# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
论文的审稿模式想必大家都不会陌生,一篇论文除了分配多个评审,最后还将由PC综合评估各位审稿人的reviews撰写meta-review。
最近,来自Meta的研究团队将这一模式引进到大模型的对齐训练中。模型同时扮演 执行者(actor)、评判者(judge)和元评判者(meta-judge) 三种角色。执行者生成回复,评判者评估生成回复的质量并打分,元评判者则检查评判者的质量,为评判者提供必要的训练反馈。
通过这种方式获得大量回复偏好对,无需人工标注数据,进一步训练对齐模型,显著提高了模型的判断和遵循指令的能力。
论文标题:
META-REWARDING LANGUAGE MODELS: Self-Improving Alignment with LLM-as-a-Meta-Judge
论文链接:
https://arxiv.org/pdf/2407.19594

本文假设没有任何额外的人工监督数据,仅有一个初始的种子LLM。通过迭代自我对弈,模型同时扮演执行者(actor)、评判者(judge)和元评判者(meta-judge)三种角色。执行者生成回复,评判者评估生成的质量并打分,元评判者则比较评判者的质量,为其提供必要的训练反馈。
虽然最终的目标是训练执行者生成更优质的回复,但评判者评判是否准确也很重要。随着评判者能力的提升,执行者也能获得更好的反馈,从而不断进步。本文提出的 “元奖励机制(Meta-Rewarding)”旨在同时增强执行者和评判者的能力。迭代过程下图所示:
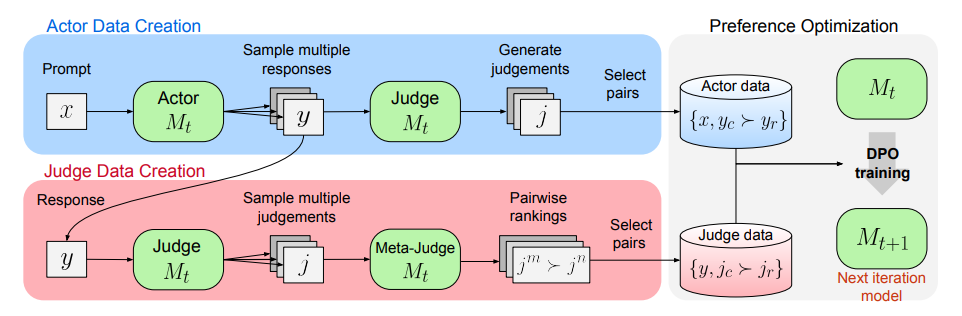
增强执行者和评判者的能力最重要的就是获取大量训练数据。因此每个迭代周期首先由执行者针对每个提示生成多个回复变体,评判者为每个回复打分,为训练执行者构建回复偏好对。
