# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
随着人工智能技术的快速发展,能够处理多种模态信息的多模态大模型(LMMs)逐渐成为研究的热点。通过整合不同模态的信息,LMMs 展现出一定的推理和理解能力,在诸如视觉问答、图像生成、跨模态检索等任务中表现出色。这种多模态能力使得 LMMs 在各类复杂场景中的应用潜力巨大,而为了严谨科学地检验 AI 是否具备较强的推理能力,数学问答已成为衡量模型推理能力的重要基准。
回顾 AI 的发展历程,我们发现人类的认知和思考问题的方式对 AI 的发展产生了深远的影响。诸如神经网络、注意力机制等突破均与人类的思维模式息息相关。想象一下,人类在解答一个数学问题时,首先需要熟知题目所考察的知识点,而后利用相关知识进行逐步推理从而得出答案。但模型在作答时,其推理过程是否与人类一致呢?
聚焦于数学问题,我们发现模型可以回答出复杂问题,但在一些简单问题面前却捉襟见肘。为探究这一现象的原因,受人类解题思维模式的启发,我们首先对先掌握知识点,再运用其进行逻辑推理的解题过程建模如下:
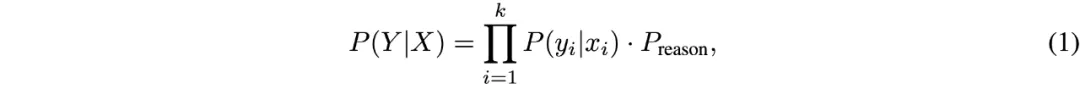
其中 (X, Y) 和 (x_i, y_i) 分别表示数学问题和每个子问题中的问题与答案,P_reason 代表 LMMs 的综合运用能力 (知识泛化)。基于此,We-Math 首先基于 67 个原子知识点构建了一个多层级树状知识体系,紧接着以原子知识及推理答案为依据,通过将多知识点的复杂问题拆解为多个原子知识点对应的子问题来探究模型的作答机制。

