# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
Benedict Evans是一位知名的独立科技分析师,拥有超过20年的移动、媒体和技术领域分析经验。他曾在股权研究、战略、咨询和风险投资等多个领域工作,包括在著名风险投资公司Andreessen Horowitz(a16z)担任合伙人,负责研究和分析科技行业的趋势和发展,为公司投资决策提供支持。
Evans以其对科技行业的深刻见解和战略分析而闻名,他每年制作大型演讲,深入探讨互联网的现状和未来趋势。此外,他运营着一个订阅者超过13万的每周通讯,分享他对大型科技公司战略动向、市场趋势和技术对社会长远影响的分析。Evans经常在科技大会和行业论坛上发表演讲,并在社交媒体上分享实时洞察,是科技界的重要意见领袖。
The AI summer
数以亿计的人体验过ChatGPT,但许多人尝试过后便未再回头。每家大型企业也都曾尝试过相关试点项目,但真正投入应用的却寥寥无几。这其中部分原因可能只是时间问题。然而,大型语言模型(LLMs)可能也存在陷阱:它们看似是产品,给人以神奇之感,但实际上并非如此。或许,我们终究需要经历寻找产品与市场契合点的漫长而单调的探索过程。
我前任上司Marc Andreessen曾说,网络泡沫时期的每一个失败想法如今都有成功的可能。这需要时间——宽带网络的建设需要数年时间,消费者需要购买个人电脑,零售商和大型企业需要构建电子商务基础设施,整个在线广告业务需要发展和壮大,更重要的是,消费者和企业的行为必须发生改变。未来的到来可能仍需要很长一段时间——美国零售业花了20多年才有20%的业务转移到线上。

人们现在可能忘记了,但iPhone在早期也经历了一段缓慢的起步时间。苹果在最初的12个月里仅售出了540万部iPhone,直到2010年,iPhone的销售才真正开始起飞(iPod的普及则花了更长时间)。这同样适用于企业市场。尽管在科技行业内部,云计算已经被视为一个成熟且司空见惯的技术,但事实上,即便在Marc Benioff(Salesforce的创始人)25年前尝试说服人们在浏览器中使用软件之后,企业的工作流程中也只有大约三分之一采用了云计算。
