# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
现在开发一个APP需要多久?
“云计算一哥”亚马逊云科技,深夜给出了一个新标准——
只需三步,几分钟,纯靠自然语言和鼠标“点点点”即可。
话不多说,直接展示!
第一步:说出你的想法
我们首先可以直接用自然语言描述一下想要打造APP的需求,例如:
为我的团队创建一个应用程序,可以通过一个表单提交项目审批。这个表单将接受详细信息,并允许用户上传相关文件。
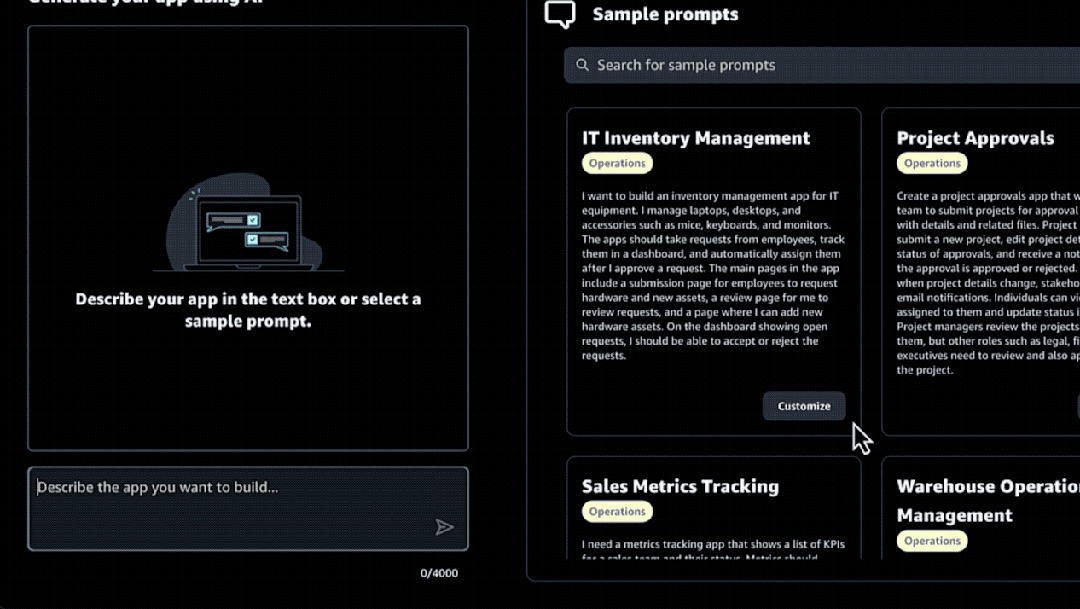
静候几秒之后,这个AI便会根据你的需求,分析总结APP的用例、流程和关键特征等信息。
在确认没问题之后,我们就可以点击右下角的“生成APP”按钮。
第二步:编辑APP
在这个可视化的界面中,我们可以进行编辑用户界面、数据对象和自动化等操作。