为了训练评判者构建评判偏好对,则选择一个回复,并让元评判者比较评判者针对该回复生成的两个评判变体,以确定哪个更好,这通过LLM作为元评判者的提示来实现,如下图所示:

一旦为执行者和评判者都收集了偏好数据,就通过DPO在数据集上进行偏好优化训练。
接下来详述每个部分数据集构建。
数据集创建过程主要包括三个步骤:





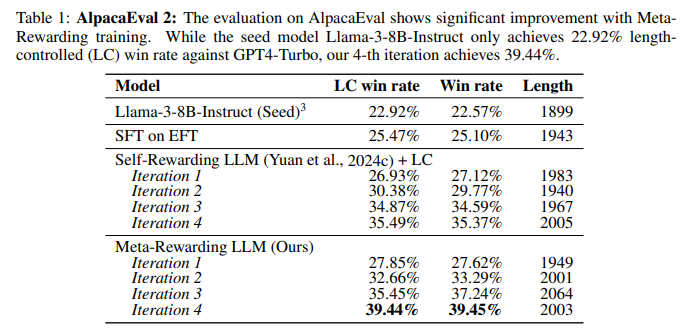
本文使用经过指令微调的 Llama-3-8B-Instruct 作为种子模型。再对种子模型利用[1]提供的评估微调数据集进行监督微调得到初始评判者。
在Meta-Rewarding迭代中,同样以[1]提供的20000个提示作为种子集,每次迭代抽取5000个提示,总共进行四次迭代:
由于Meta-Rewarding同时改善模型作为演员和评判者的表现,因此将测量两个方面。
作者采用了三个成熟的GPT4驱动自动评估基准从不同维度评估模型。AlpacaEval 2侧重于日常聊天场景,Arena-Hard则包含复杂与挑战性问题,MT-Bench评估多轮对话能力,覆盖8类问题。
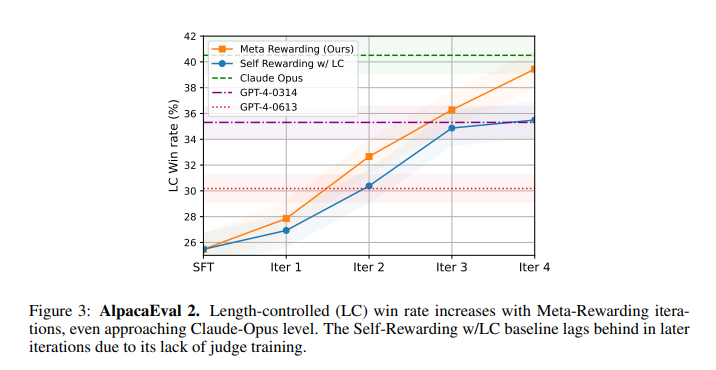
元评判者及长度控制机制对提升至关重要,在没有元评判者参与训练评判者的情况下,仅依赖自奖励基线与长度控制(LC)相结合,虽然能够带来一定程度的改进,但这种改进在训练的后期迭代中显得较为有限。如下表所示,随着训练迭代的进行,平均响应长度并未出现明显增长,这有力地证明了所采用的长度控制机制在控制输出长度方面的稳定性和有效性。
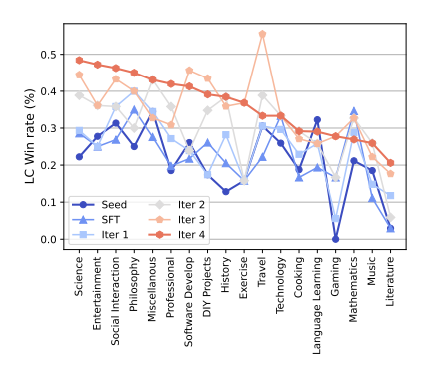
Meta-Rewarding几乎改进了所有指令类别,特别在知识密集型类别如科学、游戏、文学上表现突出(,但在旅行、数学等类别上改进较小。
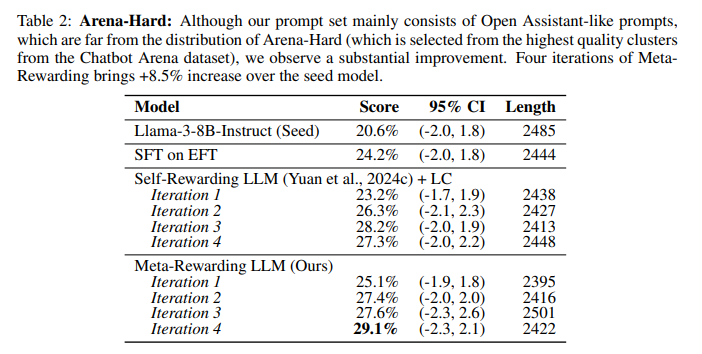
