# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
英伟达版Sora曝光——
代号Cosmos,研究副总裁刘洺堉担任负责人。
不过随着几份内部文件的泄露,他们还被曝非法抓取数据。

(确实这也不是一次两次了……)
员工被默许每天在网络上抓取任何未经授权、未经同意数据,比如YouTube、奈飞等等这种平台上。
合起来,每天抓取的几乎是一个人80年能感知到的视觉数据。
结果英伟达回应称:我们这做法,完全合法!

据404Media所获取的泄密文件显示,英伟达每天都会抓取非法数据来训练新模型。
Cosmos的目标是构建一个最先进的视频基础模型。据泄露的邮件显示该模型集合了光传输、物理和智能的模拟,以解锁对各种下游应用。
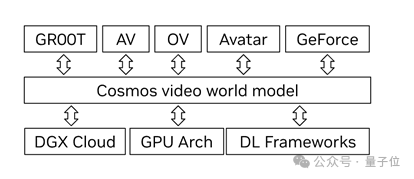
比如被用到Omniverse 3D 世界生成器、自动驾驶汽车系统和数字人产品。
英伟达研究副总裁Ming-Yu Liu(刘洺堉)担任Cosmos的项目负责人。

他同时也是IEEE Fellow。他带领英伟达Deep Imagination研究小组,推出了NVIDIA Picasso [Edify]、NVIDIA Canvas [GauGAN]和NVIDIA Maxine [LivePortrait]等产品。
此前5月份的一封电子邮件中显示:
我们正在完成 v1 数据管道并确保必要的计算资源,以构建一个视频数据工厂,该工厂每天可以产生相当于人类一生视觉体验的训练数据。
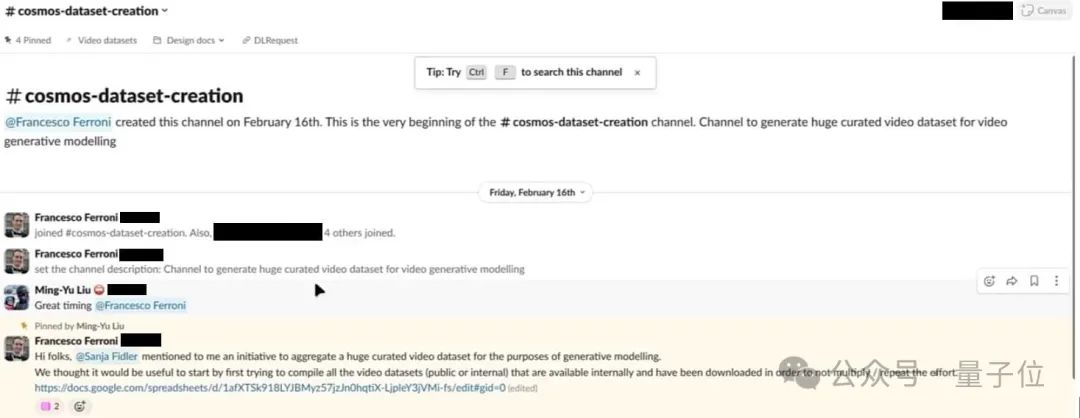
这张图中显示英伟达首席科学家 Francesco Ferroni给了个表格链接,里面汇集了各种视频数据集,包括 MovieNet(一个包含 60,000 个电影预告片的数据库)、WebVid、 InternVid-10M,以及几个内部捕获的视频游戏镜头数据集。
如今据一位前员工爆料称,员工会被要求从YouTube、奈飞等来源来抓取数据。
他们会使用一个名为yt-dlp的开源YouTube视频下载器,它能使用虚拟机来刷新IP地址,以避免被YouTube屏蔽。
为此,英伟达向404 Media回应称:
我们尊重所有内容创作者的权利,并相信我们的模型和研究工作完全符合版权法的条文和精神。
版权法保护特定的表达方式,但不保护事实、想法、数据或信息。任何人都可以自由地从其他来源了解事实、想法、数据或信息,并用它来表达自己的观点。合理使用还保护将作品用于变革性目的的能力,例如模型训练。”
而谷歌则是扔给404 Media一个链接,今年4月YouTube CEO表示,如果OpenAI用YouTube视频来训练Sora,那么明显违反YouTube的使用条款。
而奈飞则表示,他们并未与英伟达达成内容提取协议,而且该平台的服务条款不允许抓取内容。
有意思的是,同一天,YouTube博主正在寻求对OpenAI集体诉讼,指控该公司在未通知或补偿视频所有者的情况下,使用数百万条 YouTube 视频记录来训练其生成式 AI 模型。
而此前这些大厂被曝非法抓取数据的事情也屡见不鲜。
不过必须要说的是,这种原始数据真的很有用…
之前英伟达还用游戏视频,来改善训练数据质量。
最近登上Nature封面的那篇研究显示,这种用最初互联网数据训练的大模型,具有先发优势,数据质量最好,对应的模型性能也最好。
之后随着AI数据越来越泛滥,反而容易让大模型崩溃。
Garbage in,Garbage out。
对于这件事,你怎么看呢?
文章来源于“量子位”,作者“关注前沿科技”



【开源免费】Fay开源数字人框架是一个AI数字人项目,该项目可以帮你实现“线上线下的数字人销售员”,
“一个人机交互的数字人助理”或者是一个一个可以自主决策、主动联系管理员的智能体数字人。
项目地址:https://github.com/xszyou/Fay
【开源免费】LivePortrait项目可以实现高效的人像动画,通过拼接和重定向控制技术,使一个静态人像或动物图像能够变成动态的视频,变成动画形式。
项目地址:https://github.com/KwaiVGI/LivePortrait?tab=readme-ov-file
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