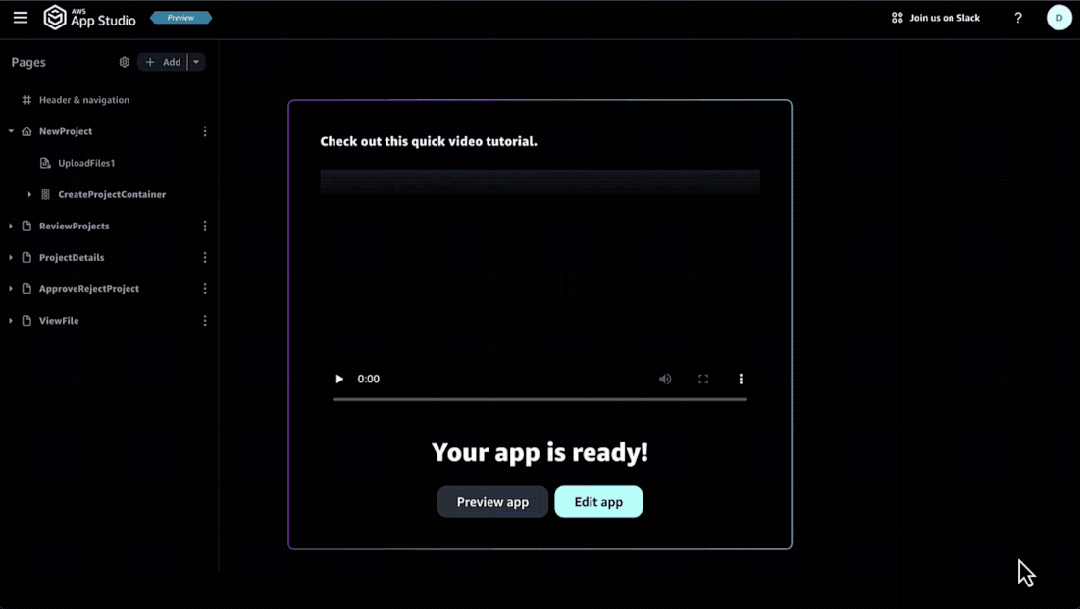
无论是给APP添加新元素或者新页面,都只需要一个“拖拽”的动作——把右边的组件拉进来。
而且所有的改动都会自动在你开发的APP中实时生效,可以随时进行预览。
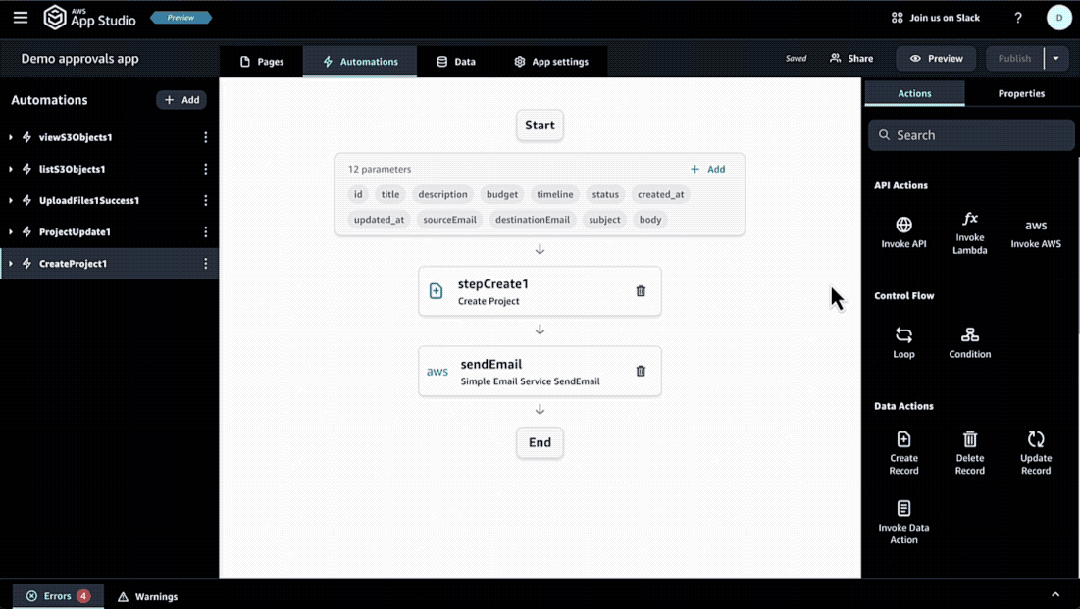
第三步:准备“上岗”
在完成所有的APP配置工作之后,我们就可以把它部署到测试环境里进行测试。
确认无误之后,就可以上线使用了。
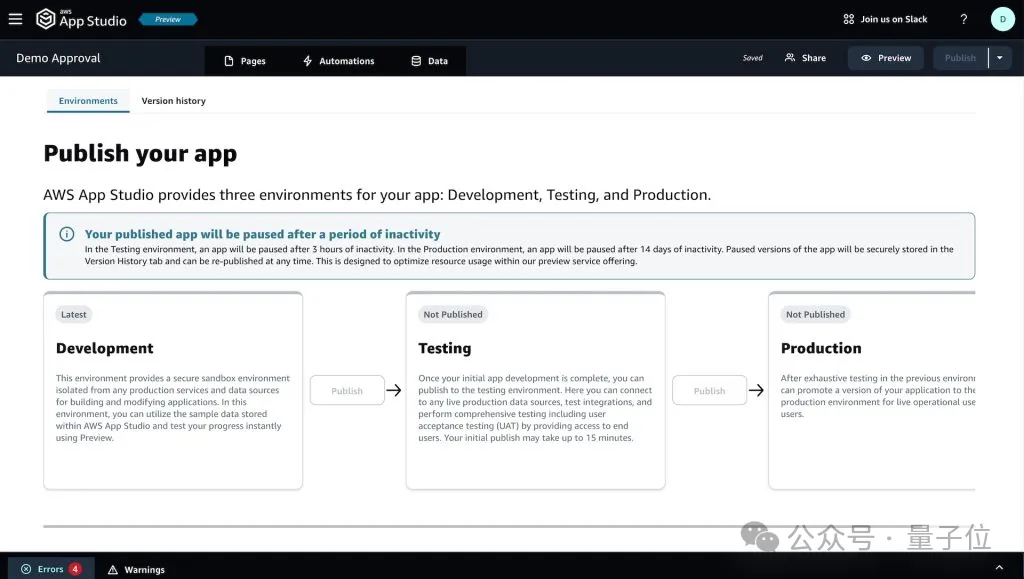
而且日后要是有内容、功能上的更新,操作上也都是像上面的步骤一样,是所见即所得的那种。
这便是亚马逊云科技在深夜的纽约峰会上正式发布的一项新功能App Studio。
亚马逊云科技AI产品副总裁Matt Wood在现场还表示:
App Studio是构建应用程序最快、最简单的方式。

