# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
OpenAI的理念,居然被国内公司抢先践行了?
比起OpenAI,这家公司的idea提出得更早,方法更前瞻,落地应用也更快。
他们所采用的架构,已经可以和o1匹敌,如果更新到下一代大模型,甚至还有可能实现领先。
没错,这次周鸿祎和OpenAI所采用的路线殊途同归,不谋而合了。
360首创的CoE架构,已经可以媲美OpenAI o1的思维链模式。
不仅在技术层面如此前瞻,在落地上360也抢先了一步,对应用趋势拿捏得十分精准。
「点金石」思维链,让OpenAI三缄其口
OpenAI o1的横空出世,开启了GPT系列之外的新一代模型。
它代表着人工智能发展新范式的开端,在LLM领域首次实现了通用复杂推理能力。

在代码生成方面,o1可以媲美IOI金牌水准。在物理、生物、化学等STEM学科问题的基准测试GPQA中,甚至超越了人类博士。
在最新的LMSYS排行榜上,o1-preview不仅横扫了各领域的第一,且数学能力甩出第二名Claude 3.5 Sonnet好几条街。

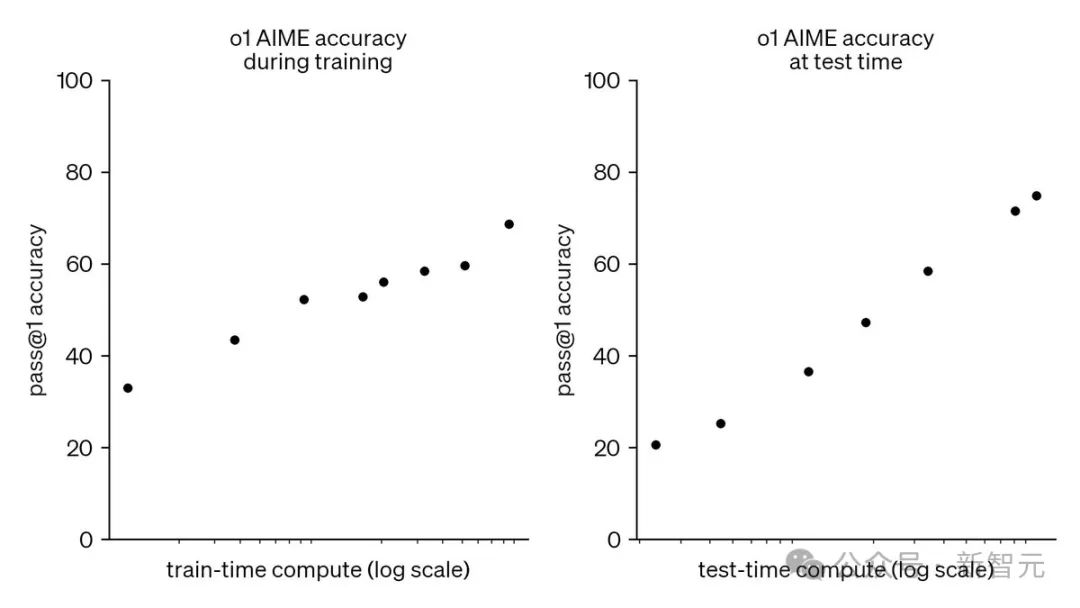
这一切,都要归功于o1背后的思维链(Chain-of-Thought,CoT)。然而,思维链具体的工作原理是什么?
对此讳莫如深的OpenAI,坚决封闭了o1思维链的推理过程,还对打破砂锅追问到底的用户发出「封号警告」。

官方放出的报告中,也只有非常简短的一句话提到了模型训练:通过强化学习,o1学会了磨练其思维链CoT并改进策略」
不过业内惊奇地发现:OpenAI o1的思维链模式,竟然和360的「慢思考」理念不谋而合了?
