# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
简单来说,领域模型 / 专家模型 就是在某一个专业领域性能特别好的模型,可能包括法律、医学、教育、role-play 等等。一般来说,领域模型比较重要的环节是 RAG,我们需要有一个特别高精的检索库,来辅助模型做一些专业的回答。这也就是说,做好 sft 和 ppo 似乎就可以了?
其实,这么想也基本正确,因为大部分领域模型所处理的任务场景,80% 都是模型的通用能力能 cover 的。以法律大模型为例,“判断是否是法律问题、总结律师发言重点、提取法官判决结果等等?” 类似的问题基本任何一个开源模型 + 几百条 sft 语料都能做的不错。
然而,领域模型的要求的准确率是远远大于 80% 的,而剩下的那 20% case 恰恰又是 sft 无论如何也做不好的。
“张三犯抢劫罪,张三买了苹果,张三杀了个人,张三睡觉,张三挪用公款,……,张三寻衅滋事李四。” 请概括张三触犯的法条?
以上面这个 case 为例,我们的通用模型大概率是会把“寻衅滋事”当做一个动作来看待,而不会把它视为一个违法行为,进而导致概括错误。可如果连这种简单 case 都调用 RAG 的话,那么显然成本高的有些过分了,何况这种情况还很难检索准确。
因此,post-pretrain 的目的便是让模型尽可能的去认识这个领域的专有名词,知道某些词汇就是这个领域的专有名词,进而让 attention 给到这些 token 一些更大的权重。法律模型需要见过所有的法律法规、医学模型需要见过所有的症状和药品名词,以此类推。
然而,大量的 paper 已经证明:续训模型的过程,大概率是“学了新的,忘了旧的”的过程。这也就是说,你提高模型在领域知识上的认知能力的同时,往往它也在丢失通用能力。前面也说了,我们有 80% 的场景时需要通用能力来覆盖的。因此,我们更加靠谱的目标是:在 post-train 阶段学习领域知识的同时,尽最大可能去避免模型的通用能力损失。(贪不了一点,大模型有太多的工作需要 trade-off)
如果你的 base_model 是自己训的,那后面不用看了。使用退火前的 checkpoint,沿用 pretrain 阶段的训练数据,使用类似于“91开”的数据配比去混合领域数据续训,训完再退火,然后这个工作就完成了!
emm,还往下读,应该都是没有自己 model 的同学了,咱们继续探讨!
pretrain 最重要的几个东西:数据,学习率,优化器!
目前,大家基本都默认使用如下三个步骤进行 pretrain:
(llama 和 面壁 都明确提出了退火阶段带来的能力提升)

llama 退火结论
面壁智能退火结论
基础知识我们回顾完了,现在开始准备数据。说句丑话,如果你没有领域模型的高精数据,也没打算去爬数据和洗数据,那神仙难救,个人建议换个方向去研究 。
好,我们已经有了领域高精数据。那 common 数据和数据配比怎么搞呢?
先说数据质量,post-pretrain 不用那么精细,我们的目标是通用能力不下降,而不是通用能力大幅度提升。qwen2 的技术报告明确指出,训了 12T 数据的模型与训了 7T 数据的模型,基本没有提升。也就说,额外的 5T 数据仅仅是因为质量稍有下降(论文里说卡的阈值更小),就没有带来任何收益。
我们大概率拿不到比 qwen2、llama3 的 pretrain 阶段质量更好的数据,因此我个人觉着不要太执着于做一份特别干净的 pretrain 数据了,你怎么洗数据都很难带来明显收益。
这里推荐几个开源数据集,感觉基本够用了!
