屏手机比键盘手机能耗更低。GPT-4o 是第一个端到端、声音进声音出的大模型。这个技术路线下,下一代交互的一个开始就是低延迟、高智能。
GPT-4o 的出现其实能让端到端的新交互变得更快。核心的变量是 4o 的声音 API 什么时候开放,可能短期还不会开放。手机触屏的交互模式催生了短视频,那声音的 agent 是不是能孕育一个新交互模式的抖音应用机会?谁会是 Voice 领域新的抖音?
多模态改变交互的确定性很高,决定了 AI 原生应用的下限在哪,但我更期待的是多模态未来可以提升模型的逻辑推理能力,而这个目前还不确定,那其实也是一个高赔率的问题。今天多模态的数据知识密度太低,现存的多模态数据到底适不适合 AI 学习会是一个问题。网上很多的视频都是人工剪辑后的,比如我们看到一个房子的大门后就直接进入到客厅了,人是知道怎么走过来的,但对于 AI 要怎么能一步一步的理解两段视频场景之间的逻辑关系比较重要。其次,今天多模态的泛化能力也不够,比如让模型读特定领域的 PDF 文件,如果很多地方没对齐,它其实就读不出来的还有就是假如未来 GPT-4o 就在我们的眼睛、手表、手机上装着,可以实时听着我们,那以后我们也不用 Hey Siri、Hey Meta 来唤醒它了。模型未来可以实时地插话,我觉得这也是一个更好的交互形态。
第三个高确定性问题是端侧,scaling law 是让模型变得更大,探索智能的边界和新智能的涌现能力,但大家其实远远低估了模型变小的速度。未来 6- 12 个月可能就会有一个 3B 大小的的模型也能达到极好的效果。
比如 GPT-4o 明年就变成了能跑在手机上一个 3B 的小模型,那对 PC 和手机端侧带来的机会还是比较大的。过去一年我们卷的是云端数据中心的基建,可能未来一两年,甚至更长时间我们会卷端侧的基建。今天 iPhone 的内存是 8GB,未来可能就是 12GB、 24GB 往上提升。端侧的机会是很大的,模型变小的速度也是很快的。之前不 work 的产品,比如 IoT 互联网,有可能也是会重新 work 了。
高赔率事件会有几个,最重要的还是逻辑推理能力。这个也还是不确定性的科学问题,目前有两三个路径在尝试,也有非常多的 Tricks。但大的方向上,下一代模型有更大的参数、更多高质量的数据、更大的模型,这个确定性是比较高的。还有就是解题和持续的 inference 也是提高逻辑能力的一个重点。
另外一个是可解释性的重要程度还是被大家低估了。可解释性如果能有突破,模型的可控性也就解决了。就像广告系统可以定向给模型的回答加一些针对于用户的倾向性。
另外一个高赔率的问题是模型的组织能力。全球所有的 AI 公司中,只有 OpenAI 的组织是相对工业化的。其他的 AI 公司都还有些实验室的感觉。比如好莱坞是持续的产出好电影的,导演和演员,谁被替换掉好像也都可以。OpenAI 持续做科研的成功率是比较高的,目前推出 GPT-4o、之前推出 Sora,未来还是会持续推出很多东西的,如果按照单位 GPU 来看,OpenAI 的产出肯定还是最高的。
最后一个高赔率的问题是,如果明天 AGI 就实现了,那应该是用一个什么产品来承接?产品的载体值得思考,是手机上的 APP,还是各种其他的东西?其实还有一个高赔率和高确定性的问题,GPT-5 和 Claude-4 的能力提升,我觉得大家应该乐观。
张小珺:模型变小的挑战是什么?
Guangmi Li:今天最主要的挑战是蒸馏。简单理解就是,比如我做了一个应用,应用中有 90% 的 Query 可能都是围绕 1000 个问题,这 1000 个问题我用不同的方法去问 ChatGPT,ChatGPT 给我的回答就足够我去 train 一个自己小模型的语料了。这种方法的不足是相当于让一个小学生、中学生能力的模型,通过死记硬背变得能说会道了,但其实不知道模型是不是真的智能。
其次是一个人总是能说会道,但是不会做任务,长期也是不行的。蒸馏会增加 hallucination,模型有时候不知道自己在说什么,不知道自己不懂的问题。OpenAI 训练的小模型效果可能比别的公司的大模型效果还要好。
张小珺:端侧的小模型肯定是会必然发生的吗?端侧小模型的意义是什么?
Guangmi Li:假如有一个 GPT-4o 在手机上时时跟着用户,隐私永远存在手机上用户是更放心的,但如果存在云端用户是不放心的,隐私是一个很重要的问题。如果用户有一个很强的 AI 助理就在手机上,全天 24 小时打开它,用户也是乐意的。但是在云端用户可能就不一定乐意了。
AI 消费硬件还是很多中国创业者的机会,我们也看到很多创业者在考虑 Meta 眼镜这种方向。这个形态蛮有意思的,但主要是今天的 AI 能力还不太行,但未来有可能做的事还是更多的。
张小珺:刚刚提到 OpenAI 的组织能力工业化,这个工业化体现在哪里?