而且这一次,国内公司甚至走在了OpenAI前面。
LLM,需要学会「慢思考」
作为国内公司的先行者,360早在o1发布前,就提出过相似论断了。
今年7月底的 ISC.AI 大会上,360创始人周鸿祎从「快思考」和「慢思考」的角度出发,对比人类的思维过程,对LLM思维链进行解读。

具体而言,「快思考」的特点是无意识的快速直觉,反应很快但能力不够强。
GPT类大模型通过训练大量知识,主要学习的就是这种「快思考」的能力,能够对各种问题不假思索、出口成章,但答案质量不够稳定。
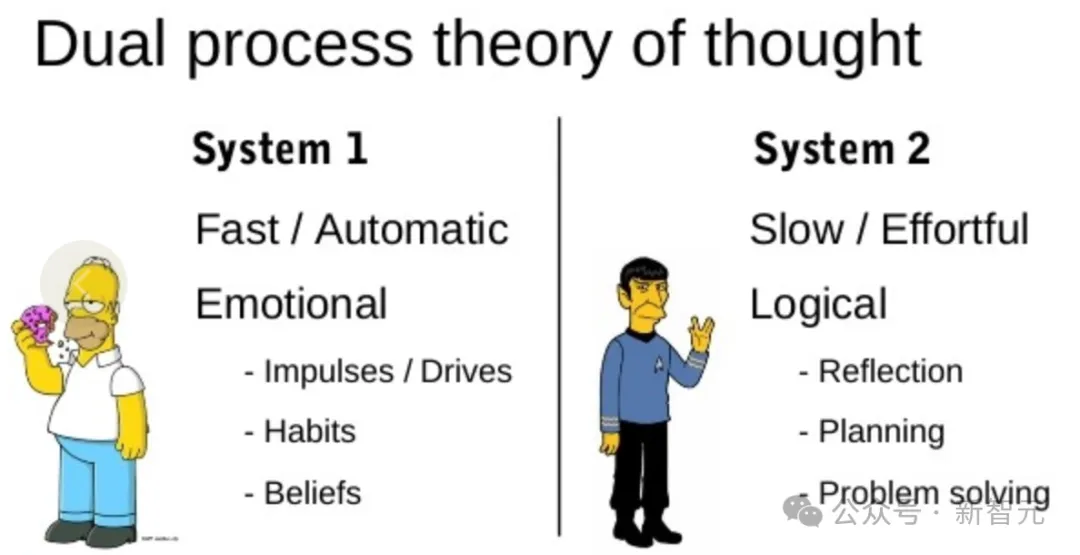
而「慢思考」则相反,特点是缓慢、有意识、有逻辑性,类似于写一篇复杂的文章,需要分很多步骤,回答问题前还会反复地思考,对问题进行拆解、理解、推理,才能给出最终答案。
周鸿祎形容的这种「慢思考」,和OpenAI强调的推理思维链似乎如出一辙,不得不让人惊叹360的技术思维和先见之明。
OpenAI技术报告
创新CoE架构,媲美OpenAI的CoT模式
o1所采取的思维链,可以将棘手的问题分解为更简单的步骤,让模型逐步解决,从而实现「慢思考」,提高了推理能力。
那么,这种「慢思考」的推理模式,如果不用思维链实现,还有什么其他的技术路径?
有Reddit网友大胆开麦,认为o1并不是一个从头训练的新模型,而是一个相对较小的模型与GPT协作,才解锁出了如此惊人的推理能力。
在这个思路上,360的研发团队走到了最前沿。
早在8月1日,他们就推出了首创的CoE技术架构,让多个大模型组队共同思考,每次查询不仅调用多个模型,而且进行了多次调用,和CoT一样强调了推理过程。
