# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
OpenAI用o1开启推理算力Scaling Law,能走多远?
数学证明来了:没有上限。
斯隆奖得主马腾宇以及Google Brain推理团队创建者Denny Zhou联手证明,只要思维链足够长,Transformer就可以解决任何问题!

通过数学方法,他们证明了Transformer有能力模拟任意多项式大小的数字电路,论文已入选ICLR 2024。

用网友的话来说,CoT的集成缩小了Transformer与图灵机之间的差距,为Transformer实现图灵完备提供了可能。

这意味着,神经网络理论上可以高效解决复杂问题。
再说得直白些的话:Compute is all you need!
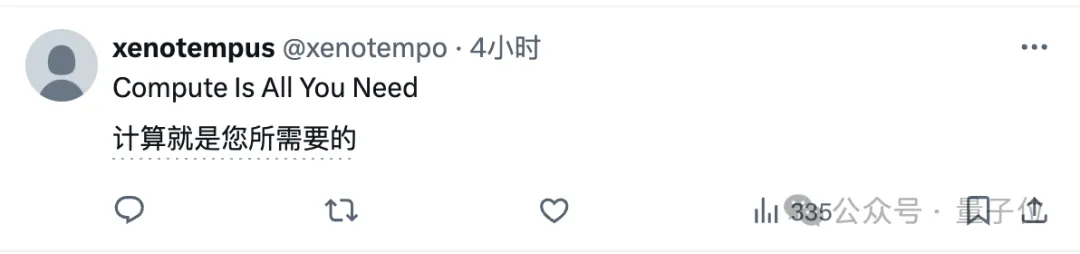
首先需要说明的是,“可以解决任何问题”是一个通俗化的表述,严格来说,论文的核心结论是思维链(CoT)能够显著提升Transformer的表达能力。
作者首先通过理论分析,提出对于固定深度、多项式宽度、常数精度的Transformer模型,如果不使用CoT,其表达能力将受限于AC0问题类别。(AC0是一类可以在并行计算中高效解决的问题,但不包括需要复杂序列化计算的问题。)
在固定指数位的情况下,固定深度、对数精度的Transformer模型即使引入了正确的舍入操作,其表达能力也仅限于TC0问题类别。
但当引入CoT时,固定深度、常数精度的Transformer模型就能够解决任何由大小为T的布尔电路解决的问题。
