# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

链接:https://arxiv.org/abs/2407.11046
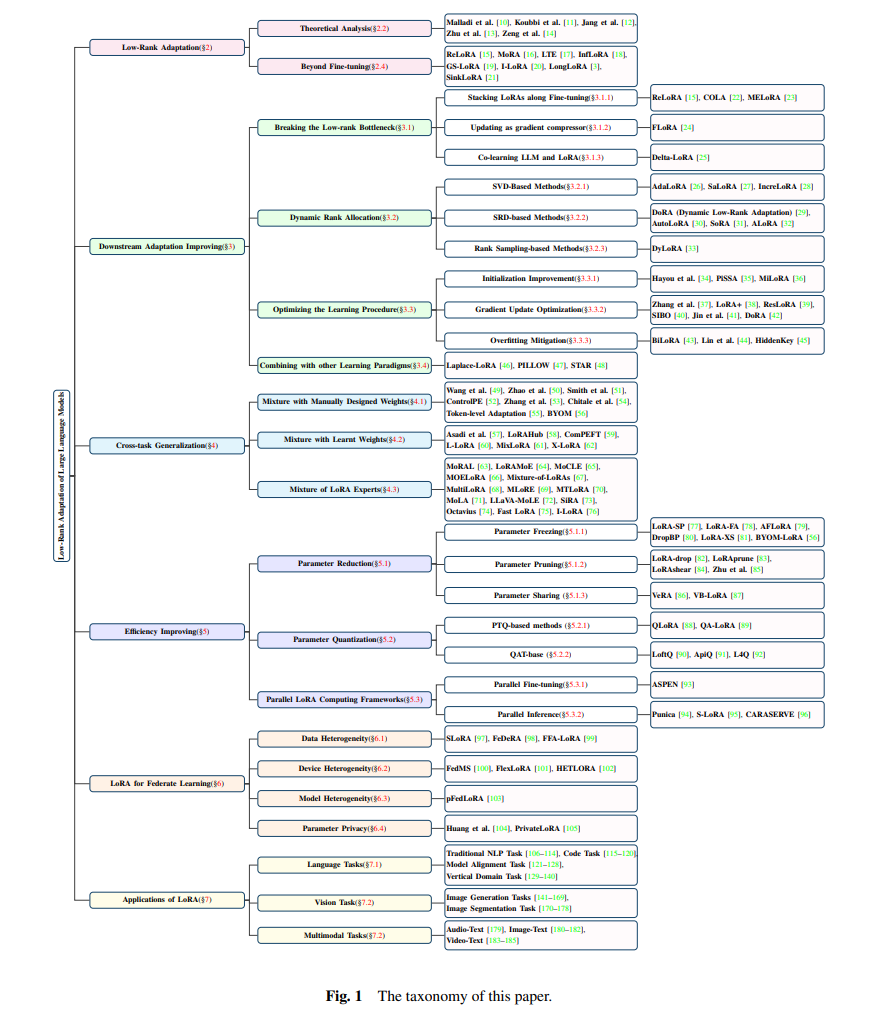
低秩适应(Low-Rank Adaptation,LoRA)通过可插拔的低秩矩阵更新密集神经网络层,是当前参数高效微调范式中表现最佳的方法之一。此外,它在跨任务泛化和隐私保护方面具有显著优势。因此,LoRA 最近受到了广泛关注,相关文献的数量呈指数增长。对LoRA的当前进展进行全面综述是必要的。本综述从以下几个方面分类并回顾了LoRA的进展:(1)改进LoRA在下游任务性能的变体;(2)通过混合多种LoRA插件实现跨任务泛化的方法;(3)提高LoRA计算效率的方法;(4)在联邦学习中使用LoRA的数据隐私保护方法;(5)应用。此外,本综述还讨论了该领域的未来研究方向。
预训练语言模型参数规模的迅速增加提升了它们的泛化能力,并带来了新的能力。近年来,预训练语言模型的参数规模增加了数千倍(例如,从具有3.3亿参数的BERT[1]到具有5400亿参数的PaLM[2])。这些具有大参数规模的预训练语言模型被称为大语言模型(LLMs)。然而,由于LLMs的知识边界,它们在某些下游任务中的能力仍然有限。为了扩展知识边界,仍然有必要在下游任务上微调LLMs。
然而,对LLM进行全参数微调(即全量微调)计算开销极其巨大,例如,对LLaMA2-7B[3]模型进行全量微调需要大约60GB的内存,超出了普通消费级GPU的容量[4]。为了减少计算成本,提出了各种参数高效微调(PEFT)方法[5]。这些方法通过只微调少量(额外的)模型参数来使LLMs适应下游任务。从是否涉及额外参数的角度来看,PEFT方法可以分为两类:额外参数方法和内部参数方法。额外参数方法冻结LLM的所有原始参数,并插入一组可学习的参数来优化模型输入或模型层,如适配器调优[6]和提示调优[7]。相比之下,内部参数方法冻结LLM的大部分原始参数,只微调LLM的一小部分参数,如BitFit[8]、LISA[4]和LoRA[9]。
在无法修改模型架构的情况下,内部参数方法是理想的。在内部参数方法中,LoRA是使用最广泛的方法,因为它在多个下游任务上可以实现与全量微调相当或更好的下游适应性能[9],且易于实施。此外,还提出了许多变体,以进一步提高LoRA在更具挑战性的下游任务中的适应能力。
LoRA通过使用可插拔的低秩矩阵更新LLM的密集神经网络层来实现参数效率。这些矩阵(即LoRA插件)是独立于LLM的,可以存储并在其他相关的下游任务中重用。此外,这些LoRA插件可以组合以实现跨任务泛化,从而促进多任务学习、领域适应和LLMs的持续学习。