然而纵观亚马逊云科技的整场活动,App Studio还只是新发布中的一隅。
最为直观的感受便是塞满了生成式AI——
应用层、模型层、算力层,层层都有新动作。
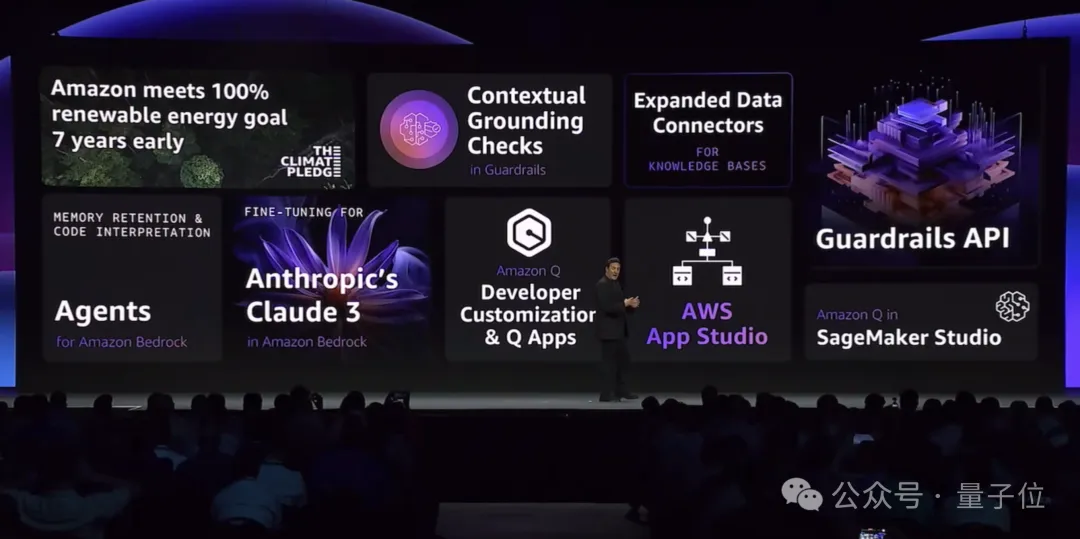
在生成式AI应用层方面,除了刚才提到的App Studio之外,最具代表性的,便是亚马逊云科技面向企业和开发者推出的Amazon Q了。
而就在今天的活动上,开发者版本Amazon Q Developer也展示了它非常AI的一面。
例如给定一段代码,我们现在在IDE中只需点击“Explain”,它就能快速对代码做解读。
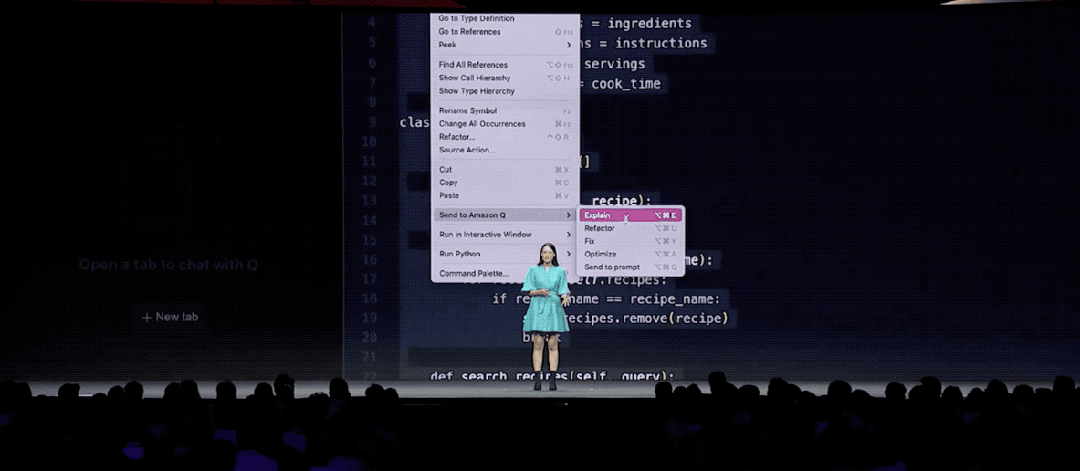
选定特定代码片段,同样是一个点击的动作——“Fix”,还可以对其做修正工作。
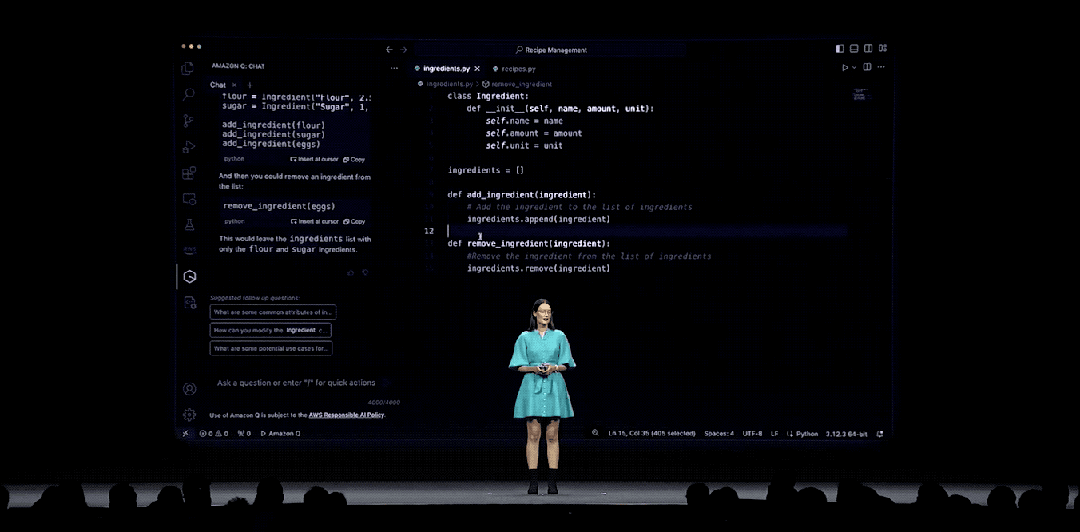
如果有对代码不清楚的地方,还可以用自然语言提问,Amazon Q Developer“啪的一下”就可以给你答疑解惑。