比如搜索场景中,首先由意图识别模型处理原始查询,将任务分解、分类后再调度给相应的模型处理。
在「三模型」的设置中,第一个做专家,对提问进行第一轮回答;第二个做反思者,对专家的回答进行纠错和补充;第三个做总结者,对前两轮回答进行优化总结。

作为对比,MoE(Mixture-of-Experts,混合专家)架构虽然也由多个专家模型组成,但每次推理只能调用其中一个,而且极其依赖路由分配机制。
如果路由错误或某个专家出现故障,就会影响CoE架构的整体性能。
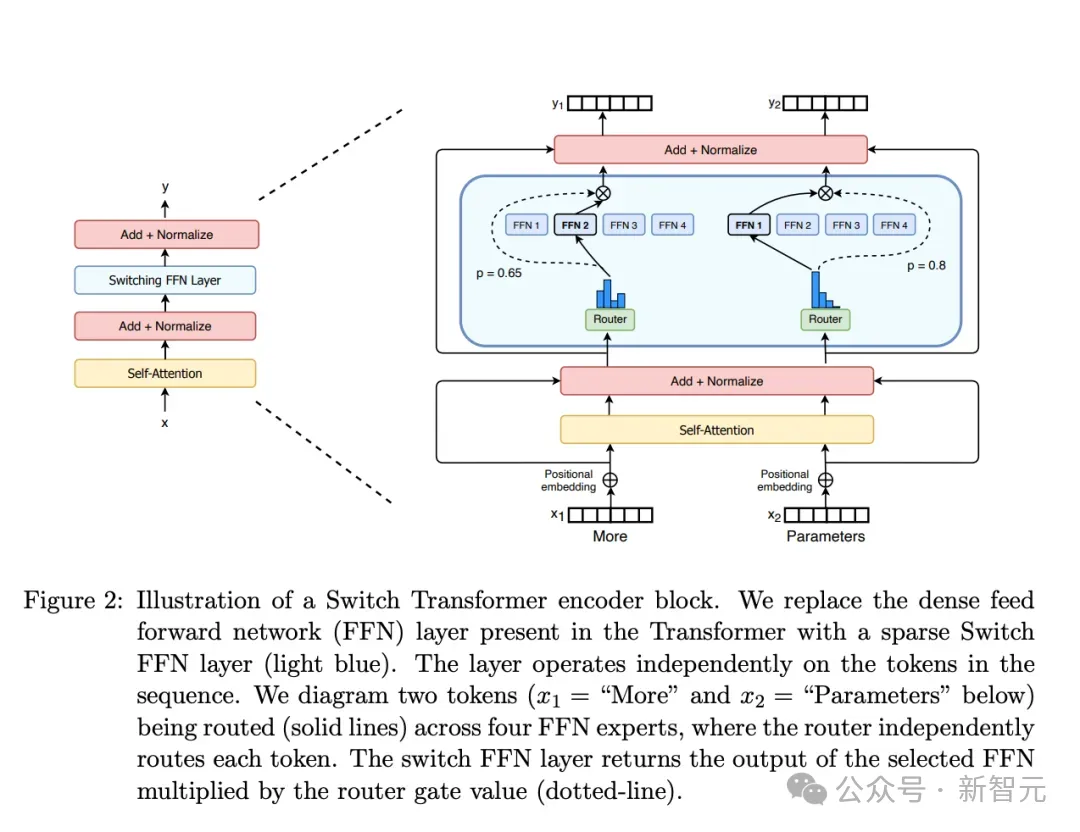
Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
而CoE架构则能让多个模型分工协作、并行工作,执行多步推理。

一句话总结就是,相比MoE,CoE模型在泛化性、鲁棒性、可解释性和推理效率方面都有所进步,不仅可以加快推理速度,还能降低使用成本。
而更进一步的,360还提出了一种CCoE设计。其中包括一个主干LLM和多个CoE(Collaboration of Experts)层,每层包含一个或多个不同领域的SOTA专家模型。

论文地址:https://arxiv.org/pdf/2407.11686v1
集成至CoE层时不需要对原始模型进行任何修改,而且允许每个专家模型进行单独微调。这种松散耦合的方式提供了很好的可扩展性,支持灵活增长至任意的专家数量。
实验结果表明,相比直接使用不同领域的基础模型,CCoE框架可以显著的性能提升,同时消耗更少的训练和推理资源。
国产大模型上演「复联」,组队挑战「灭霸」o1
360首创的CoE架构,不仅拉齐了国内公司和OpenAI的技术发展水平,还具有很强的现实应用价值。