英文 Fineweb:https://huggingface.co/datasets/HuggingFaceFW/fineweb-edu
英文 pile:https://huggingface.co/datasets/EleutherAI/pile
中文 SkyPile:https://huggingface.co/datasets/Skywork/SkyPile-150B
中文 CCI:https://huggingface.co/datasets/BAAI/CCI2-Data
代码 the-stack-v2:https://huggingface.co/datasets/bigcode/the-stack-v2-train-smol-ids
再说数据配比,llama3 和面壁智能明确给出了他们的数据配比,基本就是一个结论:代码很重要,英文很重要(即使是中文模型也应该保证英文语料的比例,有些 paper 认为模型的 general knowledge 基本来自于英文语料,中文更多的是对齐作用)。
这里给出不权威的个人建议:中英五五开,代码不能少,领域占比看算力。(根据个人需求和个人喜好,可以提高英文比例,如果有质量较好的 math 数据或逻辑数据,也添加一些)
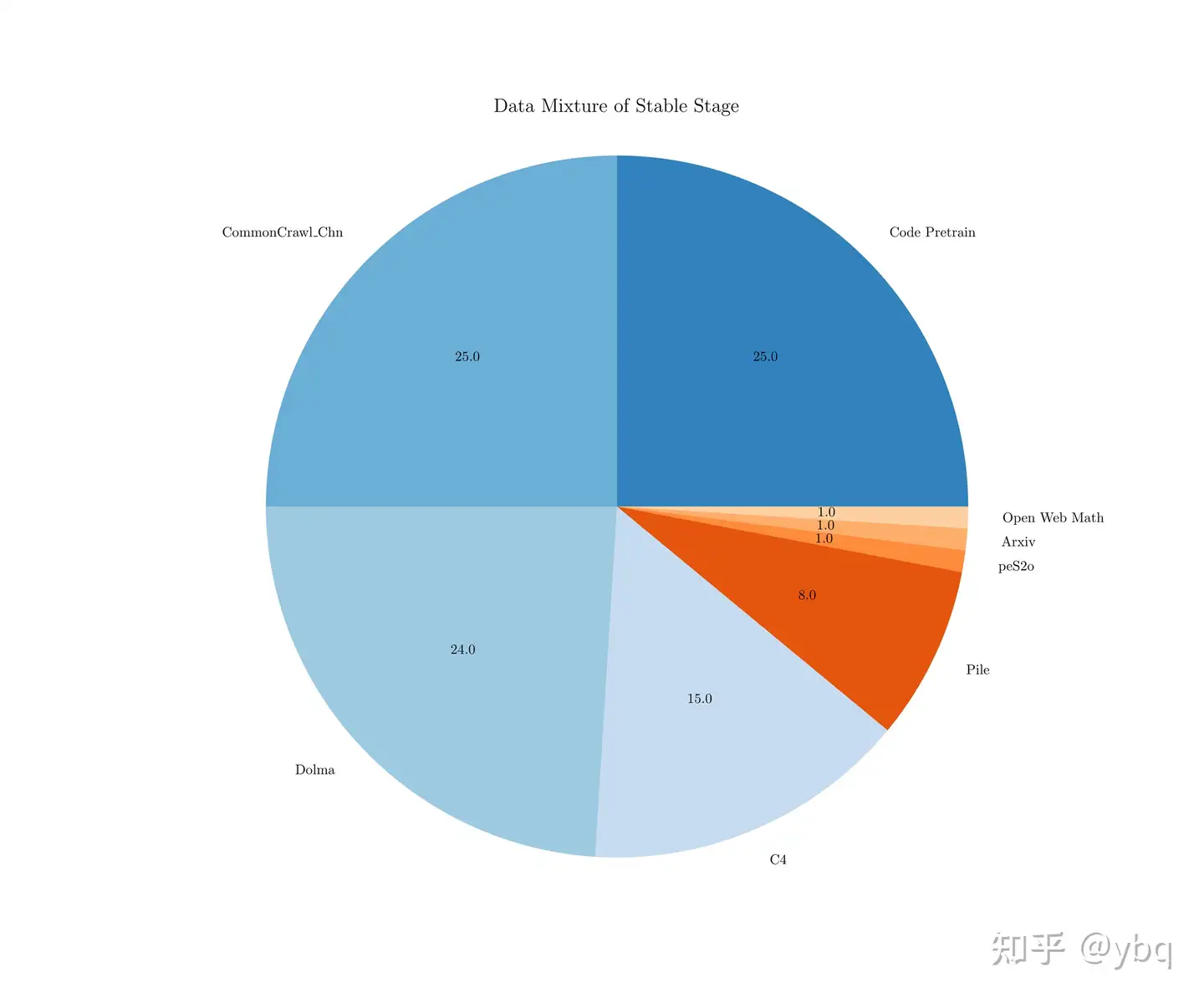
面壁智能数据配比

llama数据配比
果粉的话,建议直接使用 中文 + 领域 + 下面的数据配比,相信 apple!