除此之外,Amazon Q Developer今天还上新了自定义(Customization)的功能。
简单来说,就是开发者现在可以在内部库、API、包、类和方法中找到更加相关的代码推荐了。
例如一家金融公司的程序员,要编写一个函数来计算客户的总投资组合价值,那么他现在仅需在注释中描述意图或键入函数名称(如computePortfolioValue(customerId: String))即可。
而后Amazon Q Developer就会从私有代码库中学到的示例建议代码来实现这个功能,是更符合“本公司宝宝体质”的那种。
如此一来便让生成式AI更加贴近程序员们的诉求:

那么对于这项功能的结果,程序员们买单吗?
Matt Wood在现场给出了英国BT公司在使用Amazon Q Developer后的真实数据:
代码接受率达到了37%。
成功将超过20万行的代码转换并部署到了生产环境中。

由此可见,现在编程这件事的门槛,已经被亚马逊云科技的生成式AI给打下去了。
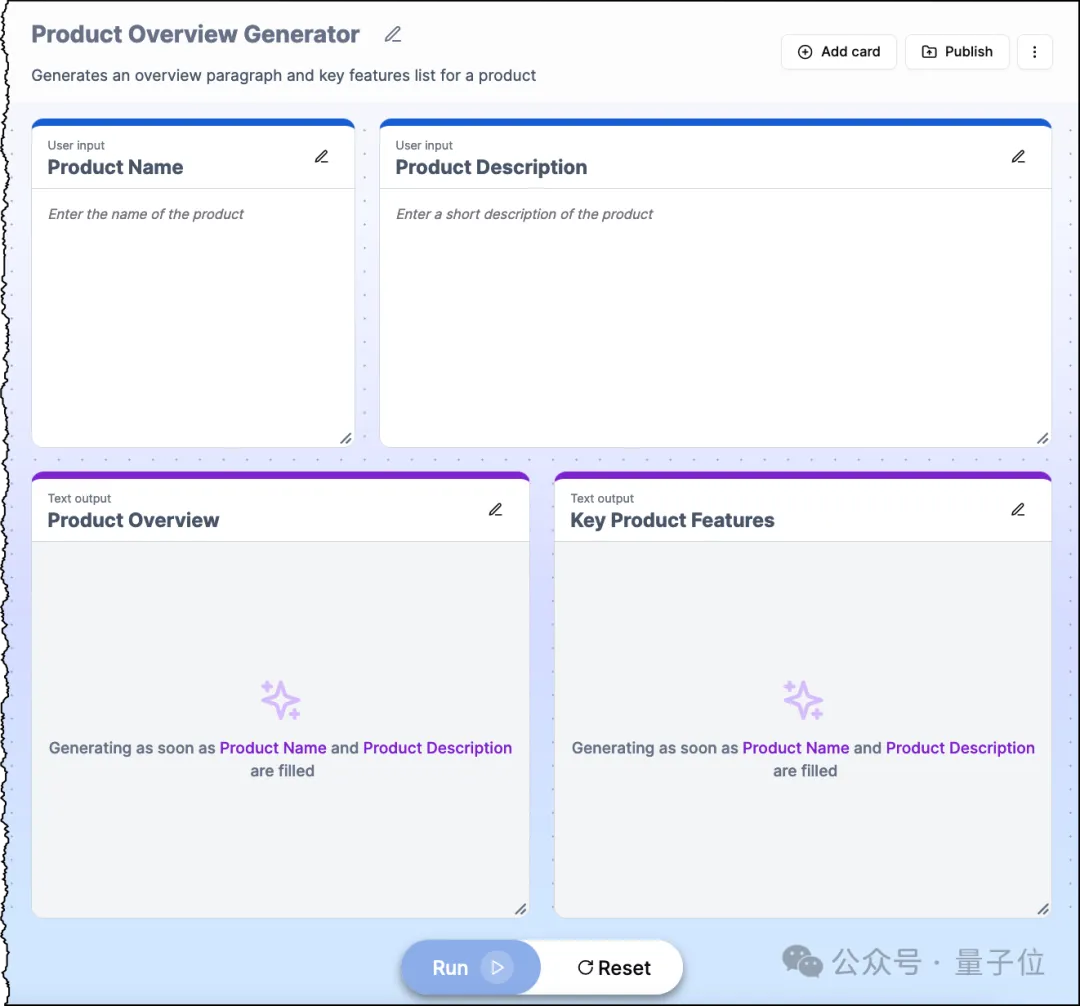
此外,Amazon Q Apps在今天也正式可用,同样是只需要自然语言,就可以轻松打造一个企业级App。
亚马逊云科技的大模型能力对外输出,主要依靠处于模型层的Amazon Bedrock。
简单理解,Amazon Bedrock是一个集成了多种先进AI大模型的平台。