这表明CoT显著扩展了模型的表达能力,使其能够处理更复杂的问题。
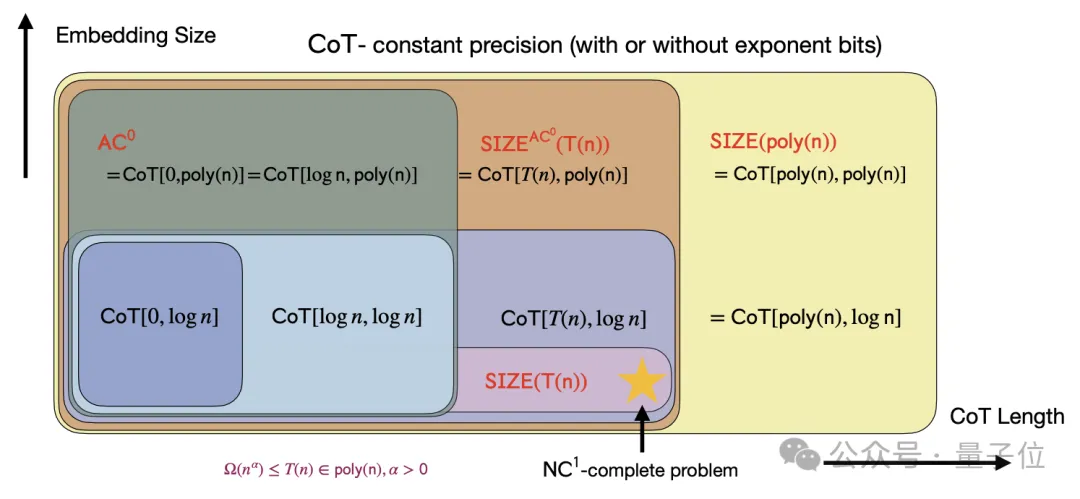
为了验证理论分析,论文在四个核心问题上进行了实验,考虑了基础(base)、CoT和提示(hint)三种不同的训练设置:
首先在可并行的模运算问题上,输入是若干个模7的数,输出是它们的模7和。
实验结果表明,所有设置下的Transformer都能够学习模加;但在较长序列(如n=16)上,CoT的优势更加明显。
这说明即使是可并行问题,CoT也能带来一定的效率提升。
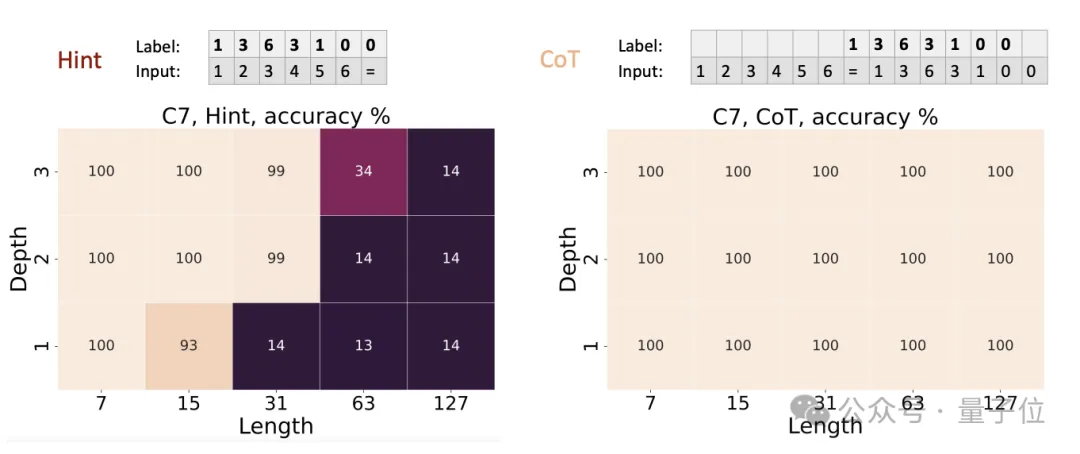
在内在串行的置换群复合任务上,输入是S_5置换群中的若干个置换,输出是它们的复合结果。
结果,CoT提高了低深度模型的准确性——
不使用CoT的Transformer即使深度较大也难以学习该任务(准确率约20%),而使用CoT后即使是1层Transformer也能轻松学习(准确率100%)。
对于迭代平方任务,输入是一个质数p、一个整数r和若干个“^2”符号,输出是r^(2^k) mod p。
实验结果与置换群复合任务相似:不使用CoT时。即使16层Transformer也难以学习;而使用CoT后。1层Transformer就能完美求解。
这再次验证了理论分析,即迭代平方是内在串行的,需要CoT来提供必要的计算能力。
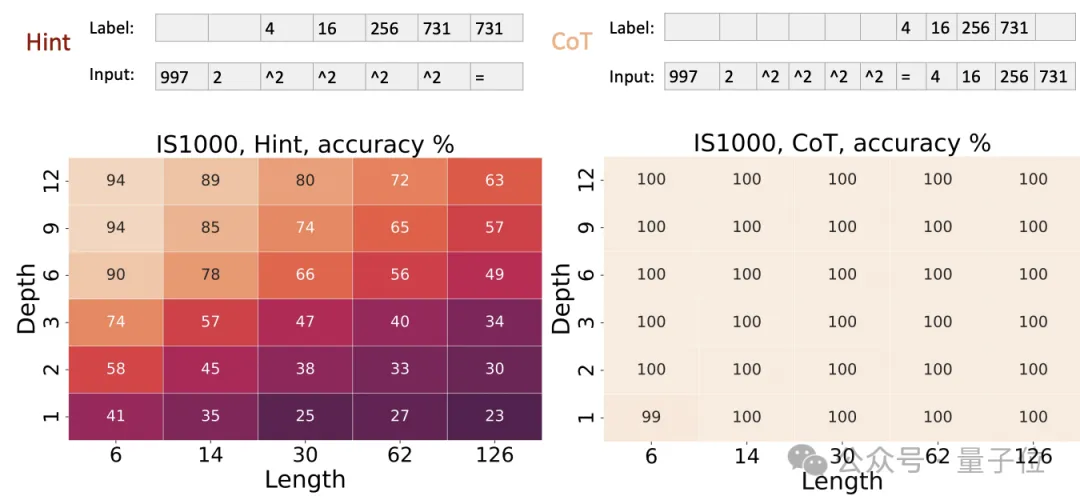
最后的电路值问题,输入是一个随机布尔电路的描述,输出是电路的最终输出值。