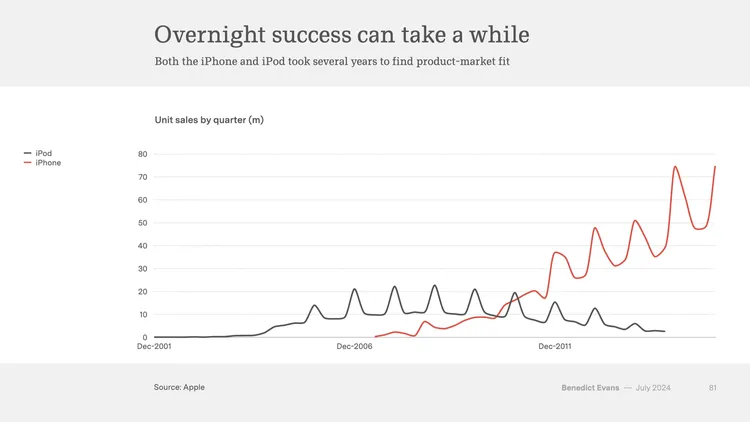
ChatGPT的发展速度要快得多。它在2022年底突然闯入我们的视线,并几乎立即占据了科技领域的所有关注焦点。如果你现在正在创办一家初创公司,而这家公司不是专注于生成式AI,你所有的朋友都会指着你笑;但更重要的是,ChatGPT仅用了2个月就达到了1亿用户。到了2023年春天,前所未有的人都已经听说过并使用过它。
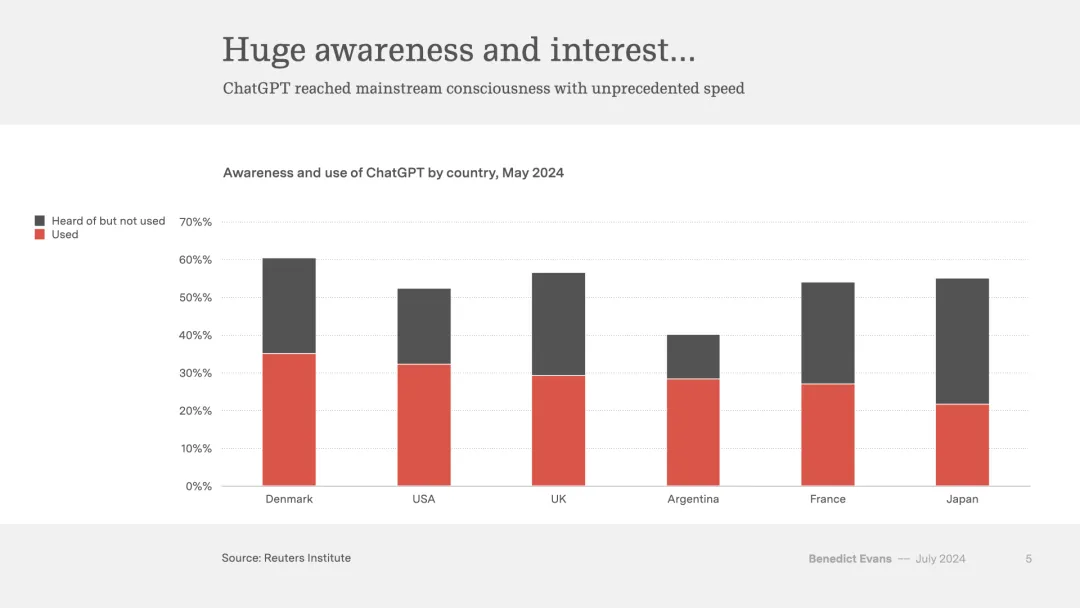
正如对技术采纳加速的每一次观察,很大程度上我们都得益于前人的努力——OpenAI 无需等待消费者购买新设备,也不必等待电信运营商去建设DSL或3G网络。对消费者而言,ChatGPT 仅是一个网站或一个应用程序,OpenAI能够直接利用我们过去25年所建立的技术基础设施。因此,去年有许多人尝试了这项新技术。
然而,问题在于,这些尝试者中的大多数并没有成为回头客。如果你深究“使用”一词的含义,你会发现大多数人仅仅是出于好奇尝试了一两次,或者只是偶尔每几周回来使用一次。
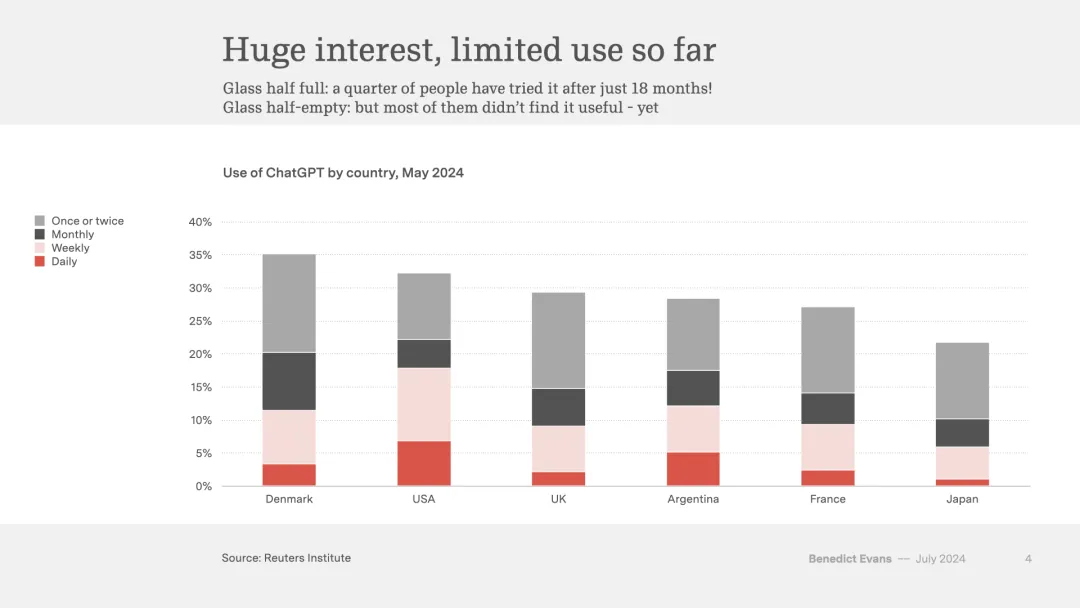
上面这张图表展示了一种典型的乐观与悲观视角。一方面,说服发达国家四分之一到三分之一的人口在18个月内尝试一款新产品,无疑是一项艰巨的任务。另一方面,许多尝试过这款产品的人似乎并未发现其价值所在。
这里不可避免地存在选择偏差:如果你已经投资了650美元购买一部智能手机,那么你很可能已经认定它具有价值,并且不太可能轻易放弃它,这与那些你仅投入五分钟尝试的网站相比,态度截然不同。同样值得指出的是,这些模型的最优版本往往隐藏在付费版本之后。
然而,如果这是一款真正能够颠覆一切的神奇产品,为何大多数人在体验后只是轻描淡写地评价一句“确实很聪明,但似乎不适合我”,然后便转身离去?为何在过去的9至12个月里,我们观察到的活跃用户数量(而非仅仅是出于好奇的用户)并没有显著增长,这从一系列类似的调查中可见一斑?
