# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
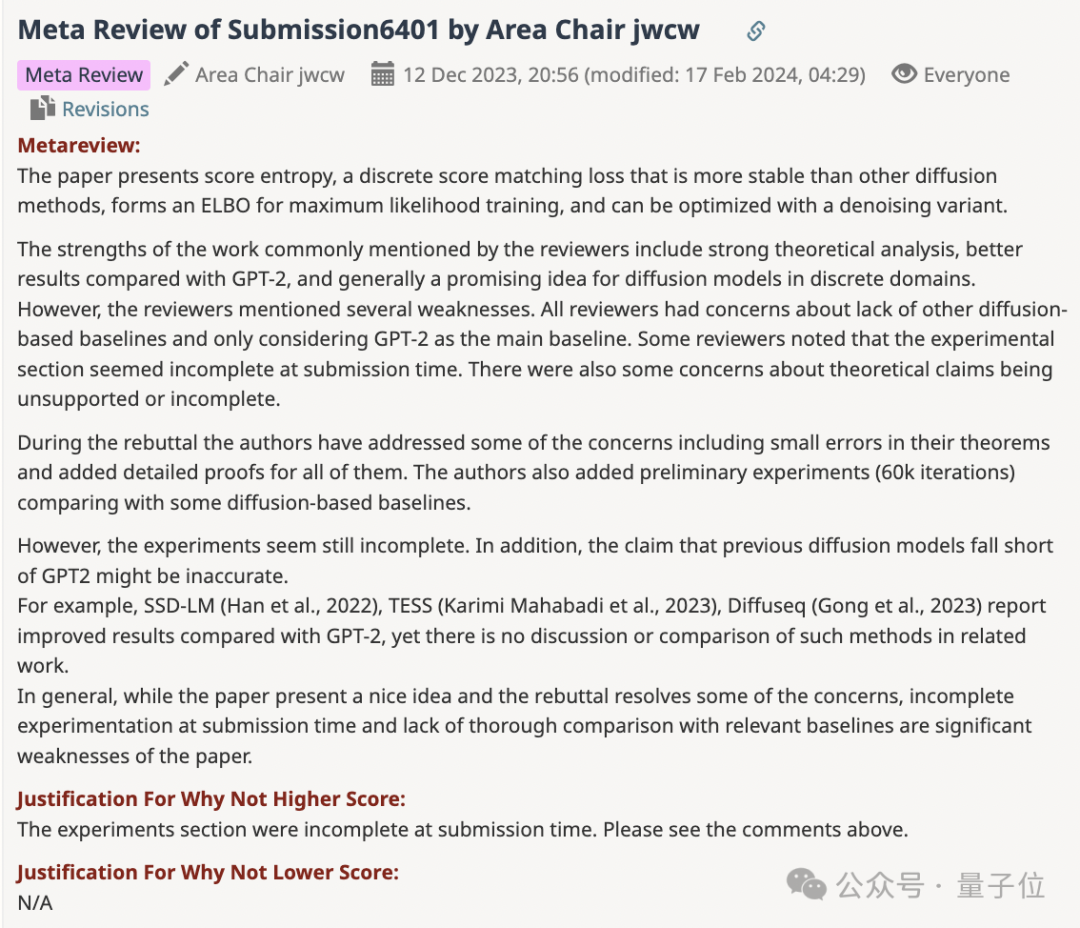
ICML 2024最佳论文出炉,结果发现其中一篇曾被ICLR 2024拒稿?

这篇论文来自斯坦福,Pika创始人之一孟晨琳(Chenlin Meng)也参与了。
它提出了一种新的离散扩散语言建模方法,通过引入分数熵损失函数,提高了离散扩散模型在语言建模任务中的性能。
实验结果和GPT-2比较,在多数任务中都完胜。
生成效果be like:

5位审稿人给出的分数分别是:88665。
但还是被AC一锤定音,最终reject……
这不禁让人想起Mamba。作为Transformer架构挑战者,它开创了大模型的一个新流派。结果却被ICLR拒稿。
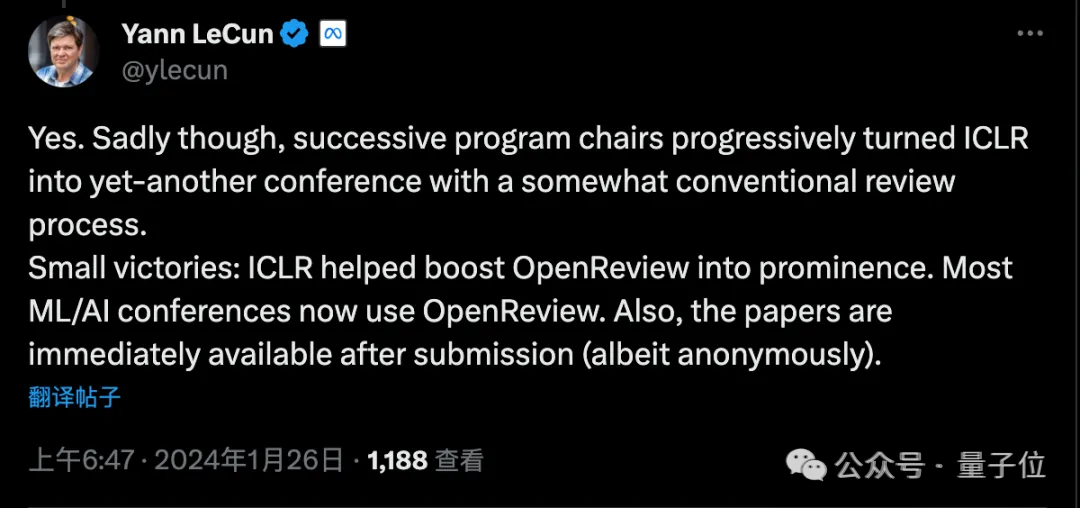
当时这引发不小争议,包括ICLR创始人之一LeCun都下场表示不满:
很遗憾,历届程序委员会主席慢慢把它变成了一个与传统评审流程差不多的会议。
只有一些小胜利:OpenReview平台现在被大多数ML/AI会议使用,以及论文提交后立刻就能被所有人阅读(尽管匿名)。
还有人说:
如果搜索ICML 2024接收的论文,就会发现很多都被ICLR 2024拒了。

这回又是咋回事?
这篇论文关注了扩散模型在文本等离散数据领域表现一直不佳的问题。
团队认为,标准扩散模型依赖于分数匹配(score matching)理论,但是这一机制推广到离散数据领域后效果不佳。
为了填补这一空白,他们提出了一种新的损失函数分数熵(score entropy),并构建了分数熵扩散模型(SEDD)。
在主要语言建模任务上,SEDD在目前所有语言扩散模型中表现最佳,和同规模自回归语言模型不相上下,在零样本困惑度任务上击败GPT-2。
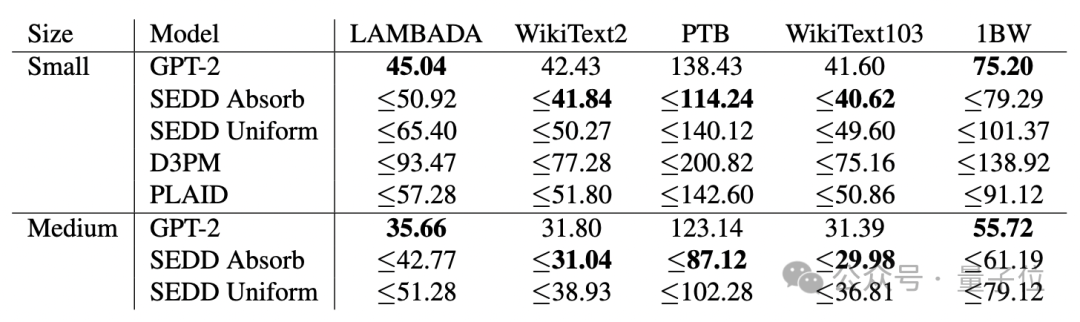
同时SEDD可生成高质量无条件样本,可以方便在计算量和生成质量之间做权衡。通过直接参数化概率比,SEDD高度可控,可以使用提示词微调而无需专门训练。
5位审稿人中,有2位都给出8分高分。
大家普遍肯定了提出的论点。一位评审觉得论文推导过程写得也很不错,实验结果非常令人信服。