Guangmi Li:OpenAI 的组织可以持续产出新的东西,做科研的效率也是最高的。比如一个很年轻、没有太多的工作经验的 PHD,到 OpenAI 一年就能产出 Sora,这个是蛮厉害的。OpenAI 的 Infra、怎么做事情、怎么做实验、怎么定目标都是很强的。未来还会有更多这种例子。
张小珺:如果只保留 1-2 个能力,接下来你觉得能力跃升的重点是什么?
Guangmi Li:我觉得是逻辑推理能力加上多模态能力。
张小珺:如果 OpenAI 的 GPT-4o 给开发者的 API 成本大幅下降,下降到可以忽略成本,哪些应用可以爆发?
Guangmi Li:我也想顺带围绕这个问题做个调研,大家可以在评论区留言。
我自己会首先看企业级应用。如果 API 成本可以忽略,那企业内的知识库、内部的数据库都可以放进去并且无限次检索,那准确率是很高的,能让企业内的 use case 落地。比如企业的客服场景,先前大家觉得大模型出来之后,AI 客服是理所当然的,但其实过去一年并没有大规模出现 AI 客服。我们前段时间做了一些客服访谈,目前反馈最大的问题,第一是大模型不够可靠,还不如 rule-based 的客服系统更可控,大模型容易乱回答,因为本质还是一个概率模型。第二个是 RAG 信息检索是很难做好的,今天是没有一个端到端、自动化、傻瓜式的 RAG 产品能让检索做得很好的。如果要精准的检索企业内的数据,那如果成本降低,企业可以大规模、无限次地试,那可能对企业内的 use case 落地是有很大帮助的。
张小珺:能不能总结一下 GPT 在过去一年定价的下降的幅度?
Guangmi Li:假如按照每 100 万 token 的定价来看,不同的三个版本。从输入端上看,最早的 GPT4-128K,对应的是每 100 万收费 60 美金。GPT4-Turbo 下降到了 10 美金,GPT-4o 下降到了 5 美金。输出端上,最早的 GPT-4 是 120 美金,GPT4-Turbo 下降到了 30 美金,GPT-4o 已经是 15 美金了。过去一年定价已经下降了 10 倍,和我们之前新摩尔定律的预测是一样的。
这个趋势其实是符合我们预期的,但我也会比较好奇为什么 OpenAI 不更激进地降价?如果它更激进降价,对很多模型公司是一个毁灭性的打击。
张小珺:你观察下来, AI 应用型的人才画像会是什么样?
Guangmi Li:年轻人,90 后、95 后。其实和一些老的人聊,感觉包袱都很大,都想把产品确定的需求规划出来,包袱挺多的,尤其是 90 后、 95 后。传统的产品是一个自动贩卖机,是有固定的按钮、固定的 SKU 的。但今天模型不是一个固定的东西,是一个随机性的概率模型,要接受这种不确定性的结果。
张小珺:可以给 AI 新物种大爆发一个时间的预测吗?
Guangmi Li:GPT-5 出来后的半年,因为需要给大家一些实验的时间。
张小珺: 为什么 GPT-5 和我们想象相比来得这么慢?去年我们很多的预期都是可能这个时候就已经出来了。
Guangmi Li:还是受限于 GPU。由于算力需求大,硬件供给还是不够。GPT-4 相比 GPT-3 是几十倍的算力提升,GPT-5 相比 GPT-4 也是十几倍的算力提升。H100 芯片大批量到货的时候已经是 2023 年的 Q4 了,集群搭起来还需要很多时间,大的 GPU 集群也不稳定,到今年初才能做大规模的训练,因为从拿到 GPU 到真正能大规模的训练可能还需要半年时间。
所以这并不是一个 AI 的问题,也不是大家提的数据不够用问题,更不是 scaling law 遇到瓶颈的问题,就是实实在在的 GPU 物理世界建设问题。其实是简简单单的需要更大的算力。随着模型变大,系统的复杂度也是指数提升的,因为模型变大以后出现的问题是大家可能之前想象不到的。
张小珺:这也 Call Back 了我们上一期节目 AGI 大基建受限于物理条件的问题。GPT-5 预计什么时候来呢?会带来哪些根本性变化?
Guangmi Li:预期是今年年底。还是应该强调下 scaling law 应该是没有减速的,虽然外面噪音比较多,但还是要相信这些全球范围最顶尖、最聪明的科学家,硅谷几个大的科技公司都是巨量投入到下一代模型中。
具体来讲,相比于 GPT-4,GPT-5 的参数上还要大 3-5 倍,假设是 5-10 T 参数,数据量也要比 GPT-4 大 7-10 倍,不排除 OpenAI 可能也会发多个版本。未来可能是会走向非常大的 MoE,参数量巨大,但是激活不一定大,激活可能做到 500D。GPT-5 能做到多模态输入、多模态输出,但很难做视频生成,视频生成的成本还是比较高的。我一直不觉得 Sora 是在 AGI 的主线中,但 GPT-5 的视频理解能力会提升。
模型变大后,GPT-5 的逻辑推理能力是能有大幅提升的,这个是对解锁应用最重要的一个关键能力。另外是多模态的交互能力变强,其实会把应用打的比较高吧。
张小珺:为什么 GPT-4 和 GPT-5 之间要插一个 GPT-4o?