最引人深思的可能是谷歌趋势数据,尽管这些数据需要谨慎解读,但它们似乎确实揭示了与学校假期的某种相关性。
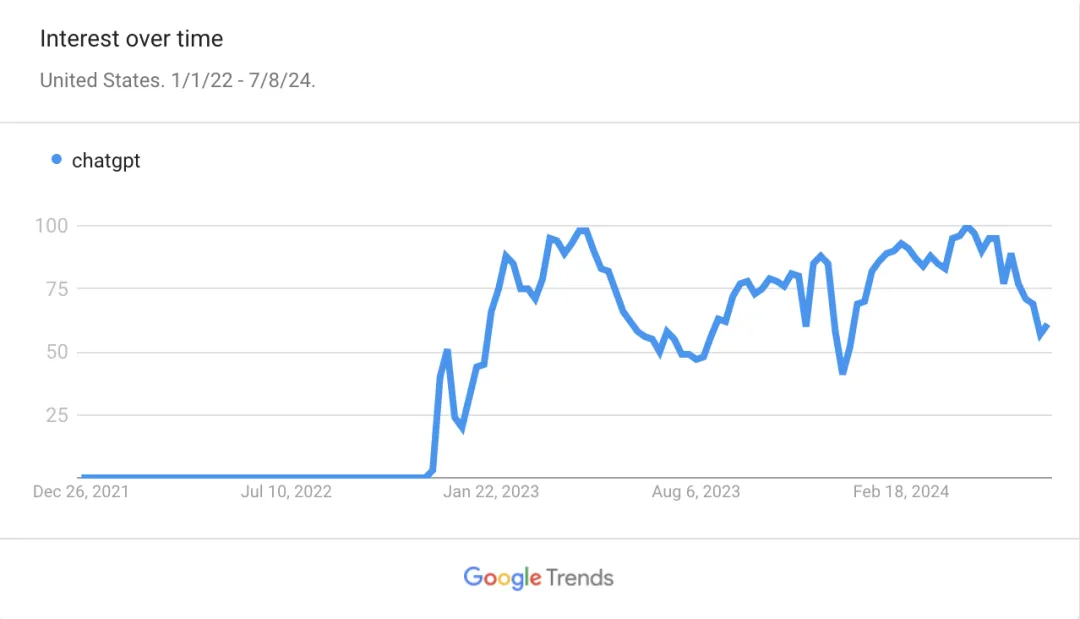
对于这个问题,我们有多种解答路径。培养新习惯,适应一种全新工具的思维模式,确实需要时间的沉淀(回想一下我们曾经将电子邮件打印出来的时代)。我们可以预见,随着技术的进步,这些模型至少在某种程度上将变得更加精准——无论是代理(agents)技术、语音识别还是多模态交互,都将拓展它们解决问题的边界。
然而,正如我在去年10月所讨论的,大语言模型(LLM)本身并不直接是一个产品——它是一种潜在的技术力量,能够激发工具或特性的创新。要让这种技术真正发挥作用,需要将其解构并重新整合到创新的框架、用户体验(UX)和工具设计中,这一过程无疑需要更多的时间。
从贝恩公司对企业界使用LLM的调查数据中,我们可以观察到相同的双重视角问题。这可以被视为一幅既包含乐观也包含悲观元素的图表:兴趣盎然,部署活跃,但具体的情况取决于你的观察角度。
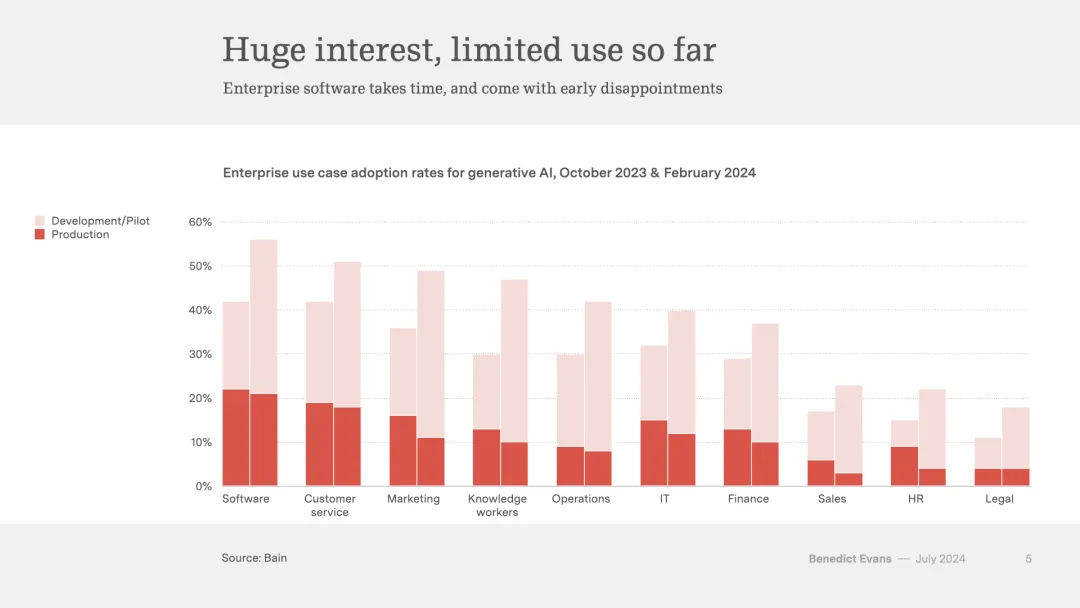
与那些简单询问“你们组织中有人在使用这项技术吗?”的调查不同,贝恩公司试图细致地区分试点项目、实验和试验与真正的部署。虽然每个企业或其他组织都可能进行着一些测试,但真正将这些技术融入其核心业务流程的组织却寥寥无几,这种差异很大程度上取决于具体的应用场景。
