# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
高端的食材,往往只需要最朴素的烹饪方式;高端的提示词也一样,把Top-K写进来,一个专属于你的CoT-decoding解码策略应运而生!丝毫不要怀疑LLM的推理能力,在这个维度上,它比我们懂!
传统观点认为,要让语言模型进行复杂推理,必须通过精心设计的提示(prompts)来引导。然而,最新研究表明,这种观点可能需要重新审视。Google DeepMind的研究人员Xuezhi Wang和Denny Zhou在今年的论文中提出了一个令人兴奋的发现:语言模型本身就具备推理能力,只是这种能力被常规解码方法所掩盖。


长期以来,研究人员一直致力于开发各种提示技术,如few-shot或zero-shot思维链(Chain-of-Thought, CoT)提示,以增强语言模型的推理能力。这些方法虽然有效,但往往需要大量人工干预来设计和优化提示。Wang和Zhou的研究为这一领域带来了全新视角:语言模型是否能在没有任何提示的情况下进行有效推理?
研究结果令人惊讶:通过简单改变解码过程,预训练的语言模型就能展现出强大的推理能力。研究者发现,只要考虑解码过程中的top-k个候选词,而不是仅仅选择概率最高的词,就能发现隐藏在模型中的思维链路径。
这一发现具有重大意义。它不仅绕过了提示所带来的干扰因素,还让我们能够更准确地评估语言模型的内在推理能力。更重要的是,研究者观察到,当解码路径中存在思维链时,模型对最终答案的置信度会显著提高。这为从众多解码路径中筛选出最可靠的路径提供了有效方法。
在解释这个原理之前,我们再巩固一下top-k,无论你是编程还是写提示词,都用得上:
Top-k 是一种用于限制模型在生成文本或进行预测时的选择范围的策略,常用于自然语言处理(NLP)模型的解码阶段。它可以帮助控制模型生成的多样性和质量。
Top-k 策略是从模型预测的所有可能的下一个词的概率分布中,选取概率最高的 k 个候选词,然后从这 k 个词中随机选择一个进行生成。这样,模型不会考虑概率较低的词,从而避免生成一些不太合理的词语。
如何工作:
1. 生成概率分布:模型对每一个可能的下一个词给出一个概率值,形成一个概率分布。
2. 筛选Top-k词汇:根据这些概率,模型筛选出前 k 个概率最高的词。
3. 从中随机选取:在选出的 k 个词中,按照它们的相对概率进行随机选择。
作用:
- 减少不确定性:通过只考虑概率最高的 k 个词,降低了生成过程中出现不相关或不合适词汇的可能性。
- 提高生成质量:可以避免模型选择那些虽然有微小概率但在上下文中不合适的词。
- 调控多样性:k 的大小可以调控生成文本的多样性。k 值较大时,模型有更多选择,生成的内容更具多样性;k 值较小时,生成的内容则更确定、可控。
Wang和Zhou提出的方法,称为CoT-decoding,其核心思想是在解码过程中探索多个可能的路径,而不是简单地选择概率最高的词。具体来说,该方法包括以下步骤:
1. 在解码的第一步,考虑top-k个候选词,而不仅仅是概率最高的词。
2. 对于每个候选词,继续进行贪婪解码,生成完整的解码路径。
3. 分析每条路径,检查是否存在思维链模式。
4. 利用模型在生成最终答案时的置信度来评估每条路径的可靠性。
5. 选择置信度最高的路径作为最终输出。
这种方法的独特之处在于,它不需要任何外部提示或微调,完全依赖于模型的内在能力。通过探索多个解码路径,CoT-decoding能够发现常规贪婪解码所忽略的推理能力。这张图很好地展示了CoT-decoding的工作原理。
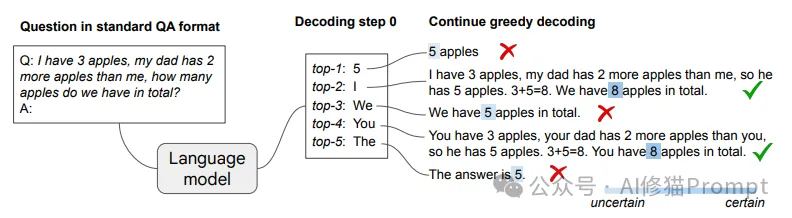
这张图清晰地展示了CoT-decoding的核心思想:
1. 输入:图的左侧显示了一个标准格式的问答输入- "Q:我有3个苹果,我爸爸比我多2个苹果,我们总共有多少个苹果? A:"
2. 解码过程:中间部分展示了语言模型在第一步解码时考虑的top-5个候选词。
3. 继续贪婪解码:右侧展示了从每个候选词开始继续贪婪解码的结果。
4. 思维链路径:图中用对勾标记的路径展示了正确的思维链推理过程,得出了正确答案8个苹果。
5. 置信度:底部的柱状图显示模型对不同路径答案的置信度,正确的思维链路径显示出最高的置信度。
这张图有力地说明了CoT-decoding如何通过探索多个解码路径,发现隐藏在模型中的正确推理能力。它还展示了如何利用模型的置信度来识别最可靠的推理路径。
重点来了:在你的提示词中你可以写下面这句,论文中并没有提到这一点,但我告诉你,你可以直白的写出来:
Generate the top-k unique initial responses (k=n).
