# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
只需30秒,AI就能像3D建模师一样,在各种指示下生成高质量人造Mesh。
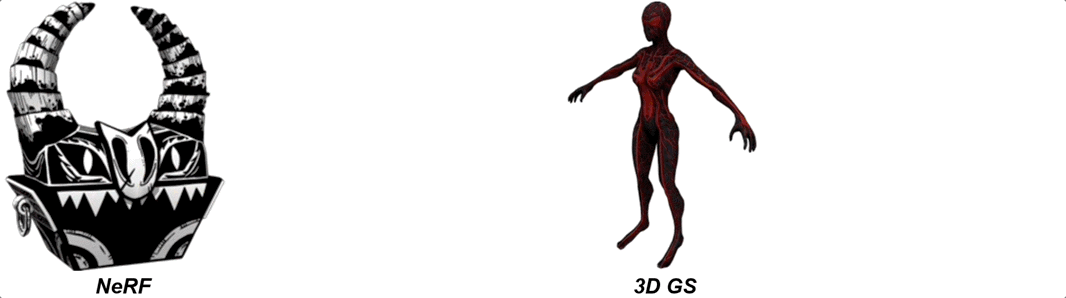
NeRF、3D Gaussian Splatting生成的三维重建图像Mesh效果如下:
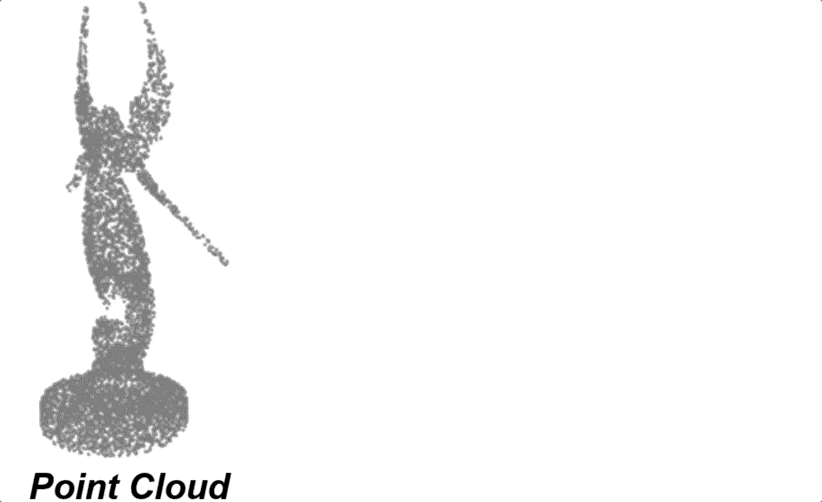
点云造出精细Mesh:
Dense Mesh基础上生成也可以:

一张图,甚至文本描述就足够了:
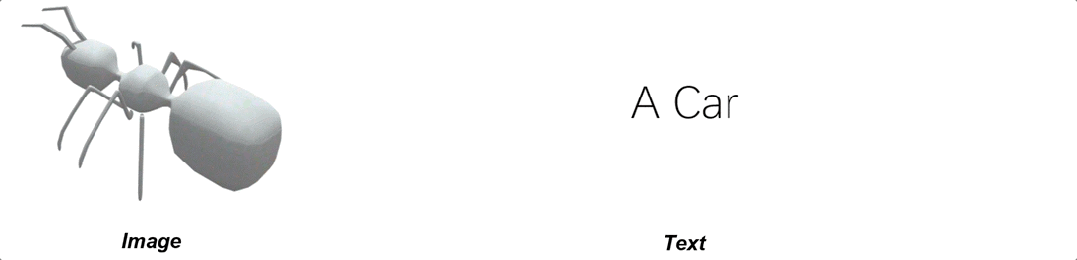
GitHub已揽星1.9k的MeshAnything项目上新了V2版本,由来自南洋理工大学、清华大学、帝国理工学院、西湖大学等研究人员完成。

MeshAnything V2相比V1,使用了最新提出的Adjacent Mesh Tokenization(AMT)算法,将最大可生成面数从800提升到了1600。
相比之前的Mesh tokenization方法,AMT平均只需要一半长度的token sequence即可表达同一个Mesh。
这项研究一经发布也迅速得到不少网友关注。

那么,MeshAnything究竟是一种怎样的方法?MeshAnything V2做了哪些改进?
值得注意的是,虽然AI很早就能够生成Mesh了,但这与上面所展示的生成人造Mesh有着巨大区别。
团队表示,所有之前方法,例如Marching Cubes和Get3D,生成的Mesh都是面片非常稠密的Mesh,面片数往往是人造Mesh的数百倍,几乎不可能应用于游戏,电影等实际3D工业。
并且由于它们的面片结构不符合人类直觉,3D建模师很难再对其进行细致的加工。
如下图所示,这一问题没法简单地依靠remesh来解决,在不影响效果的前提下,remesh方法虽然仅仅能够小幅度地减少面片:

而上述问题直接影响了3D研究应用于工业界。
3D工业界的pipeline几乎全以人造Mesh作为3D表征,即使3D研究领域能产出精度极高的NeRF或者3D Gaussian,但没法将它们转化为工业界能应用的Mesh的话,应用将十分受限。
因此,之前研究团队提出了MeshAnything,旨在实现高度可控的人造Mesh生成。

MeshAnything是一个自回归的transformer,其将Mesh的每个面片视作token,整个Mesh被视作token序列,接着像大语言模型一样,一个token一个token地生成,最终生成出整个Mesh。
MeshAnything运用精妙的condition设计,其将点云作为condition来实现高度可控的人造Mesh生成:

MeshAnything以点云为condition的设计让其可以与诸多3D扫描,3D重建,3D生成的方法结合。
这些种类繁多的方法最终得到的3D表示虽然多样,但总能从中采样到点云,从而输入到MeshAnything中转为人造Mesh,帮助这些能输出3D模型的工作运用到实际3D工业中。
另外,这种设计还大大降低了MeshAnything的训练难度,提高了效果。因为点云提供了精细的3D形状信息,MeshAnything不需要去学习复杂的3D形状分布,只需要学习如何搭建出符合给定点云的人造Mesh。
MeshAnything V2在V1版本的基础上大幅度提高了性能,并将最大可生成面数800提升到了1600。
其主要提升来源于其新提出的Adjacent Mesh Tokenization(AMT)算法。
相比之前的Mesh tokenization方法,AMT平均只需要一半长度的token sequence即可表达同一个Mesh。
由于transformer的计算是n^2复杂度,一半长度的token sequence意味着降低了4倍的attention计算量。并且AMT得到的token sequence更加紧凑,结构更好,更有利于transformer的学习。
AMT是通过尽可能地仅仅用一个vertex来表达一个一个面片来实现上述进步的:
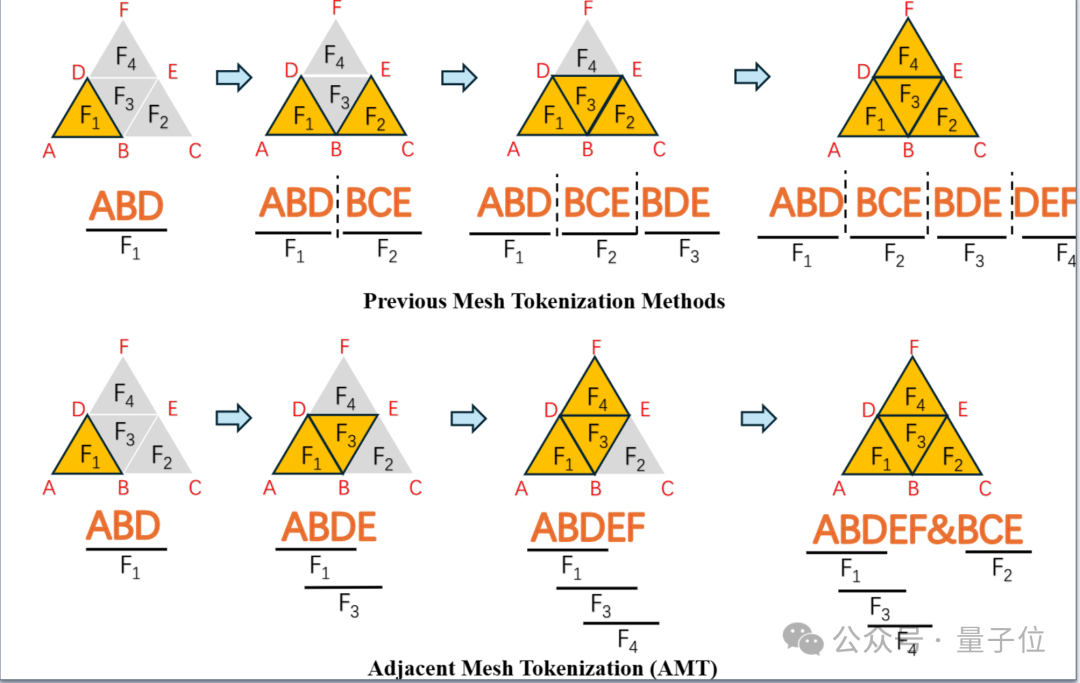
上图清晰地表达出了AMT的运作过程,其通过优先表达相邻的面片来用1个vertex表达一个面片。当不存在相邻的没表达过的面片,AMT添加一个特殊token “&”来标识这一情况并重新开始。
在AMT的帮助下,V2在性能和效率上大幅超过之前的方法,实现了高质量的人造Mesh生成。
在训练数据上,MeshAnything使用ShapeNet和Objaverse中的人造Mesh,将这些Mesh展开成token sequence之后使用cross-entropy loss监督。
V1和V2都仅仅使用了350m的transformer架构,100K的训练数据就得到了以上结果,表明该方向还有非常大scale up潜力。
更多结果如下:




【开源免费】LGM是一个AI建模的项目,它可以将你上传的平面图片,变成一个3D的模型。
项目地址:https://github.com/3DTopia/LGM?tab=readme-ov-file
在线使用:https://replicate.com/camenduru/lgm