目前 We-Math 在当日的 HuggingFace Daily Paper 中排名第一,并在推特上的浏览量达到 10K+!

We-Math Benchmark
We-Math 测评数据集共包含 6.5k 个多模态小学数学问题和一个多层级知识架构,每一个数学问题均有对应的知识点(1-3 个)。其中所有问题的知识点均被 5 层 99 个节点(最后一层包含 67 个知识点)的知识架构所涵盖。并且如下图所示,为了缓解模型在解决问题过程中固有的问题,我们参考教材与维基百科,启发式的引入了 67 个知识点的描述,从而为 LMMs 的推理过程提供必要的知识提示。
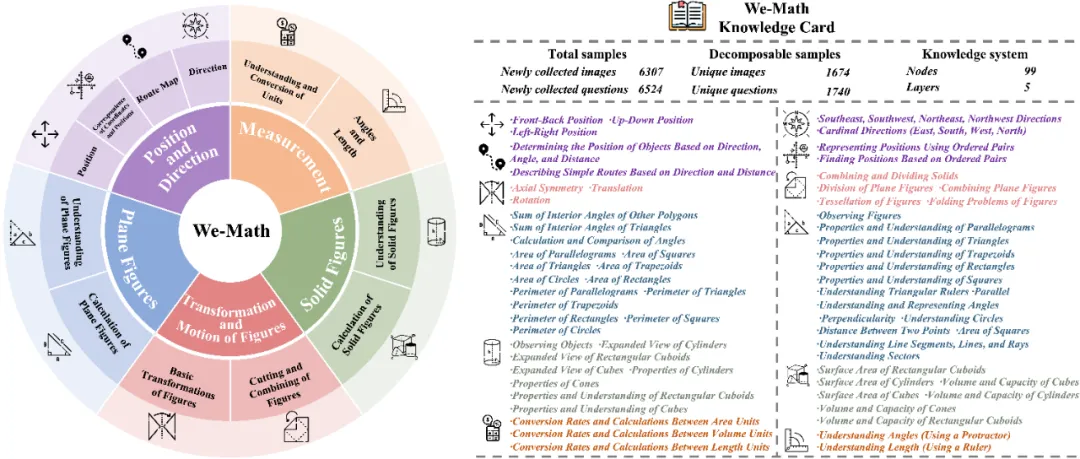
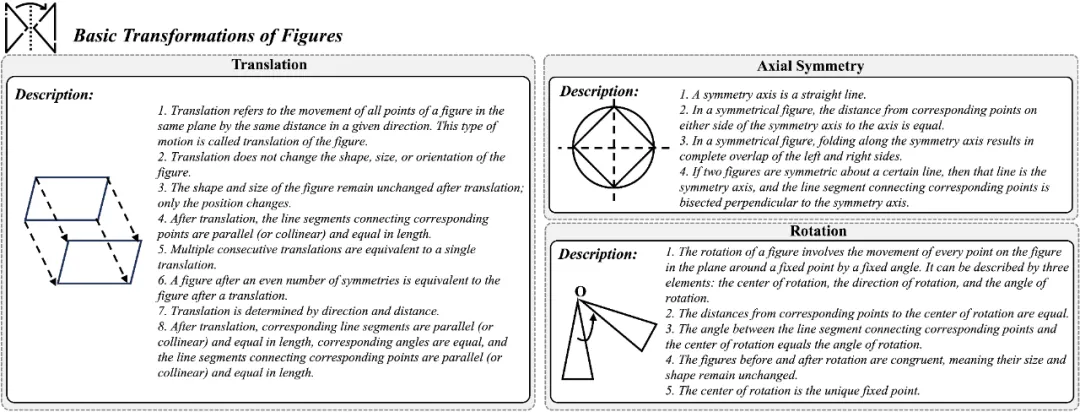
为了合理的评估模型的作答机制,我们严格以人类作答的标准答案为依据,按照复杂问题所包含的知识点,将其拆解成了 n 个子问题,其中 n 表示复杂问题包含的知识点数量。
如下图所示,对于一道复杂问题:Mary 从一个圆形花坛的最北端点沿花坛边缘走到最东端点,走过的距离是 50.24 米,求解圆形花坛的面积。在解题过程中,首先需要根据 “东南西北方向” 知识点,通过 “最北” 和 “最东” 两个方向的条件,求得 Mary 走过路径所对应的圆心角大小(“最北” 和 “最东” 的夹角为 90 度)。接着,根据 “圆的周长” 知识点,通过圆心角的大小为 90 度和 Mary 走过的路径长度的条件,计算出圆形花坛的周长,并求得圆形花坛的半径。最后,根据 “圆的面积” 知识点,通过求得的半径的条件,计算出圆形花坛的面积,至此完成题目的求解。
