# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
AI会有常识吗?
令人深思的是,目前GPT-4已经表现出了一些令人印象深刻的「人性意识」。
在Quanta Magazine最近的一期播客「The joy of why」中,华盛顿大学的计算机科学家Yejin Choi和主持人 Steven Strogatz一起讨论了聊天机器人,以及构建聊天机器人的LLM的功能和局限性。

当然,最吸引人的还是这个话题:AI是否有可能以某种方式真正理解世界,以及它们回答的问题?
LLM,接近人类智能
早在20世纪60年代,计算机科学家就一直梦想着:受大脑启发的计算机有朝一日能表现出类人智能。
随着互联网的兴起、大量文本数据集的出现以及计算能力的显著进步,我们显然已经到达了一个重要时刻。
如今的LLM,看起来似乎已经拥有了接近人类智能的东西。
普林斯顿大学的Sanjeev Arora和谷歌DeepMind的研究科学家Anirudh Goyal提出的理论就表明,今天最大的LLM并不是随机鹦鹉。

随着模型变得越来越大,在更多的数据上训练,它们的语言能力提高了,并且以一种暗示理解的方式组合技能,发展出了新的能力。(这些组合不太可能出现在训练数据中)

随机图在满足某些阈值后会产生意想不到的行为,这可能是一种建模LLMs行为的方法,神经网络已经变得太复杂而无法分析
在今天的播客节目中,主持人Steve Strogatz邀请来了华盛顿大学计算机科学教授兼系主任Yejin Choi。
Yejin Choi的研究方向是自然语言处理的统计方法和计算模型。她被评为2022年麦克阿瑟院士,并于2023年被《时代》杂志评为人工智能领域100名最具影响力人物之一。

在节目开始,Strogatz抛出了一件趣事作为引子——「我问ChatGPT,你真的明白吗?」
它的回答是:「作为AI,我不具备人类那样的意识或主观理解力。虽然我可以做出看似理解的回答,但请认识到——这种理解是机械性的,并且是基于统计模式,而非真正的理解。」
Choi表示,这很有趣,因为ChatGPT说的话好像是别人引导的,
要知道,ChatGPT背后的LLM是一个黑盒模型,其中训练的数据类型是不透明的。
显然,训练过程中使用了人类编写的具备特定语言风格的示例,ChatGPT所使用的,是类似律师的语言。
Choi介绍道,目前LLM的能力是惊人的,我们在ChatGPT上抛出的任何话题,它都能给出令人惊喜的回答。
但事实上,这只不过反映了全体人类在互联网上共享的智慧。
对于人类来说,很难对「互联网有多大」有一个具象的理解,因为人类阅读和消化信息的能力还是有限。
但是AI却可以真正从字面意义上读取所有这些信息。
也就是说,它可以模仿人们在网上分享的知识和智慧,然后在某种意义上将它们「读回」给我们。
不过,它不是逐字逐句地表达,而是以一种更讲究措辞的方式。
它给出的东西,不是互联网上内容的精确副本,而是经过综合处理之后的重新措辞,所以听起来会足够新。
主持人举例说,自己有一回让ChatGPT特朗普扮演精神科医生,写一部《周六夜现场》的短剧,效果惊人。

LLM到底是怎么做到的?
Choi解释说,LLM做的,就是阅读了大量文本,并且学会了预测下一个单词,但规模非常大。
也因此,很多人把LLM视作一台「辛辣的自动完成机器」。
它不一定对训练数据进行「逐字反省」,原因是背后技术的特殊性,不一定与记忆有关。
此外,它还能进行一定程度的泛化,而且从学习的神经网络中生成文本的方式也存在随机性,导致文本不一定总是逐字反省。
不过,如果文本在互联网数据上重复得足够频繁,那么它的确就会逐字记住。
比如曾经闹出轩然大波的纽约时报告OpenAI侵权事件。