苹果论文:https://arxiv.org/pdf/2406.11794v3
苹果训练数据:
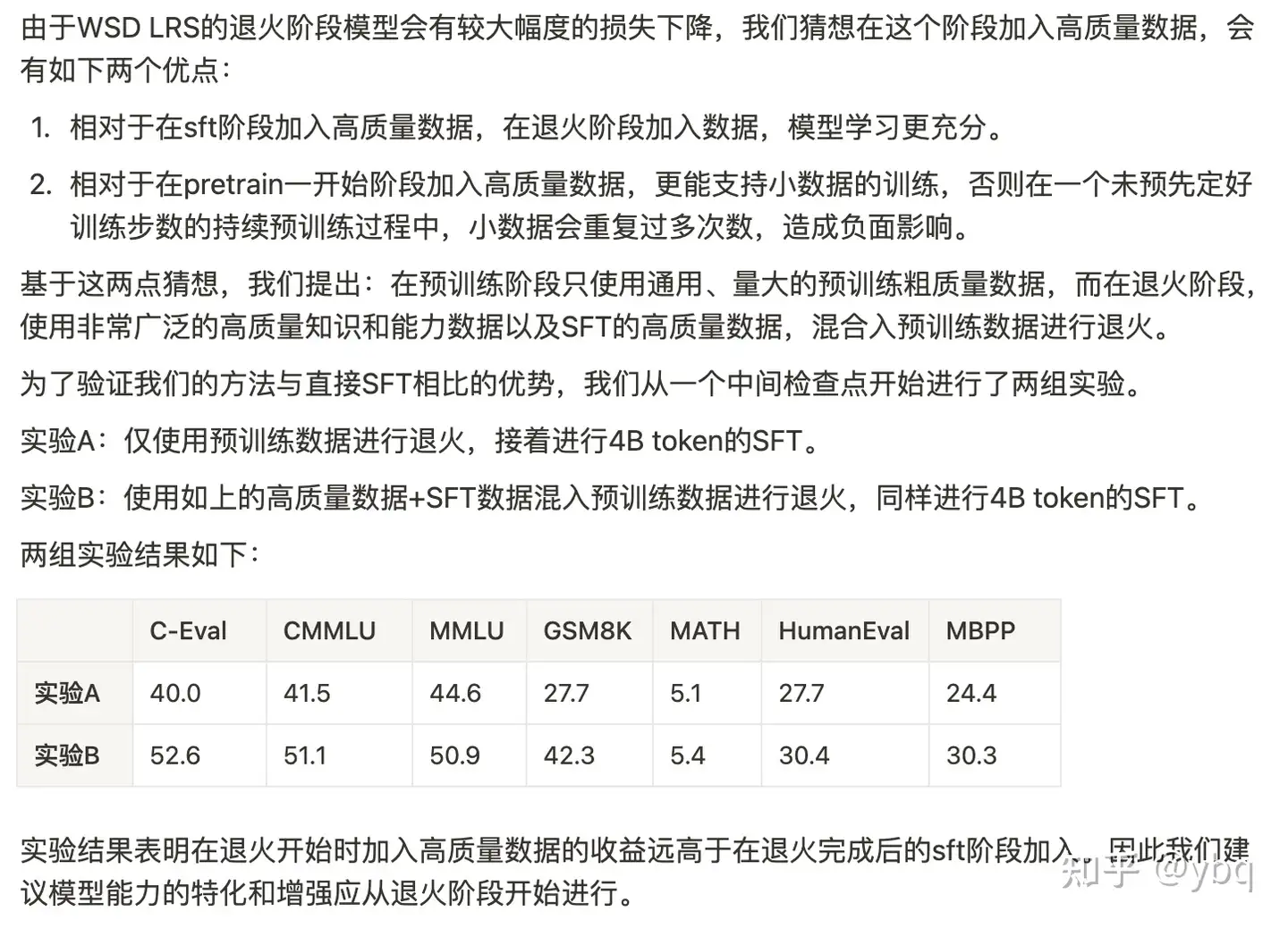
就一句话:做 domain post-pretrain 不看 channel loss,你不如别开 tensorboard。
你就算随机拉一个数据集过来训,大概率也是 loss 缓慢下降的现象,你能得到啥信息呢?你难道要等训了一周,才去做实验验证数据配比和学习率配置吗?
