# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
AI如何成为「更强的AI」?
最关键还是,得学会「借力」。
来自蒙特利尔大学、剑桥、普林斯顿、谷歌DeepMind四大机构研究人员联手,竟发现:
GPT-4能够帮助其他LLM,在数学性能上暴增11.6%,而且是通过一种「元认知」的方式。

论文地址:https://arxiv.org/pdf/2405.12205
在这个过程中,GPT-4可以始终如一地,标记数学问题所需的解决技能。
当LLM获得了由GPT-4生成的技能标签时,它们在解决相应的数学问题时,就会得到相应地表现得更好。
有网友做了一个精辟的总结,这便是「群体智能」。

元认知,原本是指,人类对自己思维、推理过程的直观认识。
那么,大模型也具备「元认知」的能力吗?
研究人员对此,提出了一种假设,并设想是否可以通过知识引导,进一步提高LLM的能力。
其实,此前的研究已经表明,大模型表现出一些类人的特征,比如通过CoT一步一步推理。
而且,也有一些研究称,LLM具备了元认知能力。
比如,这篇来自谷歌、UCSD等机构2月论文提出了Ask-LLM,并称想要破译LLM元认知,最直接方法就是——问!

论文地址:https://arxiv.org/pdf/2402.09668
在最新研究中,作者将重点放在了AI元认知,在解决数学问题时,所应用的技能。
因为数学领域中,覆盖了人类丰富的技能目录,从简单的(变量运算、求解方程、掌握函数的概念),到复杂的(定理和证明)。
如下图所示,研究人员描述了,让GPT-4根据数学问题,所需的特定技能对数学问题进行分类的自动化过程。
这里一共划分为两个阶段:
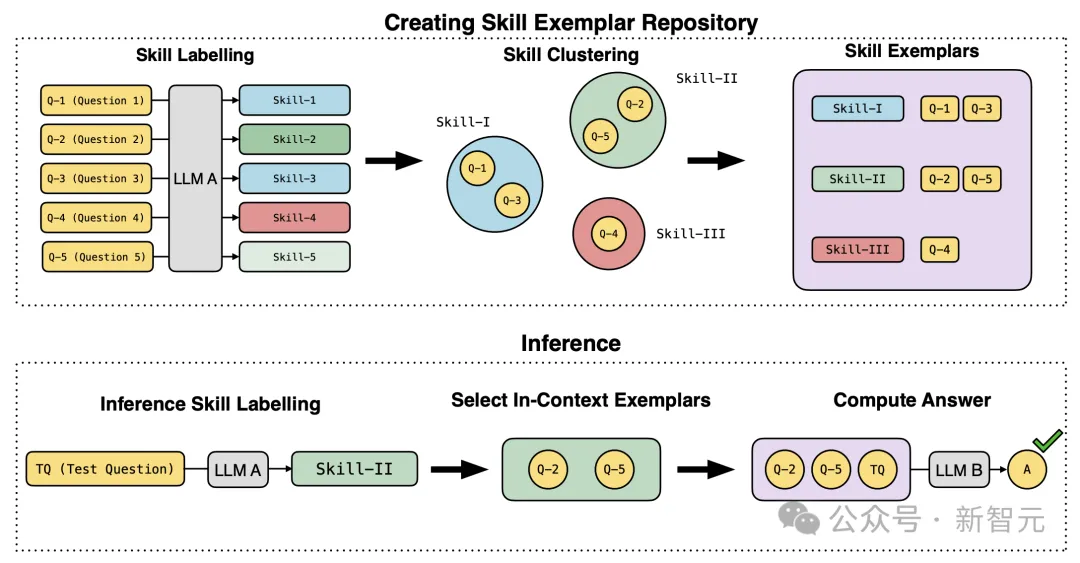
首先,创建技能示例仓库。
功能强大的LLM A会用相应地技能,标记每个问题,如下图2(左)中,提供的提示中详细介绍的那样。
接下来,LLM A要求将类似的细粒度技能,组合成广泛的技能集群,代表着复杂的技能。
这大大减少了,第一阶段的独特技能数量,如图2(中)描述的提示。
然后,大模型被要求,将训练集中的所有示例,重新分类为一种后聚类技能。
第二阶段,是推理。
在使用LLM B(其中B可能与A不同),对测试问题进行推理期间,要求LLM B使用技能示例仓库中,一项技能来标记测试问题。
接下来,研究人员从仓库中,获取具有相同技能标签的范例,并向LLM B提供主题上下文示例,以帮其解决测试问题。
举个例子,对于MATH数据集,第一阶段识别了约5000个技能,第二阶段将其减少到117个粗粒度技能。
代表粗粒度技能的随机子集例子被保留作为其技能示例。