Guangmi Li:为了降成本,也能省出来很多卡去给到 research。这是一个最简单的原因。成本下降的速度还是超出我们预期的。
张小珺:硅谷大模型公司格局在牌桌上发生了什么变化?
Guangmi Li:过去半年,硅谷的格局用简单的一句话说就是 GPU 决定生死线。今年和明年分别对应两条生死线。今年年内如果模型公司还没有 3.2 万卡的集群,那这家公司肯定就不在第一梯队了。到明年,第一梯队的门票是 10 万卡集群,这里是指 H100,因为 B 系列可能要明年这个时候才能大规模到货。这是一个明牌,拼资源、拼决心大不大。GPU 资源的竞争也会加速二、三线模型公司出局或者被收购的过程。比如像 Character AI、Mistral、Cohere。Elon Musk 拿到了最后一张门票,如果 Meta 想入局,还是得收购公司。
张小珺:中国公司在过去半年的梯队有变化吗?他们的生死线是什么?
Guangmi Li:今天这七八家还挺模糊的,从今天的模型能力上来看其实很难分辨哪家公司一定是最好的。从今天的模型能力上来看,是很难拉开的差距形成断崖式领先的。目前是交替、都有一些亮点,第一个分水岭就是哪家公司真正开始 GPT-4 水平的试训练,拥有 8000 张 H100 量级的集群,但是今天好像还没开始。
张小珺:Musk 的 xAI 相当于自己给自己造了一张大模型门票?它有什么差异化吗?
Guangmi Li:可能存在一种暴力美学,因为 Elon Musk 公开提到了 xAI 就是 bet on 10 万卡集群,而且是全球第一个,可能今年 8-9 月份上线充分互联、全液冷的 10 万卡集群。这意味着一个月可以 train 10 个 GPT-4,迭代速度变快了,并且可以更早训练下一代模型。
我很期待这个超大集群未来能出来哪些新东西。xAI 如果比其它模型公司更早 6 个月做出来 10 万卡集群,那是有弯道超车机会的。Elon Musk 觉得 GPU 是最重要能决定生死的资源。此外,xAI 的团队还是很强的,可以看看他们未来能不能很快发出来接近 GPT-4、Claude-3 水平的模型,我还是比较乐观。
张小珺 :据你了解大模型公司工作节奏怎么样?他们卷不卷?
Guangmi Li:工作节奏是非常卷的。我听过一个很形象的比喻,大基建很像西部拓荒,OpenAI 内部的状态就像一个从东向西的火车来开拓美洲大陆,科学家让火车在高速奔跑, Infra 工程师在前面修铁路,铁路铺设和火车行驶是齐头并进的,你就能感受到这种状态。很多人说硅谷下午 4-5 点就下班,这个印象不是全对的。做大模型的人都是很卷的,基本的休息时间、运动时间几乎全没了,每天都在一个很卷的战斗状态。因为没解决的问题比解决的问题多,而且新问题也非常多。
OpenAI 是最卷的,而且人才密度也确实是最高的。有一个朋友提到连续 5 天平均每天只睡 3 个小时,睡前和醒来就是在 train Model。
张小珺:整体来看,过去一年你觉得在大模型上中美差距是放大还是缩小了?
Guangmi Li:有一个非共识的观点是真实差距可能在拉大,而不是表面上看着真的追上了。更准确的说应该是可以局部追上,比如热门问题的问答,但是国内模型处理长尾的问题其实都还不太行,这个就说明模型的泛化能力还是不够的。最核心的是今天我们不知道 OpenAI 内部走到多远了。GPT-4o 到底代表 OpenAI 的几成功力呢?有可能只占三成功力。OpenAI 的人才密度很高,也都是非常聪明的人,而且有最领先的模型,也能更早拿到了更大量的 GPU、做更多的探索。只是探索的结果已经不公开了。用 5% 的资源就想真正超过 OpenAI 百分百的投入还是比较难的,除非说第一名成为先驱。人才密度角度上看,OpenAI 的一个人还是能顶其他公司的十个人。
Sora 团队可能也就不到 10 个人,别的公司可能几十个人也不一定能做出来一样的模型。
外界是希望更早、更快地看到一些新的进展,但模型变大后,需要处理的细节还是很多的。过去 GPT-4 其实是一个技术发展史中的跳跃时刻,那不可能每年都有这种跳跃时刻的,因为大家的预期变高了。不跳跃大家可能就觉得无聊了。然后其中很多细节、各种产品的打磨,需要的工作量还是比较大的。里面是一个优化打补丁的点,大家都还是基于 Python 来做的,只能每次处理一个事情,执行起来其实是不够 Efficient。最近也有人提出基于 C 语言手搓一个大模型,只是说大家还没有大规模试起来,大家对模型结构的优化做的还是比较多的,只是外界可能没有谈到。
张小珺:在 GPU 上中美差距拉大了吗?