channel loss:不同数据 channel 各自的 loss。也就是说假设 1 个 batch 有 100 条数据:40条 en,30 条 cn, 20条 code, 10 条 domain,那么就绘制四条不同 channel 的 loss 曲线和一条总的 total loss 曲线。
(题外话,我本来以为 channel_loss 需要在 dataloader 侧做很复杂的操作才能实现,后来经大佬同事指点,发现只要给每条数据加一个 channel 字段,再通过 all_gather_object 去通讯下就行,代码如下)
channel_loss = {}
for step, batch in enumerate(train_dataloader):
batch = to_device(batch, device)
channel = batch['channel'][0]
del batch['channel']
outputs = model(**batch)
loss = outputs.loss
# Update channel loss
if channel in channel_loss:
channel_loss[channel][0] += loss.item()
channel_loss[channel][1] += 1
else:
channel_loss[channel] = [loss.item(), 1]
all_channel_loss = [None for _ in range(world_size)]
torch.distributed.all_gather_object(all_channel_loss, channel_loss)
merged_channel_loss = {}
for lst in all_channel_loss:
for k, v in lst.items():
if k in merged_channel_loss:
merged_channel_loss[k][0] += v[0]
merged_channel_loss[k][1] += v[1]
else:
merged_channel_loss[k] = [v[0], v[1]]
for k,v in merged_channel_loss.items():
avg_loss = v[0] / v[1] if v[1] != 0 else 0.0
print_rank_0("The Channel {} loss is {}".format(k, avg_loss), args.global_rank)
# Log channel loss to TensorBoard
if dist.get_rank() == 0:
writer.add_scalar(f'Loss/channel_{k}', avg_loss, epoch * num_batches + step)
channel_loss = {}
前面提到过,pretrain 阶段有 warmup,那么 post-pretrain 当然也要有了,原因也很简单啊。我们用的开源模型并没有提供给我们 checkpoint 对应的“优化器参数”,我们无法获得以前积攒的动量啊。
continue pretrain:https://arxiv.org/pdf/2406.01375