大语言模型(LLM)在编程和市场营销领域已经证明了其巨大的潜力,然而对于法律行业或人力资源部门来说,它们的价值则显得不那么明显(律师们对于任何新技术的接受度通常都较为缓慢)。
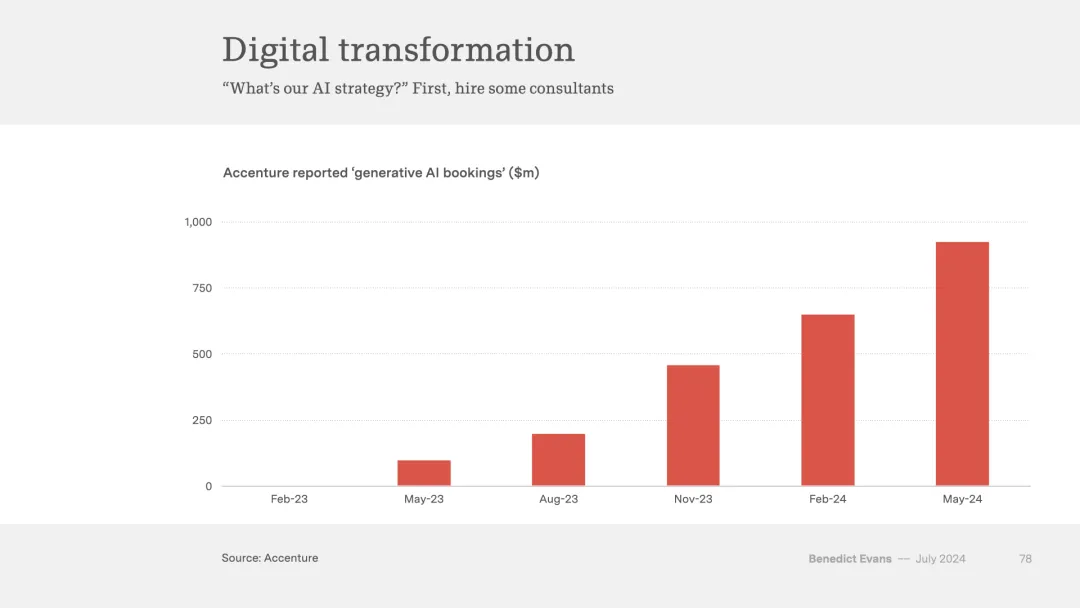
与此同时,埃森哲提供了一个鲜明的例证,展示了企业在生成式人工智能领域的实验规模,同时也反映出这些实验目前大多还停留在探索阶段——这同样是一个充满希望与挑战并存的景象。
埃森哲的例子显示了企业对生成式AI的实验规模,但目前这些实验大多数只是试点项目,而非实际部署。去年,埃森哲完成了3亿美元的生成式AI工作,涉及300个项目。平均每个项目价值100万美元,这表明很多项目只是试验性质的,而不是全面应用。
此外,波士顿咨询集团(BCG)预计今年其20%的收入将来自帮助大公司应对生成式AI,这表明生成式AI的市场需求很大,但很多公司仍在探索和理解其应用。这意味着,在2024年,咨询公司可能会在解释和帮助企业理解生成式AI方面获得大量业务。
这些图表实际上描述了当AI乌托邦式的梦想遇上消费者行为和企业IT预算的混乱现实时会发生什么——事情的发展比你想象的要慢,而且过程复杂(这也是我认为“末日论者”很天真的一个原因)。
企业通常的IT销售周期比Chat GPT3.5发布以来的时间还长,摩根士丹利最新的CIO调查显示,30%的大公司CIO预计在2026年之前不会部署任何产品。他们可能过于谨慎,但上面的云采用图表(特别是预期数据)表明了相反的情况。记住,贝恩的“生产”数据只意味着某处、某人正在使用这项技术,并不意味着它已经接管了你的工作流程。