研究者在多个推理任务上进行了广泛的实验,结果令人振奋。以下是一些关键发现:
1. 在GSM8K(小学数学问题集)上,使用CoT-decoding的PaLM-2 Large模型达到了63.2%的准确率,而传统贪婪解码仅为34.8%。这一性能甚至接近于使用指令微调的模型(67.8%)。
2. 在年份奇偶性判断任务中,CoT-decoding使PaLM-2 Large模型的准确率从57%提升到了95%。

3. 对于Mistral-7B模型,在GSM8K任务上,CoT-decoding将准确率从9.9%提升到了25.1%。
4. 即使对于已经经过指令微调的模型,CoT-decoding仍能带来显著改进。例如,在MultiArith任务上,Mistral-7B指令微调模型的准确率从37.8%提升到了66.5%。
这些结果清楚地表明,CoT-decoding能够有效激发语言模型的内在推理能力,在多种任务和模型上都带来了显著的性能提升。研究者用下面这张图展示了CoT-decoding在两个不同任务上的详细工作过程:
苹果计数问题:
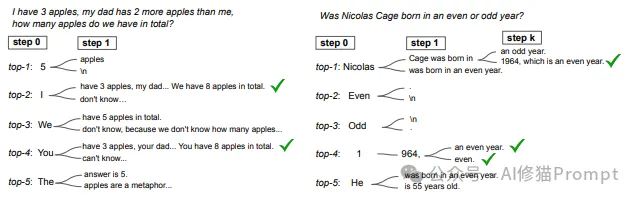
左侧显示了模型在step 0和step 1两个解码步骤的top-5候选词。
我们可以看到,正确的思维链路径(标记为✓)出现在top-2和top-4的位置,而不是top-1。
这些正确路径清晰地展示了完整的推理过程,得出正确答案8个苹果。
Nicolas Cage出生年份奇偶性问题:
右侧展示了模型在处理这个问题时的解码过程。
有趣的是,正确的推理路径出现在step k(后续步骤),模型首先确定了具体的出生年份1964,然后推断这是偶数年。
这个例子说明,有时正确的推理可能需要多个解码步骤才能完成。
这张图有力地证明了CoT-decoding的几个关键特点:
多样性探索:通过考虑多个候选词,方法能够发现隐藏的正确推理路径。
跨步骤推理:正确的推理可能需要在多个解码步骤中逐步展开。
任务适应性:CoT-decoding在不同类型的问题上都表现出色,从简单的数学计算到更复杂的常识推理。
错误路径识别:图中还显示了一些错误的推理路径,这有助于我们理解模型可能犯错的方式。
与现有方法的比较
CoT-decoding与现有的推理增强方法有何不同?研究者进行了详细的对比:
1. 与传统提示方法相比:CoT-decoding完全不依赖外部提示,避免了提示设计的复杂性和潜在偏差。
2. 与指令微调相比:CoT-decoding不需要额外的训练数据和计算资源,可以直接应用于预训练模型。
3. 与其他解码方法相比:温度采样、top-k采样等方法在没有CoT提示的情况下效果不佳,而CoT-decoding能有效找到隐藏的推理路径。
4. 与自一致性方法相比:在没有CoT提示的情况下,自一致性方法效果有限,而CoT-decoding通过显式鼓励第一步解码的多样性,能更好地发现推理路径。
这些比较凸显了CoT-decoding的独特优势:它能在不增加任何外部知识或训练的情况下,有效激发模型的内在推理能力。
跨模型性能比较
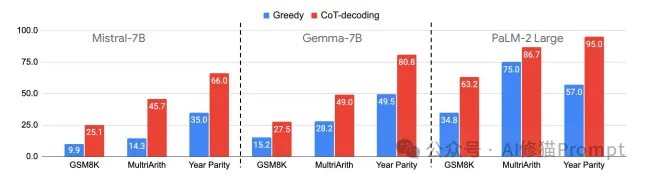
上图展示了CoT-decoding在Mistral-7B、Gemma-7B和PaLM-2 Large三个模型上的表现:
一致的性能提升:在所有模型和任务上,CoT-decoding都显著优于贪婪解码。
任务适应性:
GSM8K(数学推理):CoT-decoding带来了2-3倍的性能提升。
