# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
随着OpenAI o1的爆火,最近CoT也成了圈内热议的高频词。
靠着CoT的强力加持,o1直接在LLM领域首次实现了通用复杂推理能力,俨然是AI发展新范式的开端。
许多人惊呼:莫非CoT就是通往AGI的正确路径?
而且,o1这种慢思考模式不仅帮助LLM做数学和符号推理,甚至,还让LLM发展出了类人情感!
最近,斯坦福等机构学者发文证实:LLM在情感方面表现出的认知和推理比人类还像人类,背后最大贡献者竟然就是CoT。

就在这几天,风口浪尖上的CoT,又让AI社区掀起了一场风波。
谷歌DeepMind首席科学家称LLM推理无极限,LeCun田渊栋回怼
CoT爆火之后,谷歌DeepMind首席科学家Denny Zhou拿出了自己团队八月份的一篇论文,抛出了这样的观点:「LLM推理能力的极限是什么?那就是没有限制」。
他表示,谷歌团队已经用数学方法证明,Transformer可以解决任何问题,只要允许它们根据需要生成任意数量的中间推理token。

可以看出,Denny Zhou等人提出的中间推理token,跟o1的核心技术CoT非常相似。
传统的Transformer模型的致命弱点,就是擅长并行计算,但不擅长串行推理。
而CoT,恰恰解决了这个问题。
在这项工作中,Denny Zhou等人发现:传统的Transformer模型,只能解决AC0电路能解决的问题;但一旦加入CoT,Transformer几乎可以解决任何问题。
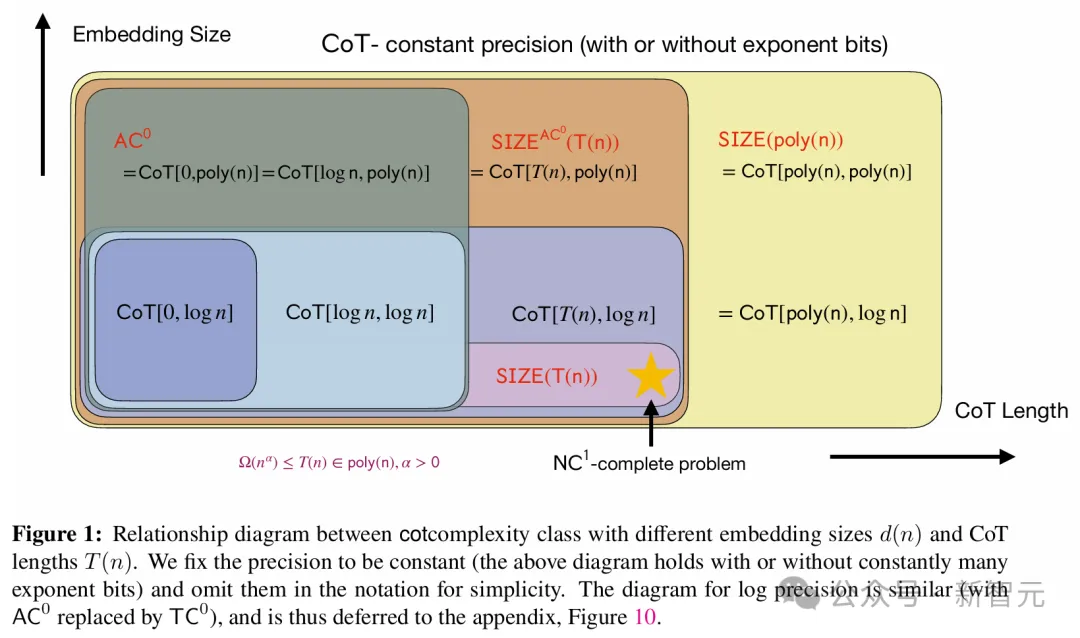
只要CoT步骤足够多,Transformer就能模拟任意大小的布尔电路,解决P/poly问题
也就是说,可以用数学严格证明,CoT可以让Transformer解决几乎所有能用计算机解决的问题。
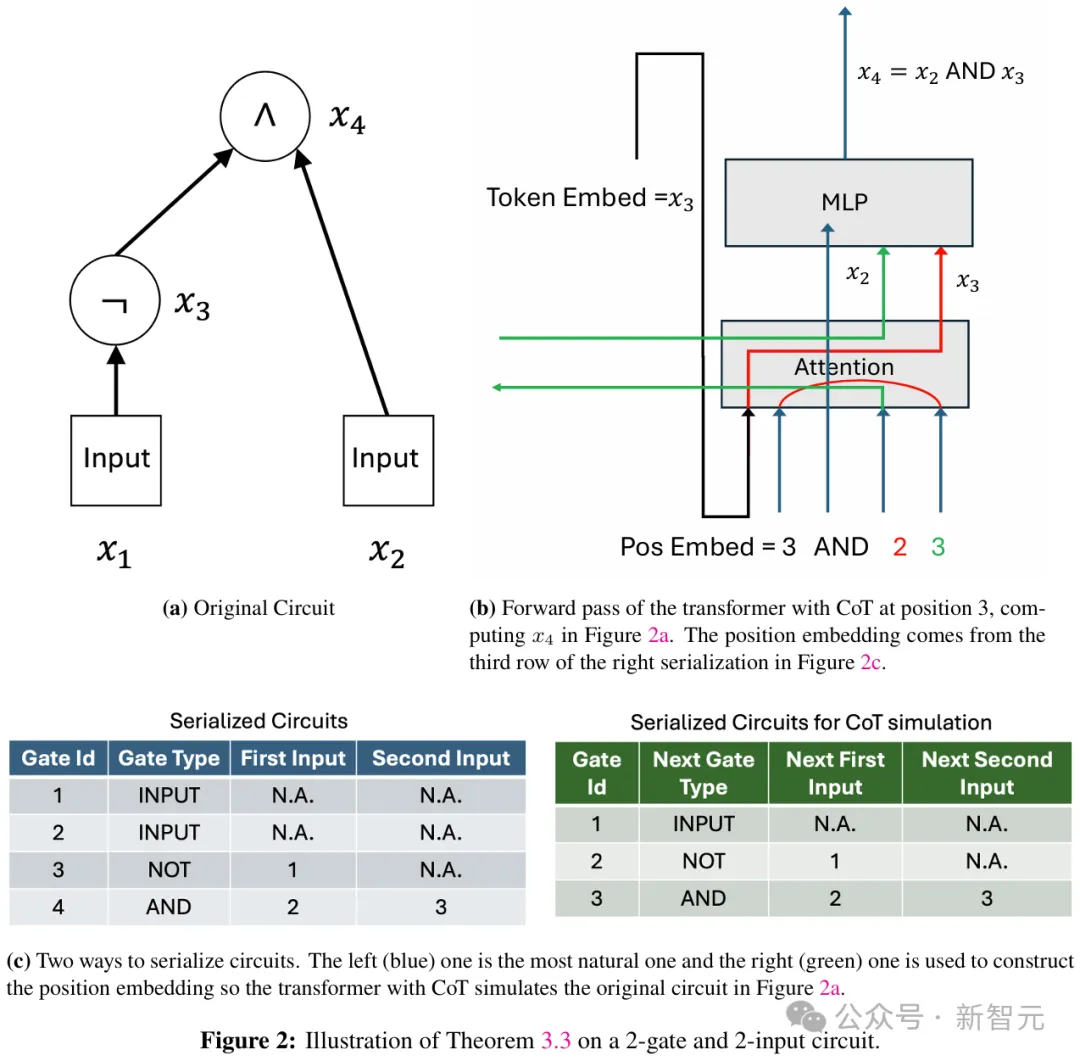
利用CoT,可以模拟布尔电路中每个逻辑门的计算
这项工作暗示着,CoT为更强大的LLM推理提供了新的思路,CoT或将成为未来LLM发展的重要方向,而且很可能闪烁着AGI的火花。
Denny Zhou发帖后,立即引发了AI社区的热议。
多位研究者下场讨论,也惊动了其他大佬。
这不,就在刚刚,田渊栋和LeCun依次发表意见,回怼了Denny Zhou。
在他们看来,CoT的作用,被远远夸大了。