然而,退一步来看,ChatGPT从一个科学项目迅速增长到1亿用户的速度可能本身就是一个陷阱(正如自然语言处理技术对Alexa的影响一样)。大语言模型(LLMs)看起来有效,它们看起来具有通用性,它们看起来像是一个产品——它们的科学成果是一个聊天机器人,而聊天机器人看起来像是一个产品。你输入一些内容,就会得到神奇的回应!但这种神奇的效果可能并不实用,甚至可能是错误的。它看起来像是一个产品,但实际上并不是。
微软去年年初试图将这项技术强行整合到Bing中以对抗谷歌,但最终失败并被遗忘,这是问题的一个很好的缩影。LLMs看起来像是更优秀的数据库,看起来像是搜索引擎,但正如我们所见,它们“错误”的程度足够高,而且“错误”难以管理,以至于你不能仅仅给用户一个原始的提示和一个原始的输出——你需要围绕它构建许多专门的产品,即便如此,也不清楚这究竟有多大用处。
匆忙推出基于LLM的网络搜索就是陷入了这个陷阱。萨蒂亚·纳德拉曾表示他想让“谷歌起舞”,但具有讽刺意味的是,与“Bing Copilot”竞争的最佳方式可能是耐心等待——观望、学习并在推出任何产品之前深思熟虑(当然,如果华尔街允许的话)。
将这项技术急于整合到搜索中,部分是出于竞争压力和股市压力,但更根本的是出于一种感觉,即这是下一个平台转变,你必须全力以赴抓住它。这比谷歌的影响要广泛得多。这种紧迫感被“站在巨人肩膀上”的时刻加速了——你没有时间等待人们购买设备——而且这些技术看起来像是成品。与此同时,这些公司在过去十年中产生的大量现金与尖端LLMs的巨大资本密集度相碰撞,就像物质与反物质相遇一样。