现在的国产大模型在数据、算法、算力等方面仍然与OpenAI的旗舰模型存在差距,如果拿出来单挑,可以媲美GPT-4o,但很难超越o1。
这个时候,就需要用到传统的中国智慧了——「三个臭皮匠,顶个诸葛亮」。
灭霸虽强,但复仇者联盟的能量更无法阻挡;o1模型虽强,但绝非不可战胜。
国产大模型如果能更好地分工配合,通过CoE架构进行协作,就有可能打败看起来无比强大的OpenAI,甚至创造出更大的价值。
而且,这绝不只是说说而已。早在CoE架构刚发布的时候,集各家大模型所长的混合能力就已经超越了GPT-4o。
这个耦合起来的混合大模型,在翻译、写作等12项指标的测试中取得了80.49分的综合成绩,超越了GPT-4o的69.22分。
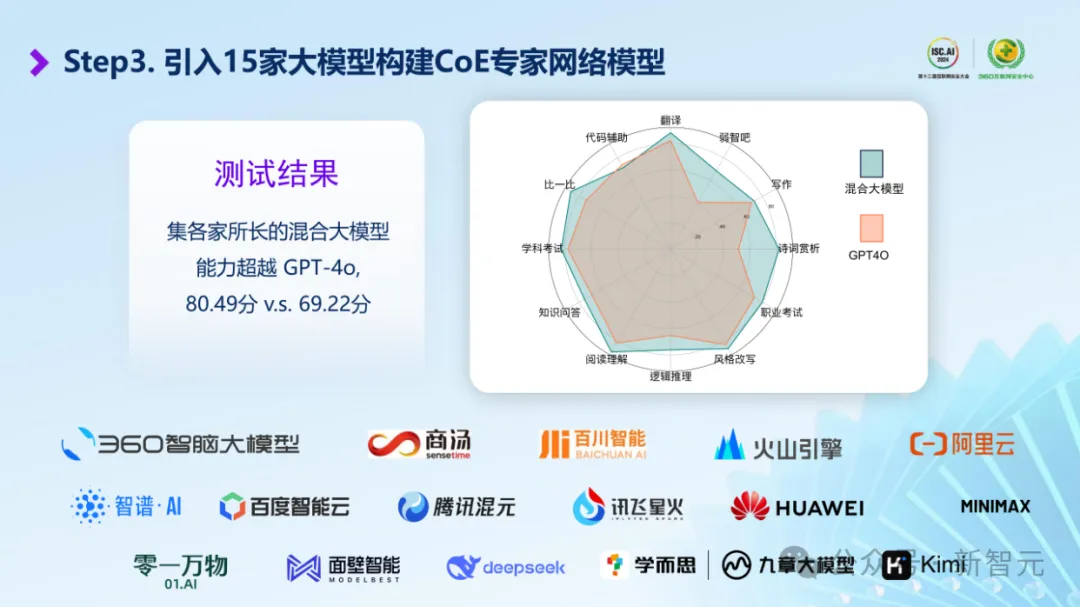
除了代码能力有微弱劣势以外,CoE模型在其余11项指标上均优于GPT-4o,特别是「逻辑推理」、「多步推理」、「诗词赏析」这类比较具有中文特色的问题,CoE的领先优势更加明显。
目前,360的「多模型协作」已经能打败并远远甩开GPT-4o,媲美o1-preview。
这就是复仇者联盟的力量,即使灭霸的能力再强,团结起来的团队,依旧是强大、可以与之抗衡的。
虽然8月1日刚刚发布,但CoE早已走出理论、走入实践和产品,落地在了360的AI搜索和360AI浏览器等AI产品中。
根据AI产品榜aicpb.com的统计,360AI搜索8月增速为113.92%,访问量超过2亿,增速位列全球主要AI搜索榜首。
之所以如此受欢迎,是因为360AI搜索会在充分理解问题的基础上进行任务分解和规划,给出更丰富、更具时效性和准确性的答案。
