# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
AI 视频圈正「互扯头花」。
国外的 Luma、Runway,国内的快手可灵、字节即梦、智谱清影…… 你方唱罢我登场。无一例外,它们对标的都是那个传说中的 Sora。
其实,说起 Sora 全球挑战者,生数科技的 Vidu 少不了。
早在三个月前,国内外视频生成领域还一片「沉寂」之时,生数科技突然曝出自家最新视频大模型 Vidu 的宣传视频,凭借其生动逼真、不输 Sora 的效果,惊艳了一众网友。
就在今天,Vidu 正式上线。无需申请,只要有个邮箱,就能上手体验。(Vidu官网链接:www.vidu.studio)
例如,皮卡丘和哆啦 A 梦玩「贴脸杀」:

《暮光之城》男女主秀恩爱:

它甚至还解决了 AI 不会写字的问题:

此外,Vidu 的生成效率也贼拉猛,实现了业界最快的推理速度,仅需 30 秒就能生成一段 4 秒镜头。
接下来,我们就奉上最新的一手评测,看看这款「国产 Sora」的实力究竟如何。
上手实测:镜头语言大胆,画面不会崩坏!
这次,Vidu 亮出了绝活。
不仅延续了今年 4 月份展示的高动态性、高逼真度、高一致性等优势,还新增了动漫风格、文字与特效画面生成、角色一致性等特色能力。
主打一个:别人有的功能,我要有,别人没有的功能,我也要有。
哦莫,它竟然认字识数
现阶段,Vidu 有两大核心功能:文生视频和图生视频。
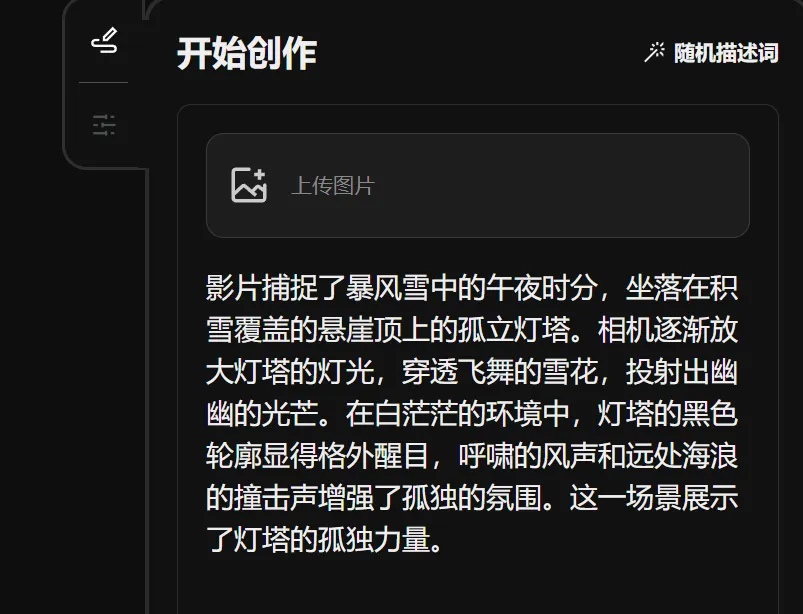
提供 4s 和 8s 两种时长选择,分辨率最高达 1080P。风格上,提供写实和动画两大选择。
先看看图生视频。
让历史重新鲜活起来,是当下最流行的玩法。这是法国画家伊丽莎白・路易丝・维瑞的名作《画家与女儿像》。