Guangmi Li:国内应该还是小几千张 GPU 做训练,而硅谷的一线模型应该都是 2-3 万卡的集群做训练了,下一阶段是 10 万卡集群。Elon Musk 还提到自己有 30 万张 B100,这就对应了 60 万张 H100。国内可能首先要突破万张卡和万亿参数 MOE 这两个临界点,我也不知道未来怎么去追赶 10 万卡集群,而且 OpenAI 和微软的星际之门(Stargate),投入 1000 亿美金搭建新的超级计算机。如果这件事情真的在发生,不知道怎么去追赶。
张小珺:Benchmark 上看国内模型是追上来了。
Guangmi Li:模型评估是很难的,就像评估一个人一样。Benchmark 的题目全是公开的,也都可以围绕题目做提前的充分训练。可以理解为这个榜单已经被 Hack 掉了。另一方面是蒸馏,国内模型做蒸馏还是比较多、比较凶的,很多人在 distill 头部模型公司的数据。最终模型的经济价值还是取决于是否能做任务。国内模型这么多,其实也挺难说哪家是真的好,今天可能还是模糊的状态。短期模型能力是不决定胜负的,还是真正看谁先做出 GPT-4 水平的模型。但是做出来 GPT-4 水平的模型又会怎样呢?下一阶段可能会是,哪家公司先能有 3000-5000 万 DAU 的产品占住心智,留存好、商业模式跑通,这个比较重要。
张小珺:接下来我们来聊聊大模型的商业模式和壁垒。大模型是一个好的商业模式吗?
Guangmi Li:目前肯定没有广告平台的商业模式好,订阅还是一个比较传统的商业模式。
ChatGPT 现在是 1 亿多的 DAU,假设 10% 的付费用户,那就是 1000 万付费用户,订阅 200 美金一年,总数就是 20 亿美金。假如未来能翻几倍,那相比 Google 广告平台一年 2000 多亿美金的营收,也还只是 Google 营收的 1%- 2%,是比较小的。
广告平台是一个非常成熟的商业模式,每新增一个用户,在未来 6- 12 月肯定是能把新增用户花费的成本赚回来的,这个 ROI 是能算得很清楚的。
但大模型投入,购买 GPU 的 ROI 是没法计算而且很难分析的。因为这里面兼具着很多科研属性,而且失败率比较高,失败的成本其实是 GPU 的时间,一张 GPU 运行一个小时的成本假设是 3 美金,那一张卡一个月可能就是 200 多万美金成本。用不好 GPU 就是在浪费成本。
但从另外一个角度思考, GPT-4 当年的训练成本假设是 2 亿美金,OpenAI 已经通过 ChatGPT 早就赚回来了这个钱,单看 ChatGPT 这个产品好像是盈利性很好的,他们的亏损主要还是在探索新的模型技术上。
这就很像药企的新药研发,也许 GPT-5 还能发现下一个新药,也能帮 OpenAI 赚更多的钱,但从全球范围看,可能也只有 2-3 家模型公司通过卖模型可以把训练成本赚回来。其实很多模型公司连训练成本还是赚不回来的。
新事物的商业模式总是要慢一些。比如 AI Agent 落地后会不会颠覆广告平台?用户让一个 Travel Agent 帮忙规划一个意大利的旅行计划,用户的精力和注意力是有限的,其实是被迫看了很多广告。那如果有一个 Travel Agent,其实就不用看太多广告了,而是让 Agent 帮忙比价、谈价。这对传统广告平台是有很大颠覆效应的,传统的广告平台是建立在人的注意力和精力是有限的情况下,但未来 Agent 是 7* 24 小时工作。
包括之前播客提到未来能不能有一个 value-based 的定价,类似于在电商平台卖掉 1 万块钱商品要给电商平台付 5 个点左右的抽成。那未来用 ChatGPT 的 Agent 增加了 1 万块钱每月的产出,给 OpenAI 付 500 块钱, 对应 5% 的抽成好像也合理。
而且今天模型的 API 切换成本是不高的,用户很容易换,也因此很容易产生价格战,整体来看感觉还不是一个最好的商业模式。
张小珺:听起来最后好的商业模式还是建立在产品和应用上,那会是什么样的产品?如果 AI 助手的产品都是帮助用户节约时间,那它就让广告投放天然会变得比较差?
Guangmi Li:是的,任何一个伟大的公司都是建立在极好的商业模式之上的。广告、类似 Apple 这种科技消费品、公有云平台,都具有规模效应,包括电商平台。AI 公司想成为伟大公司,还是要有极好的商业模式。今天商业模式的 0 到 1,这个 1 我觉得还是没有跑通的。
张小珺:产品角度跑通了吗?AI 助手是不是一个好的产品形态?