田渊栋表示,虽然CoT的确很有用,但Denny Zhou等人对其过于盲目追捧了,显然,CoT并不是我们所需要的一切。
在这篇论文中提到的是一种通用理论,可以通过显式构建Transformer权重,让其更好地适应特定任务。
然而这样,CoT的长度就会很长,这样的权重配置,能否通过梯度下降来学习呢?
理论上,2层多层感知器是可以拟合任何数据的,那我们就该相信它可以应用在所有场景中吗?
人类的推练链是十分简洁的,面对从未见过的问题,也能捕捉关键因素。但LLM可以吗?
如何在瞬间就学习或构建出这样的表征,是很令人着迷的。
田渊栋的帖子一发出,立刻就获得了LeCun的支持。

LeCun表示,自己本来也想发表类似的言论,不巧被田渊栋抢先了。
「2层网络和核机器可以无限逼近任何函数,达到我们想要的精度,所以我们不需要深度学习。」
从1995年到2010年,LeCun听到这个说法无数遍了。
当然,这个操作理论上是可行的。但如果真的在实践中应用所有相关的函数,光是第一层中的神经元数量就会多到不可思议。
对此,网友的评价是:收敛和等价证明被高估了,高效的学习策略被低估了,就是这样。
「我很高兴Python的存在,尽管Pascal是图灵完备的。」
一位从业者表示,自己的研究是从一个隐藏层MLP判别式开始,然后就是CNN或Deep NN等专业模型。
他的判断是:较小的模型更稳健、更可解释,而且通常很接近,但永远不会那么好。而使用更深层次的模型,总是会有额外的百分比。
很多人是「挺CoT派」的。比如有人表示理解LeCun的观点,但在多维扩展场景中,CoT绝对大有潜力。

而对于LeCun所担心的问题,有网友表示,LeCun在采用一种自上而下的策略,在这种情况下他必须控制所有的第一层输入,但其实,他并不需要。

因为,CoT通过创建了新的临时层,让人放弃了对这种控制的幻想。其解决方案就是,通过网络层的一般形式,来逼近注意力头本身。
有趣的是,该网友表示,自己的灵感来源是《物理学》上的一封信,表明量子全息拓扑能更有效地满足这一点。
即使爱因斯坦-罗森桥的边界相当大,它可以更连续地离散表示为无数不同的小层,横跨所产生的平坦空间。这,就是表征的力量所在。
有人表示,这个讨论没什么意思,本质上不过是「无限猴子定理」罢了。
让一只猴子在打字机上随机按键,当按键时间达到无穷时,几乎必然能打出任何给定文字,比如莎士比亚全集。