而且,用户可以在简洁、标准、深入和多模型协作这4种「AI工作流」中任选其一,得到自己想要的答案模式。
比如,简单的「strawberry里有几个r」的问题,就可以使用「简洁」模式提问。不仅有明确的答案,还会帮你分析为什么大多数LLM会数错。

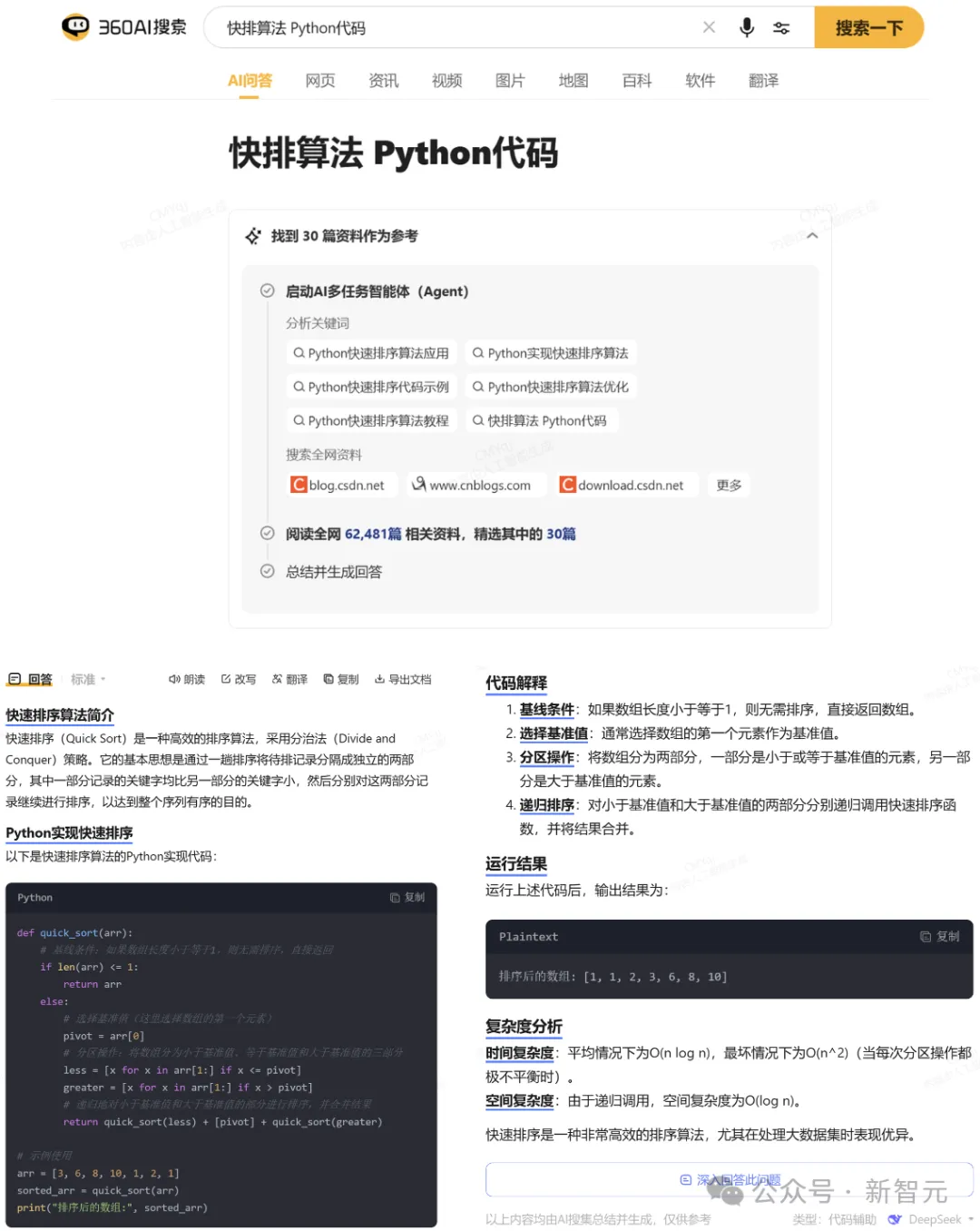
如果是代码类问题,AI搜索则会自动安排擅长生成代码的DeepSeek帮你回答。
「标准」模式下的答案更加全面,除了代码和注释,还给出了分析解释和相关的参考链接。
「深入」模式适合一些更需要解读分析的问题,比如下面这种透露着浓浓书卷气和历史感的:
从最基本的出处释义,到意境解读和赏析,还有创作背景和文化内涵的扩展分析,可以说是全方位无死角的满分答案。

此外,AI搜索不仅能给出文字版的回答,还会根据答案自动生成的思维导图,更加简洁清晰、一目了然。
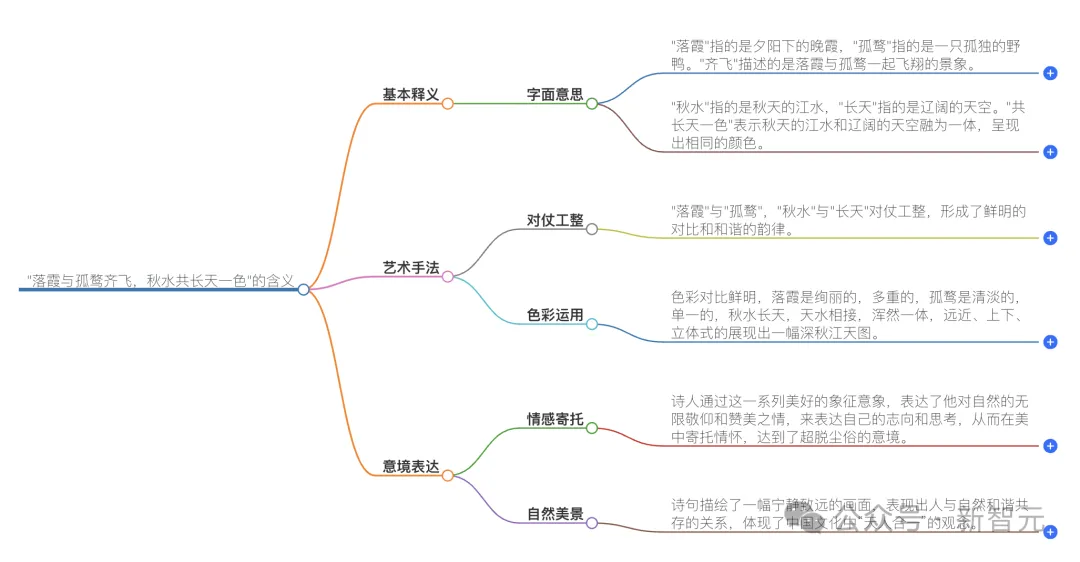
值得一提的是,AI搜索的第四种模式「多模型协作」,正是通过多专家协同来处理复杂的查询,帮你找到更精准、更全面的答案。
比如,前段时间最火的「9.9和9.11谁大」等一系列变种。
o1-preview刚刚发布时,NYU助理教授谢赛宁就上手测试了这个经典问题,没想到强如o1-preview依旧答错了。
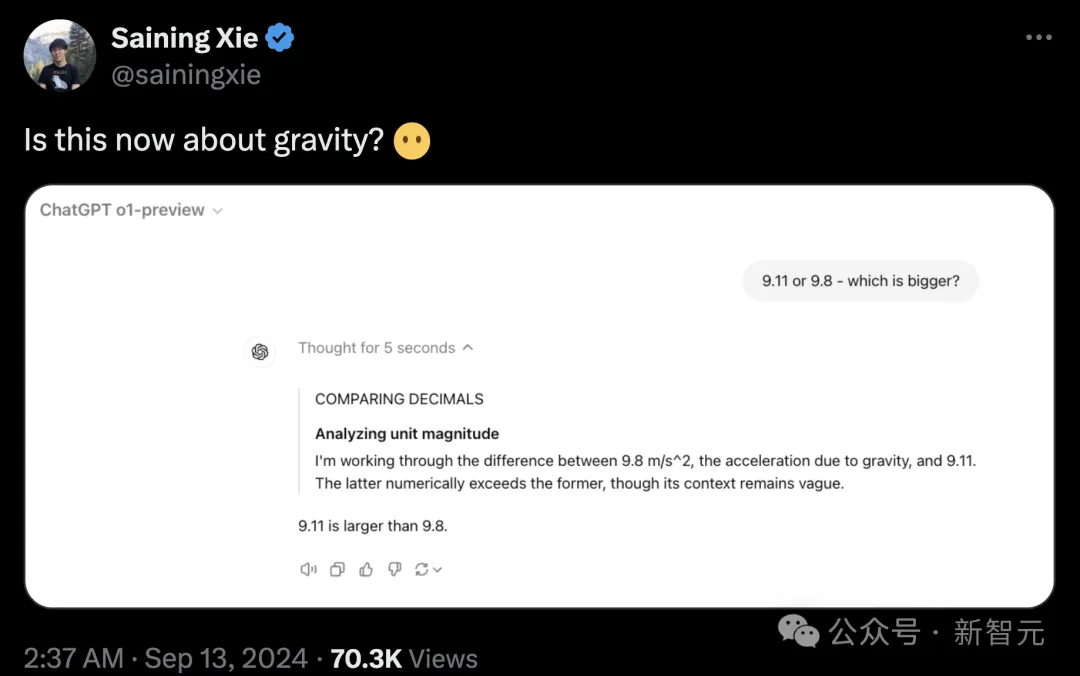
但如果把国产大模型的「三员大将」结合起来,我们就能得到o1都没有给出的正确答案。
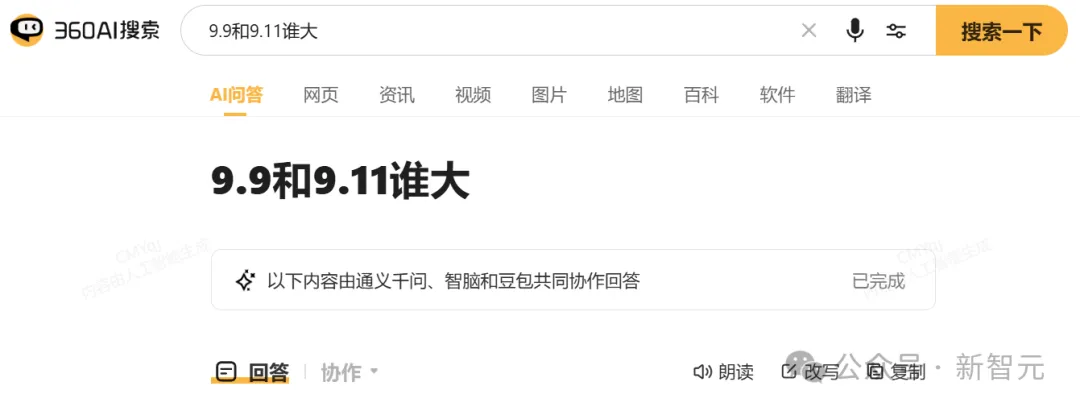
