# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
离大谱!!不看视频完整版谁知道里面的美少女竟是一位大叔。

好嘛,原来这是用了快手可灵团队的可控人像视频生成框架——LivePortrait。
LivePortrait开源即爆火,短短时间已在GitHub狂揽7.5K星标。
还引来HuggingFace首席战略官Thomas Wolf亲自体验:
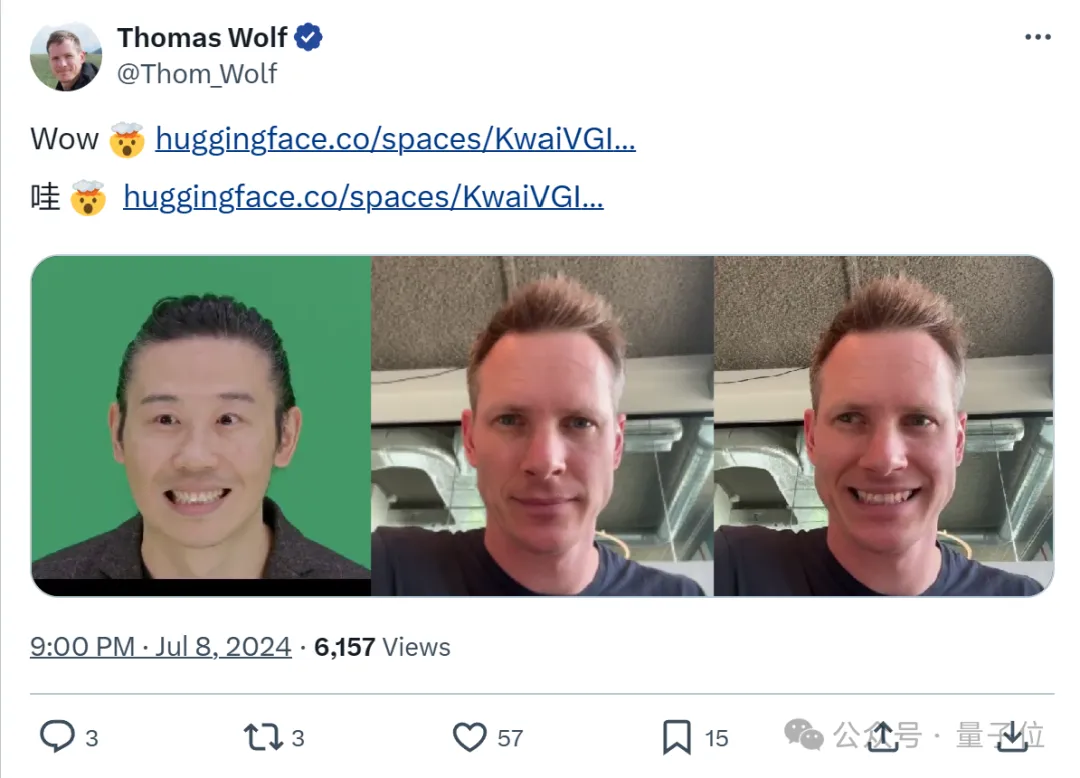
甚至目前仍在HuggingFace全部应用里排在趋势第一:

所以,为啥LivePortrait能够疯狂引人关注?
还得从它让人眼前一亮的表现说起……
LivePortrait由快手可灵大模型团队开源,只需1张原图就能生成动态视频。

先来看一组官方输出。
从最简单的开始,丢一张静态图像,LivePortrait可以让肖像眨眼、微笑或转头。
还可以施展“移花接木”,也就是将表情、动态等复制到其他人身上,还是不限风格(写实、油画、雕塑、3D渲染)和尺寸那种~

当然了,这种“魔法”不限于单人,搞个全家福也不是不行。[doge]

除了从静态图→视频,我们还可以让一个或多个视频实现“笑容增加术”。
比如提供一段宝宝没有表情的视频(最右侧),我们可以让宝宝按照参照视频wink或微笑。

对了,不仅限于人物肖像,小猫小狗也能开始撒娇卖萌了。

总之,LivePortrait可以实现人物表情精确控制,比如嘴角上扬的弧度,双眼放大程度都能开启自选。
举个栗子,下面这两个是不同参数设置下,人物眼睛大小的变化:


看来小说里的“三分凉薄,三分讥笑,四分漫不经心”也不是不能实现。[doge]
看完这些不知道你有没有心动,反正网友们整活儿的心是挡不住了。
比如配个灯光花式扮鬼脸,有恐怖片那味儿了:

再比如实时化身二刺猿:

看完这些例子,接下来我们挖一挖背后的技术原理。
和当前主流基于扩散模型的方法不同,LivePortrait探索和扩展了基于隐式关键点的框架的潜力。
具体而言,LivePortrait不依赖于图像中明确可见的标记或特征点,而是通过学习数据集中的模式来隐式地推断出关键点的位置。
在此基础上,LivePortrait通过两个阶段从头开始训练模型。
先说第一阶段,LivePortrait对基于隐式点的框架(如Face Vid2vid),做了一系列改进。

这些改进包括高质量数据整理、混合图像和视频训练、升级网络架构、可扩展运动变换、地标引导的隐式关键点优化以及级联损失项的应用等。
有了这些,模型的泛化能力、表达能力和纹理质量都能进一步提升。
再说第二阶段,通过贴合模块和重定向模块的训练,模型能够更精确地处理面部表情的细节。

贴合模块通过跨身份动作训练增强泛化性,估计表情变化并优化关键点。
眼部和嘴部重定向模块则分别处理眼部和嘴部的变形变化,通过独立的目标函数计算像素一致性和正则损失,提升模型在复杂表情处理上的灵活性和精确度。
那么,LivePortrait具体表现如何呢?
研究显示,在同身份驱动对比结果中,与已有方法相比,LivePortrait具有较好的生成质量和驱动精确度,可以捕捉驱动帧的眼部和嘴部细微表情,同时保有参考图片的纹理和身份。


且在跨身份驱动对比结果中同样表现较好,虽然在生成质量上略弱于基于扩散模型的方法AniPortrait。但与后者相比,LivePortrait具有极快的推理效率且需要较少的FLOPs。


总之,在RTX 4090 GPU上,LivePortrait的生成速度达到了每帧12.8毫秒,显著高于现有的扩散模型方法。
补一条官方最新预告:可灵AI即将在全球范围内推出其服务。
Sora还没来,可灵这回倒是先走出去了~

LivePortrait体验地址:
https://huggingface.co/spaces/KwaiVGI/LivePortrait
项目主页:
https://liveportrait.github.io
论文:
https://arxiv.org/abs/2407.03168
参考链接:
[1]https://x.com/Yokohara_h/status/1815440947976794574
[2]https://weibo.com/1727858283/5059185991221724
[3]https://x.com/Kling_ai/status/1815332322599973289
[4]https://x.com/toyxyz3/status/1811300657158320450
[5]https://x.com/thione/status/1815114364581748861
文章来自于微信公众号“量子位”,作者 “一水”




【开源免费】LivePortrait项目可以实现高效的人像动画,通过拼接和重定向控制技术,使一个静态人像或动物图像能够变成动态的视频,变成动画形式。
项目地址:https://github.com/KwaiVGI/LivePortrait?tab=readme-ov-file
