# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
英伟达GPU,一直是OpenAI等大模型公司研发AI的命脉。
而现在,由于Blackwell GPU的设计缺陷,英伟达发货时间不得不推迟3个月,甚至更长的时间。
Information独家报道称,最近几周,台积电工程师在为Blackwell芯片量产做准备时,才发现了缺陷。

就在上周,老黄曾在SIGGRAPH上表示,英伟达已经向世界各地客户递交Blackwell工程样本。
他满脸轻松的样子,根本没有暗示任何意想不到的延误。

那么,芯片设计究竟哪里出现了缺陷?
GB200包含了2个Blackwell GPU和1个Grace CPU。问题所在,就是连接2个Blackwell GPU的关键电路上。
正是这一问题,才导致台积电生产GB200良率下降。

最新芯片推迟发货,意味着对于Meta、谷歌、微软等科技大厂来说,AI训练进程将会受到影响。
而且,他们数据中心建设也将不可避免地延期。
据称,Blackwell芯片大量出货,预计要到明年第一季度。
在SemiAnalysis最新报告中,同样详细阐述了英伟达面临的技术挑战,推迟发货后的时间表,以及新系统MGX GB200A Ultra NVL36。

Blackwell推迟三月,哀声一片
还记得GTC 2024大会上,老黄手捧最强Blackwell架构GPU,向世界宣告了最强的性能野兽。
5月,他曾公开表示,「计划在今年晚些时候,将大量出货Blackwell架构的芯片」。
甚至,他还在财报会议上信心满满地表示,「今年我们会看到大量的Blackwell收入」。
英伟达股东们更是对Blackwell GPU寄予厚望。

来自Keybanc Capital Markets的分析师估算,Blackwell芯片将为英伟达数据中心带来,将从2024年的475亿美元,提升到2025年超2000亿美元的收入。
也就是说,Blackwell系列GPU,对于英伟达未来的销量和收入起着决定性作用。
却没想到,设计缺陷直接影响了英伟达在今年下半年,以及明年上半年的生产目标。
参与Blackwell芯片设计内部人士透露,英伟达正与台积电进行测试芯片生产运行,来尽快解决难题。
不过目前,英伟达的弥补措施是,继续延长Hopper系列芯片发货量,尽可能按计划在今年下半年加速生产Blackwell GPU。
不仅如此,这个链式效应,将对大模型开发商、数据中心云服务提供商,造成了致命的打击。