Guangmi Li:不知道,核心还是看是不是足够聪明。如果足够聪明,那就相当于 AGI 来了。很多商业模式都会从本质上发生变化,广告平台也发生变化了。
张小珺:大模型的壁垒在哪里?
Guangmi Li:壁垒是明牌。第一阶段就是 GPU,第一梯队如果没有 3.2 万卡,今年就很难在硅谷坐稳第一梯队。但其实背后更核心的点,是要具备 30-50 人的核心人才团队。今天很难再重新 build 一个像 xAI 一样团队了,因为人才收敛比较快的,最后可能还是一个综合的壁垒。比如说像好莱坞,有没有工业体系和成熟的组织方式决定了效率。如果给了卡,也投入很多钱,但最后科研的效率很低,那也很容易掉队。
张小珺:现在很多人开始说 scaling law 不一定是唯一的路径,或者是错误的路径。你觉得会有不一样的路径能走向 AGI 吗?
Guangmi Li:Scaling law 是最简单的路径了,因为简单粗暴地怼 GPU 就能通往 AGI,如果成功就可以造福人类,失败也是科技巨头买单,那其实是应该继续加大投入的。
很多人也在关心另类的架构,其实肯定 OpenAI 是更关心另类架构的,新的架构 OpenAI 应该全都试过了,但至今是没有发现其他新的、真的 work 的路径的。如果有,大家肯定就扑上去了。今天还有很多人质疑 transformer ,其实是不是 transformer 也不重要了。最重要的还是什么架构既能满足持续的 scaling up、又能具有通用的泛化能力,这两个能力是 transformer 最大的优势。但 transformer 今天最大的缺点是 data hungry,其次是 compute hungry,要消耗很多的数据,消耗很多的卡。data 和 compute 效率是头部模型公司目前在解决的。有可能未来的架构还是以 transformer 一个底座,有本身优秀的特性。上面加一些能让 data、compute 更 efficient 的新架构。
这里有一个高赔率的问题,是研究怎么提高 data 和 compute 效率的问题,让小样本数据也能取得很好的效果。比如教一个小学生解方程,可能教个几十次慢慢就能教会了。但是今天要教给模型,可能要教几万次。随着模型能力变强,可能未来几百个也就够了,甚至说模型能力更强了之后可能教他两三个就够了,这就是一个数据的效率吧。其实在模型架构角度,像 OpenAI、Anthropic 其实对 transformer 的动刀幅度已经很大了,比如马车早已经没有了马,已经变得四不像了。
其次也要看大家对 AGI 的预期。AI 并不完全需要像人,人机互补是更重要的。比如 AI 很擅长数据吞吐量特别大的工作,可以并行读取、加工很多的数据。而且 AI 比人更擅长学习,能从大量的数据中找到最大公约数。今天 AI 数据量小的时候是不如人的,但 AI 也有更擅长,比如它可以 7* 24 小时工作、提供经济价值。如果逻辑推理能力提升之后还可以 7* 24 小时帮用户去执行推理的工作。
只要能创造经济价值就好了,不一定需要完全 follow 人的工作,马车也没有马,就是轮子,效率也比较高。AGI 即便无法实现,下限也是非常高的。AIGC 在数据量很大、套路很多的领域是更有优势的, AI 提供了智能的劳动力,人是智能的创造力。
基于 scaling law 让模型变大其实主要是在探索智能的边界,并不是模型一定要保持一直很大的状态。未来人们把模型变小、进行大规模商用的速度也会是很快的,是一个时间和工程的问题。
张小珺:在大模型的应用侧,除了 AI 软件,其实还有通用机器人和无人驾驶,你怎么看待这两条腿的落地?
Guangmi Li:通用机器人的大脑未来就是多模态大模型的底座,再加一些针对机器人数据的 fine tuning,我觉得是不存在独立的机器人大脑模型的,其中有一个难点是怎么从大脑的智能规划能力转化为控制信号,这是未来需要大规模铺设设备基础上才能继续做的。硅谷的通用机器人公司,除了 Tesla 外,都不具备制造硬件本体的能力,硬件大概率还是中国公司的机会。控制部分比较难,中国的供应链优势还是非常强的。
还有个点比较有趣的是今天想做通用机器人的公司还没有一家能定义出来一个真正好的场景的,所以大家就只能先把通用机器人开发出来,就像当时个人电脑开发的过程一样。大家也不知道怎么用,最后大家发现 PC 的第一个场景是报税,于是企业内部报税先用起来了。
所以有可能通用机器人明年可以大规模的做出来让大家去试,有可能餐厅老板我能用把机器人起来,或者酒店老板说我能用起来,到最后就是大家去试场景的过程。
张小珺:通用机器人和无人驾驶哪个会落地更快?