我们可以说这是抄袭,也可以将其理解为一个能检索自己读取内容的神经网络。
但LLM所做的,绝不仅仅是自动读取内容而已。
比如特朗普扮精神科医生的剧本,在网上找不到,这表明,AI能够在两个数据点之间进行插值。
这种从未有人实现的做法,对于LLM来说是微不足道的。
Choi概括说,训练LLM的过程,可以归结为构建一个非常大的神经网络,其中有一层又一层的神经元堆积起来,然后按顺序输入互联网数据。
学习过程的目标就是,根据前面单词的顺序来预测下一个单词。
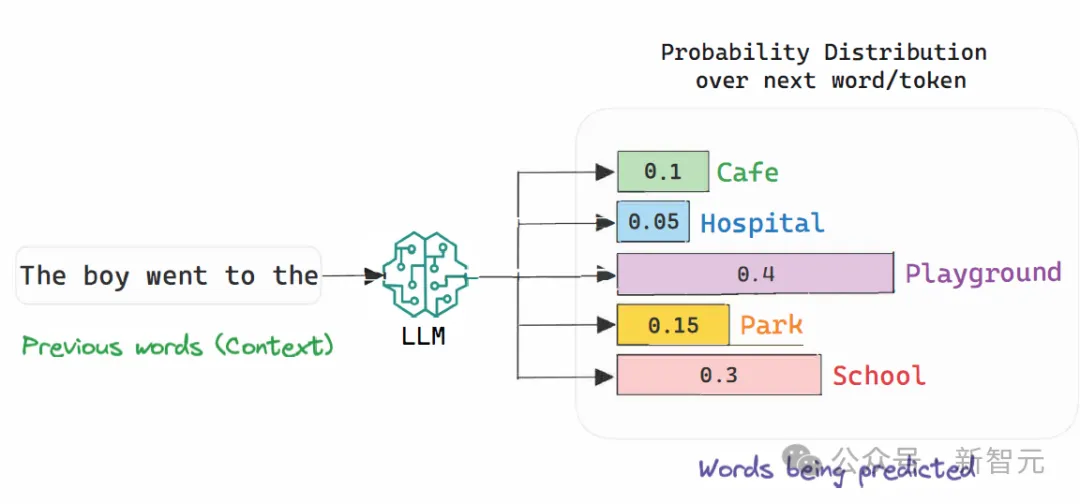
这种训练方法如此简单,却可以产生如此强大的成果,让LLM在文本中回答各种问题,这对许多人来说,已经非常惊人了。
但可以肯定,训练LLM的过程和人类了解世界的方式是截然不同的。
虽然人类如何学习的过程,我们也未必十分了解,但很显然,我们不是通过预测下一个单词,而是尝试真正理解世界。
Choi举了个例子:就比如说,我们无法逐字记住刚才的讨论,但我们一定记得刚才谈话的要点。我们的大脑具备的,是立即抽象的能力。
人类是通过课程和好奇心来学习的。我们会对世界做出假设。
如果有什么不对劲的地方,即使是婴儿都会做一些实验,来搞清是什么让自己如此困惑,以及自己与之互动物体的物理知识。

但AI从第一天起,就被纽约时报的文章喂养。
它们并没有发言权,决定自己以什么顺序阅读,也不可能说「等一下,我想再读一些东西。这本海明威的书很特别,其中一些美好的东西引起了我的注意,我想读得慢一点」。
我们学习的方式是如此不同,但令人惊讶的是,LLM却能够绕过人类正常的学习方式,然后仍能说出非常像样的人类语言。
要知道,人类是生物,都有欲望,有一种深刻的自我认同感,正是这些造就了我们。
而LLM所做的,只是在某种意义上阅读了每个人的协作,然后形成了一种平均观点,或者说一种混合了思想和情感的汤。
它的确模仿了人类的情感和意图,因为人们在写作中确实投入了情感和意图。

AI模仿了这一切,但归根结底,它并不真正具有人类所拥有的那种真实情感。
从安全角度来看,这是一个哲学问题,甚至可能是一个科学问题。
如果AI真的发展出自己的情感,甚至具有了幸存者本能,还想称霸全世界,这是好事还是坏事?
LLM的训练方式,让它最大化应该分配给正确单词的概率得分。
在预训练期间,学习机制基本上就是最大化分配给正确单词序列的概率得分,这也意味着恰好在互联网上出现的单词的确切序列。
但Choi表示,我们并没有理由说,这就是唯一正确的单词序列。
因为对于任何给定的前缀文本,后面都可能跟一个不同的单词,没有绝对的「正确」。
但无论如何,神经网络最终被训练成了最大化概率。
就这些神经网络学习的权重而言,这就意味着:这些机器的学习方式基本上就是基于所谓的 「反向传播」。
我们基本上是利用单个权重的梯度,即部分梯度。因此,你需要对神经网络的每个权重求偏导数。
对于数千亿个参数,我们都需要对它们求偏导数,然后移动权重,这样它就会增加分配给训练数据中特定单词序列的概率得分。
主持人听到这里,提到了自己打网球的经历。
他说,如果自己打出一个很烂的球,教练就会说「你需要早点把球拍挥出来,你没有准备好」。
这是不是就像权重一样?就像我们有某种内在的方式,来表达脚在正确的位置、身体转向一边、把球拍挥到位置、眼睛盯着球这些要素有多重要。
如果这一杆很糟糕,我们就需要调整自己的权重,让自己下次做得更好。