为了训AI,Meta、微软、谷歌等金主爸爸们,不惜重金斥资数百亿美元,订购了大量Blackwell芯片。
谷歌已经订购了超40万个GB200,外加服务器硬件,谷歌订单成本远超100亿美元。
今年,这家巨头已经在芯片和其他设备财产上,支出预计约为500亿美元,比去年增长了超过50%。
另外,Meta也下了至少100亿美元的订单,而微软订单规模近几周增加了20%。
不过,这两家公司的具体订单规模,尚未得知。
知情人士透露,微软计划到2025年第一季度,要为OpenAI准备5.5万-6.5万个GB200芯片。
而且,微软管理层原计划在25年1月,向OpenAI提供Blackwell驱动的服务器。

现在看来,原计划需要推迟到3月,或者来年春天。
按原本预定的时间,他们将在2025年第一季度开始运行新超算集群。
包括OpenAI在内AI公司,都在等着使用新芯片开发开发下一代LLM。
因为大模型的训练还需要多倍的算力,从而能够更好回答复杂问题、自动化多步任务,生成更逼真的视频。
可以说,下一代超强AI,就指望着英伟达最新的AI芯片了。
史上罕见的延迟
不过,这次大规模芯片订单延迟,不仅在所有人意料之外,更是罕见的。
台积电最初计划在第三季度,开始量产Blackwell芯片,并从第四季度开始大规模向英伟达客户发货。
内部人士透露,Blackwell芯片现在预计将在第四季度进入量产阶段,如果没有进一步的问题,服务器将在随后的季度内大规模出货。

其实,早在2020年,英伟达旗舰GPU早期版本,也因为一些问题不得不延迟。
但当时英伟达所面临的风险较低,客户们并不急于订单到货,而且从数据中心中实现盈利也相对较少。
而这次,在量产前发现重大设计缺陷,确实非常罕见。
芯片设计师通常会与台积电晶圆厂合作,进行多次生产测试和模拟,以确保产品的可行性和顺利的制造过程,然后才会接受客户的大量订单。
对于台积电来说,停止生产线,并重新设计一个即将量产的产品,也并不多见。
他们专为GB200量产做了充分准备,包括分配专门的机器产能。
而现在,在问题解决之前,这些机器人不得不暂时闲置。
设计缺陷还将影响英伟达NVLink服务器机架的生产和交付,因为负责服务器的公司必须等待新的芯片样品,才能最终确定服务器机架设计。
被迫推出重制版
技术挑战也让英伟达不得不紧急开发一套全新的系统及组件架构,比如MGX GB200A Ultra NVL36。
而这种全新的设计,也将对数十家上下游供应商产生了重大影响。
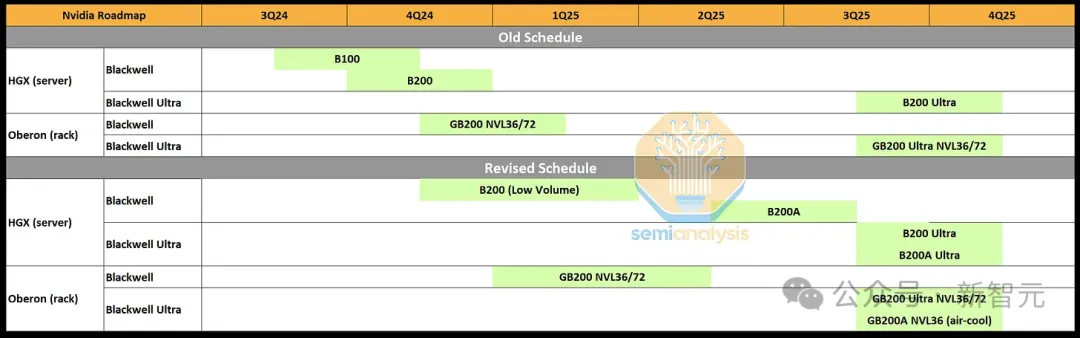