Meta-Rewarding 改进了复杂和困难问题的回答。 在应对复杂问题上,通过Arena-Hard评估,Meta-Rewarding持续提分,较种子模型提升显著(+8.5%)。
作者比较评判者的能力与人类评判和当前最强的判断模型 gpt-4-1106-preview 之间的相关性。还通过斯皮尔曼相关性分析,量化模型生成排名与Open Assistant数据集中的一致性。
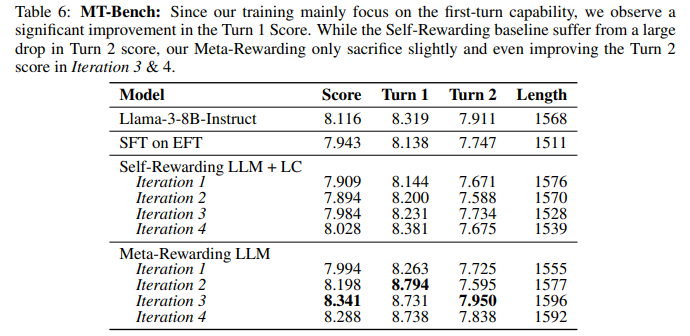
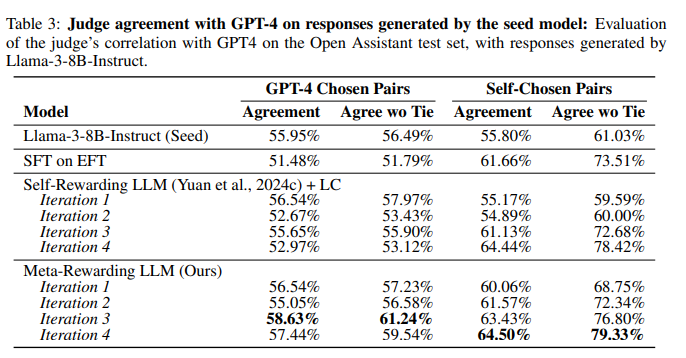
模型经Meta-Rewarding训练后,判断能力显著提升。下表显示,与自奖励基线相比,在两种评估设置中,Meta-Rewarding与GPT-4判断的相关性均大幅增强,尤其是无平局一致性指标提升显著。自选对设置中,迭代2时改进高达+12.34%,而GPT-4选择对设置中也超过+6%。这证明了Meta-Rewarding在提升模型判断能力上的有效性,使其更接近GPT-4的评估水平。
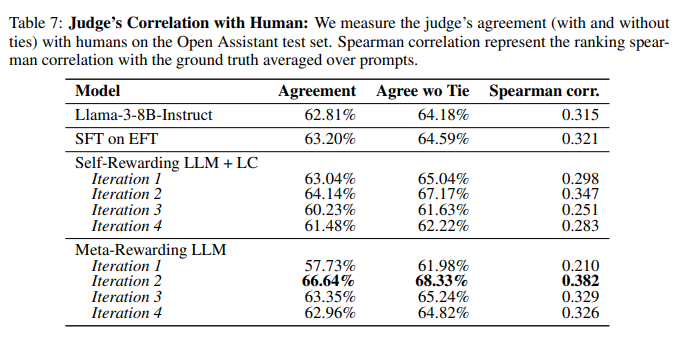
Meta-Rewarding 训练提高了与人类的判断相关性。 通过Open Assistant数据集验证,可以看到本文模型与人类排名的相关性显著增加。然而,随着训练深入,这一改进有所减缓,可能与响应分布变化有关。
本文利用元评判者分配元奖励,优化模型判断偏好,克服自奖励框架的训练限制。同时,引入长度控制技术,解决训练中的长度问题。即使没有额外的人类反馈,该方法也显著改善了 Llama-3-8B-Instruct,并超越了依赖于人类反馈的强基线 Self-Rewarding 和SPPO 。并且该模型的判断能力与人类及强大AI评判者(如GPT-4)高度相关。也许随着科技发展,无需人类反馈的模型超对齐将可能实现。
文章来源于“ 夕小瑶科技说”,作者“ 谢年年”




【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