最终,田渊栋也承认,谷歌这篇论文的思路的确有可取之处。然而由于涉及到不同的数据分布、模型架构、学习算法、后处理等等,问题还要更复杂。
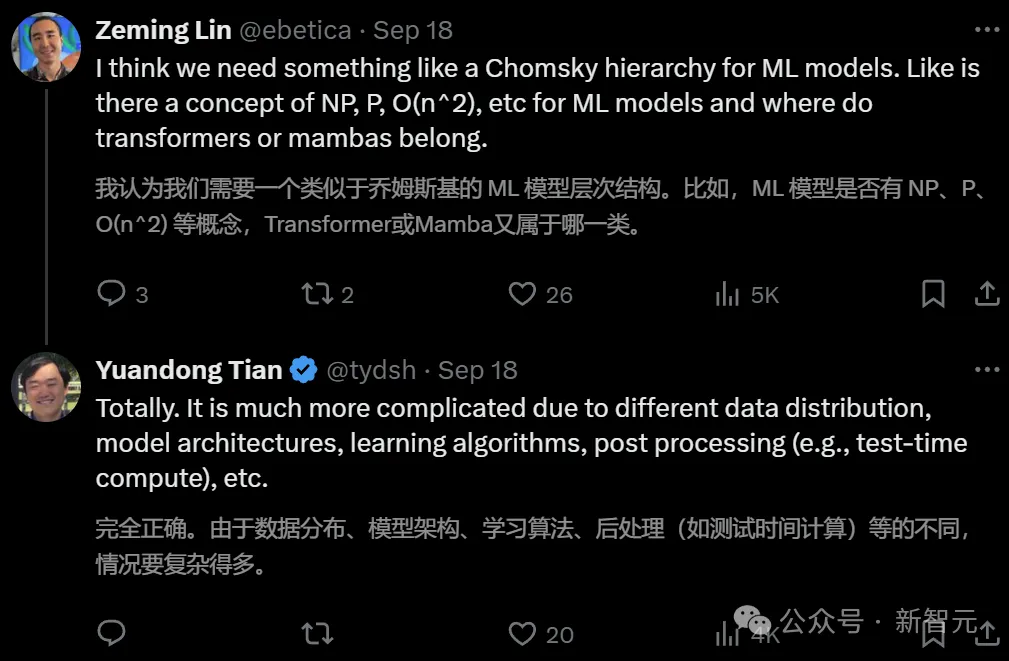
正如Evolutionary Scale联创Zeming Lin所言:我们需要像乔姆斯基层次结构这样的机器学习模型。就像ML模型有NP、P、O(n^2) 等概念一样,Transformer或Mamba属于哪里呢?
而在田渊栋发帖的第二天,谷歌论文主要作者马腾宇也上线评论说:CoT的长度是可以超长的。
2层MLP中的神经元数量呈指数级,才能逼近几乎任何函数。
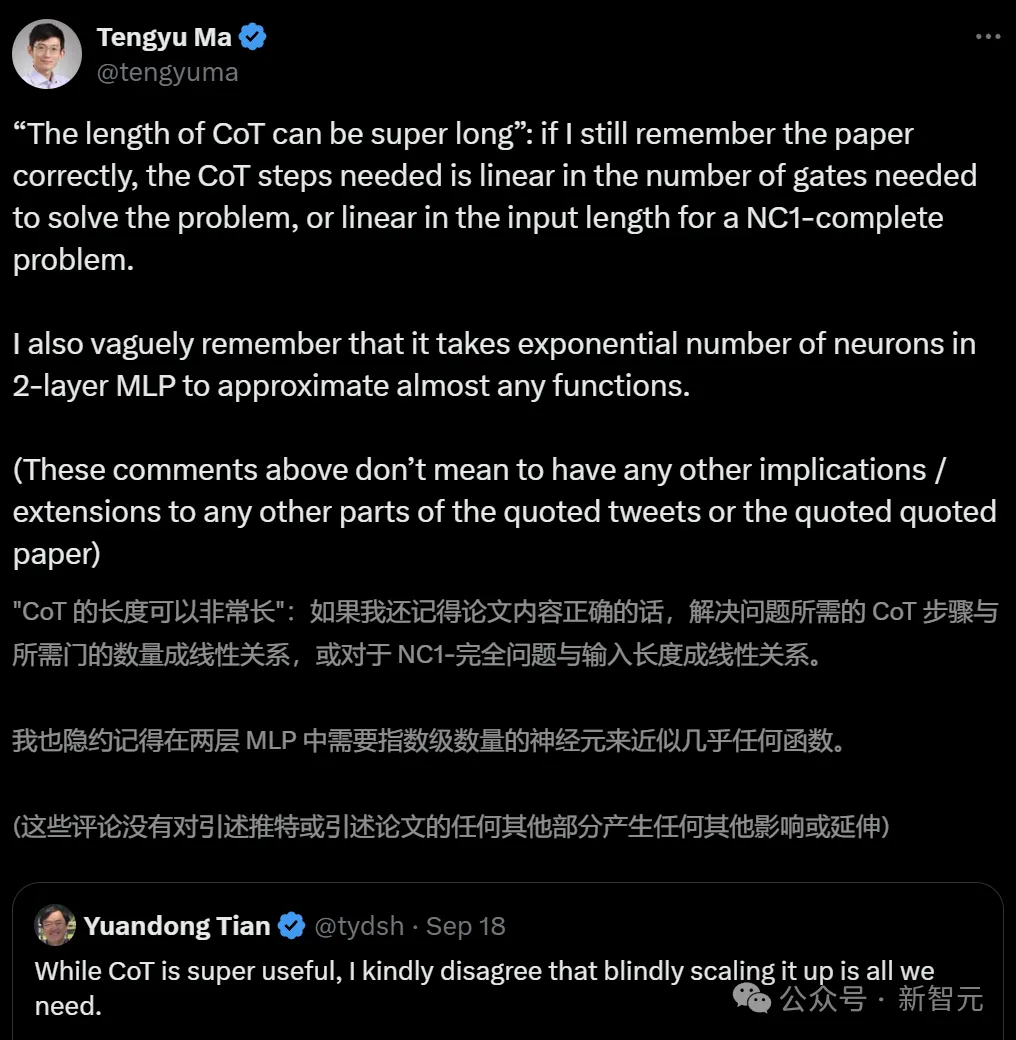
田渊栋回复他说:对那些可能需要指数数量的门的问题,CoT的长度可以很长。
这和2层MLP情况是一致的,因为无论拟合任意函数,都需要覆盖高维空间中的所有角,这是最坏的情况。
然而,现实世界的问题,是否有如此良好/简洁的表征呢?如果它们都像NC1一样,属于P问题,那么当然可以通过构建Transformer的权重来做到。