只需单个API,就可以提供包括Claude、Mistral、Llama、Stable Diffusion、自研Titan系列在内的30多个模型的能力。
目前让大模型变得更聪明的方法之一便是检索增强生成(RAG),此前的Amazon Bedrock已然是支持这个功能的。
而就在今天,亚马逊云科技在数据层面上做了进一步的更新——
除了可以选择原先的Amazon S3之外,现在的数据源开可以pick来自Web爬虫和第三方的数据。
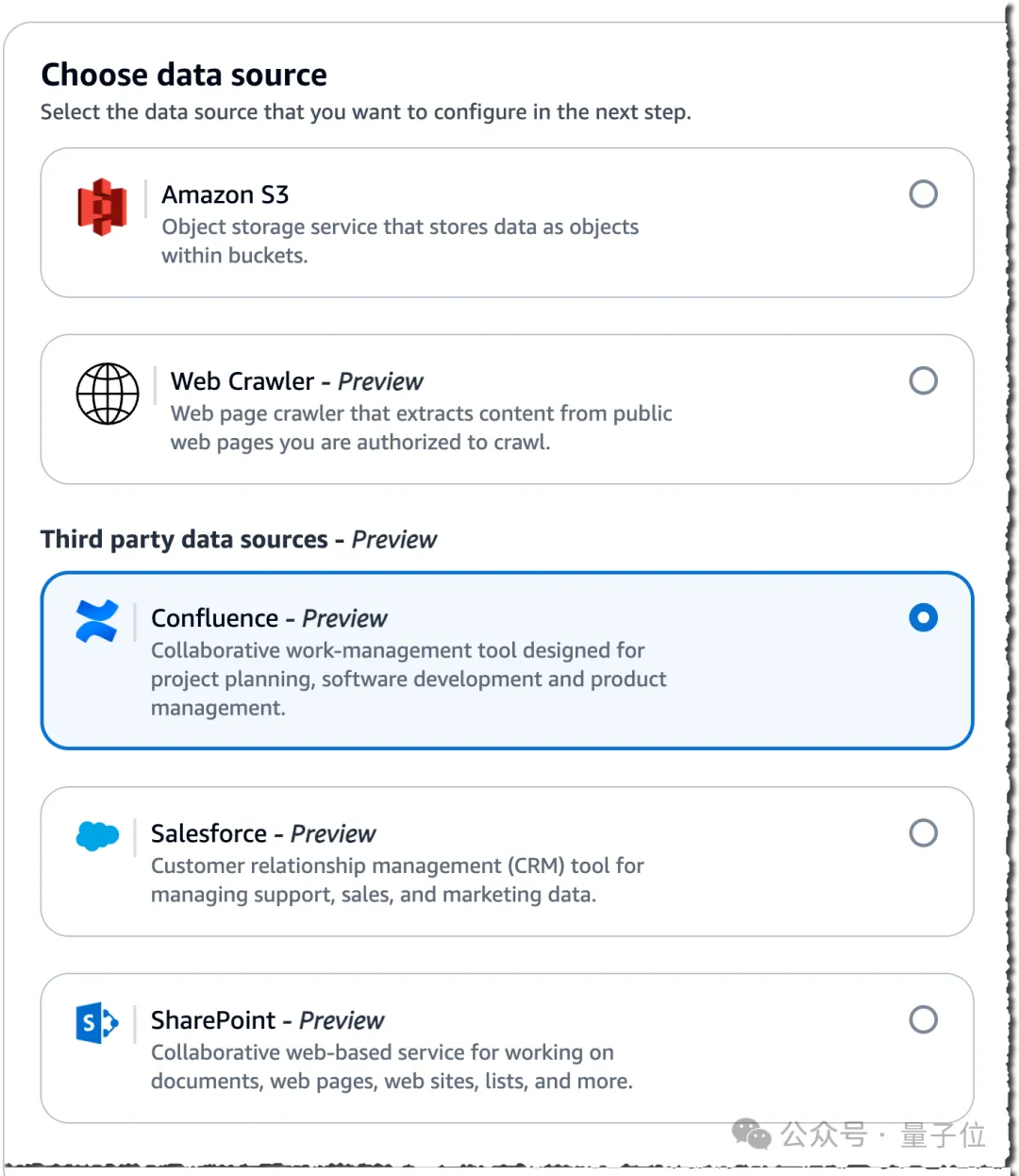
例如以Confluence作为数据源为例,只需简单的4步就可以完成操作。