这篇论文讨论了“post-pretrain 模型时,warmup 应该使用的数据比例”。同时它也指出,warmup 在训练充分的时候是不太重要的。但因为我们无法判断模型是不是训练充分了,所以还是老老实实的做个 warmup 吧。
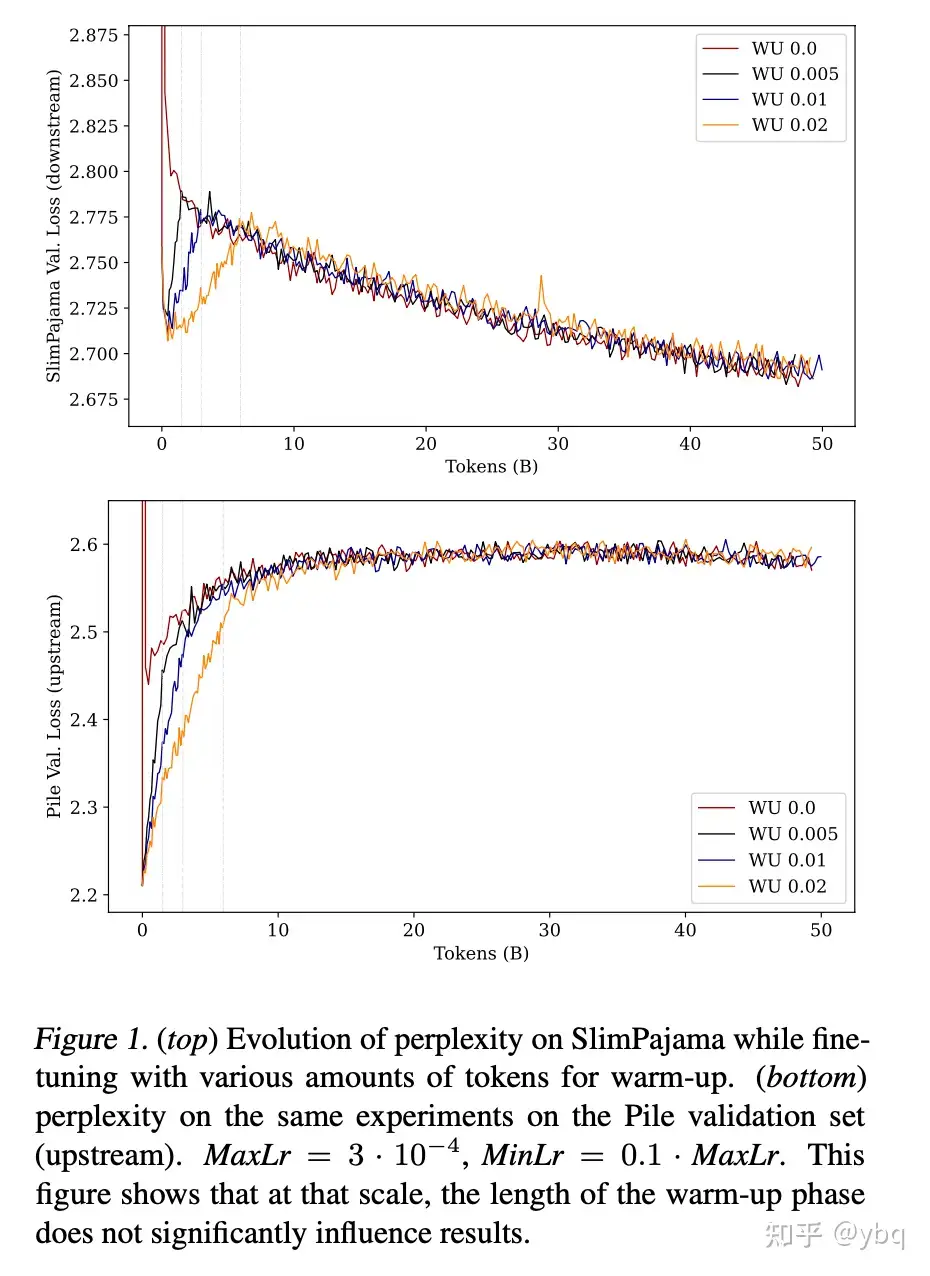
warmup 比例
敲定 warmup 的数据比例后,选择一个顺眼的学习率和数据配比,就去开始训练和观察 channel loss 吧,在最理想情况下,我们期待得到一个这样的曲线:
结合 loss 曲线,我们再回过头来谈谈数据配比:post-pretrain 阶段最好的数据配比,就是沿用 pretrain 阶段的数据配比,很可惜,我们不可能获取到 qwen、llama 的 pretrain数据。因此,我们也别纠结数据去重了,大概率我们使用的 common 数据是人家已经训过的,我们尽可能去找质量最高的 common 数据喂给模型就可以了。
不过从 channel loss 上,我们大概率能观察和反推一些东西:
综上,通过观察 loss,多做几组实验,基本能试探出哪个数据配比和哪个开源数据最适合拿来 post-pretrain。
真的勇士,就应该去研究 sacling law,这也就是除了llama、qwen,我还特别推崇“面壁智能”的原因,它似乎是国内唯一一家不执着于size,而是执着于“sacaling law”的公司。
这篇 domain scaling law 的论文明确指出“domain能力“和”general 能力“是相互冲突的,也就回归到了我一开始说的:我们的目标不是提高通用能力,而是去损失尽量少的通用能力。
D-CPT:https://arxiv.org/pdf/2406.0137
D-CPT
这篇论文的结论都是比较 make sense 的:
文章再多的内容我就不谈了,感兴趣的读者自己拜读一下即可,scaling law 的文章都相对晦涩一些,我还没有完全读懂,不敢班门弄斧。我引用这篇 sacaling law 论文的主要原因是,一是讴歌一下做 scaling law 的大佬们,二是想表达“学习率真的很重要”这一观点,不要因为大家都在强调数据质量的重要性,就忽略了炼丹的老本行。
这里引用我的大佬同事跟我说过的一句话:“你把学习率设成 0 ,那是不是模型怎么训效果都不下降。那根据夹逼准则,你只要找到一个好学习率,你数据再烂也能训出一个通用能力只下降一丢丢的模型。”
退火本身怎么做,我就不多说了,小学习率 + 高精数据。基本每一个开源模型的技术报告,都会详细指出自己的退火数据配比。
我在这里提到退火,是想强调几个观点:
退火直接能提高刷榜能力!我们 post-pretrain 的模型,都是做过退火的,也就是说这个模型就像是刚高考完的高三学生,考试能力是人生巅峰!现在不管教他什么知识,他的考试能力都会下降。不管你怎么训,模型的打榜能力基本都会下降,所以大家不要太过焦虑这个现象。但做 post-pretrain 之前,一定要构建好 domain 能力的评估集,证明自己的 domain 能力在提升。要不然 common 也降、domain 也降,是钱多闲得慌吗?
面壁技术报告:/shengdinghu.notion.site
Qwen2技术报告:Qwen2 Technical Report
llama3技术报告:://ai.meta.com/research/pu
文章来源于“知乎”,作者“ybq”



【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