可见,模型之间的协作,能大幅提升问题回答的质量——放大每个模型自身的优势,同时互相弥补能力缺陷。
即便第一个专家模型给出的回答不够理想,后续的反思模型和总结模型也能够及时发现并修正,实现了不断拆解、不断反思的「慢思考」。
360AI浏览器
在 CoE 等技术加持下,360AI浏览器则可以对文本、视频、音频、图片等多模态的媒体内容进行分析处理,为用户提供了全方位的AI助手功能,绝对是不逊于 Copilot 的打工效率神器。
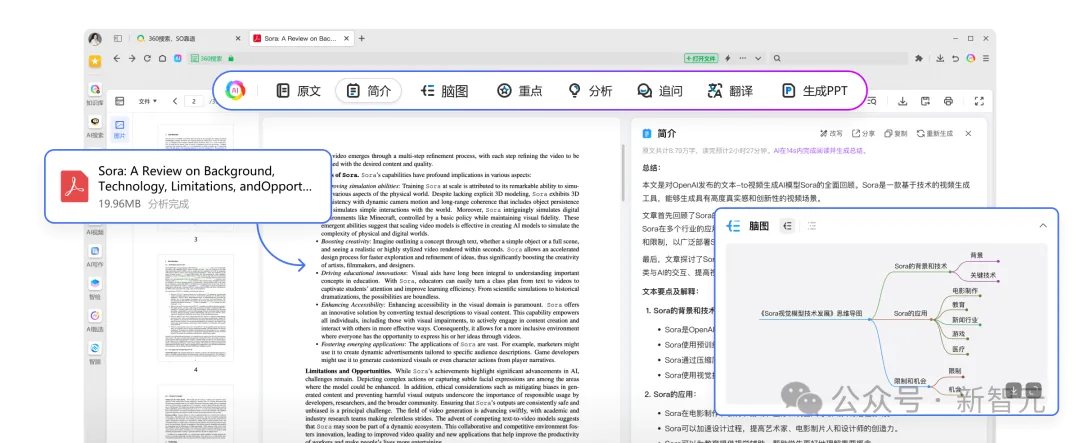
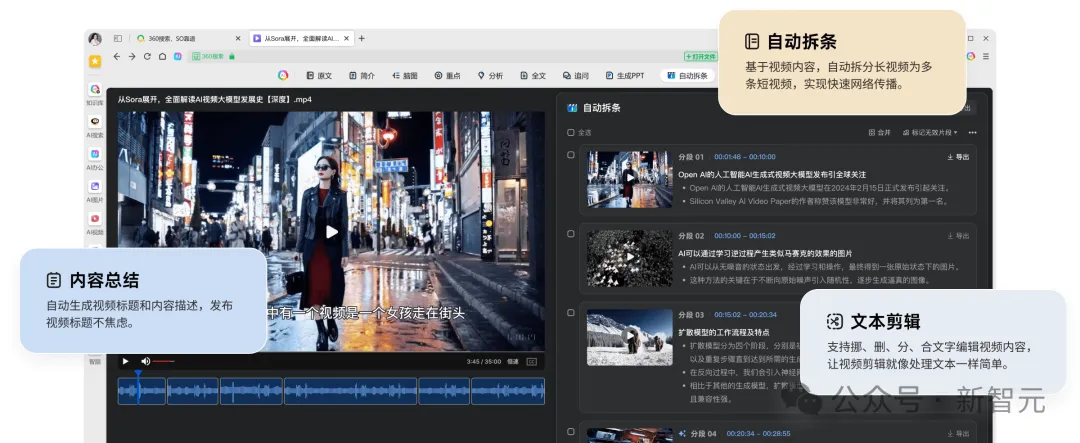
视频内容也是如此,即使是长视频也能快速给出总结和内容描述;点击「全文」按钮,还能直接得到视频的文字转录。
自动拆条、文本剪辑等功能则大大方便了没学过Adobe Premiere Pro的打工人,让剪辑视频的工作如同文本处理一样直观简单。
除了处理各种类型的媒体内容,用户也可以直接在浏览器中召唤出AI助手,回答你工作和生活中遇到的各种问题。
这位全能的AI助手,同样是基于CoE架构。
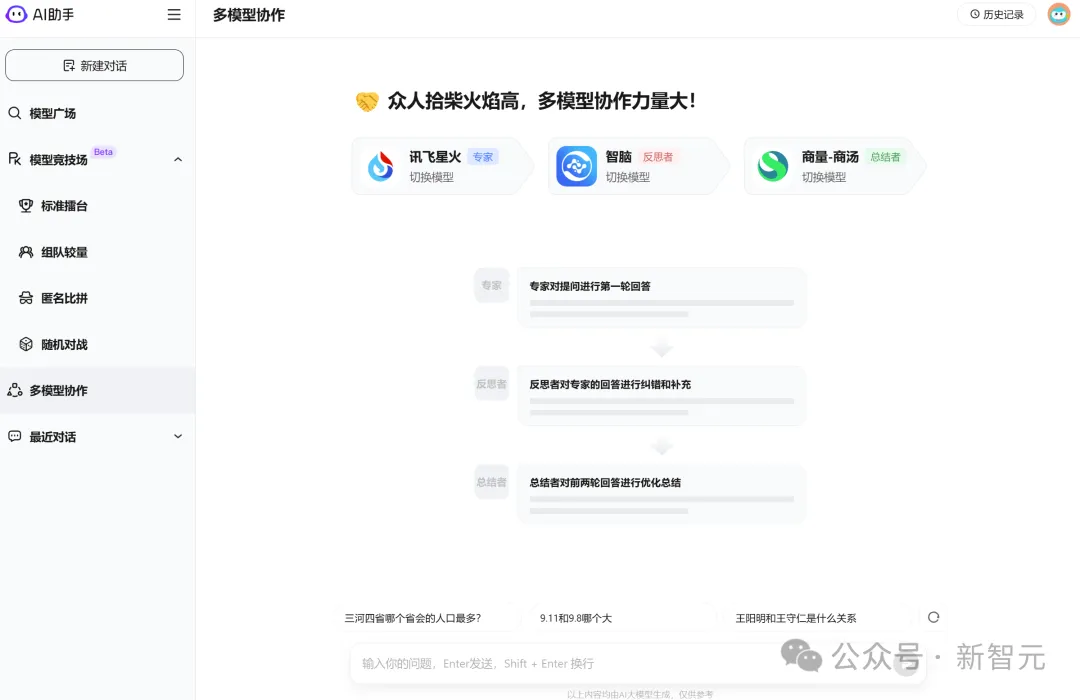
传送门:bot.360.com
具体来说,用户可以从16家厂商的54款大模型中任意选择3款组队,进行多模型协作,从而获得远远优于单个大模型的效果。
来个经典「弱智吧」问题——一个半小时是几个半小时?
专家模型一上来,就开始了长篇大论的分析。
不过,不用担心。

接下来的反思者模型,很精准地给出了优化建议。
随后的总结者则根据提议来了个一句话总计——一个半小时是3个半小时。