分析上述解题过程,为了探究模型的答题机制以及模型的细粒度推理表现,可以将原题按照其对应的知识点拆解成三个子问题,具体而言,第一问:Mary 从一个圆形花坛的最北端点沿花坛边缘走到最东端点,求她走过路径的圆弧所对应的圆心角的度数;第二问:圆形花坛中,90 度圆心角所对应的圆弧弧长为 59.24m,求解圆形花坛的半径;第三问:求半径为 32m 的圆形花坛的面积。

在此基础上,如下图所示,我们引入一种新的四维度量标准,即知识掌握不足 (IK)、泛化能力不足 (IG)、完全掌握 (CM) 和死记硬背 (RM)。
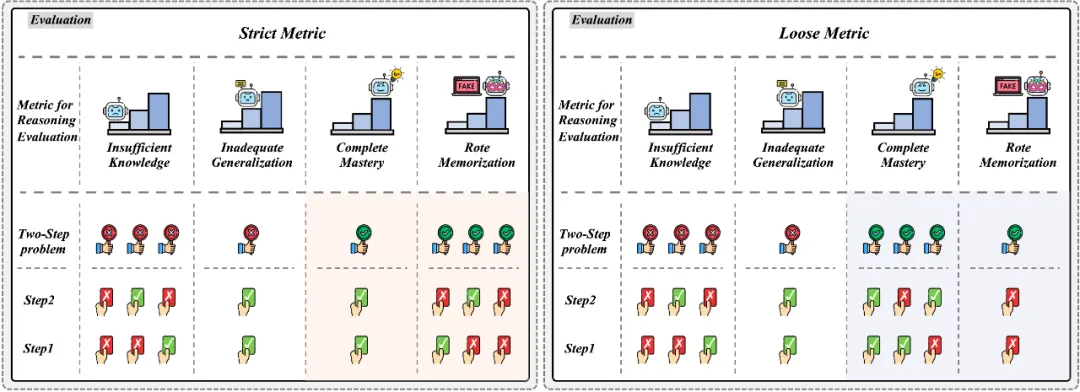
其中 IK、IG、CM 之间存在 IK<IG<CM 的层次关系,即模型需要先掌握知识,才可以讨论综合运用的能力,而 RM 我们认为是一种不合理的现象。此外,考虑到模型的不稳定性,当前判定结果是否属于 RM 的标准较为严格。因此,我们提出了一种更灵活的宽松标准。如上图所示,在包含两个知识点的问题中,TFT 和 FTT 情况根据宽松标准(Loose Metric)被视为 CM(而非 RM)。我们在文章的附录中同样讨论了四维度指标在三步问题中的情况。因此,结合上述情况我们最终提出了一个综合打分度量标准,以此评估 LMM 推理过程中的固有问题。
实验与结论
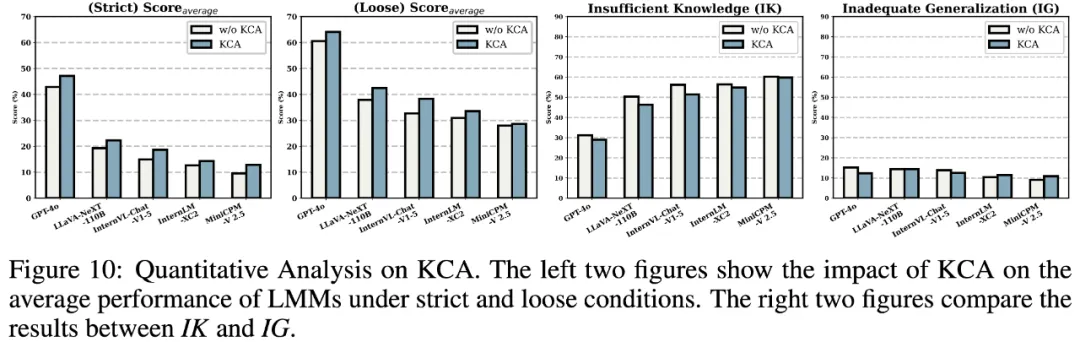
We-Math 目前在 17 个大模型中完成了评测,共包含 4 个闭源模型与 13 个开源模型。其中表 1 与图 6 展示了 LMMs 在不同知识点数量下的结果与模型在第二层级知识点下的表现;表 2 与图 7、图 8、图 9 展示了 LMMs 在四维指标下的结果以及在严格和宽松标准下的综合打分结果;图 10 展示了 KCA 策略对模型在 IK 问题中的缓解结果。