随着LoRA插件的累积,管理LoRA插件的计算成本也在增加。尽管LoRA计算效率高,但管理大量LoRA插件的计算成本不可忽视。因此,有必要进一步提高LoRA的计算效率。改进可以通过减少单个LoRA插件的计算成本和加速多个插件的可扩展服务来实现。这可以促进LoRA在现实世界中的应用,如生成即服务(GaaS)云产品。
在某些情况下,训练数据由多个客户端私有且无法集中。为了使用分布式训练数据使LLMs适应,我们可以采用联邦学习来保护每个客户端的数据隐私。然而,联邦学习会产生高昂的通信和计算成本。为了降低成本,LoRA是一个自然的选择。其参数高效特性有助于降低每个客户端的计算成本和跨客户端共享参数的通信成本。此外,LoRA的可插拔特性有助于在联邦学习中保留每个客户端的参数隐私。因此,LoRA在隐私保护方面具有巨大潜力。
在本综述中,我们对LoRA的当前进展进行了全面概述,包括:(1)提高LoRA下游适应性能的方法;(2)混合LoRA插件以实现跨任务泛化的方法;(3)提高LoRA计算效率的方法;(4)在联邦学习中采用LoRA的方法。此外,还简要介绍了LoRA的应用。图1展示了LoRA相关方法的分类。本综述旨在提供LoRA的全面背景知识、研究趋势和技术见解。
本综述的其余部分组织如下。第2节介绍了LoRA的背景知识,第3节介绍了旨在提高下游适应性能的LoRA变体。在第4节中,我们回顾了混合LoRA插件以实现跨任务泛化的方法。第6节介绍了LoRA驱动的联邦学习方法。第7节报告了LoRA的应用。第8节总结了本综述并讨论了未来的研究方向。
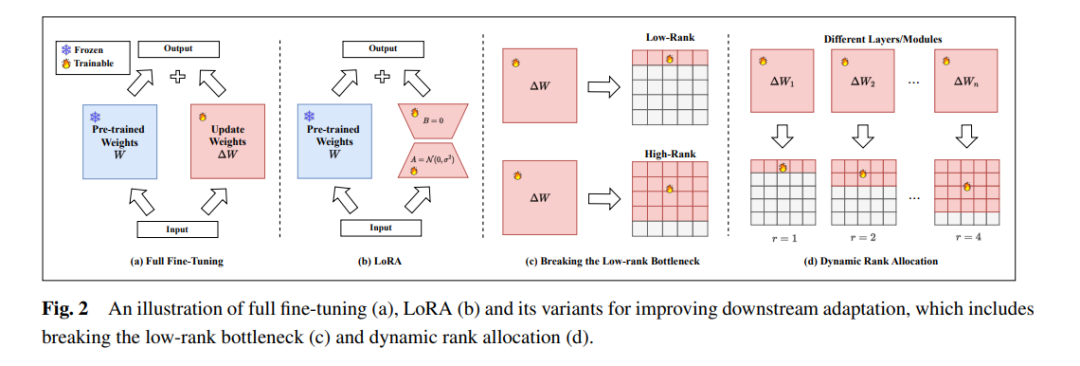
低维固有维度假说[186]提出,过度参数化模型存在于低固有维度上,这表明我们可以通过仅更新与固有秩相关的参数来实现适当的学习性能。基于这一假说,LoRA[9]提出用低秩矩阵更新模型中的密集层。它可以同时实现参数和计算效率。在本节中,我们首先介绍LoRA的细节,然后介绍现有的聚焦于LoRA理论分析的工作。此外,我们展示了LoRA在实践中的效率。最后,本节介绍了LoRA在微调之外的其他用例。

LoRA在参数上非常高效,因为它仅更新模型参数的一小部分,从而在不增加推理延迟的情况下减少了微调所需的内存和计算要求[187]。此外,可以通过从低秩矩阵扩展到低秩张量[188]或与克罗内克分解结合[189, 190]进一步提高参数效率。除了参数效率,LoRA也是可插拔的,因为LoRA参数在训练后可以从模型中分离出来。LoRA的可插拔特性使其可以被多个用户共享和重用[191]。当我们拥有多个任务的LoRA插件时,可以组合这些插件,并期望获得适当的跨任务泛化性能[58]。此外,LoRA的低秩机制兼容其他参数高效方法,如适配器[192, 193]。
在实践中,对于基于Transformer的LLM,密集层通常由两种类型的权重矩阵组成:注意力模块中的投影矩阵和前馈神经(FFN)模块。在原始研究中,LoRA应用于注意力层的权重矩阵。后续工作表明,在FFN层中使用它可以进一步提高模型性能[194]。