我们输入提示词:画家与女儿像,母女紧紧抱在一起。
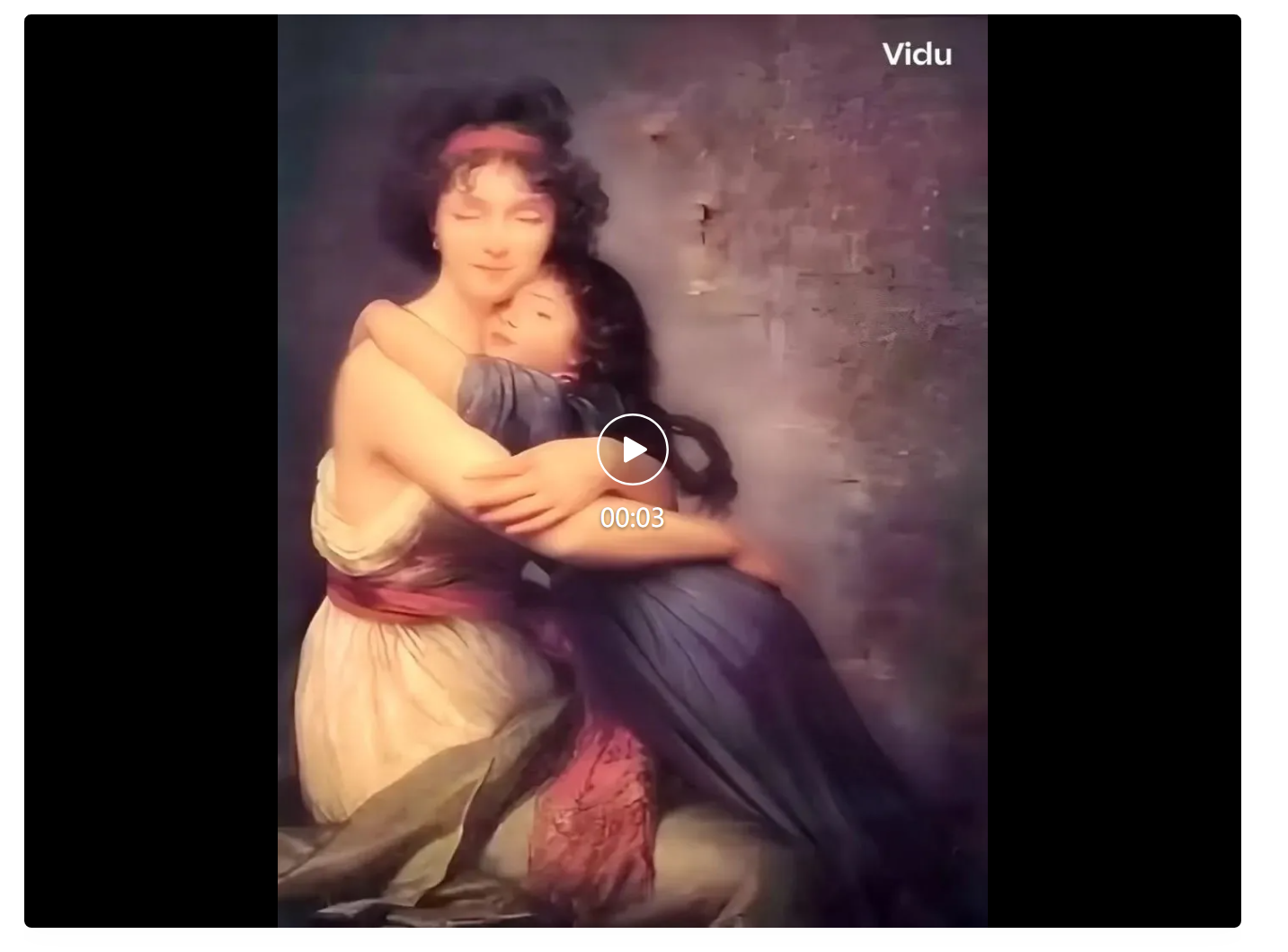
生成的高清版本让人眼前一亮,人物动作幅度很大,连眼神都有变化,但效果挺自然。
再试试达芬奇的《抱银鼬的女子》。

提示词:抱银鼬的女子面露微笑。

长达 8 秒的视频里,女子和宠物动作幅度较大,特别是女子的手部抚摸动作,还有身体、面部变化,但都没有影响画面的自然、流畅。
大幅度、精准的动作有助于更好地表现视频情节和人物情绪。不过,动作幅度一旦变大,画面容易崩坏。因此,一些模型为保证流畅性,会牺牲动幅,而 Vidu 比较好地解决了这一问题。
模拟真实物理世界的运动,还真不错。比如,复刻类似库布里克《2001 太空漫游》的情景!