MultiArith(多步算术):性能提升更为显著,特别是在Mistral-7B上。
Year Parity(常识推理):展现了最大的性能飞跃,如Mistral-7B从35%提升到66%。
模型间差异:
PaLM-2 Large总体表现最佳,但CoT-decoding在较小模型上带来的相对提升更大。
Gemma-7B在Year Parity任务上表现出色,接近PaLM-2 Large的水平。
模型规模对CoT-decoding的影响
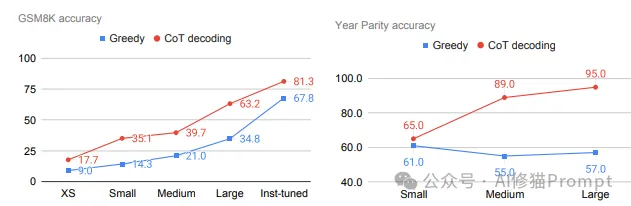
上图深入分析了CoT-decoding在不同规模的PaLM-2模型上的表现:
GSM8K任务:
CoT-decoding在所有规模上都优于贪婪解码。
性能差距随模型规模增大而扩大,在Large模型上达到最大。
即使是经过指令微调的模型,CoT-decoding仍带来显著提升。
Year Parity任务:
CoT-decoding的优势更加明显,特别是在较大规模模型上。
在Large模型上,CoT-decoding几乎达到了完美准确率(95%)。
有趣的是,贪婪解码在模型规模增加时性能反而略有下降,这突显了CoT-decoding的重要性。
与其他方法的综合比较

上图提供了CoT-decoding与其他方法的详细对比:
无提示方法:
CoT-decoding(最大路径和聚合路径)显著优于其他无提示方法。
在PaLM-2 L上,CoT-decoding将准确率从34.8%提升到64.1%。
结合提示的方法:
CoT-decoding与零样本CoT提示结合,进一步提升了性能。
在Mistral-7B上,这种组合将准确率从17.5%提升到48.4%。
计算复杂度:
CoT-decoding的计算复杂度为O(k),与自一致性方法相同,但性能更优。
这表明CoT-decoding在性能和效率之间取得了很好的平衡。
我们可以看到:
普适性:CoT-decoding在不同模型、任务和规模上都展现出强大的性能提升能力。
与模型规模的协同效应:CoT-decoding似乎能更好地激发大规模模型的潜力。
补充效应:CoT-decoding不仅可以单独使用,还能与现有的提示技术结合,进一步提升性能。
效率考虑:尽管CoT-decoding需要额外的计算,但其带来的性能提升足以证明其价值。
这些结果充分证明了CoT-decoding作为一种新型解码策略的强大潜力。它不仅显著提升了模型的推理能力,还为我们理解和改进语言模型提供了新的视角。未来的研究可能会进一步探索如何优化CoT-decoding,以在更广泛的任务和模型上实现更好的性能。
对于有兴趣实现CoT-decoding的开发者,以下是一些关键的技术细节:
1. 输入格式:使用标准的问答格式,如"Q:[问题]\nA:"。
2. 解码参数:对于PaLM-2模型,使用256的输入序列长度和128的最大解码步数。对于Mistral模型,根据是否经过指令微调,生成200-400个新token。
3. 答案识别:对于数学问题,提取最后的数字作为答案。对于其他任务,可以使用"So the answer is"提示来定位答案。
4. 路径聚合:计算每条路径上答案的置信度(Δ值),选择Δ值之和最高的答案作为最终输出。
5. 过滤无效响应:删除空响应、重复响应或以问号结尾的响应。
通过这些技术细节,开发者可以在自己的项目中实现CoT-decoding,从而充分发挥语言模型的推理潜力。