作为Blackwell系列中技术最先进的芯片,英伟达在系统层面上对GB200做出了大胆的技术选择。
这个72 GPU机架的功率密度达到了前所未有的每机架125kW。相比之下,数据中心大多数架只有12kW到20kW。
如此复杂的系统,也导致了许多与电力传输问题、过热、水冷供应链增长、快速断开的水冷系统泄漏以及各种电路板复杂性问题相关的问题,并让一些供应商和设计师措手不及。
不过,这并不是导致英伟达减少产量或重大路线图调整的原因。
真正影响出货的核心问题是——英伟达Blackwell架构的设计本身。
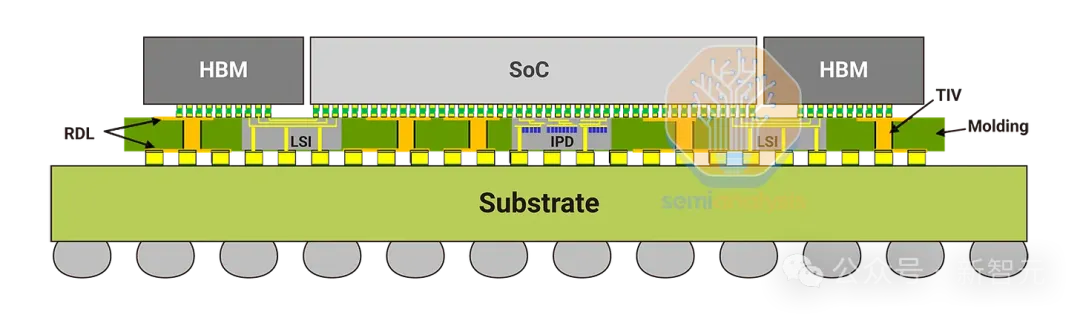
Blackwell封装是第一个使用台积电的CoWoS-L技术进行大规模量产设计的封装。
CoWoS-L需要使用带有局部硅互连(LSI)和嵌入桥接芯片的RDL中介层,来桥接封装内各种计算和存储之间的通信。
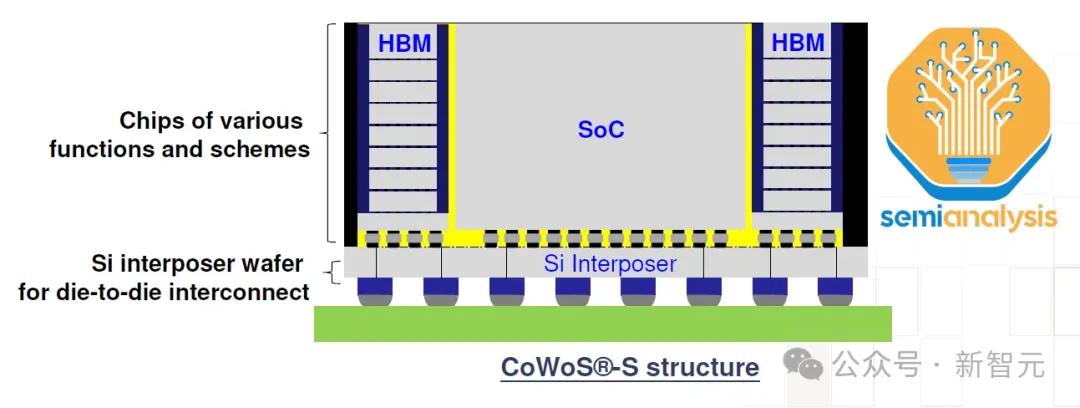
相比起目前采用的CoWoS-S技术,CoWoS-L要复杂得多,但它是未来。
英伟达和台积电制定了一个非常激进的增长计划,每季度超过一百万颗芯片的目标。
但各种各样的问题,也因此出现了。
其中一个问题是将多个细间距凸点桥嵌入有机中介层和硅中介层中,可能会导致硅芯片、桥、有机中介层和基板之间的热膨胀系数(CTE)不匹配,导致翘曲。

桥接芯片的布局需要非常高的精度,特别是涉及到2个主要计算芯片之间的桥接时,因为这些桥接对于支持10 TB/s的芯片间互连至关重要。
据传,一个主要的设计问题与桥接芯片有关。同时,顶部几层全局布线金属层和芯片的凸点也需要重新设计。这是导致多个月延迟的主要原因之一。
另一个问题是,台积电没有足够的CoWoS-L产能。
过去几年中,台积电建立了大量的CoWoS-S产能,其中英伟达占了大部分份额。
现在,随着英伟达迅速将需求转向CoWoS-L,台积电正在为CoWoS-L建造一个新的工厂AP6,并在AP3改造现有的CoWoS-S产能。
为此,台积电需要改造旧的CoWoS-S产能,否则这些产能将被闲置,而CoWoS-L的增长速度将会更慢。而这个改造过程将使得增长变得非常不均匀。
结合这两个问题,台积电显然是无法按照英伟达的需求供应足够的Blackwell芯片。
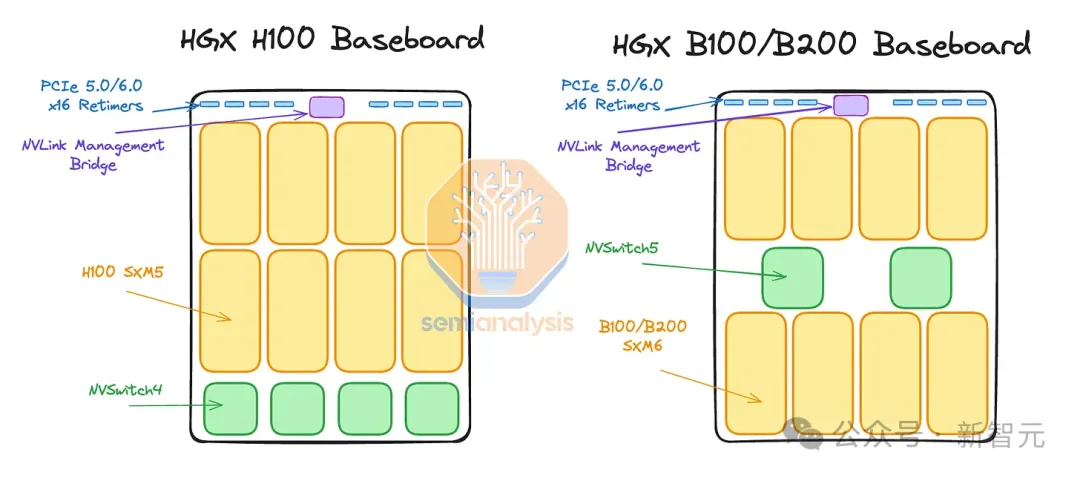