Guangmi Li:自动驾驶更快。Tesla 团队是比较自信的,觉得可能 2 年内可以结束战斗,通用机器人可能还需要 5 年。因为自动驾驶是一个限定领域,总共有几个 action:往前走、刹车、左转、右转。但通用机器人的目标还没有定义清楚。而且无人驾驶领域 scaling law 和成长速度还是比较快的,也比较期待接下来 8 月 8 日 Tesla Robotaxi 的发布,可以看看到时候还有没有方向盘,如果没有方向盘那是真的比较自信了。
张小珺:FSD 这一年有什么进展?两年内结束战斗能结束到什么程度?
Guangmi Li:从 Palo Alto 开车到三藩基本不用碰方向盘了,甚至不用碰方向盘了。这已经是一个挺大的进步了,FSD 的安全性已经比人要高很多了。FSD 的终局可能是Tesla 一部分车型可以没有方向盘了,这样的话它就可以重新定义“车”这个产品了。
张小珺:我们接下来聊聊过去半年巨头都发生了什么。OpenAI 变化也很大,Ilya 离开了,也造成了一个小的 OpenAI 离职潮,这种离职风波对这家公司影响大吗?可以先讲讲怎么看 Ilya 的离开?他的离开对于 OpenAI 的影响大不大?
Guangmi Li:有两派观点,一派是认为 Ilya 过去几年贡献不是很突出,另外一派认为 Ilya 的 research taste 非常好,讲的都是未来三五年决定性的事情。
我感觉 Ilya 的离开对于 OpenAI 几乎没有任何影响,OpenAI 最核心 100-200 人是没有变化的。其他的公司像 xAI、Anthropic,或者其他模型公司想挖人几乎是挖不动 OpenAI 最核心的人的。新加入的人主要还是围绕产品、商业、安全这些方面。最核心的底子是非常稳且非常强的。
张小珺:最近 Apple 举办了发布会,大家的关注度比较高。你怎么看 Apple 这次的发布?
Guangmi Li:Apple 还是很稳的,未来三年手机可能还是人们最方便、最可信的设备。今天好像看不到哪个设备真的能够替代手机。之前出现了很多 AI 消费设备,但更多还是一个补充。对苹果最重要的一个判断是 AI 的 feature 能不能带来手机的换机潮?这个是对 Apple 商业上最重要的一个判断。其次是能够加上什么样的新 feature?比如内存很大、端侧模型能力足够强,能够刺激用户愿意买一个新的手机,或者 Siri 真的变得极其聪明了、有其他的 features 出现,促使用户去买一个新的手机才是一个更大的变化。
硅谷的科技巨头股价都已经涨了那么多,真的要挑一个能用妈妈养老的钱买的公司股票,我可能还是愿意买 Apple,虽然估值也不便宜。
张小珺:为什么 Apple 这次发布会以后股价大涨了 7 个点?
Guangmi Li:因为大家发现 OpenAI 没有颠覆巨头,并且最后都要求着巨头。
张小珺:Google 呢?
Guangmi Li:Google 的模型进展好像是不是很乐观。从 Gemini 1.5 之后大幅的提升是没有的。Google 的流量优势还是很强的,但好像模型还是差一点意思。不知道具体原因是什么。
张小珺:英伟达呢?
Guangmi Li:英伟达现在 3 个 T 的市值和股价已经提前 price-in 了未来一年半到两年的预期。大家对英伟达的股价争议还是比较大的。
其实今天从股价角度讨论英伟达已经超出了可分析性,有特别多人对英伟达极其有信仰,其实越来越多人今天讨论英伟达和 2021 年讨论比特币一样,都在讨论信仰。但确实从实际角度来讲,英伟达没有竞争对手。全球范围的模型公司 train 模型,除了 Google 用自己的 TPU train model 以外,几乎所有人都是用 GPU 来 train LLM 大模型。未来两三年的竞争格局也是极其稳的,不太会有新的公司,完全颠覆英伟达了。
但是 AI 的变化是很快的,叙事上变化也是很快的,可能会影响大家对它的预期。长期英伟达肯定还是极其重要的公司,是整个 AGI 基建中最关键的一个要素。就像 Elon Musk 说的 GPU 定生死,英伟达还是一个最重要的角色。
张小珺:Amazon 呢?
Guangmi Li:我们之前有一个感觉是模型 to 企业侧最大的客户是云平台,因为云与企业建立了最深的信任。先前也有说法是在大模型上花一块钱,就会在云上带来 5 块钱的营收。我们一直想把这个假设调研清楚,但是一直没有找到太多的 facts。企业除了测试以外,在 cloud spending 层面还没有大规模的新东西出来,因此可能还是需要花一些时间。但是云还是很稳的,很多企业客户不是直接调用 GPT、Claude 的 API,而是调云厂商的 API。因为云更稳定,可信度更高。Azure 之前的声音很大,但比较下来 AWS 的技术积累与客户积累还是很 solid 的。
张小珺:Meta 呢?