在最近一条X帖子中,田渊栋表示,自己的想法是,能够找到更短的CoT,同时使用专家迭代(穷人的RL)来保持最佳结果。
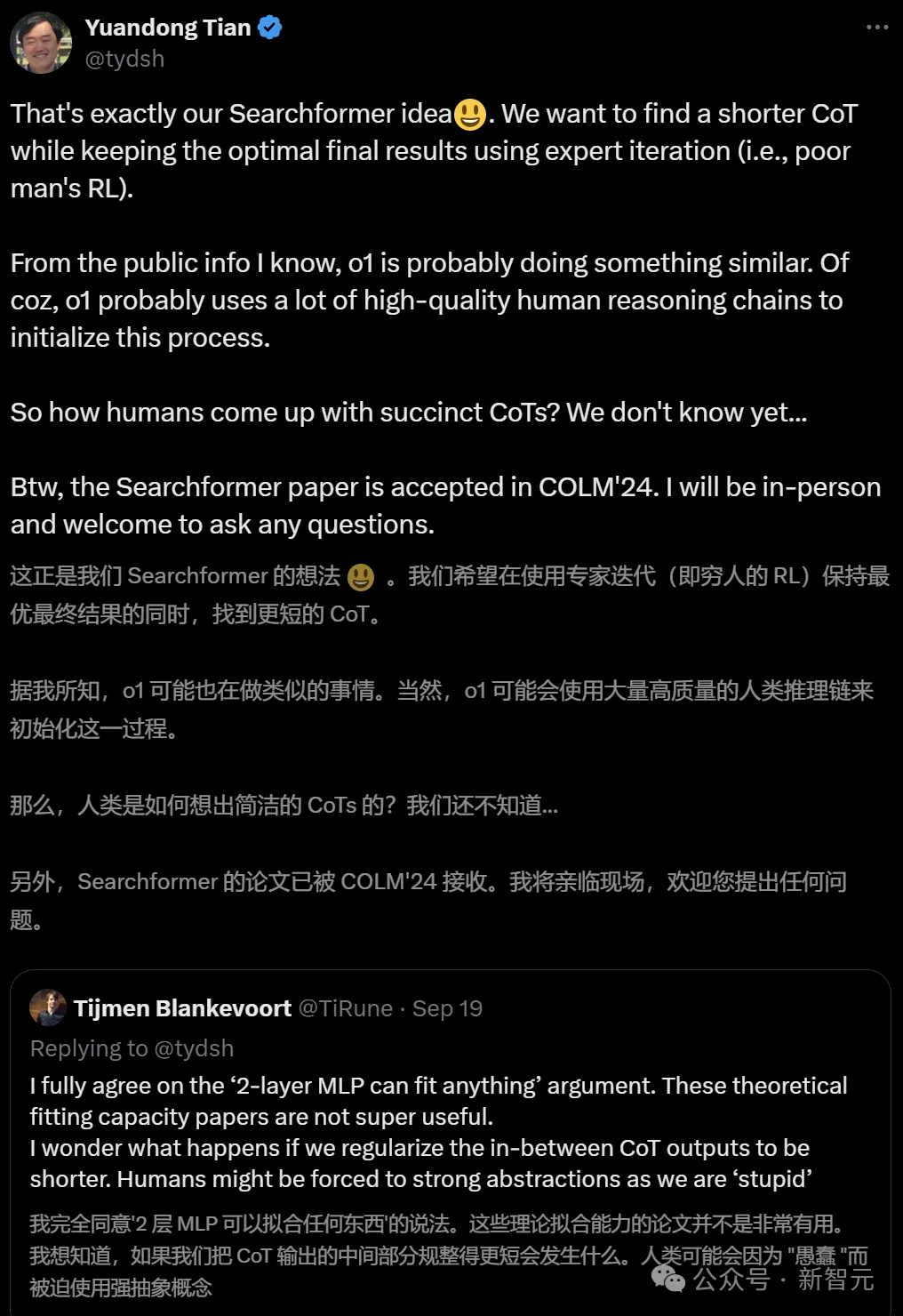
从公开信息来看,他推断o1也是在做类似的事情。至于初始化过程,可能是使用了大量高质量的人类推理链。
人类是如何想出简洁的CoT呢,这就不为人所知了。
趁此机会,他还宣传了一下自己团队Searchformer的论文。