因此,英伟达几乎将所有产能都集中在GB200 NVL 36x2和NVL72机架规模系统上。并取消了搭载B100和B200的HGX计算模组。
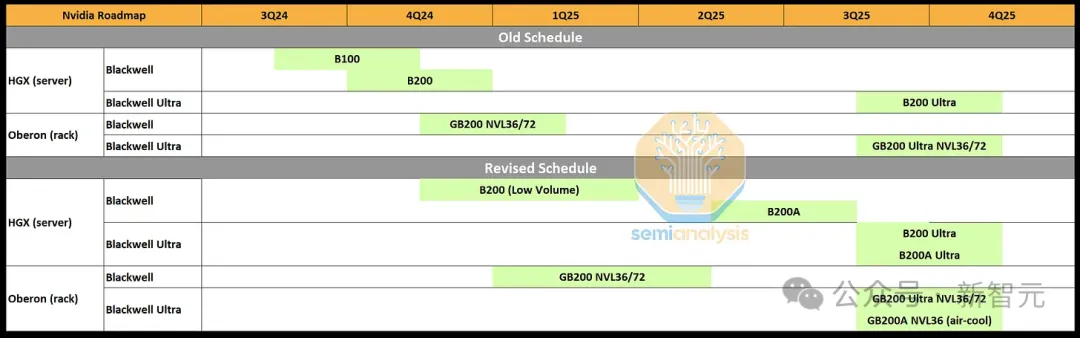
作为替代,英伟达将推出一款基于B102芯片并配有4层HBM显存的Blackwell GPU——B200A,用以满足中低端AI系统的需求。
有趣的是,这款B102芯片也将用于中国「特供版」的B20上。
由于B102是一个单片计算芯片,因此英伟达不仅可以将其封装在CoWoS-S上,而且还能让除台积电以外的其他供应商进行2.5D封装,如Amkor、ASE SPIL和三星。
B200A将以700W和1000W的HGX形态出现,配备高达144GB的HBM3E显存和高达4 TB/s的带宽。值得注意的是,这比H200的显存带宽要少。
接下来是中级增强版——Blackwell Ultra。
标准的CoWoS-L Blackwell Ultra,即B210或B200 Ultra,不仅在显存刷新方面达到高达288GB的12层HBM3E,还在FLOPS性能方面提升了高达50%。
B200A Ultra则会有更高的FLOPS,但在显存上不会进行升级。
除了有和原版B200A一样的HGX配置外,B200A Ultra还引入了一个全新的MGX NVL 36形态。

在训练少于5000个GPU的工作负载时,HGX Blackwell的性能/TCO非常出色。
尽管如此,由于基础设施更加灵活,MGX NVL36仍是许多下一代模型的理想选择。
由于Llama 3 405B已经接近H200 HGX服务器的极限,下一代MoE LLAMA 4肯定无法适应单个Blackwell HGX服务器节点。
再结合上对于MGX B200A Ultra NVL36价格的估计,SemiAnalysis认为HGX B200A卖得不会太好。
MGX GB200A Ultra NVL36架构
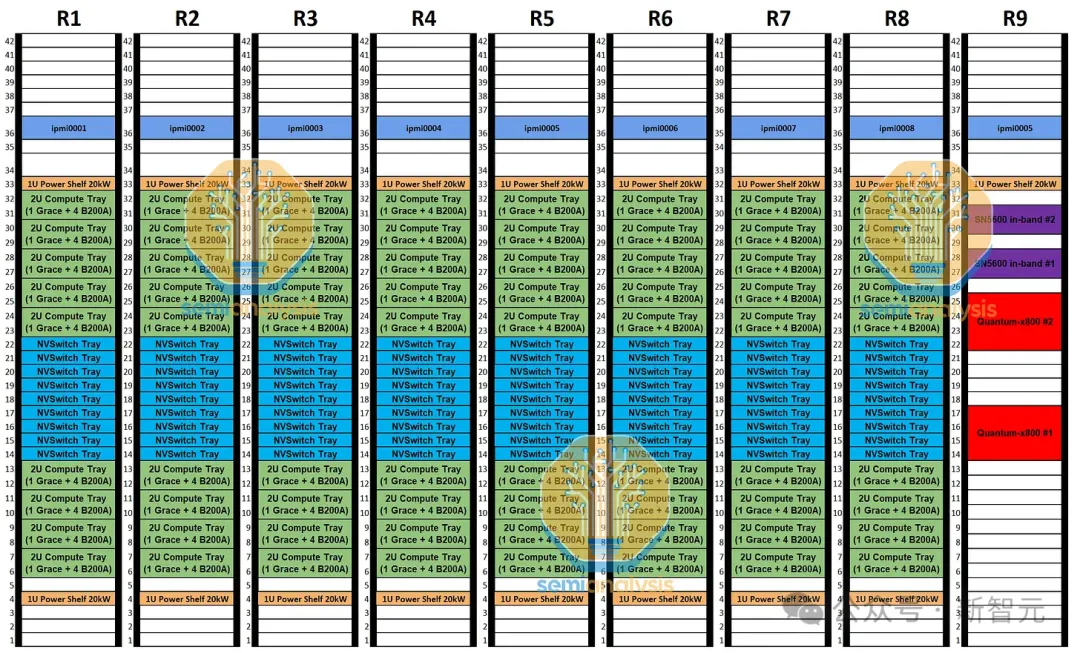
MGX GB200A NVL36 SKU是一款风冷40kW/机架服务器,配备36个通过NVLink完全互连的GPU。
其中,每个机架将配备9个计算托盘和9个NVSwitch托盘。每个计算托盘为2U,包含1个Grace CPU和4个700W的B200A Blackwell GPU。每个1U NVSwitch托盘则只有1个交换机ASIC,每个交换机ASIC的带宽为28.8 Tbit/s。
相比之下,GB200 NVL72 / 36x2包含2个Grace CPU和4个1200W的Blackwell GPU。