换句话说——“这些技术是未来,将立即改变一切,它们需要所有这些资金,而我们拥有所有这些资金。”
正如许多人现在所指出的,所有这些加起来导致了巨额的资本支出(以及其他许多投资)被提前用于一项大多仍处于实验预算中的技术。
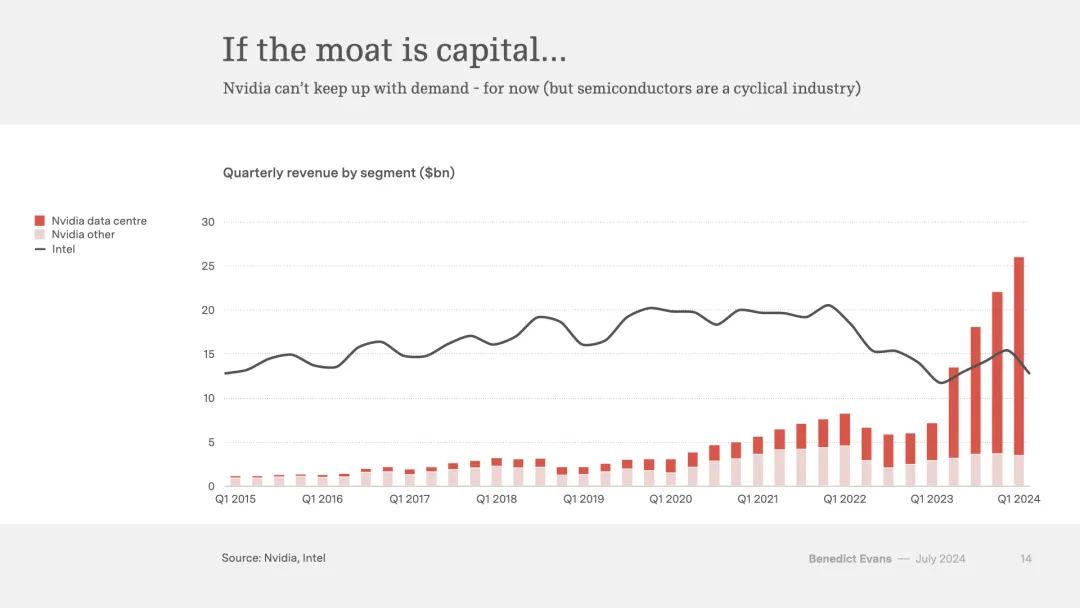
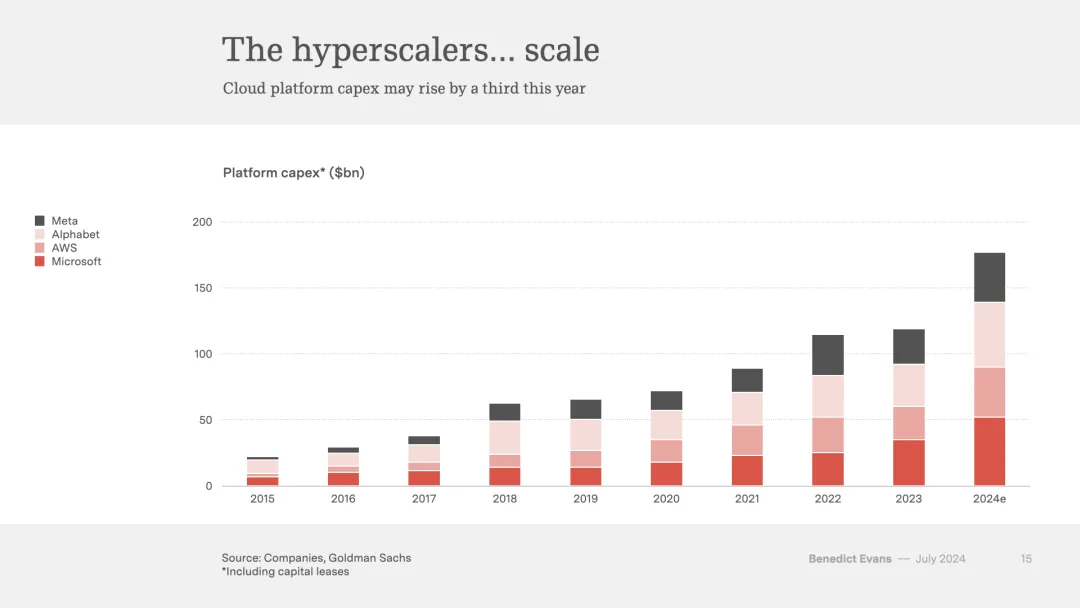
这种急于求成意味着我们已经跳过了S曲线底部缓慢而痛苦的阶段,在这个阶段,你试图弄清楚产品与市场的契合度是什么,同时你正在构建实际的产品。网络、电商和iPhone都必须经历一个痛苦的成长和学习过程,才能变得有用。
App Store最初并不是iPhone计划的一部分,而蒂姆·伯纳斯-李(Tim Berners-Lee,万维网World Wide Web的发明者)最初设计网页浏览器的时候,并没有把它作为一个内容发布的平台来看待。相反,他设计了一个包含编辑器的浏览器,主要是为了方便人们编辑和存储信息,就像使用一个网络驱动器那样。大语言模型(LLMs)跳过了这个部分,在人们还未弄清楚这是什么以及它的用途之前,就直接进入了“它适用于一切!”的阶段,意味着在遇到真正的用户之前并没有真正进行深入思考。
这张图表因此显得特别有趣。直接的怀疑论解释是,这是一次典型的投资激增,即使还不是泡沫的话,它也将不可避免地变成泡沫。