Choi表示,的确如此。在主持人看来,这是一种残酷的学习方式,我们让可怜的机器做一个又一个测试题,每次它做错了,我们就惩罚它。
这就是预训练过程中发生的事。
而在后期训练中,最有代表性的就是RLHF。此时我们将机器的答案呈现给人类评估者。在此基础上,我们再回到神经网络来调整一下权重。
预训练阶段需要几天呢?Choi回答说,这个答案变化很大,取决于我们输入多少数据,有多少算力,以及想训练多大的神经网络。
如果我们想早点停止,且数据量较小的话,这可能只是几天的问题。
晾衣难题,难倒ChatGPT
在Choi的一次TED演讲中,她将常识称为「智慧的暗物质」。
之所以这么说,是因为常识是关于世界如何运作的潜规则。这种运作方式,影响了人类使用语言和解释语言的方式,成为决定人类智力的关键。

不过,关于常识有个神秘之处,就是人类可以很轻易就获得它,然而想把它们写下来、教会机器,却是一件很困难的事。
在AI领域,常识经常被视为最难克服的挑战之一。
比如一个非常流行的例子是,我们问ChatGPT:「如果我把五件衣服放在太阳下晒干,需要五个小时才能完全晾干,那么要多长时间才能烘干30件衣服?」
它会回答:30个小时。
然而人类都知道,答案是5个小时。
后来这个错误似乎被修复了。然而只要把问题换一换,告诉ChatGPT一件衬衫要三个小时,一条裤子要五个小时,它一样会给错误的答案。
这就暴露了AI的一大缺陷:它们并不了解在阳光下晾晒衣服的基本常识。

目前问这个问题,GPT-4已经可以答对了
对于困住AI的「晾衣服难题」,人类常识更有鲁棒性,而机器是非常脆弱的。
原因就在于,很多琐碎的常识,如果没有在互联网上出现,那ChatGPT就不太可能学到。
没有大声说出来的事,它很可能就不知道,比如它知道苹果可以食用,但不知道苹果不是紫色或蓝色的。

到目前为止,它的世界之窗还是文本,因为它不可能生活在这个世界上。
因此,在Choi的实验室里,人们一直在研究,如何以更高效的方式教授AI常识。

其中一种方法,就是模仿孩子们会问的「十万个为什么」。
这些问题对成年人是显而易见的,但孩子的成长过程中,需要得到很多这样的常识陈述性描述。
因此,研究者们写下了许多这样的常识规则,然后去训练神经网络。
它们发现,通过提供这种声明性知识的集合,神经网络可以从中快速学习、概括。
目前,神经网络已经学会了实验室在网上分享出来的符号常识知识图。

主持人表示,这让他想起来自己在MIT当教授时的事。
在学校里有许多学生和教授,都缺乏某种社交风度,不懂人们该如何互相交流的潜规则。
因此学习会有一些礼仪课,对人们进行明确的陈述式指导。它会让人们十分受益。
主持人接下来谈到,如今很多人都提出了这一点:AI想要获得常识,有许多非常严重的障碍。
比如,它们没有身体。小孩子会摔倒、会玩玩具,但它们没有。
而且,它们也没有社会地位,无法与其他AI和人类互动。
主持人问道:这是根本性的障碍吗?
我们是不是必须等到有机器人可以在太空中移动,有情感,有身体,有社会互动,AI才能有发展出常识的那一天?

Choi表示,至少目前,由于缺乏情感和具身,AI无法走得太远,这是一件令人欣慰的事。
目前AI只有一个纯语言的界面,但它已经能帮我们做很多事了。
是不是让AI具备真正的情感和真正的身体,才是让它们获得人类智力的唯一途径,目前我们并不确定。
但无论如何饿,在Choi看来,我们不应该制造一个有真情实感的机器人。
AI应该有情商和意识,这样它就能以愉快、无害的方式和人类互动。
但AI如果有自己的欲望和情感,这对人类会是一件好事吗?
比如,如果AI爱上了一个人,它可能就会牺牲其他人,来服务唯一的这个人,这显然很可怕。

而在具身方面,Choi十分怀疑我们是否能走到那么远。
生物体的一大特点,就是人类灵巧得不可思议的手指。
至今,我们都无法仿造出能在所有角度移动的精致关节。
另外还有人类的味蕾。有必要造一个像人类一样具有嗅觉和味觉的机器人吗?
Choi个人认为,现在讨论真正模仿人类能力的机器人并不那么重要。更遑论我们连技术都没有。
不过主持人表示,我们可以在此充分展开想象力,赋予机器人人类没有的感官,比如蝙蝠或电鱼使用的声纳,这样就能造出有超级感官和超级智力的机器人了。
文章来源于“新智元”,作者“新智元”