包括为数据源提供名称和描述,选择托管方法,并输入Confluence URL等。
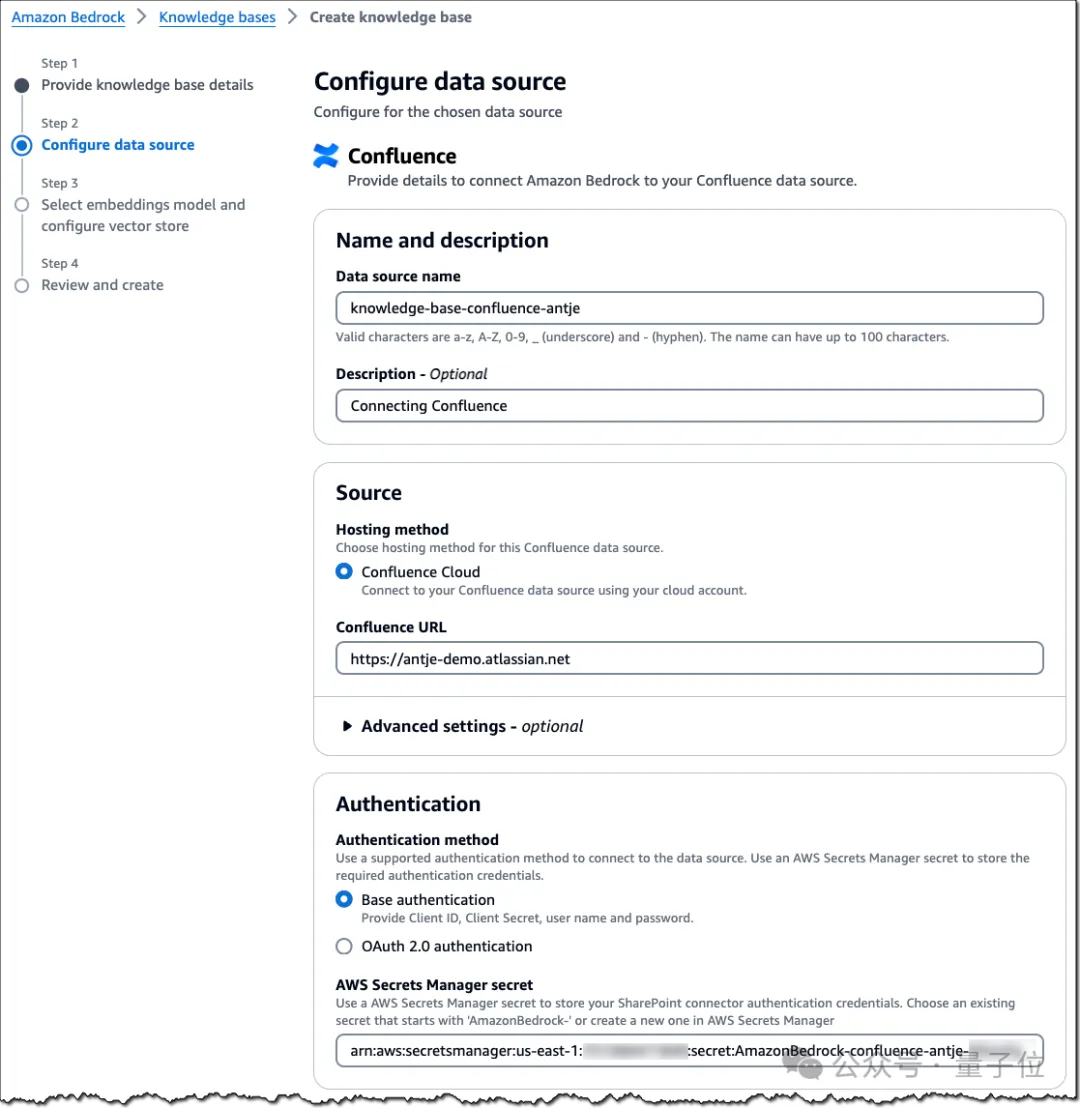
在完成Confluence数据源配置后,便可以通过选择嵌入模型并配置所选的向量存储来完成知识库设置了。
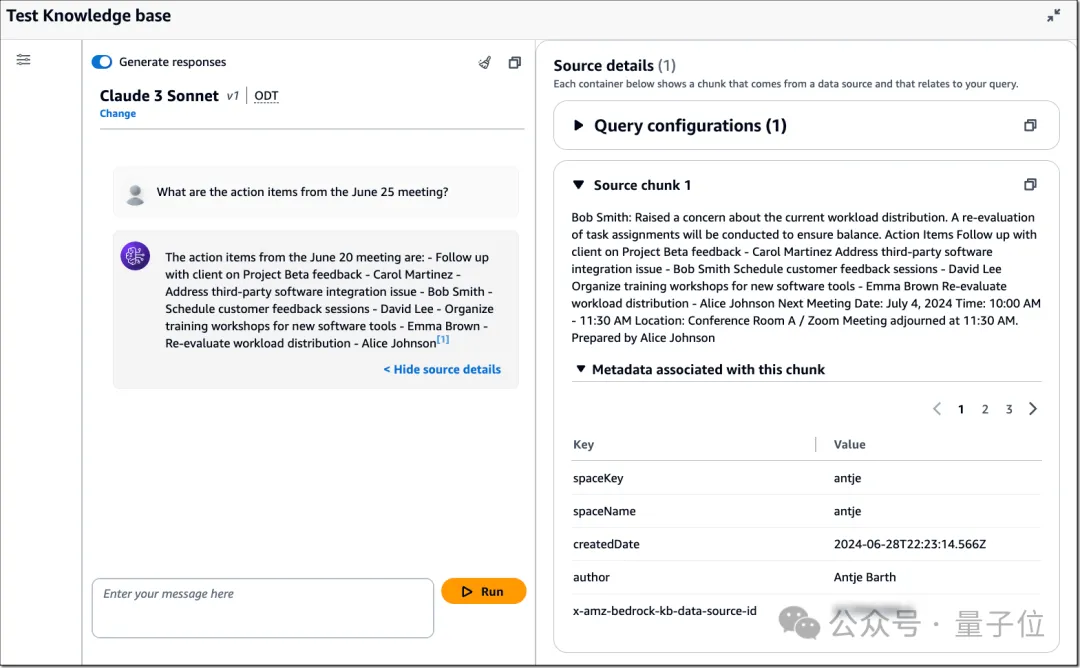
但随着数据源的增多,安全,便自然而然地成为了一种隐患。
为此,亚马逊云科技在Amazon Bedrock上还加了一把更安全的“锁”——Guardrails。
具体而言,是在原先已有的四大安全措施,即被主题过滤器、内容过滤器、敏感信息过滤器和单词过滤器的基础上,再新添两道“安全栓”:

