# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
无需训练或微调,在提示词指定的新场景中克隆参考视频的运动,无论是全局的相机运动还是局部的肢体运动都可以一键搞定。

本文提出了名为 MotionClone 的新框架,给定任意的参考视频,能够在不进行模型训练或微调的情况下提取对应的运动信息;这种运动信息可以直接和文本提示一起指导新视频的生成,实现具有定制化运动的文本生成视频 (text2video)。

相较于先前的研究,MotionClone 具备如下的优点:

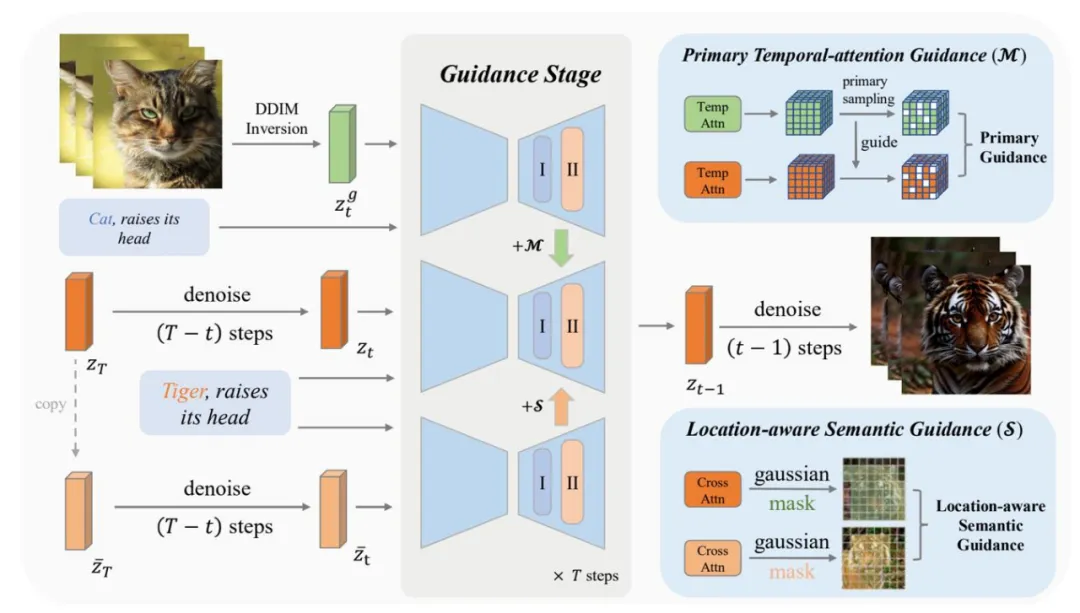
在文本生视频工作中,时序注意力模块 (Temporal Attention) 被广泛用于建模视频的帧间相关性。由于时序注意力模块中的注意力分数 (attention map score) 表征了帧间的相关性,因此一个直观的想法是是否可以通过约束完全一致的注意力分数来复制的帧间联系从而实现运动克隆。
然而,实验发现直接复制完整的注意力图 (plain control) 只能实现非常粗糙的运动迁移,这是因为注意力中大多数权重对应的是噪声或者非常细微的运动信息,这些信息一方面难以和文本指定的新场景相结合,另一方面掩盖了潜在的有效的运动指导。
为了解决这一问题,MotionClone 引入了主成分时序注意力运动指导机制 (Primary temporal-attention guidance),仅利用时序注意力中的主要成分来对视频生成进行稀疏指导,从而过滤噪声和细微运动信息的负面影响,实现运动在文本指定的新场景下的有效克隆。

主成分时序注意力运动指导能够实现对参考视频的运动克隆,但是无法确保运动的主体和用户意图相一致,这会降低视频生成的质量,在某些情况下甚至会导致运动主体的错位。
为了解决上述问题,MotionClone 引入空间语义引导机制 (Location-aware semantic guidance),通过交叉注意力掩码(Cross Attention Mask)划分视频的前后背景区域,通过分别约束视频前后背景的语义信息来保障空间语义的合理布局,促进时序运动和空间语义的正确耦合。
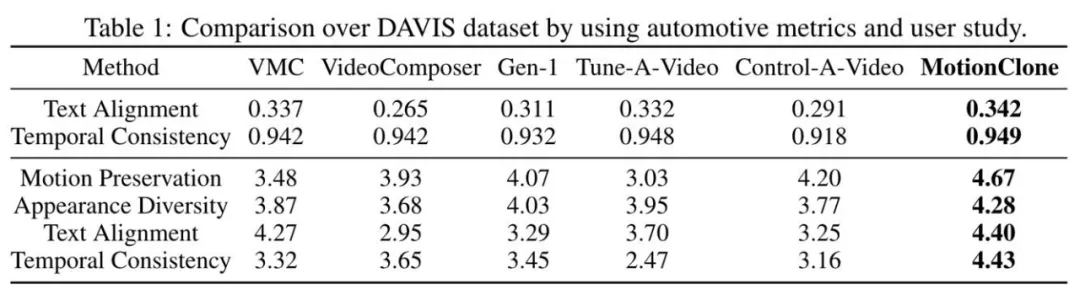
DAVIS 数据集中的 30 个视频被用于测试。实验结果表明 MotionClone 实现了在文本契合度、时序一致性以及多项用户调研指标上的显著提升,超越了以往的运动迁移方法,具体结果如下表所示。
MotionClone 与已有运动迁移方法的生成结果对比如下图所示,可见 MotionClone 具有领先的性能。

综上所述,MotionClone 是一种新的运动迁移框架,能够在无需训练或微调的情况下,有效地将参考视频中的运动克隆到用户给定提示词指定的新场景,为已有的文生视频模型提供了即插即用的运动定制化方案。
MotionClone 在保留已有基座模型的生成质量的基础上引入高效的主成分运动信息指导和空间语义引导,在保障和文本的语义对齐能力的同时显著提高了和参考视频的运动一致性,实现高质量的可控的视频生成。
此外,MotionClone 能够直接适配丰富的社区模型实现多样化的视频生成,具备极高的扩展性。
文章来自于微信公众号“机器之心”,作者 “机器之心”



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