论文地址:https://arxiv.org/abs/2402.14083
总之,虽然我们还不知道如何拓展2层神经网络,但OpenAI似乎确信自己已经掌握了拓展CoT的秘诀。

最新讲座:揭示LLM推理的关键思想和局限
目前,这场空前热烈的讨论还在继续。
而关于LLM推理,Denny Zhou最近在UC伯克利也进行了一场类似主题的讲座。

他表示,自己对AI的期待是可以像人类一样从较少的示例中进行学习。

但曾经尝试的种种机器学习方法之所以都不成功,是因为模型缺失了一种重要能力——推理。

人类之所以能从较少的示例中学习到抽象的规律和原理,就是因为推理能力。正如爱因斯坦所说的,「Make things as simple as possible but not simpler」。(一切都应该尽可能简单,但不能过于简单)
比如,对于下面这个问题:

对人类而言,这是一道小学水平的「找规律」。
但机器学习需要海量的标注数据才能找出其中的规律。
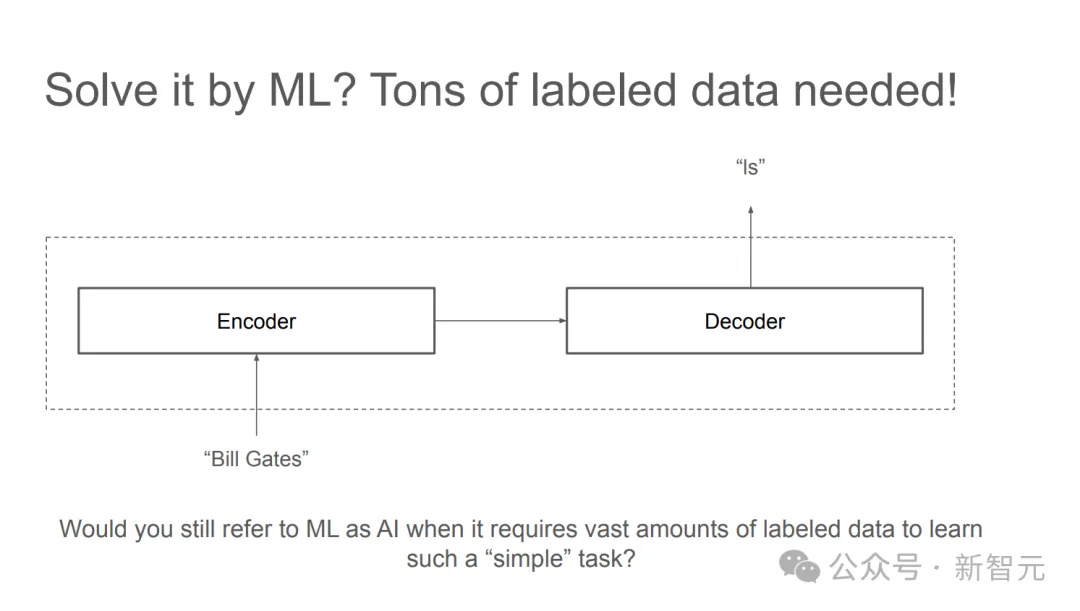
而LLM的少样本学习更是难以解决。
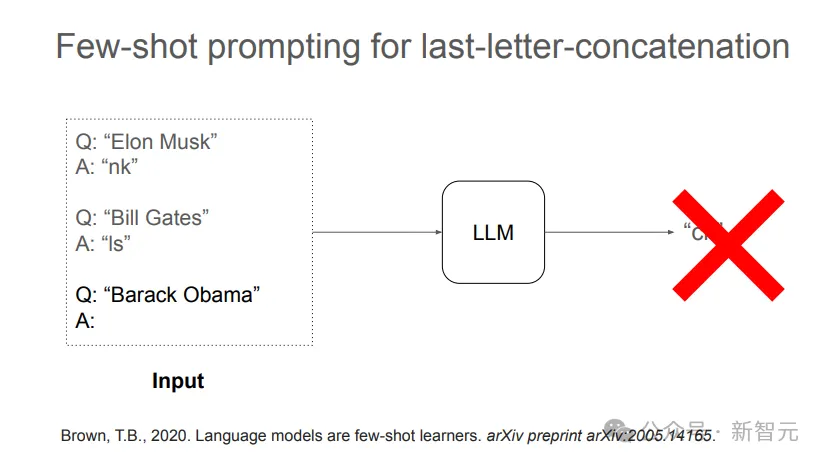
但如果在数据中加入「推理过程」,LLM就很容易有样学样,学习到少量样本示例中展现出的规律,并给出正确答案。