实验结果表明,在基准设置下,4层Transformer的准确率约为50%,8层约为90%,16层接近100%;
而使用CoT后,1层Transformer就能达到接近100%的准确率。
这验证了理论结果,即CoT赋予了Transformer任意电路的模拟能力,使其能够解决电路值问题这一P完全问题。
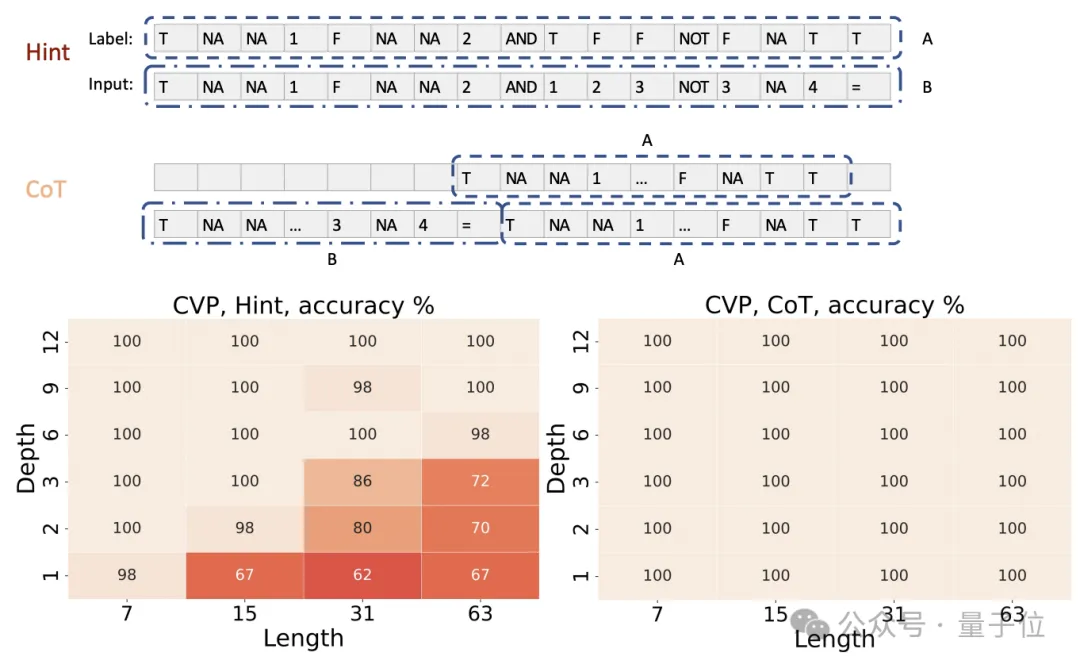
除了上述实验,作者还对以下结论进行了理论证明:
对于任意一个可以用多项式大小的布尔电路计算的函数,都存在一个仅有常数层数的Transformer,可以通过足够多步数的思维链(CoT)来模拟电路的计算过程,从而计算出这个函数。
证明的思路是先将布尔电路视为一系列逻辑门的组合,然后利用Transformer中的位置编码为每个逻辑门及其状态分配一个独特的表示,进而通过逐步计算来模拟整个电路的执行过程。
这个证明的关键,在于利用CoT来逐步模拟电路中每个门的计算。
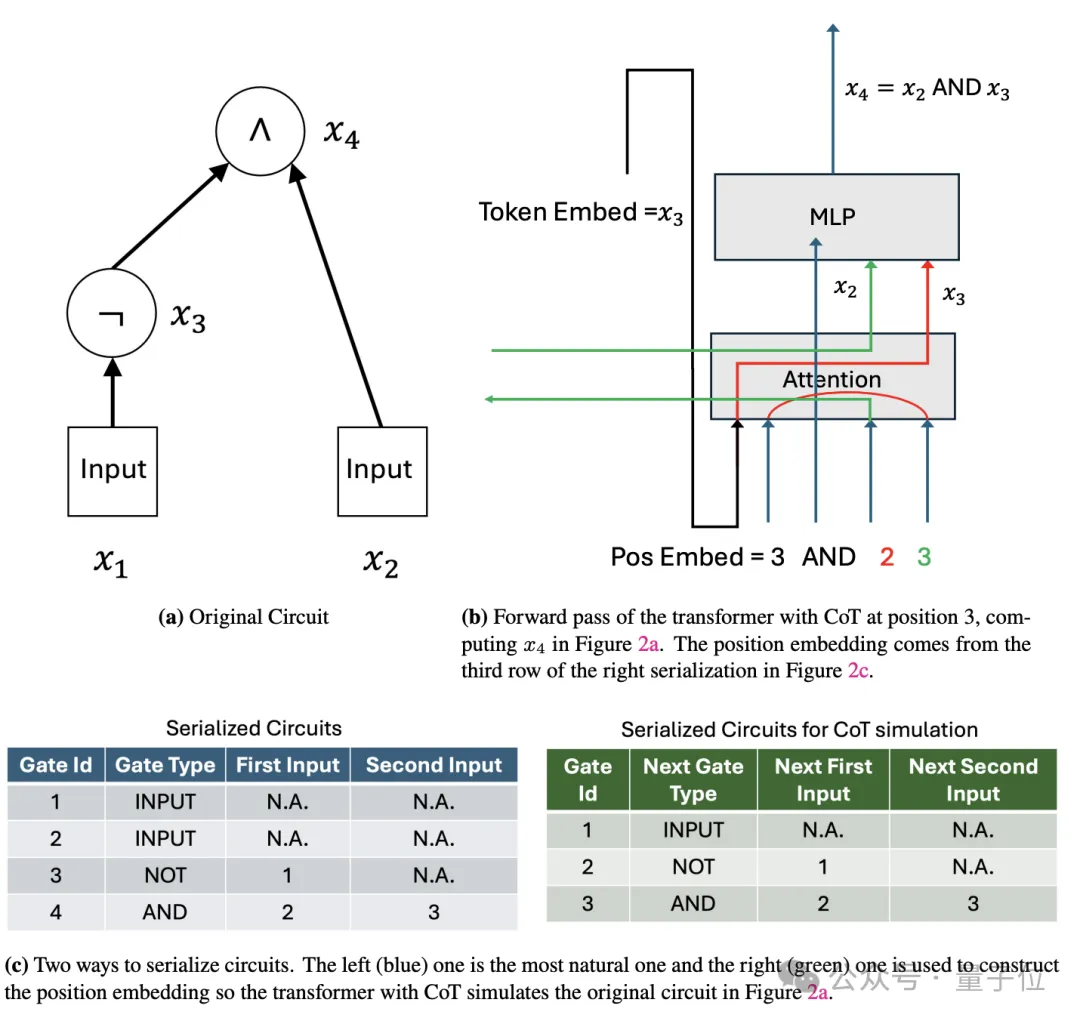
具体而言,对于一个有T(n)个门的电路,作者设计了一个4T(n)个token的输入序列。
这个序列包含了电路的完整描述,每个门用4个连续的token表示:门类型、两个输入门的索引和当前门的索引,并用输入序列中的第一个token指示了电路的输入值。
然后,作者构造了一个常数深度的Transformer,这个Transformer的嵌入维度只需要O(log n),就足以对T(n)个门进行编码。
在第一层,Transformer读取输入序列,并将电路的描述信息存储到其位置嵌入中。