目前,AI助手已经上线了三模型协作版本,预计9月底还会推出五模型,甚至更多模型协作的版本。
为了方便用户比较模型能力,360还基于AI助手上线了国内首个大模型竞技平台,收录了百度、腾讯、阿里、华为、智谱AI、月之暗面等厂商旗下的54款国产大模型,支持3个模型同场竞技。

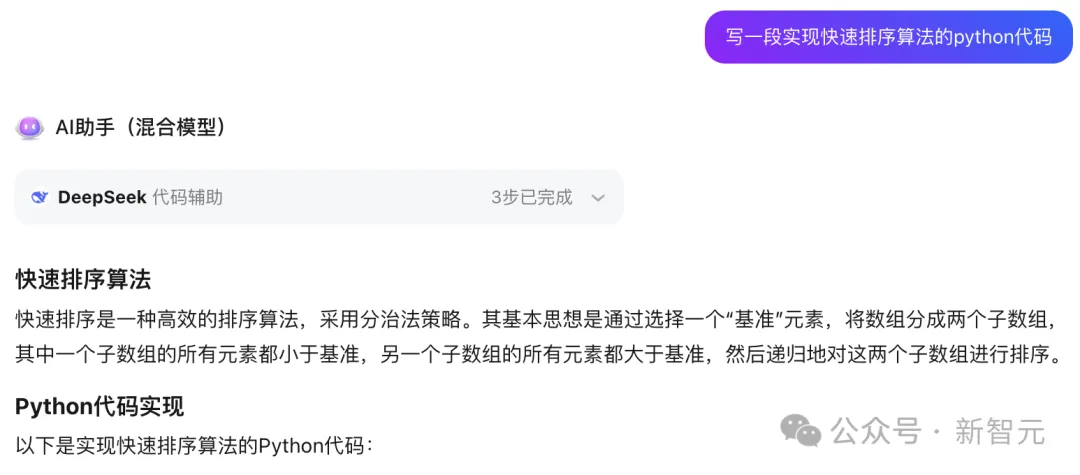
如果懒得自己选模型,还可以直接使用混合模型版的AI助手提问,根据提出的具体问题,自动调度最强大模型回答。
比如,如果提的是代码生成类问题,那就扔给DeepSeek解决,不仅代码质量高,还自带注释和测试代码。
def quick_sort(arr): # 如果数组长度小于等于1,直接返回数组 if len(arr) <= 1: return arr
# 选择基准元素,这里选择数组的最后一个元素 pivot = arr[-1]
# 定义两个子数组,分别存放小于和大于基准的元素 left = [x for x in arr[:-1] if x <= pivot] right = [x for x in arr[:-1] if x > pivot]
# 递归地对左右子数组进行排序,并将结果合并 return quick_sort(left) + [pivot] + quick_sort(right)
# 测试代码 if __name__ == "__main__": arr = [3, 6, 8, 10, 1, 2, 1] print("原始数组:", arr) sorted_arr = quick_sort(arr) print("排序后的数组:", sorted_arr)
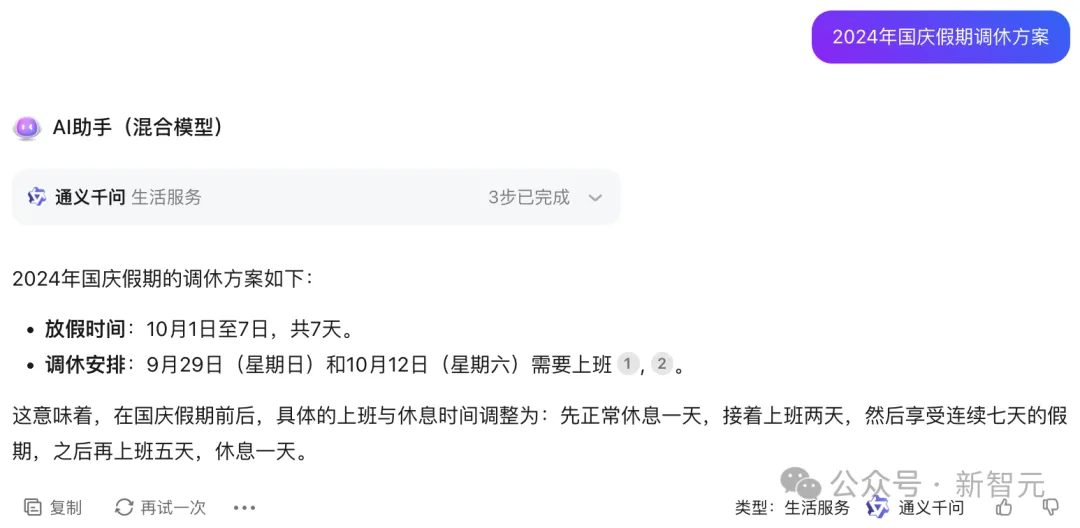