Guangmi Li:Llama 3 400B 的模型一直还没有发出来,据说是内部还没搞清楚 MoE 怎么做。Meta 好像一直在 train,train 到一个好的结果再发出来。这个模型不一定会开源了,因为这么大的模型如果再开源,很多人是用不起来的,而且成本比较高,是一个 400B 的 dense model。
张小珺:微软呢?
Guangmi Li:首先,Copilot 距离先前的预期还是要差一些。我印象最深的还是微软和 OpenAI 提出了星际之门,投入 1000 亿美金造一个最大的超级计算机,具体会怎么实施,以及到底能带来什么样的突破,这两点会是最有意思的。
张小珺:Tesla 的变化是什么?
Guangmi Li:EV 的销售竞争是很激烈的,所以车本身是很被动的。FSD 每隔几个月就有一个大幅提升, xAI 未来一段时间可能有很多间接的技术助力。我感觉 FSD 的进度可能是比 AGI 要更快的。
今天对特斯拉一个比较大的争议是特斯拉到底是一个车的公司还是一个 AI 的公司?但目前 AI 的 revenue 还是没有的。如果是作为车企的话那可能就是一个比较低的估值。AI 怎么体现出来是比较重要的,而且 100 美金每个月的 FSD 定价是比较高的,如果说 FSD 免费了,或者说通过车险来间接付费,可能会是一个更好的做法。因为 FSD 对车险未来的冲击还是比较大。
张小珺:台积电呢?
Guangmi Li:全球 100% 的 H100 都是台积电参与生产,这个公司的重要性是极强的,因为过去卷了云端的数据中心,下一步又要卷手机上的芯片, Apple 还是台积电的最大客户。所以感觉这么大体量了每年还能有 50%的增速是极其厉害的。台积电未来几年也是不可替代的。
其实我们聊的这几个大的公司,潜在都还是受益的。拿着这几个大的公司做一个 Passive 的指数,是能跑赢很多其他产品的,反而这一波是强者恒强的局面。AI 公司并没有真的颠覆大的公司,而且是依附于大公司。
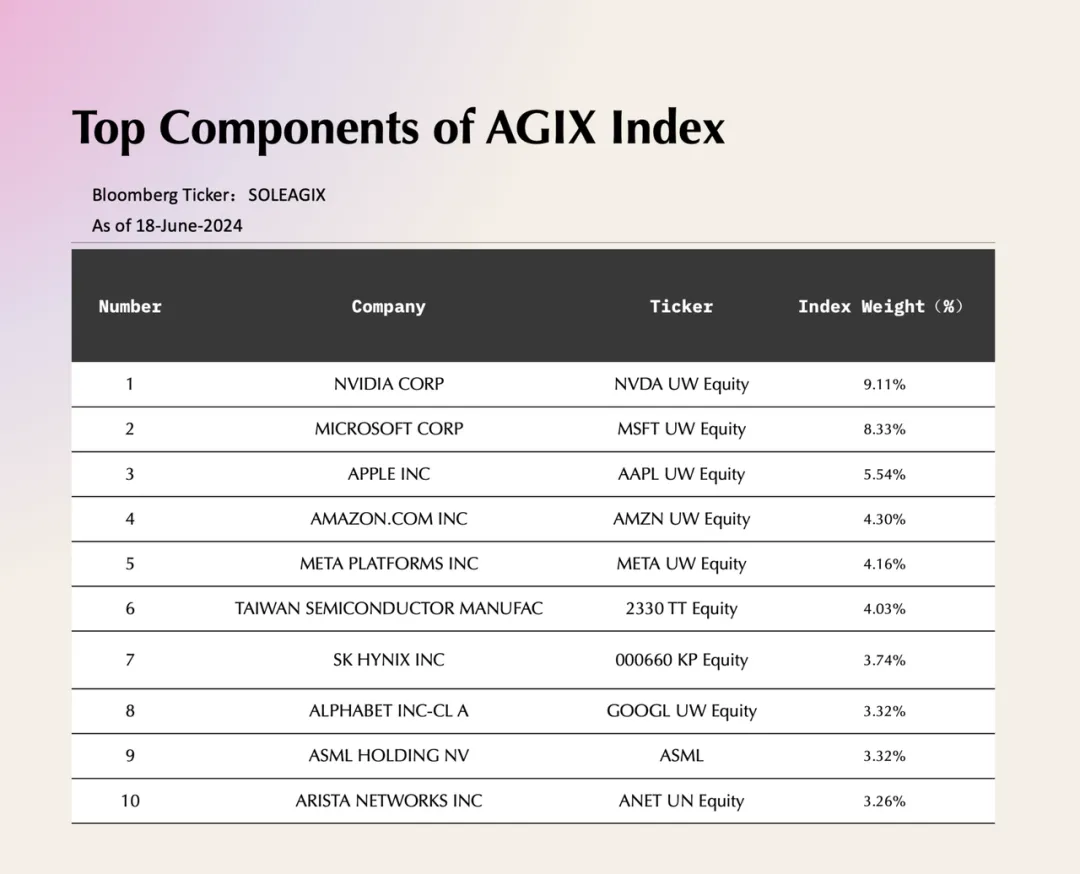
AGIX Index Top10 Components
张小珺:今天的 AI 公司都活在巨头的阴影下,这是为什么?