不过也有很多小问题被提出,比如拼写错误、忽略了对一些实验细节的解释。

从记录中可以看到,作者针对评审提出的问题进行了详尽的说明和修改(有的分2条才发完)。
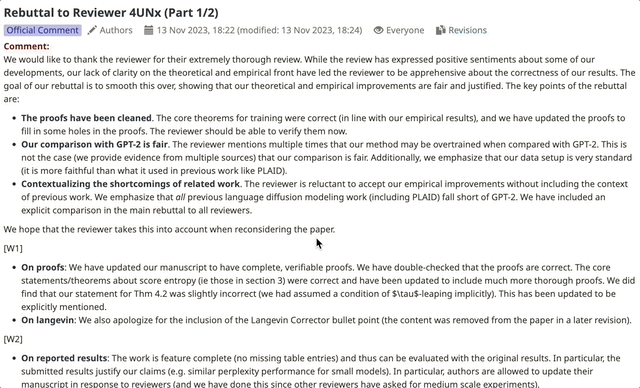
有评审看到调整后的内容,也相应调整了分数。

不过最终AC还是拒收了这篇论文。
反驳的点就主要在于实验部分不完整。
所有审稿人都认为,该论文只将GPT-2作为主要基线,缺少和其他扩散模型基线。一些审稿人认为,论文提交时实验部分不完整。
尽管作者后续增加了一些实验,但是AC仍然认为不够完善,而且论文中提到此前扩散模型表现不及自回归模型的说法可能不够准确。
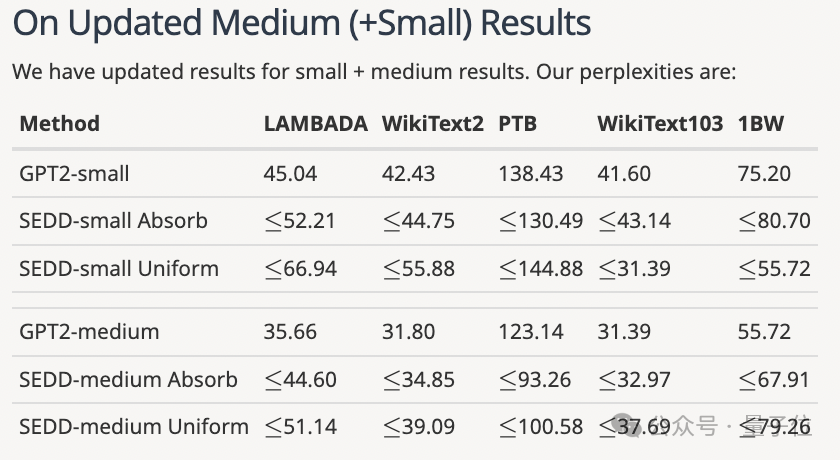
比如SSD-LM、TESS等模型的表现都比GPT-2表现更好,但是论文中却没有和这些结果做对比。
总之,AC认为论文提出了很好的idea,但是在实验和对比上不够完善。
有人表示,之前Mamba被拒也是类似的原因,后面完善了论文再拿best paper也很合理。

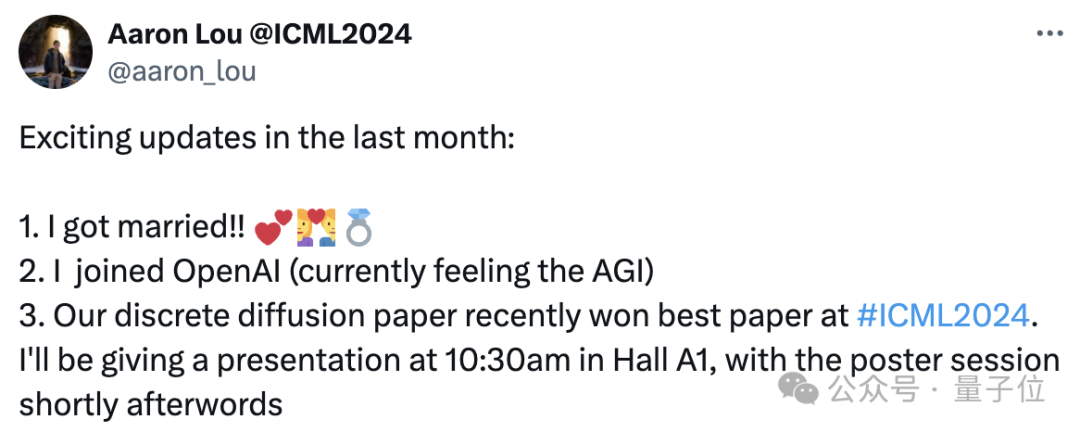
值得一提的是,这篇研究的作者中不光有Pika创始人之一孟晨琳。
一作最近也加入OpenAI,更近距离感受AGI了。他将在最近的ICML 2024上进一步讲解这项工作。
文章来源于“量子位”,作者“关注前沿科技”



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