01
下游适应性改进
尽管LoRA在某些下游任务上可以实现适当的适应性能,但在许多下游任务上(如数学推理[200-202]),LoRA与全量微调之间仍存在性能差距。为填补这一差距,许多方法被提出以进一步提高LoRA在下游任务中的适应性能。通常,现有方法从以下几个角度改进下游适应性能:
02
结论与未来方向
在本综述中,我们系统地回顾了LoRA在下游适应性改进、跨任务泛化、效率提升、联邦学习和应用等方面的最新进展。从这一综述中,我们可以发现LoRA在参数效率、可插拔性、兼容性和实现跨任务泛化的简便性方面具有显著优势,使其成为LLMs应用中最重要的技术之一。最近的进展进一步提升了LoRA的泛化能力和效率,并激发了其在更多场景中应用的潜力。以下列出了LoRA在未来将不可或缺的三个发展方向。
在生成即服务(GaaS)中,基于云的平台为用户提供生成性人工智能(AGI)服务。GaaS使用户无需部署本地计算资源即可享受AGI服务。由于用户的需求多样化,提供各种功能的GaaS是必要的。为了实现这些各种功能,我们可以为每个功能构建一个LoRA插件。LoRA的参数效率和可插拔性可以促进高效的功能构建和执行。此外,GaaS平台上的服务会随时间迅速变化。为了跟上这些变化,我们可以通过组合先前的插件来初始化新的LoRA插件。LoRA的跨任务泛化能力可以促进服务更新的快速适应。
在持续预训练中,基础模型通过无标签的用户数据持续训练,以使模型适应特定领域。通常,自监督训练目标与预训练相同,学习率则比预训练小得多。持续预训练是构建垂直领域LLMs的重要阶段。然而,这在计算上非常昂贵,阻碍了垂直领域LLMs的发展,尤其是对于计算资源有限的组织。增强LoRA以进行持续预训练并降低其计算成本是值得探索的方向。
在基于LLM的自主代理中,代理被赋予特定角色。根据角色和环境,代理会采取行动来回应用户或其他代理的请求。这些行动可以基于自我知识或为特定领域任务设计的工具。这些请求和行动被存储在内存中,以支持未来的请求。
在当前的代理中,角色通常通过提示来分配;然而,当角色复杂且相关数据量大时,提示可能无法全面描述角色。通过从与角色相关的数据中训练LoRA插件来分配角色可能是更好的选择。此外,代理的工具也可以是LoRA插件。通常,内存通过检索增强生成(RAG)来增强代理;然而,由于输入令牌的限制和上下文学习的缺点,基于RAG的支持可能效果不佳。相比之下,我们可以使用基于LoRA的持续学习来构建内存插件,从而解决RAG的问题。因此,值得探索LoRA驱动的代理。
总之,LoRA在生成即服务、持续预训练和自主代理等领域展现出巨大的潜力,未来的研究将进一步挖掘和扩展LoRA的应用,使其在越来越多的实际场景中发挥重要作用。
文章来源于“大模型智能”




【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