Guangmi Li:第一,太烧钱了。第二, AI 的能力还是一个小学生、初中生的水平,还需要时间慢慢长大,还要大公司给钱继续再养着,估计还得养一段时间。
创业公司和大公司不是颠覆关系,而是依赖关系。第一,AI 公司还是太花钱了。第二,巨头的卡位太好。今天 OpenAI 是没法撒开腿跑的,因为它逃离不了几个科技巨头的覆盖。GPU 受限于英伟达,如果英伟达不提前给 OpenAI 卡,或者说英伟达给第二名、第三名模型公司卡,那 OpenAI 也会卡不足。GPU 的集群的搭建是受限于微软的,微软还是 49% 的大股东,金主,微软的 Azure 是 GPT 触达企业客户最重要的一个渠道。
C端还是逃离不了苹果,最后还要求着苹果集成 ChatGPT。苹果其实还是可以分分钟换掉 ChatGPT 的,所以 OpenAI 如果真的颠覆,目前也只能挑战一下。
张小珺:AGI 时代 VC 投资变难了吗?
Guangmi Li:我觉得是变难了。现阶段面对的很多问题是科学问题,不是一个可分析的数学问题或数字问题。如果今天投大模型,依然是两条标准,第一,这个公司是不是一个做 AGI 的团队?是不是真的奔着 AGI 在前进、 有 Vision,也有团队基础?第二,有没有大腿支持做 AGI。模型公司每年要买 10- 20 万张卡,要几个 Billion 的投入。背后是有一个巨大、长期的资源支持问题,这个是非常重要的。AGI 竞赛的正赛还没有正式开始,大事还没有发生。
比如很多人提 RAG,几十家公司在做 RAG 这个方向,其实今天还是很难分析哪一家公司一定能跑出来,因为应用还没有大爆发。那今天的 RAG 产品还没有经历过大的考验,经历过大的考验后杀出来的公司才是比较重要的。
张小珺:为什么突然开始提 RAG 提的比较多?
Guangmi Li:有人说 RAG 是阶段性需求,因为企业内有很多样的各种信息要检索, LLM 只用通用的东西是回答不了的,所以需要有检索增强,把企业内的各种知识能检索、排序理解得比较好。因为没落地,那就要一个 RAG 的产品来帮它,但发现加了 RAG 之后,首先今天还没有太多人能做好 RAG,第二,做好了之后依然还没有弄好。RAG 做得最好的还是 Perplexity 里,它是检索网页检索的最好的。
张小珺:RAG 的核心难点是什么?Perplexity 为什么做得好?
Guangmi Li:RAG 是一个工程问题,有十几个环节都要优化。一个公司优化好一个环节比较容易,但是要优化好 10 个环节其实是很难的。
张小珺:对比下来你看美国和国内这两边的创新生态在 AI 上有什么差异?
Guangmi Li:硅谷 0 到 1 还是比较多的,而中国的创业者 1 到 100 非常多。这是一个非常明显的体感差异,背后是资本的充裕程度。硅谷长期能 0 到 1 创新挺重要的背后是容忍了非常多的失败。即使有人失败了后,他的公司依然还能被收购、还能退出。硅谷的收购环境也比较好,感觉硅谷还是一个创新的温室,很多人可以异想天开,因为有比较充足的 VC 资本支持 0 到 1 的创新。
国内 1 到 100 更多,这里面会导致一个问题:技术辨识度还是比较低,而且创业的玩家比较多。内卷有很大的原因是技术辨识度比较低,比如今天没有公司与 SpaceX 竞争,甚至说今天要买一个无人机,人们不知道大疆的第二名是谁?大疆是有技术辨识度的。我是期待更多的 0 到 1 创新的,创业者能提出一些更不一样的,也需要更多长期的风险资本的支持。
张小珺:最后我们来做一个展望, 2024 年下半年你会更愿意把时间花在哪里、会重点关注哪些问题?
Guangmi Li:第一是关于成本下降,因为这是一个高度确定的事情,那我希望围绕成本下降速度提升,哪些应用原本不 work,最后 work 了,这是值得期待的。
第二个比较期待端侧,手机上能加哪些新的东西,尤其是国产手机,包括新的消费设备,可能是对手机一个很好的补充,比如像 Meta 眼镜可能就是一个多模态的入口,与手机有一个更好的辅助,那端侧可能会出来很多东西。
第三是通用机器人,通用机器人需要的时间会很长,但是会很有意思,因为多模态模型在进步。中国创业者的机会还是很多的。
本文内容仅为研究分享,不作为投资建议。
文章来源于:微信公众号Founder Park




【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