针对不同数据集,所列出的技能表,这些技能名称由GPT-4-0613提供。

下图中,展现了一些在数学领域中的技能。
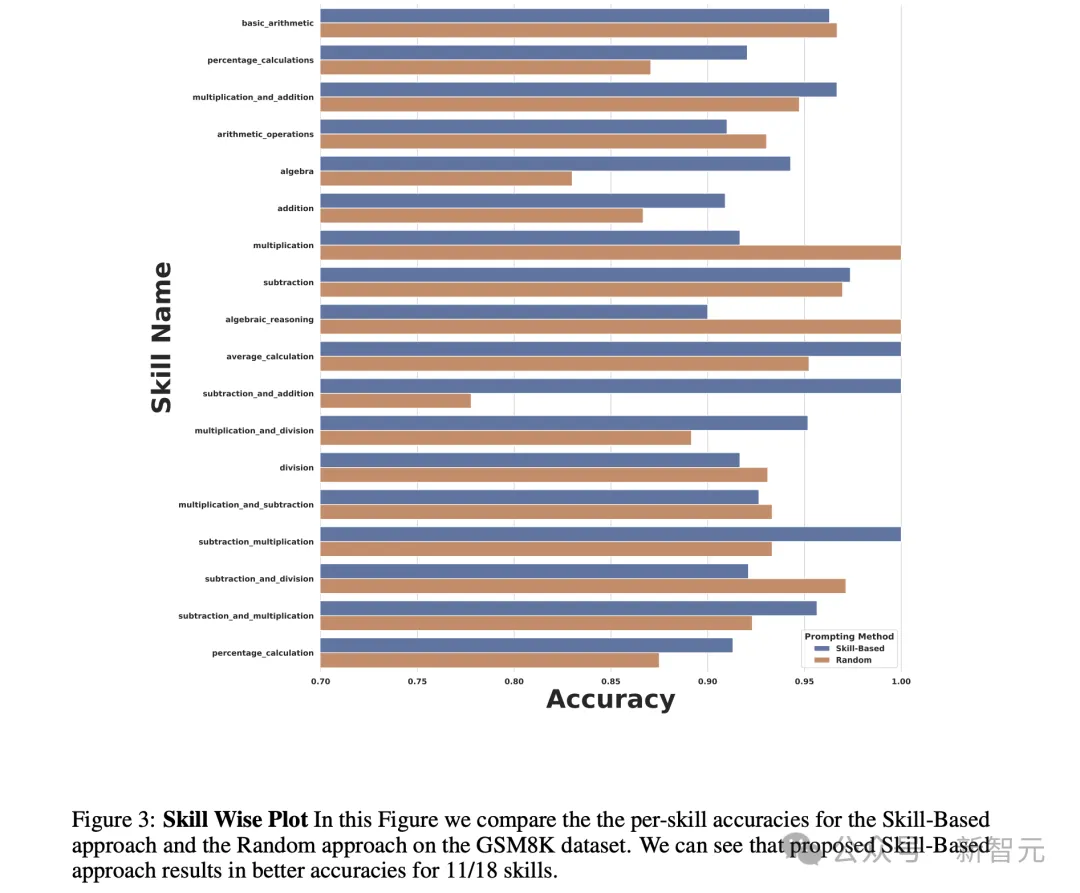
接下来,研究人员描述一种LLM在提取元认知知识的程序,这种只是以数学问题技能标注形式呈现。
结果表明,技能知识显著改善了不同数据集上,基于文本和程序的提示性能。
此外,这些技能表现出强大的可迁移性,提升其他数学数据集和LLM的数学推理能力。
具体结果如下所示。
论文中,主要研究了两种主要类型的上下文提示方法,以增强法学硕士的数学推理能力。
首先是,基于文本的提示,利用文本示例来演示解决问题的步骤,思想链(CoT)就是一个很好的例子。
其次是,程序辅助提示,使用程序来展示推理步骤,如程序辅助语言模 型 (PAL) 中所示。
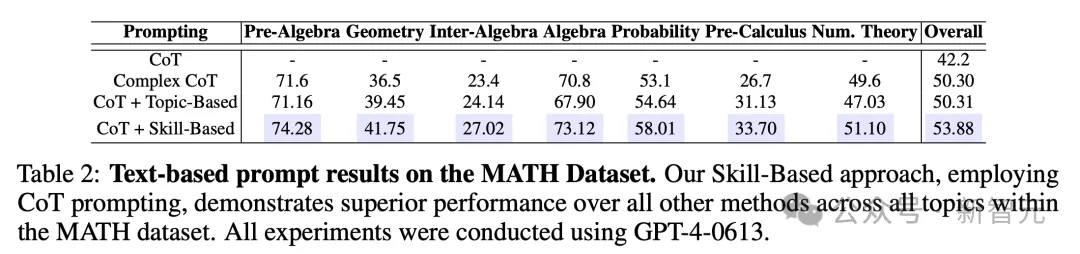
表2展示了,MATH数据集上,基于文本的提示结果。
研究人员基于技能的方法采用CoT提示,在MATH数据集中的所有话题中,表现出优于所有其他方法的性能。
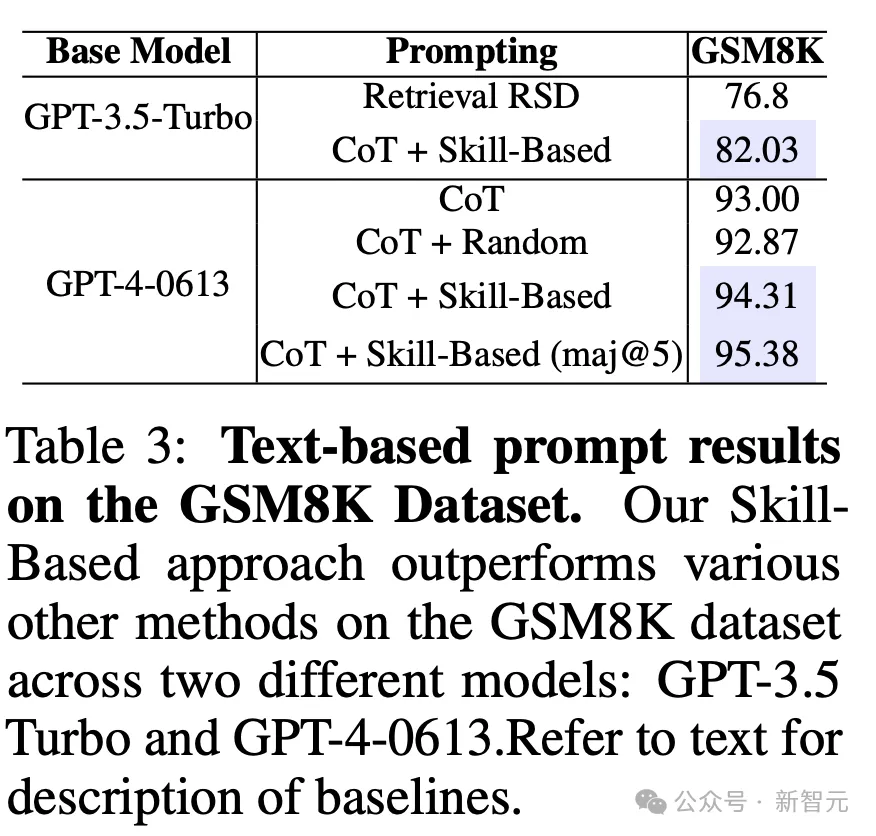
研究者利用技能示例库,解决GSM8K数据集中的测试集问题。
结果如表3所示,基于技能的方法在GSM8K数据集上的表现,优于CoT和随机基准方法,并强调了准确技能分配、相关上下文示例在有效问题解决中重要性。