LMMs 在不同知识点数量下的表现及其在第二层级知识点下的表现
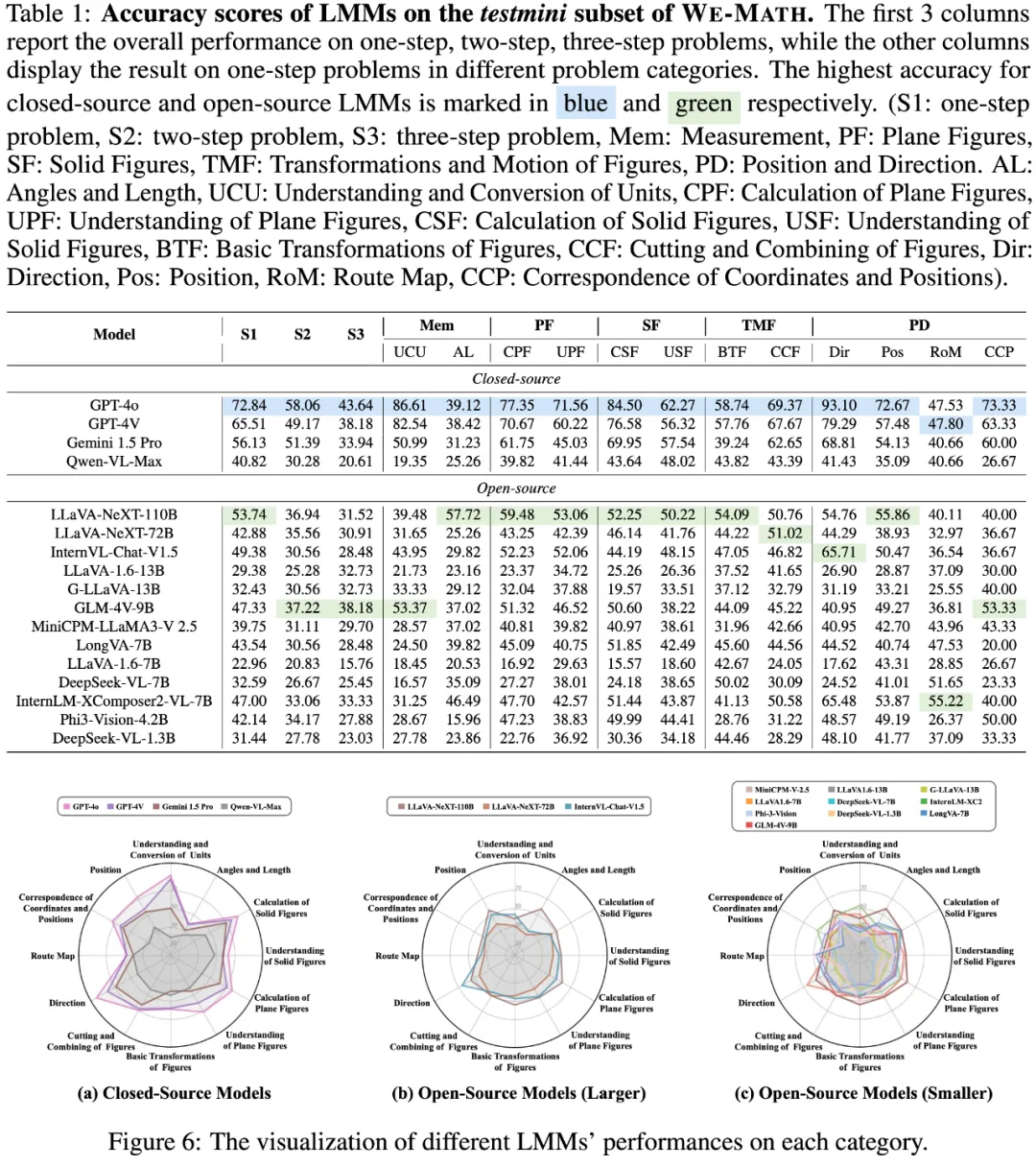
LMMs 在四维指标下的表现及其在严格和宽松标准下的综合评分结果

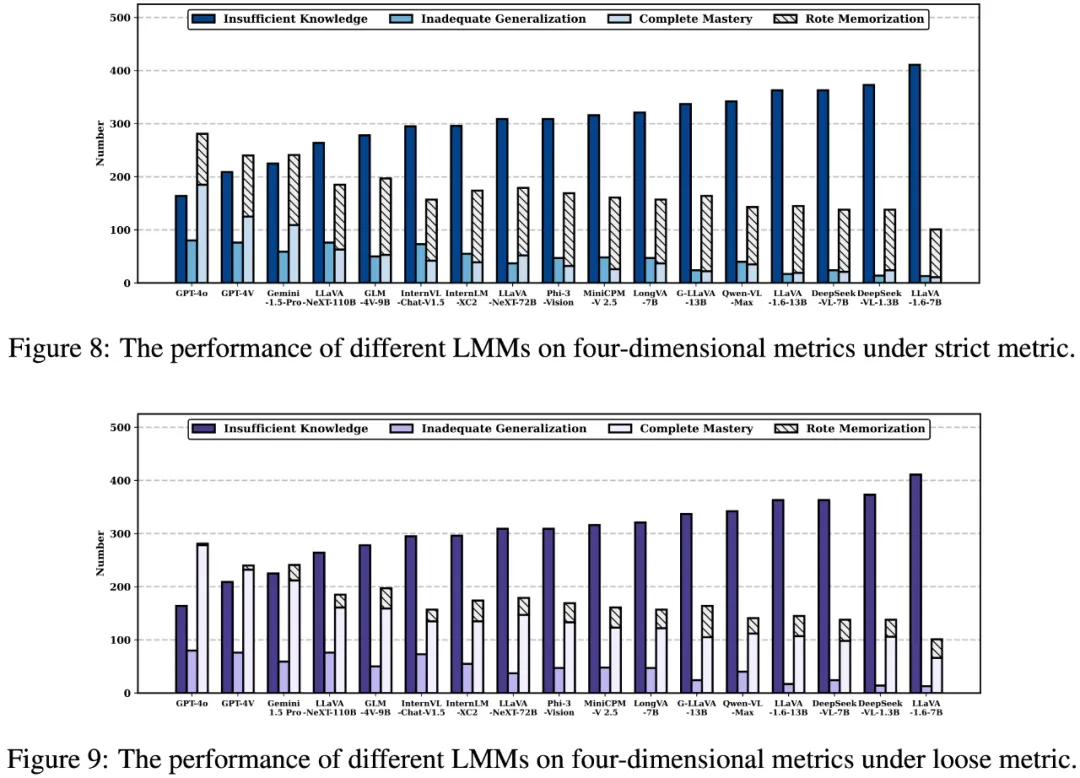
LMMs 在 KCA 策略下的表现
在本文中,我们提出了 WE-MATH,一个用于细粒度评测 LMMs 在视觉数学推理任务中作答机制的综合基准。WE-MATH 共包含 6.5k 个视觉数学问题,涵盖 5 层 67 个知识点的多级知识架构。我们开创性地根据题目所需的知识点将其拆解为多个子问题,并引入了一种新的四维度指标用于细粒度的推理评估。通过 WE-MATH,我们对现有的 LMMs 在视觉数学推理中的表现进行了全面评估,并揭示了模型作答情况与题目所包含的知识点数量呈现较明显的负相关关系。
此外,我们发现多数模型存在死记硬背的问题 (RM),并且知识掌握不足(IK)是 LMMs 最大的缺陷。然而,GPT-4o 的主要挑战已从 IK 逐渐转向 IG,这表明它是第一个迈向下一个阶段的模型。最后,我们对 KCA 策略和错误案例的分析进一步启发性地引导现有的 LMMs 向人类般的视觉数学推理发展。
文章来自于微信公众号“机器之心”,作者 “机器之心”



【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