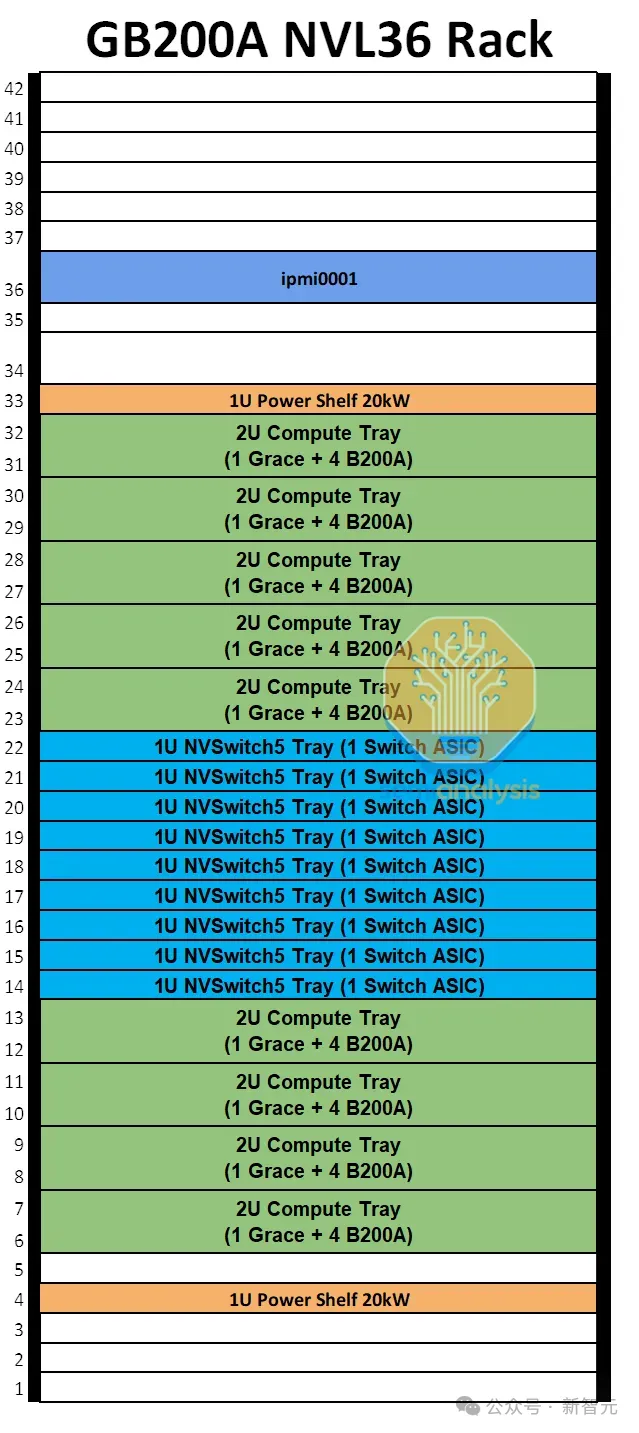
由于每个机架仅为40kW并可采用空气冷却,因此现有的数据中心运营商可以在不重新调整基础设施的情况下轻松部署MGX NVL36。
与GB200 NVL72 / 36x2不同的是,4个GPU对1个CPU的比例,意味着每个GPU只能获得一半的C2C带宽。
因此,MGX NVL36无法使用C2C互连,而是需要采用集成的ConnectX-8 PCIe交换机来完成GPU与CPU的通信。
此外,与所有其他现有的AI服务器(HGX H100/B100/B200, GB200 NVL72 / 36x2, MI300)不同,每个后端NIC现在将负责2个GPU。
这意味着尽管ConnectX-8 NIC设计可以提供800G的后端网络,但每个GPU只能访问400G的后端InfiniBand/RoCE带宽。(同样也是在GB200 NVL72 / 36x2的一半)

GB200 NVL72/NVL36x2计算托盘的核心是Bianca板,其包含2个Blackwell B200 GPU和1个Grace CPU。
由于每个计算托盘配有2个Bianca板,因此总共会搭载2个Grace CPU和4个1200W的Blackwell GPU。
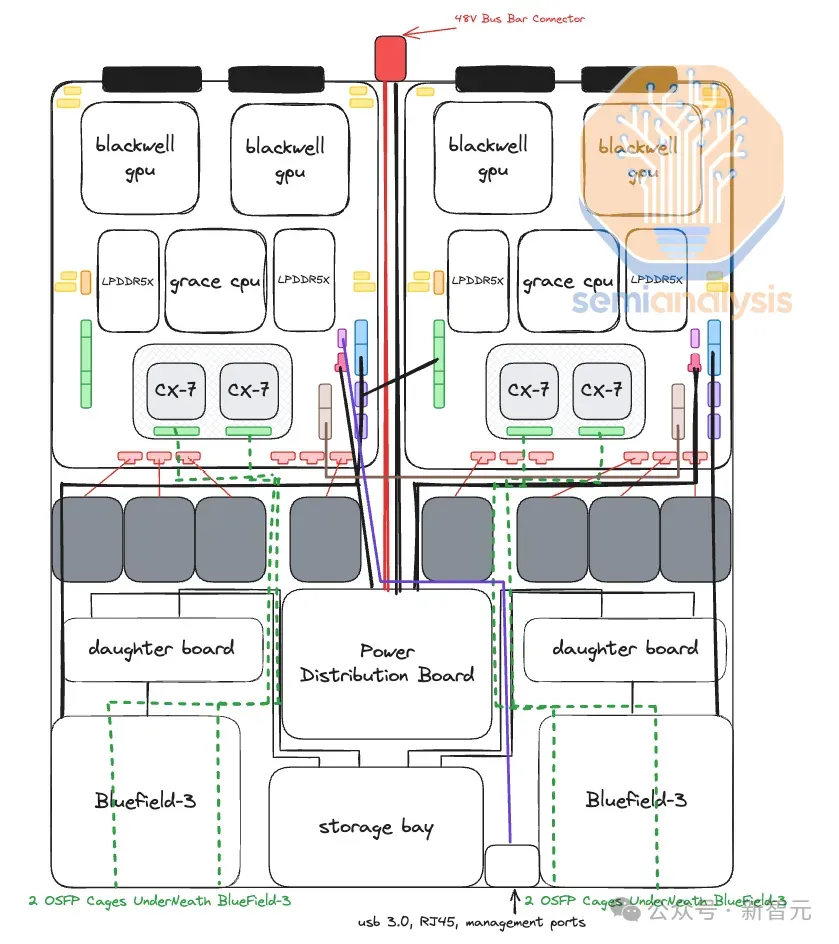
相比之下,MGX GB200A NVL36的CPU和GPU将会位于不同的PCB上,类似于HGX服务器的设计。
但与HGX服务器不同的是,每个计算托盘的4个GPU将被细分为2个2-GPU板。每个2-GPU板则搭载了类似Bianca板的Mirror Mezz连接器。
然后,这些Mirror Mezz连接器将用于连接到ConnectX-8中间板,并将ConnectX-8 ASIC与其集成的PCIe交换机连接到GPU、本地NVMe存储和Grace CPU。
由于ConnectX-8 ASIC距离GPU非常近,因此GPU和ConnectX-8 NIC之间并不需要重新定时器。而HGX H100/B100/B200需要。
此外,由于Grace CPU和Blackwell GPU之间没有C2C互连,因此Grace CPU会位于一个完全独立的PCB上,即CPU主板。该主板将包含BMC连接器、CMOS电池、MCIO连接器等。
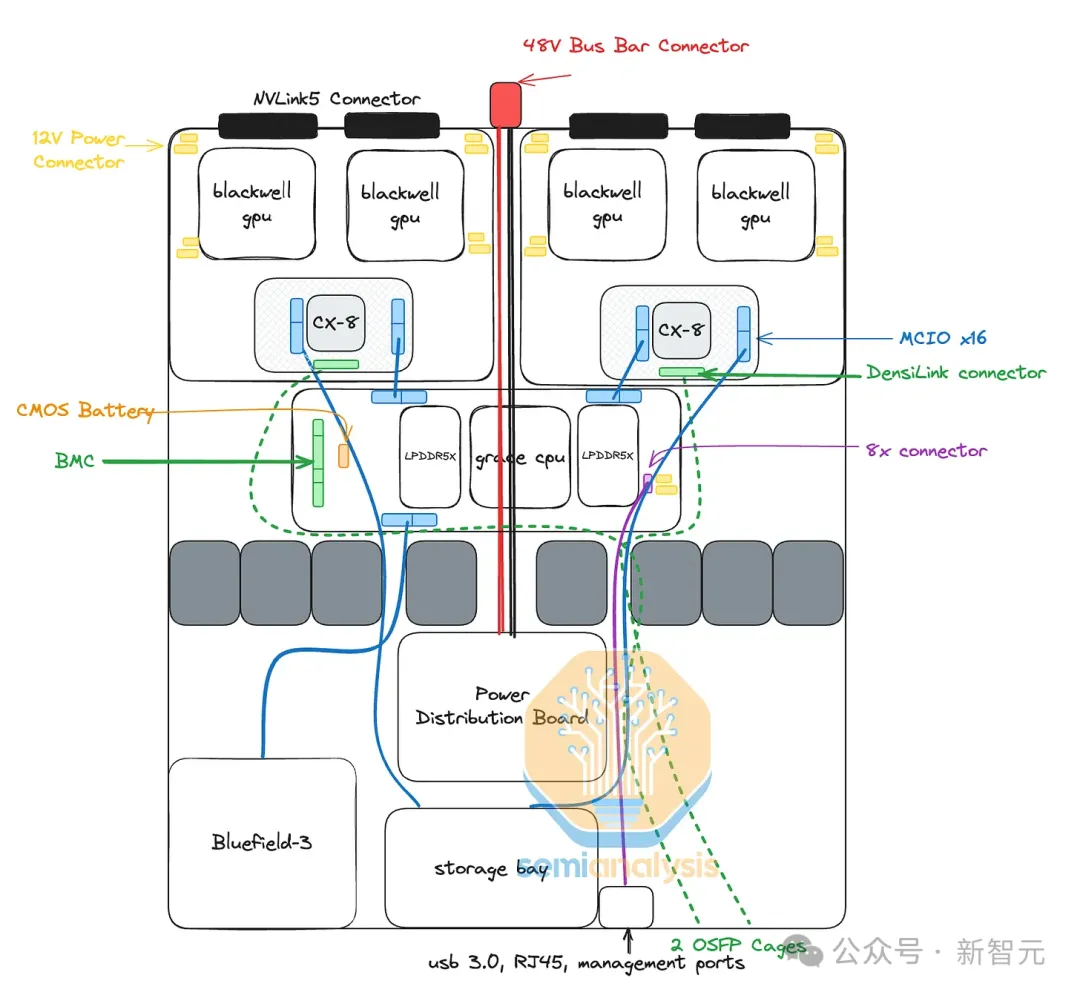
