# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
随着大模型的快速发展,指令调优在提升模型性能和泛化能力方面发挥着至关重要的作用。
然而,对于指令调优数据集的数据评估和选择方法尚未形成统一的体系,且缺乏全面深入的综述。
为了填补这一空白,腾讯优图实验室发布一篇完整综述进行梳理。
长度超过了万字,涉及的文献多达400余篇。

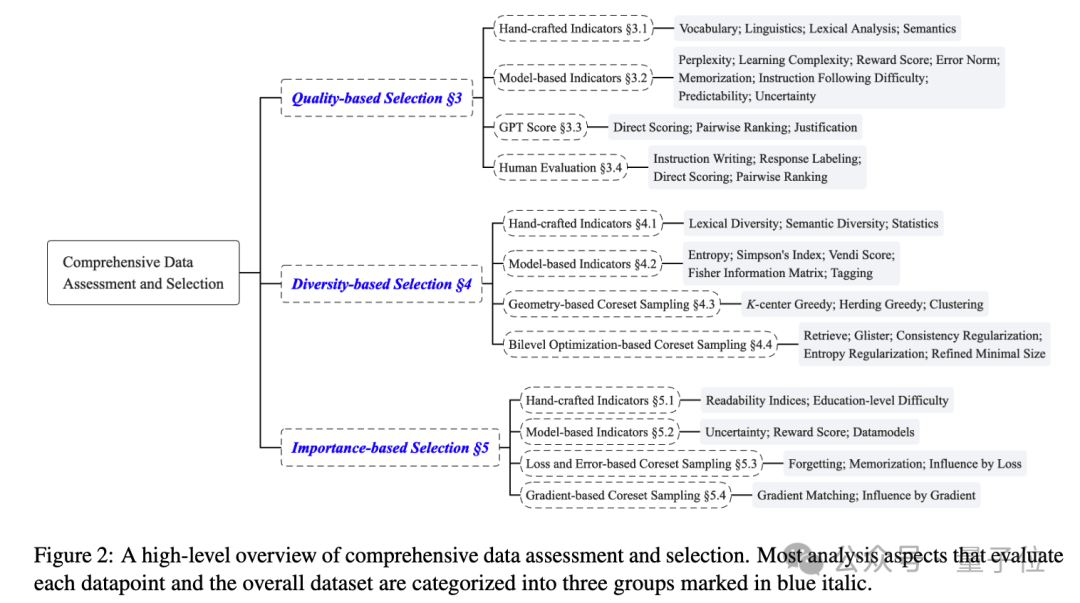
这项研究涵盖了质量、多样性和重要性三个主要方面的数据评估和选择方法,对每个方面都进行了详细的分类和阐述。
同时,作者还关注了该领域的最新进展和趋势,包括一些新兴的技术和方法,如利用GPT等强大语言模型进行数据评分、基于双层优化的Coreset采样等。
LLMs的发展目标是解锁对自然语言处理(NLP)任务的泛化能力,指令调优在其中发挥重要作用,而数据质量对指令调优效果至关重要。
作者深入研究了各种指令调优数据集的数据评估和选择方法,从质量、多样性和重要性三个方面进行了分类和阐述。
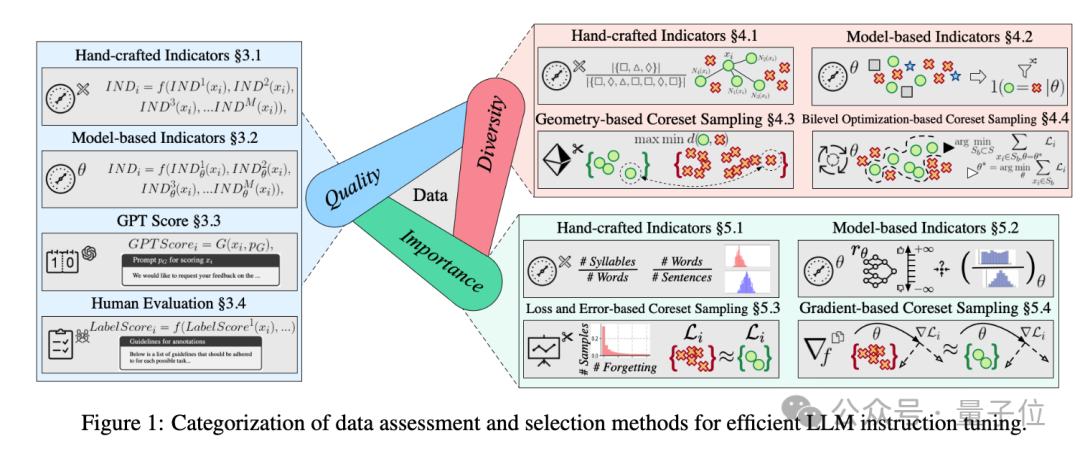
“质量”主要指指令响应数据点的完整性、准确性和合理性,现有方法通常制定统一的评分机制来综合考虑这些维度。
针对数据集的质量,作者主要总结出了四种测试方法:
这里的多样性,是指指令数据集的个体多样性(如词汇和语义丰富度)和整体多样性(如数据分布),选择具有多样性的数据集可增强模型的泛化能力。
作者同样是总结了四种测试数据集多样性的方式。
重要性是指样本对模型训练的必要性,与模型任务相关,同时也关乎性能。易样本可能不需要额外调优,而难样本对模型训练至关重要。
对重要性的评估,主要有这样几种指标和方法:
作者发现,数据选择的有效性与模型在基准测试上的性能报告之间存在差距,原因包括评估损失与基准性能相关性不强、测试集污染等。
未来需要构建专门的基准来评估指令调优模型和所选数据点,并解耦数据选择和模型评估以排除数据污染的影响。
目前也没有统一标准来区分“好”“坏”指令,现有质量测量方法具有特定任务导向性且缺乏解释性,未来需要更统一、通用的定义和提高选择管道的可解释性,以适应不同下游任务的需求。
随着数据集的扩大,确定最佳选择比例也变得困难,原因包括噪声增加、过拟合和遗忘问题,建议通过质量测量方案、强调多样性和考虑与预训练数据的相似性来确定最佳选择比例,并优化数据评估和选择的可扩展性pipeline。
除了数据集,大模型本身的规模也在增大,数据评估和选择的成本效率降低,需要发展高效的代理模型,同时重新思考传统机器学习技术,如优化技巧和降维方法。
文章来源于“量子位”,作者“腾讯优图实验室”




【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