通过这个简单的例子,Denny Zhou指出,关键想法是在数据中包含中间步骤,或者是解释原理(rationale),同时让模型写出推导过程。
这就是使用CoT背后的逻辑和直觉。
DeepMind的研究者们,率先使用自然语言原理去解决数学问题。
关键就在于从头开始训练了一个序列到序列模型,从而通过一系列小步骤得出最终答案。

继这项工作后,OpenAI的研究者们建立了一个更大的数学单词问题数据集(GSM8K),其中包含自然语言基本原理,并利用它对GPT-3进行了微调。

这样,语言模型的中间计算步骤,就被展示了出来。

o1模型的奠基性贡献者之一Jason Wei在谷歌大脑工作时曾和Denny Zhou发表了一篇论文,指出CoT提示可以引导出LLM的推理能力。
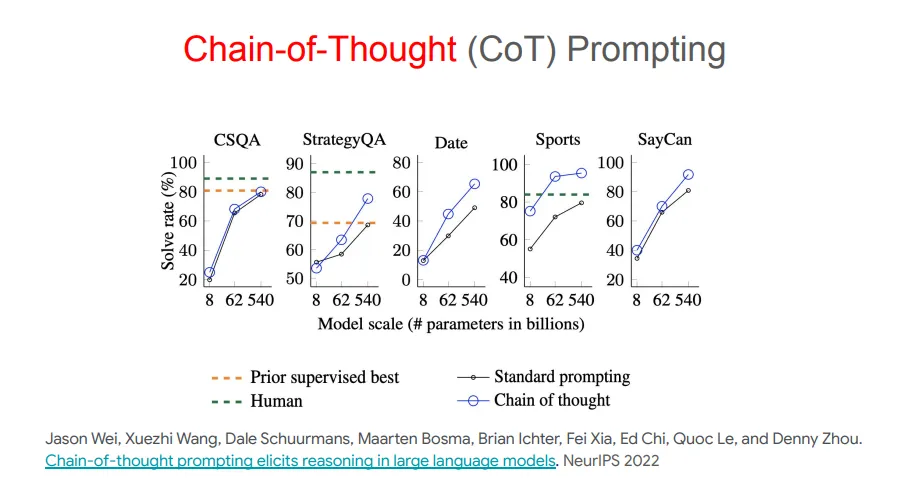
Denny Zhou甚至更直白地指出样本「中间步骤」的重要性:无论是训练、微调还是提示,都需要给出中间步骤,才能让LLM在响应中也包含中间步骤。

实际上,这也是Denny Zhou、马腾宇最近论文的核心观点。如果能生成足够长的中间推理步骤,常数深度的Transformer模型也能解决任何串行问题。

但是,这也并不意味着CoT可以包打一切,解决LLM推理的所有缺陷。
比如,模型很容易被无关的上下文干扰,这一点和人类思维也很类似。
实验中发现,在GSM8K数据集中添加无关上下文,可以导致模型性能出现高达20+百分点的损失。