每个GPU的NVLink带宽将为每个方向900GB/s,这与GB200 NVL72 / 36x2相同。按每FLOP计算,这显著增加了GPU到GPU的带宽,使MGX NVL36在某些工作负载中更具优势。
由于只有一层交换机连接36个GPU,因此仅需9个NVSwitch ASIC即可提供无阻塞网络。
此外,由于每个1U交换托盘只有1个28.8Tbit/s的ASIC,因此非常容易进行空气冷却。比如Quantum-2 QM9700这样的25.6Tbit/s 1U交换机就可以。
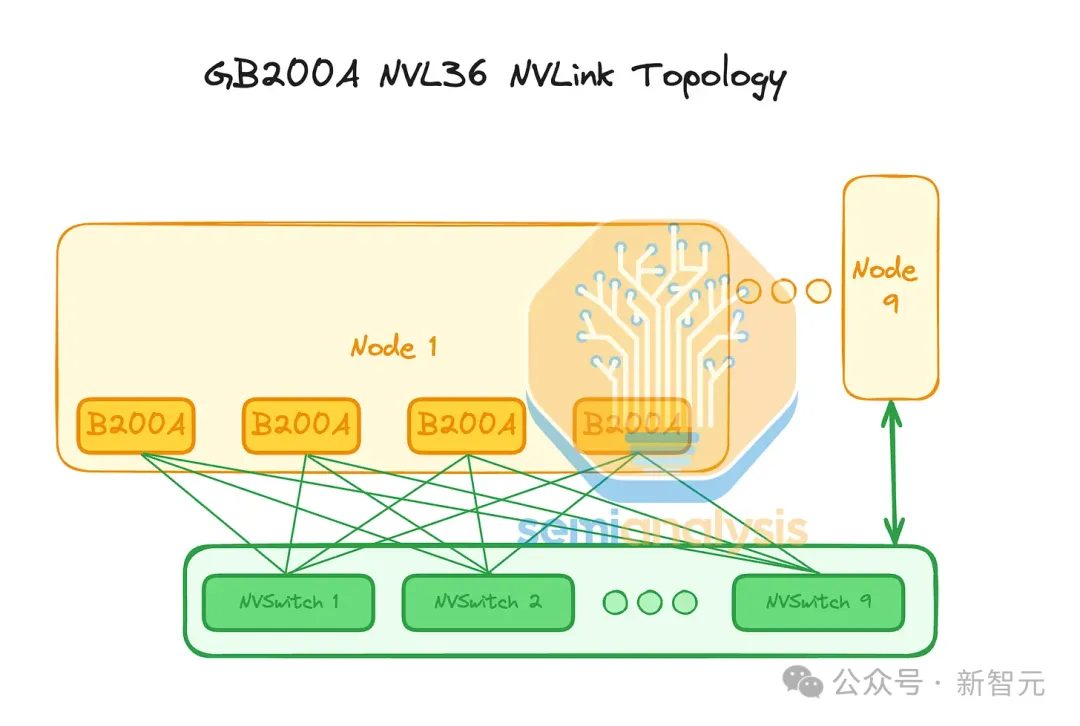
在后端网络上,由于每个计算托盘只有2个800G端口,因此它将使用2轨优化的行尾网络。
对于每8个GB200A NVL36机架,将有2个Quantum-X800 QM3400交换机。
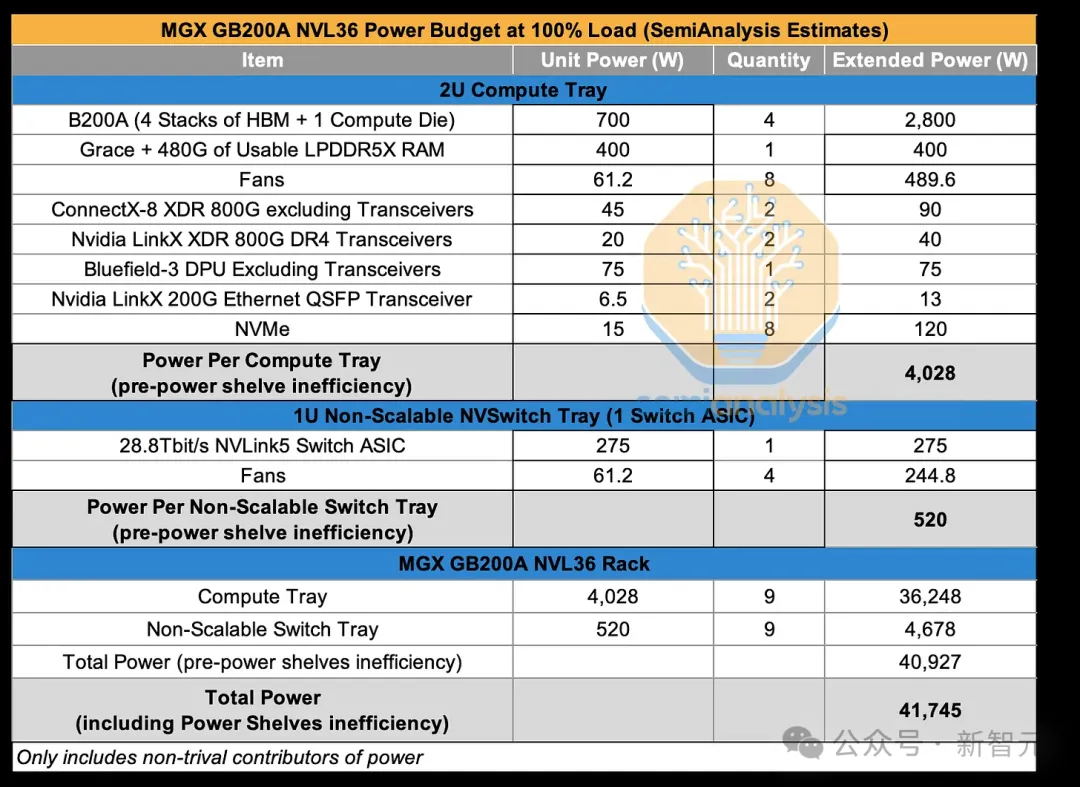
在每个GPU 700W的情况下,GB200A NVL36每个机架的功耗可能在40kW左右,即2U空间散热4kW。
如此一来,将需要专门设计的散热片和高速风扇来进行空气冷却。
部署MGX GB200A NVL 36的挑战
由于GB200A NVL36完全依靠风冷,而且在2U机箱前端除了PCIe形态的NIC外,还要有一个专用的PCIe交换机,这将显著增加热管理的挑战。
因此,在GB200A NVL36上进行定制后端NIC基本上是不可能的。
由于许多机器学习依赖项是为x86 CPU编译和优化的,且Grace CPU和Blackwell GPU位于单独的PCB上,因此很可能还会有一个x86 + B200A NVL36版本。
不过,x86 CPU虽然可以提供更高的峰值性能,但功耗也会相应高出100W,从而极大增加了OEM的热管理挑战。
此外,考虑到Grace CPU的销量问题,即便英伟达推出了x86 B200A NVL36解决方案,他们也会push客户去选择GB200A NVL36。
当然,GB200A NVL36也有自己的卖点——每机架40kW的风冷系统。
毕竟,很多客户并不能负担得起每机架约125 kW的GB200 NVL72(或总功耗超过130kW的36x2)所需的液冷和电力基础设施。
H100的TDP为700W,目前使用的是4U高的3DVC,而1000W的H200使用的是6U高的3DVC。
相比之下,MGX B200A NVL36的TDP也是700W但机箱只有2U,空间相当受限。因此将需要一个水平扩展的阳台状散热片来增加散热片的表面积。