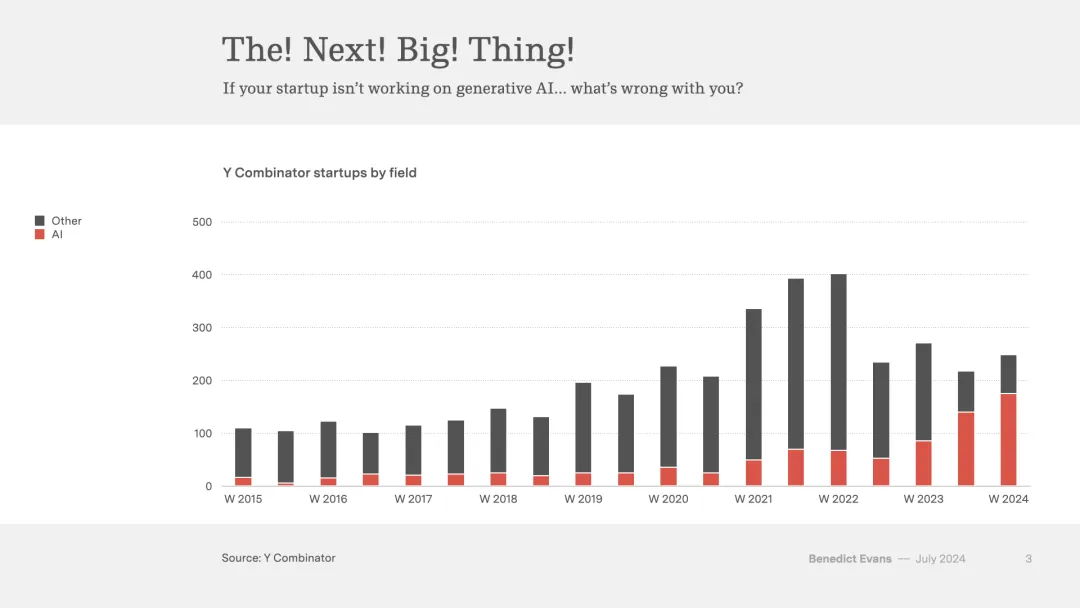
当然,这些初创公司(指的是那些专注于开发和应用LLMs的公司)代表了硅谷对大语言模型(LLMs)的集体赌注,他们认为LLMs是一种技术而非单一产品,并且我们需要经历传统的客户发现过程来实现产品与市场的契合。至少可以说,推动生成式人工智能泡沫的真正因素是这样一个观点:历史已经结束,LLMs将能够完成所有任务,如果真的是这样,我们就不需要这些公司中的任何一个了。(这句话基于一个假设的情景:如果LLMs最终能够完成所有任务,变得如此强大和多才多艺,那么市场上可能就不再需要如此多专门从事LLMs研究和应用的公司,因为LLMs自己就能够满足各种需求。)从这个角度来看,这些公司实际上是反泡沫的,这是一个非常乐观的想法。
当然,互联网络泡沫时代的那些疯狂梦想如今确实成真了,AI乌托邦主义者也或许是对的——大语言模型(LLMs)可能真的能够包办一切。它们不仅可能整合并取代现有的众多软件应用,还可能独立或在全新构建的产品、公司及企业销售层面的支持下,自动化那些以前从未被软件触及的复杂任务类型。这或许将成为科技史上首个呈现出J型增长路径的S型技术发展曲线。但这样的转变不会在本年度内发生。
文章来自于微信公众号非凡产研 作者Benedict Evans



【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