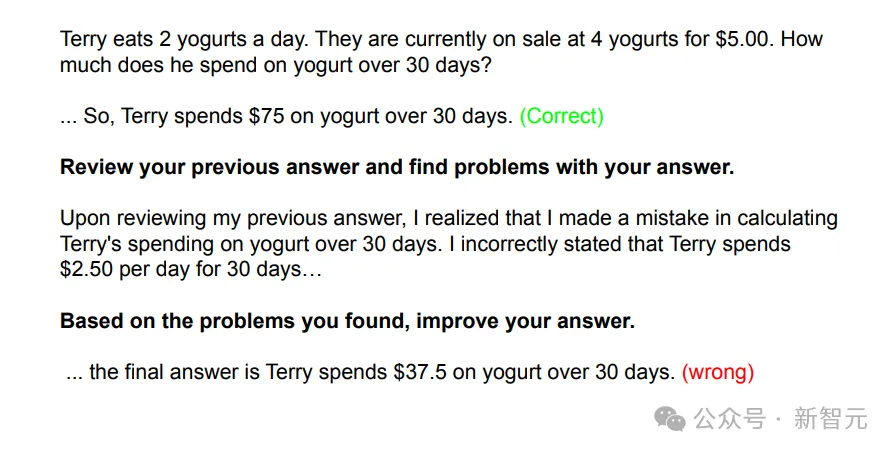
此外,LLM的自我纠正能力也并不健全。
虽然有些模型在反思后可以成功修改错误答案,但也存在另一种风险——可能反而把正确答案改错。
那么,LLM的下一步应该往何处去?
Denny Zhou指出,虽然我们已经知道了模型推理有哪些缺陷和不足,但最重要的还是定义好问题,再从第一性原理出发去解决。

此处,再引用一句爱因斯坦的话:「如果有1小时用来拯救星球,我会花59分钟来定义问题,然后用1分钟解决它。」
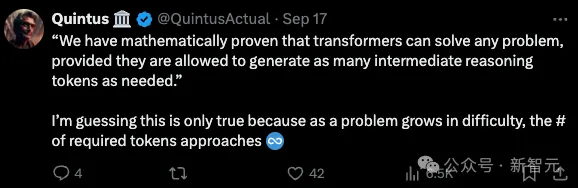
虽然Denny Zhou的演讲内容相当详实,但「CoT实现推理无极限」的论断确实相当大胆,因此也引起了网友的反驳。
比如有人指出,前提中所谓的「无限多token」只是在理论上可行,在实践中未必如此。
token数量很有可能随输入增加呈现指数增长,问题变得越来越复杂时,token数量逼近无限,你要怎么处理?
而且,LLM推理和人类还存在本质差异。AI目前只能进行暴力搜索(brute-force),但人类有所谓的「启发式」思考,「直觉」让我们能将数百万种可能性快速缩减至几种可行的解决方案。
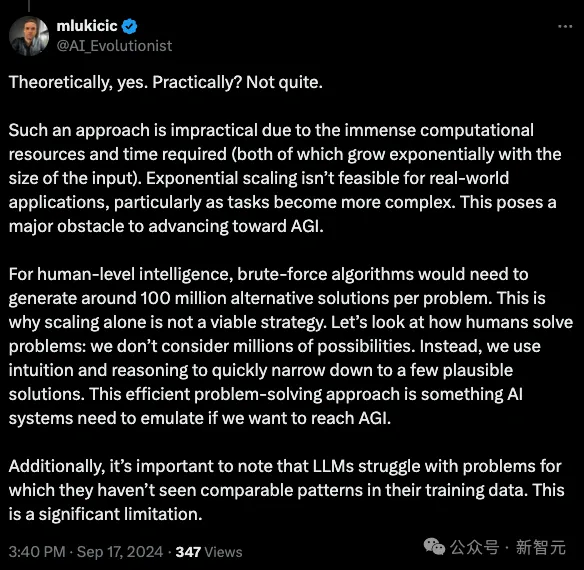
如果想达到AGI,AI系统就需要模拟出这种高效的问题解决路径。
文章来源于“新智元”,作者“新智元”



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