除了需要更大的散热片外,风扇还需要提供比GB200 NVL72 / 36x2 2U计算托盘或HGX 8 GPU设计更强的气流。
根据估计,在40kW机架中,15%到17%的总系统功率将用于内部机箱风扇。相比之下,HGX H100的风扇也只消耗总系统功率的6%到8%。
由于需要大量的风扇功率来使 MGX GB200A NVL36 正常工作,这是一种效率极低的设计。
为什么取消GB200A NVL64
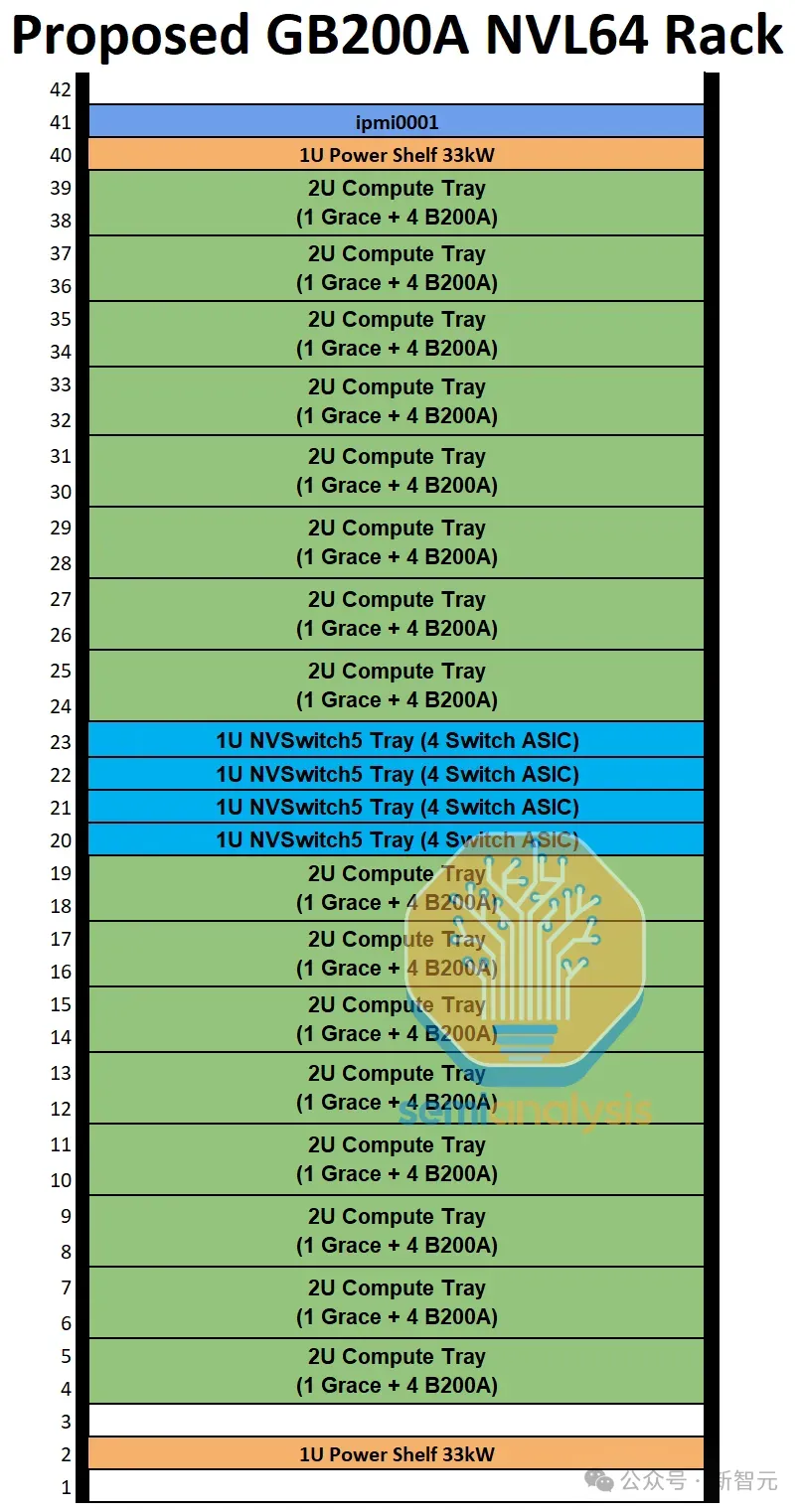
在英伟达最终确定MGX GB200A NVL36之前,他们也在尝试设计一个空气冷却的NVL64机架——功耗60kW,搭载64个通过NVLink完全互连的GPU。
然而,在经过广泛的工程分析之后,SemiAnalysis认为这个产品并不可行,且不会上市。
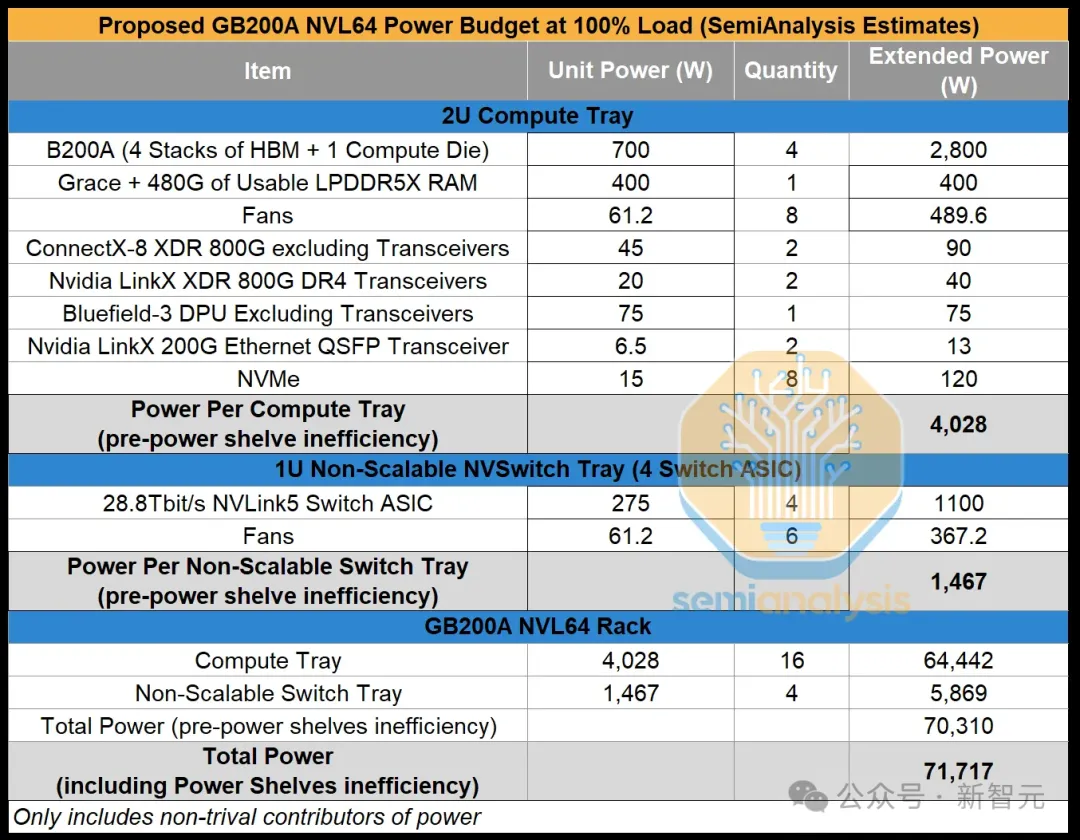
在提议的NVL64 SKU中,有16个计算托盘和4个NVSwitch托盘。每个计算托盘是2U,包含1个Grace CPU和4个700W的Blackwell GPU,就像MGX GB200A NVL36一样。
主要的修改在于NVSwitch托盘——英伟达没有将GB200每个托盘的2个NVSwitch减少到1个,而是尝试将其增加到4个ASIC交换机。
显然,仅靠空气冷却功耗如此之高的庞然大物几乎是不可能的。(英伟达提出的是60kW,SemiAnalysis估算是70kW)
这通常需要使用后门热交换器,但这破坏了空气冷却机架架构的意义,因为仍然依赖于液冷供应链。此外,这种解决方案仍然需要大多数数据中心进行设施级别的改造,以便将冷却水输送到后门热交换器。
另一个非常棘手的热问题是NVSwitch托盘将在1个1U机箱中包含4个28.8Tbit/s的ASIC交换机,需要近1500W的散热功率。
单独来看,1U机箱实现1500W并不困难。但是,当考虑到从ASIC交换机到背板连接器的Ultrapass飞线会阻挡大量气流,冷却挑战就变得非常大了。
鉴于空气冷却的MGX NVL机架需要以极快的速度推向市场,英伟达试图在设计开始后6个月内就交付产品。然而,对于一个已经资源紧张的行业来说,设计新的交换托盘和供应链是非常困难的。
GB200A NVL64的另一个主要问题是每个机架有64个800G后端端口,但每个XDR Quantum-X800 Q3400交换机搭载的是72个800G下游端口。也就是说,每个交换机将有16个800G端口空置。