此外,基于技能方法与自洽性,带来了更好的性能。
对于SC实验,研究人员从LLM中采样5个推理链,并选择最频繁的答案。
为了进一步强调所提出方法的有效性,他们将其与Retrieval-RSD方法进行比较,后者也是一种用于少样本提示的相关上下文示例选择方法。
MATH数据集的结果,如表2所示。
对于此分析,研究人员提出的方法采用简单的思想链 (CoT) 方法,其中上下文示例源自技能示例仓库。
新方法在性能上取得了显著的进步,超出了标准CoT 11.6%,令人印象深刻。
另外,新方法也要比复杂CoT好3.5%,比基于主题方法高3.5%。
这些结果,凸显了方法的有效性,特别是细粒度技能标签。
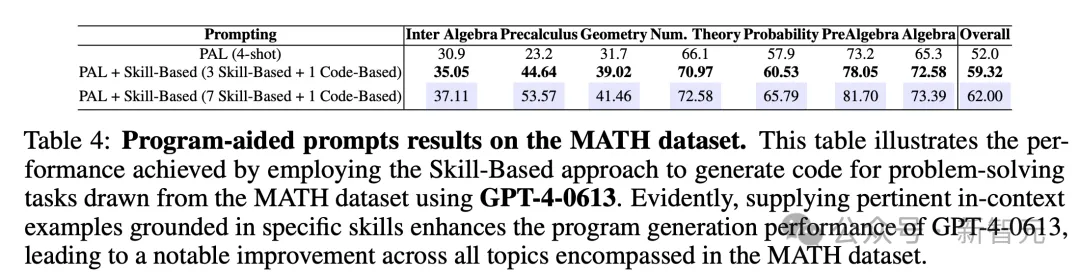
技能示例,向其他模型的迁移结果如下所示。
所有实验都使用MATH数据集在Mixtral 8 × 7B模型上进行,与标准思维链(CoT)、使用基于主题示例的CoT、使用基于技能示例的CoT、以及使用主题和技能示例的CoT加自洽性(maj@4)进行比较。
新技能的方法表现出的增强性能表明,技能可以有效地从GPT-4迁移到另一个模型。
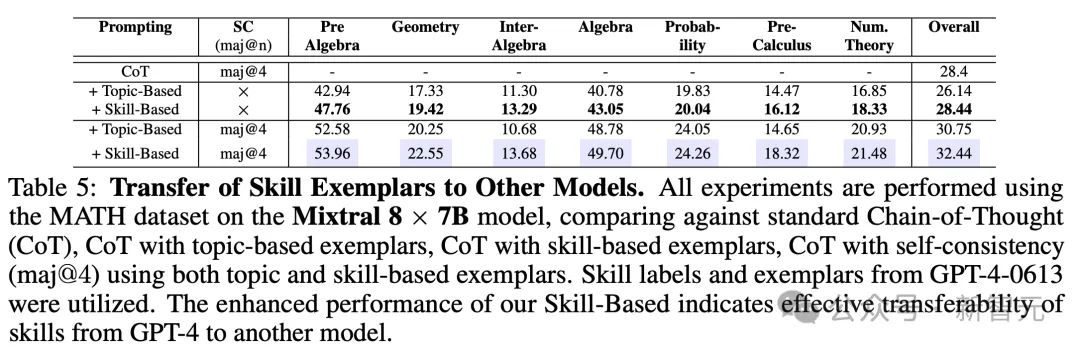
表7说明了,基于技能的方法使LLM能够有效应用相关技能的实例。
红色加亮的文本,显示了基于主题的基线在概念上的错误,而蓝色加亮的文本,则展示了娴熟而准确的技能应用。