接下来是关键的CoT步骤。Transformer逐步生成4T(n)个token的思维链,每4个token对应电路中的一个门。
对于第i个门,Transformer执行以下操作:
通过这一过程,Transformer逐步模拟了电路中每一个门的计算,并将中间结果存储在思维链中。在生成完整个思维链后,最后一个门的输出就对应了电路的最终输出。
也就是说,通过将电路“展开”为一个长度为O(T(n))的思维链,即使固有深度很浅,Transformer也可以逐步执行电路中的计算。
在此基础上,作者进一步证明,具有O(T(n))长度CoT的常数深度Transformer,可以模拟任意T(n)大小的电路,因此其计算能力等价于多项式大小电路。
能够模拟电路的计算过程,意味着CoT+Transformer能够解决可计算问题。
同时,这也说明只要有足够的CoT思考时间,大模型不需要扩展尺寸也能解决复杂问题。
有专业人士用一篇长文解释了CoT和图灵完备性之间的关系:
如果没有CoT,Transformer仅限于执行AC0复杂度类中的可并行任务;
CoT推理从根本上改变了这一格局,它使Transformer能够通过中间推理token处理串行计算,从而增加计算深度并允许模型模拟AC0以外的更深层次的电路。
这一进步将Transformer带入了P/poly领域,即多项式大小电路可以解决的问题类型。
理论上,只要有足够的CoT步骤,Transformer就可以模拟多项式大小电路可以执行的任何计算,从而缩小了Transformer与图灵机之间的差距。
但实际限制仍然存在,例如有限的上下文窗口和计算资源。要充分利用这一潜力,需要仔细的模型设计和优化。