在昂贵的后端交换机上有空置端口会显著影响网络性能和总拥有成本,因为交换机非常昂贵,尤其是像Quantum-X800这样高端口密度的模块化交换机。

此外,在同一个NVLink域中使用64个GPU并不理想。
表面上看,64是一个很好的数字,因为它有2、4、8、16和32作为公因数,这对于不同的并行配置来说非常合适。
例如,张量并行TP=8,专家并行EP=8,或TP=4,完全分片数据并行FSDP=16。
不幸的是,由于硬件的不可靠性,英伟达建议每个NVL机架至少保留1个计算托盘作为备用,以便在维护时将GPU下线并作为热备份使用。
如果每个机架没有至少1个计算托盘处于热备用状态,即使是1个GPU故障也会导致整个机架被迫停用相当长的时间。这类似于在8-GPU的HGX H100服务器上,只要有1个GPU故障,就会迫使所有8个H100停用。
如果保留至少一个计算托盘作为热备份,意味着每个机架只有60个GPU能够处理工作负载。这样一来,刚刚提到的那些优势就不复存在了。
而NVL36×2或NVL72则搭载了72个GPU,也就是说,用户不仅可以把2个计算托盘作为热备用,而且每个机架上仍有64个GPU可供使用。
GB200A NVL36则可以有1个计算托盘作为热备用,此时有2、4、8、16作为并行方案的公因数。
对供应链的影响
根据SemiAnalysis的推测,GB200 NVL72 / 36x2的出货量会减少或推迟,B100和B200 HGX的出货量则会大幅减少。
同时,Hopper的出货量将在2024年第四季度至2025年第一季度有所增加。
此外,GPU的订单将在下半年从HGX Blackwell和GB200 NVL36x2转移到MGX GB200A NVL36上。
这将影响所有的ODM和组件供应商,因为出货和收入计划将在2024年第三季度至2025年第二季度发生显著变化。
文章来源于“新智元”,作者“新智元”



【开源免费】OWL是一个完全开源免费的通用智能体项目。它可以远程开Ubuntu容器、自动挂载数据、做规划、执行任务,堪称「云端超级打工人」而且做到了开源界GAIA性能天花板,达到了57.7%,超越Huggingface 提出的Open Deep Research 55.15%的表现。
项目地址:GitHub:https://github.com/camel-ai/owl
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