模型的内在推理能力
通过CoT-decoding,研究者能够更深入地了解语言模型的内在推理能力。一些关键发现包括:
1. 模型能够生成正确的思维链路径的能力与任务难度密切相关。对于简单任务,正确的思维链更容易被找到。
2. 当解决方案涉及1-2步知识操作时,模型通常能生成正确的思维链路径。但当步骤增加到3步或更多时,模型开始纠结挣扎。
3. 模型的推理能力似乎与其预训练分布高度相关。对于更合成或不自然的任务,找到正确的思维链路径变得更加困难。
4. CoT-decoding还揭示了模型在推理过程中的一些固有弱点。例如,在复杂任务中,模型可能会失去对状态的准确跟踪,或者在数学计算中没有遵循正确的运算顺序。
这些发现不仅帮助我们更好地理解语言模型的能力和限制,还为写出高级的提示词给出一些启发。
CoT-decoding的发现为语言模型的应用开辟了新的可能性:
1. 增强现有AI助手:通过集成CoT-decoding,现有的AI助手可以在复杂推理任务上表现得更好,无需额外的提示工程。
2. 改进模型评估:CoT-decoding提供了一种新的方法来评估语言模型的内在推理能力,可能lead to更准确的模型比较。
3. 指导模型训练:通过分析CoT-decoding揭示的模型弱点,研究者可以设计更有针对性的训练策略。
4. 降低部署成本:由于CoT-decoding不需要额外的微调或提示设计,它可以降低大型语言模型在实际应用中的部署成本。
这些潜在应用表明,CoT-decoding不仅是一个理论突破,还有望在实际AI系统中产生深远影响。
局限性
尽管CoT-decoding展现了令人兴奋的结果,研究者也坦诚指出了该方法的一些局限性:
1. 计算成本:探索多个解码路径会增加计算成本,这在大规模应用中可能成为一个挑战。
2. 开放性问题:对于更开放性的问题,使用top-2 token的概率差作为置信度指标可能不够精确。
3. 分支策略:目前的方法只在第一个token处进行分支,未来可以探索在解码过程中的任意位置进行分支。
4. 模型依赖:不同模型可能对CoT-decoding的反应不同,需要更多研究来了解这种方法的普适性。
Wang和Zhou的研究对我们理解语言模型的推理能力提出了挑战。它表明,预训练的语言模型已经具备了强大的推理能力,只是这种能力被常规解码方法所掩盖。CoT-decoding为我们提供了一把钥匙,打开了语言模型推理能力的黑匣子。
对于正在开发AI产品的Prompt工程师来说,这项研究带来了几个重要启示:
1. 重新评估提示的角色:虽然提示仍然重要,但我们应该更多地关注如何激发模型的内在能力,而不是过度依赖外部指导。
2. 关注解码策略:在优化模型性能时,不仅要考虑模型架构和训练方法,还应该重视解码策略的选择和优化。
3. 平衡性能与效率:在实际应用中,需要在探索更多解码路径带来的性能提升和计算成本之间找到平衡点。
CoT-decoding的发现为语言模型的应用开辟了新的可能性。它不仅提高了模型的性能,还为我们理解和改进AI系统提供了新的视角。随着这一领域的不断发展,我们有理由期待更多令人兴奋的突破,推动AI技术向着更智能、更透明的方向前进。
我们完全可以用这个方法写一个提示词。比如下面这样,用CoT-decoding写一篇介绍元提示词如何使用的文章:

文章来自于“AI修猫Prompt”,作者“AI修猫Prompt”。




【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