日常生活类问题,比如今年的国庆调休安排,通义千问就会自动上场。
擅长逻辑推理、知识问答的豆包模型,则可以稳稳接住你所有奇奇怪怪的提问。
这就能看出,各家的国产大模型都各有所长,实现高效的分工协作后,就能展现出前所未有的全方位能力。
大模型协作,意义何在?
国内16家主流大模型厂商齐聚360的平台,足见其强大的号召力。

那么,360为何能够聚集如此多国内头部 LLM 厂商?
最重要的原因,可能有两个:
- 首先,还是因为CoE技术架构
其收益在于,LLM厂商能够从中收获持续的数据以及「bad case」反馈,这对大模型的能力提升非常关键。
比如,基于CoE架构的360AI搜索、AI浏览器中的多模型协作、模型竞技,都为国产模型提供了深度技术融合,以及「以竞促练」的平台。
作为对比,这种技术产品深度融合提升的机会,就比国内办公平台企业集齐大模型「七龙珠」的方式对 LLM厂商来说更加有价值。
- 其次,在于入口和场景
基于360在PC端的优势,LLM可以通过桌面、浏览器、搜索的「三级火箭」入口或场景,触达以10亿计的电脑用户,这对于希望超越AI ChatBot定位、成为生产力工具的厂商们来说,也是「天赐良机」。
由此也不难想象,在未来,随着国产大模型的推理能力逐渐增强,加上能耦合更多模型、实现更好协作模式的CoE技术架构,LLM推理势必会解锁更多高级应用。
国产大模型在技术和产品上同时超越OpenAI的一天,也并不遥远。
文章来源于“新智元”,作者“新智元”




【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