上下文基准检测的目的,是检测基于参考源和用户查询的模型响应中的幻觉,主要包含Grounding和Relevance,在设置过程中可以对二者的阈值做调整。

ApplyGuardrail API目的,则是评估所有基础模型的输入提示和模型响应,实现对所有生成式AI应用的集中治理。
这个功能允许对使用任何自定义或第三方基础模型构建的所有生成式AI应用程序,采用标准化和一致的保护措施。

如此一来,Guardrails起到了阻止多达85%的有害内容、过滤超过75%的RAG幻觉响应的作用。

除此之外,在Agents方面,亚马逊云科技为Amazon Bedrock上新了记忆保留(Memory retention)的功能。

简单来说,这个功能可以保留Agents与用户对话的摘要,提供流畅的自适应体验。
这在复杂多步骤任务,如用户交互和企业自动化解决方案等方面可以发挥重要的作用。
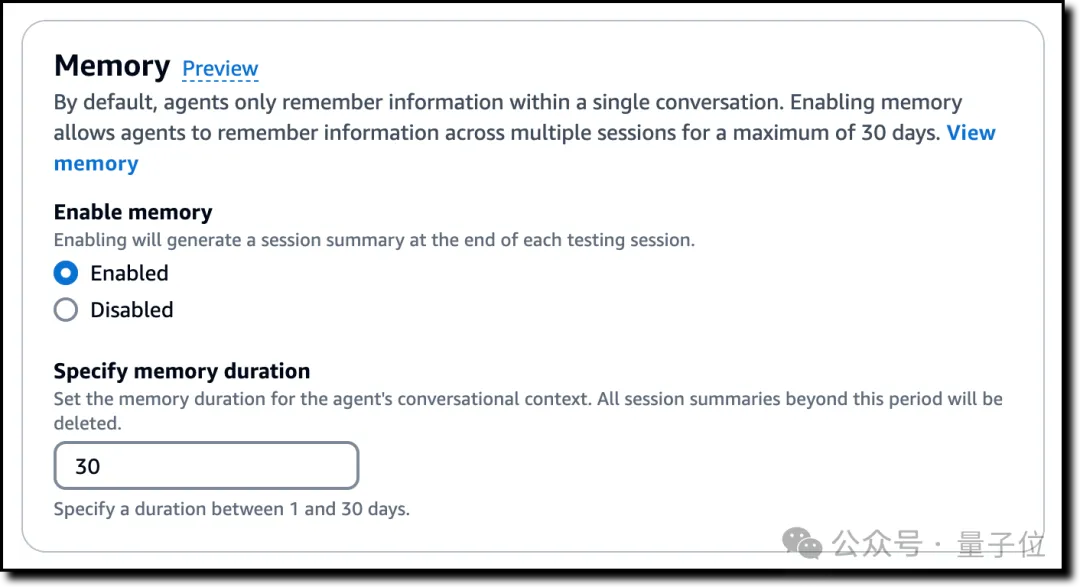
值得注意的是,每个用户的对话历史和上下文都安全地存储在唯一的内存标识符下,并且默认保留30天。
除了记忆变长了,现在Amazon Bedrock上Agents的代码解释能力也被增强。
这样做的目的,同样是更好地处理数据分析、数据可视化、文本处理、求解方程和优化问题等复杂用例。

具体到Amazon Bedrock上的大模型,亚马逊云科技则是对Claude 3 Haiku增添了微调(Fine-tuning)的功能。

据了解,Anthropic是在Amazon Bedrock中首发了这个功能。
在微调之后,Claude 3 Haiku现在的“打开方式”是这样的:
分类准确率从81.5%提高到 99.6%,同时将每个查询的tokens减少了89%。

最后,在算力和能源方面,亚马逊云科技也在今天的活动带来了一个好消息:
提前七年实现100%可再生能源目标!

总而言之,纵观整场的发布活动,围绕生成式AI,亚马逊云科技已然是做到了“多快好省”。
首先,是速度够迅猛。
以Amazon Bedrock为例,其实它从2023年4月发布到现在也只有一年多的时间而已,但几乎是保持着每1、2个月一更新的速度:
尤其是当主流大模型发布重大更新之际,例如Claude 3,Amazon Bedrock几乎是在第一时间将其囊括了进来。
与之相呼应的,这些主流大模型玩家也是将其功能更新的首发地选在了Amazon Bedrock,正如此次Claude 3 Haiku新增的微调功能。
其次,是技术够实力。
亚马逊云科技在AIGC时代与众多主流大模型玩家还有些许不同的地方,就是它属于全栈型选手。
也正因如此,每一次的更新迭代是要照顾到算力层、模型层和应用层整套流程。
从这次的发布来看,亚马逊云科技也是针对每一层分别做了多项功能和能力上的优化,就像拼图一般,不断地在扩大生成式AI的版图。
根据Matt Wood所公布的数据显示,在过去18个月里,亚马逊云科技在生成式AI发布的功能数量,是第二、第三名加起来的2倍还要多。
如此数量,可以说是对技术实力的一种认证了。

最后,是市场够认可。
这一点,同样是从Matt Wood公布的一组数据中窥知一二:
96%的AI/ML独角兽企业在使用亚马逊云科技
2024福布斯评选的AI 50强公司,90%在使用亚马逊云科技

有技术、有实力、有速度、还有市场,亚马逊云科技还将在AIGC时代带来哪些惊喜,是值得期待一波了。
文章来源于:微信公众号量子位




【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】ScrapeGraphAI是一个爬虫Python库,它利用大型语言模型和直接图逻辑来增强爬虫能力,让原来复杂繁琐的规则定义被AI取代,让爬虫可以更智能地理解和解析网页内容,减少了对复杂规则的依赖。
项目地址:https://github.com/ScrapeGraphAI/Scrapegraph-ai
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