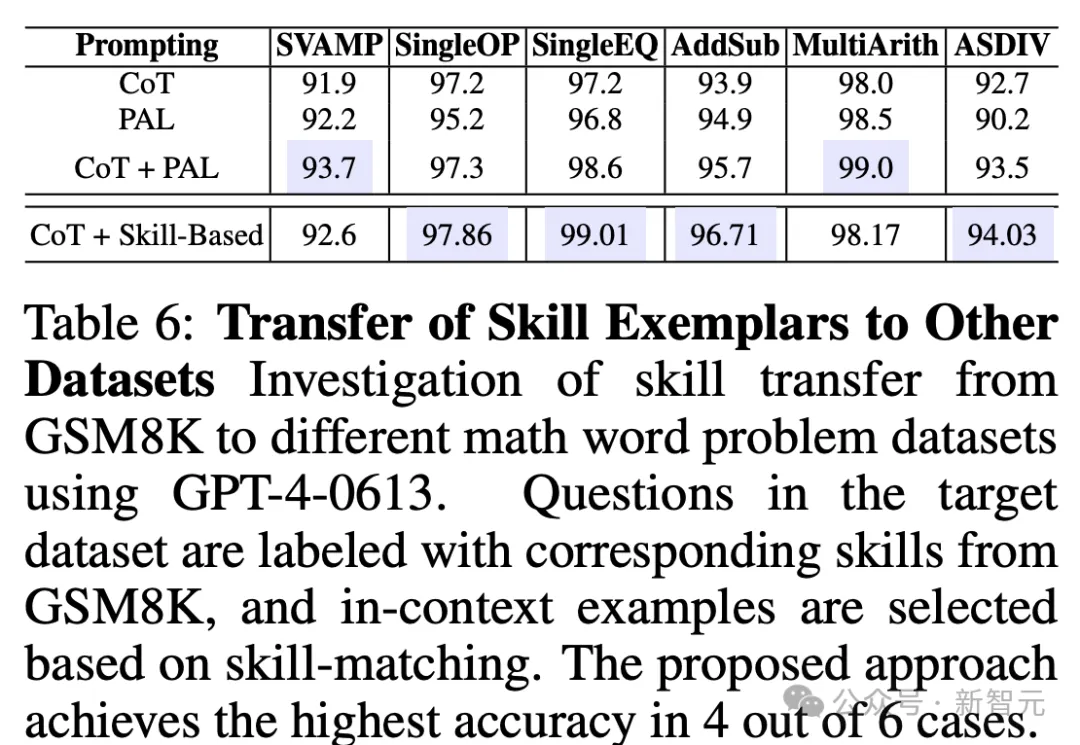
表6呈现了,新论文所提出的方法,在4个案例中实现了最高准确率。
总之,作者提出一个LLM提取元认知知识框架,其形式是根据解决问题所需的概念,对数学数据集中的问题进行分类的技能。
目前,新框架依赖于GPT-4等高级模型的可用性。
然而,技能发现过程改进了GPT-4的情境学习,这表明使用技能来微调GPT-4可能会提高其能力。
文章来源于“新智元”,作者“新智元”




【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