还有人把这项成果和OpenAI的“草莓”,也就是爆火的超强模型o1联系到了一起——
草莓同样也是思考的时间越长,准确性越高,按照这个思路,只要有好的模型,就能解决人类面临的一系列难题。
甚至有人表示,如果这项研究是真的,那么AGI就已经在到来的路上了……

不过也有人认为,这只是一个理论性的结果,距离实际应用还存在很大差距。
即使抛开理论与实际条件的不同,时间和成本问题就是一个重要的限制因素。
而且实验的一个假设是模型权重被正确设置,但实际模型的训练很难达到这一程度。

还有人指出,这种模拟门电路运算,并不是大模型实际学习和工作的方式。

换言之,如何将实际问题用布尔电路表示,是Transformer从能解决运算问题到能够解决实际问题的一个关键。
但现实中,诸如“如何治疗癌症”这样的问题,很难以电路的形式去描述。
虽然距离实际应用还有一系列问题要解决,但这项研究至少揭开了CoT的巨大潜力。
本论文一共有四名作者,全部都是华人。
按署名顺序,第一位作者为清华姚班校友李志远,是马腾宇已毕业的博士生,现为芝加哥丰田技术学院(TTIC)的终身教授助理教授。
第二位作者是Hong Liu,也是马腾宇的博士生,现在在读,本科就读于清华,曾获得特等奖学金及优秀毕业生荣誉。
第三位是Google Brain推理团队创建者Denny Zhou,中科院博士,2017年加入Google前在微软担任了11年的高级研究员。
最后是2021年斯隆奖得主、斯坦福大学助理教授马腾宇,他是姚班校友、陈丹琦的同班同学。
文章来自于“量子位”,作者“克雷西”。