提示词:长镜头下,缓缓走向消失。

提示词:长镜头下,漂浮着,慢慢飘向尽头。
除了图生视频,还有文生视频。

提示词:两朵花在黑色背景下缓慢绽放,展示出细腻的花瓣和花蕊。

提示语:这次只她一人,独自坐在樱花深处的秋千架上,穿着粉红的春衫,轻微荡着秋千,幅度很小,像坐摇椅一般,微垂着头,有点百无聊赖的样子,缓缓伸足一点一点踢着地上的青草。那樱花片片飘落在她身上头上,她也不以手去拂,渐渐积得多了,和她衣裙的颜色相融,远远望去仿佛她整个人都是由樱花砌成似的。
Vidu 语义理解能力不错,还可以理解提示中一次包含多个镜头的片段要求。
比如,画面中既有海边小屋的特写,还有运镜转向海面远眺的远景,通过镜头切换,赋予画面一种鲜明的叙事感。

提示语:在一个古色古香的海边小屋里,阳光沐浴着房间,镜头缓慢过渡到一个阳台,俯瞰着宁静的大海,最后镜头定格在漂浮着大海、帆船和倒影般的云彩。
对于第一人称、延时摄影等镜头语言,Vidu 也能准确理解和表达,用户只需细化提示词,即可大幅提升视频的可控性。

提示词:第一人称视角,女友牵着我的手,一起漫步在海边。
Vidu 是一款能够准确理解和生成一些词汇的视频生成器,比如数字。

提示词:一块生日蛋糕,上面插着蜡烛,蜡烛是数字 “32”。
蛋糕上换成「Happy Birthday」的字样,它也能hold住。

提示词:一块蛋糕,上面写着"HAPPY BIRTHDAY"。
动漫风格嘎嘎好用
目前市面上的 AI 视频工具大多局限于写实风格或源于现实的想象,而 Vidu 除了写实风格外,还支持动漫风格。
我们选择动画模型,直接输入提示词即可输出动漫风格视频。
例如,提示词:动漫风格,小女孩站在厨房里切菜。

说实话,这画风有宫崎骏老爷子的味道。Vidu 读懂了提示词,小女孩切菜动作一气呵成,就是手指和刀具在不经意间仍有变形。
提示词:动漫风格,一个戴着耳机的小女孩在跳舞。

Vidu 的想象力还挺丰富,自个儿把背景设置为带有喷泉的公园,这也让视频画面不那么单调。
当然,我们还可以上传一张动漫参考图片,再输入提示词,如此一来,图片中的动漫人物就能动起来啦。
例如,我们上传一张蜡笔小新的静态图,然后输入提示词:蜡笔小新大笑着举起手里的小花。图片用途选择「用作起始帧」。

我们来瞅瞅效果:

再上传一张呆萌皮卡丘的图像,输入提示词为「皮卡丘开心地蹦起来」。图片用途选择「用作起始帧」。

继续上效果:

上传《海贼王》路飞的图像,再喂给它提示词:男孩突然哭起来。

效果如下:

不得不说, Vidu 的动漫效果相当惊艳,在保持风格一致性的同时,显著提高了画面的稳定性和流畅性,没有出现变形、崩坏或者六指狂魔、左右腿不分等「邪门」画面。
梗图、表情包燥起来
在「图生视频」板块中,除了支持首帧图上传,Vidu 这次还上新一项功能 —— 角色一致性(Charactor To Video)。
所谓角色一致性,就是上传一个角色图像,然后可以指定该角色在任意场景中做出任意动作。
我们就拿吴京为例。


提示词:在一艘宇宙飞船里,吴京正穿着太空服,对镜头挥手。

提示词:吴京穿着唐装,站在一条古街上,向镜头挥手。
如果说,首帧图上传适合创作场景一致性的视频,那么,有了角色一致性功能,从科幻角色到现代剧,演员七十二变,信手拈来。
此外,有了角色一致性功能,普通用户创作「梗图」、「表情包」可以燥起来了!
比如让北美「意难忘」贾斯汀・比伯和赛琳娜再续前缘:

《武林外传》中佟湘玉和白展堂嗑着瓜子,聊着同福客栈的八卦:

还有《甄嬛传》皇后娘娘委屈大哭:

只要脑洞够大,什么地铁老人吃手机、鳌拜和韦小宝打啵、容嬷嬷喂紫薇吃鸡腿,Vidu 都能整出来。
就一个字,快!
视频生成过程中,用户最烦啥?当然是龟速爬行的进度条。
试想,为了一段几秒的视频,愣是趴在电脑前等个十分钟,再慢性子的人也很难不破防。
目前,市面上主流 AI 视频工具生成一段 4 秒左右的视频片段,通常需要 1 到 5 分钟,甚至更长。
例如,Runway 最新推出的 Gen-3 工具需要 1 分钟来完成 5s 视频生成,可灵需要 2-3 分钟,而 Vidu 将这一等待时间缩短至 30 秒,速度比业内最快水平的 Gen-3 还要再快一倍。

基于完全自研的 U-ViT 架构,商用精心布局
「Vidu」底层基于完全自研的 U-ViT 架构,该架构由团队在 2022 年 9 月提出,早于 Sora 采用的 DiT 架构,是全球首个 Diffusion 和 Transformer 融合的架构。

在 DiT 论文发布两个月前,清华大学的朱军团队提交了一篇论文 ——《All are Worth Words: A ViT Backbone for Diffusion Models》。这篇论文提出了用 Transformer 替代基于 CNN 的 U-Net 的网络架构 U-ViT。这是「Vidu」最重要的技术基础。
由于不涉及中间的插帧和拼接等多步骤的处理,文本到视频的转换是直接且连续的,「Vidu」 的作品感官上更加一镜到底,视频从头到尾连续生成,没有插帧痕迹。除了底层架构上的创新,「Vidu」也复用了生数科技过往积累下的工程化经验和能力。
生数科技曾称,从图任务的统一到融合视频能力,「Vidu」可被视为一款通用视觉模型,能够支持生成更加多样化、更长时长的视频内容。他们也透露,「Vidu」还在加速迭代提升。面向未来,「Vidu」灵活的模型架构也将能够兼容更广泛的多模态能力。
生数科技成立于 2023 年 3 月,核心成员来自清华大学人工智能研究院,致力于自主研发世界领先的可控多模态通用大模型。自 2023 年成立以来,团队已获得蚂蚁集团、启明创投、BV 百度风投、字节系锦秋基金等多家知名产业机构的认可,完成数亿元融资。据悉,生数科技是目前国内在多模态大模型赛道估值最高的创业团队。
公司首席科学家由清华人工智能研究院副院长朱军担任;CEO 唐家渝本硕就读于清华大学计算机系,是 THUNLP 组成员;CTO 鲍凡是清华大学计算机系博士生、朱军教授的课题组成员,长期关注扩散模型领域研究,U-ViT 和 UniDiffuser 两项工作均是由他主导完成的。
今年 1 月,生数科技旗下视觉创意设计平台 PixWeaver 上线了短视频生成功能,支持 4 秒高美学性的短视频内容。2 月份 Sora 推出后,生数科技内部成立攻坚小组,加快了原本视频方向的研发进度,不到一个月的时间,内部就实现了 8 秒的视频生成,紧接着 4 月份就突破了 16 秒生成,生成质量与时长全方面取得突破。
如果说 4 月份的模型发布展示了 Vidu 在视频生成能力上的领先,这次正式发布的产品则展示了 Vidu 在商业化方面的精心布局。生数科技目前采取模型层和应用层两条路走路的模式。
一方面,构建覆盖文本、图像、视频、3D 模型等多模态能力的底层通用大模型,面向 B 端提供模型服务能力。
另一方面,面向图像生成、视频生成等场景打造垂类应用,按照订阅等形式收费,应用方向主要是游戏制作、影视后期等内容创作场景。
文章来源于“机器之心”,作者“关注AI的”




【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
