# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
OpenAI最新发布的o1模型再次证明了自我纠正、显式思考过程在大模型推理中的重要性,思维链可以帮助大模型分解复杂问题,利用计算和交互来改进模型在测试时的性能。
不过,最近有多项研究结果表明,大模型在缺乏外部输入的情况下,基本上无法实现自我纠正,而现有的自我纠正训练方法要么需要多个模型,要么依赖更强大的模型或其他形式的监督信号。
Google DeepMind的研究人员发布了一种多轮在线强化学习(RL)方法 SCoRe,在完全使用自生成数据(entirely self-generated data)的情况下,显着提高了LLM的自我纠正能力。

论文链接:https://arxiv.org/pdf/2409.12917
研究人员首先验证了有监督微调 (SFT) 及其变体得到的离线模型,生成的纠正轨迹(correction traces)不足以把自我纠正能力灌输(still)给语言模型。
还可以观察到,通过 SFT 进行的训练要么会受到训练数据与模型本身回复之间分布不匹配的影响,要么会倾向于某种在测试时无效的纠正模式。
SCoRe 通过在模型本身的自生成纠正轨迹分布下进行训练,并使用适当的正则化来引导学习过程,来学习在测试时有效的自我纠正策略,而非简单地根据给定提示来拟合高奖励回复,从而解决了前面提到的难题。
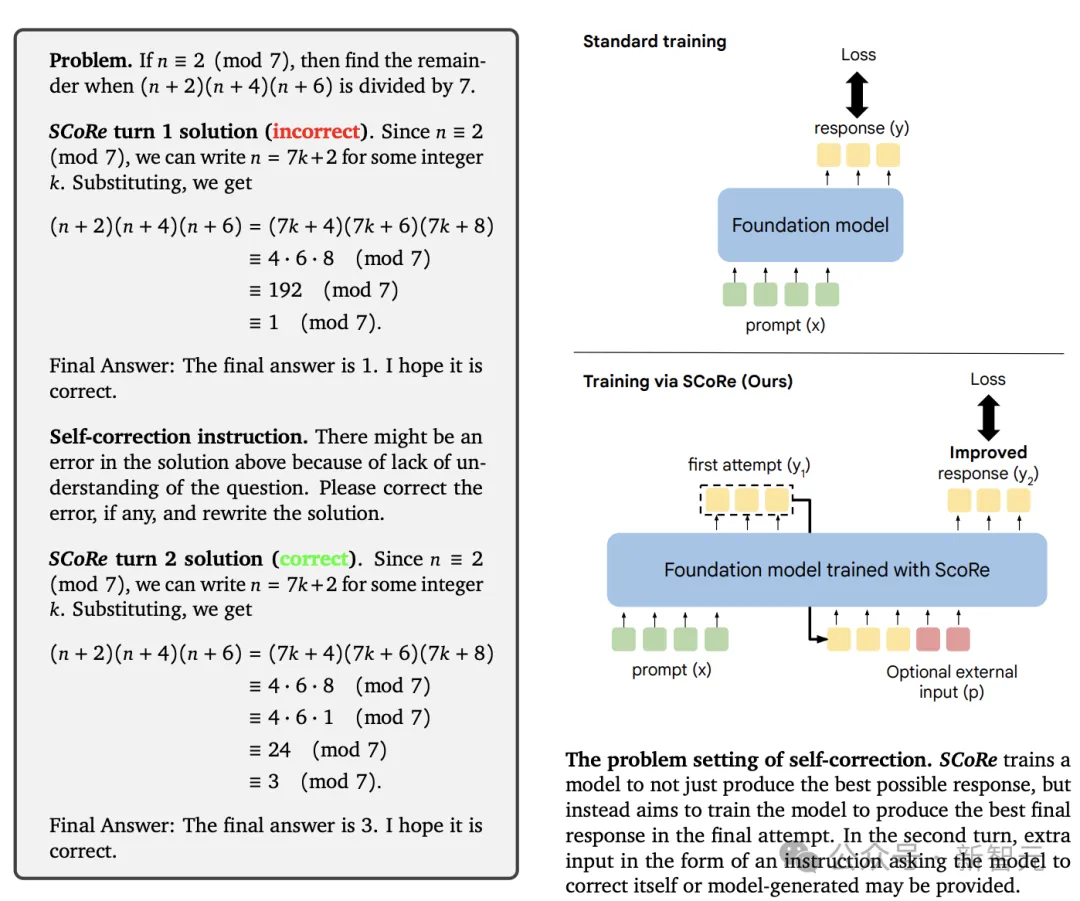
在基本模型上运行强化学习的第一阶段进行正则化,防止生成容易崩溃的策略初始化,然后使用额外奖励来放大训练期间的自我纠正信号。
在实验阶段,把SCoRe应用于Gemini 1.0 Pro和1.5 Flash模型时,该策略的自我纠正性能最高,在MATH和HumanEval基准上分别将基础模型的自我纠正性能提高了15.6%和9.1%。
之前尝试实现自我纠正的大模型要么依赖于提示工程,要么需要专门针对自我纠正进行微调模型,两种方法都有缺陷:提示工程无法有效地执行有意义的内在自我纠正,而基于微调的方法需要在推理时运行多个模型,比如需要一个额外的验证器或优化(refinement)模型,或是一个预言模型(oracle)来指导自我纠正的过程。
研究人员提出的基于强化学习实现自我纠正(SCoRe, Self-Correction via Reinforcement Learning)只需要训练一个模型,既可以对推理问题产生回复,也可以在没有接收到任何预言信号(oracle)反馈的情况下纠正错误,SCoRe完全在自生成的数据上训练,而不需要任何预测器来指导模型。
文中首先研究了现有基于微调策略在这种设置中的失败模式,可以观察到,在多轮自我纠正轨迹上运行有监督微调,结合拒绝采样,通常会放大模型的偏见,虽然与基础模型的自我纠正行为相比有显著改进,但仍未能达到积极的自我修正率,并且与第一次尝试相比,第二次尝试的表现更差。
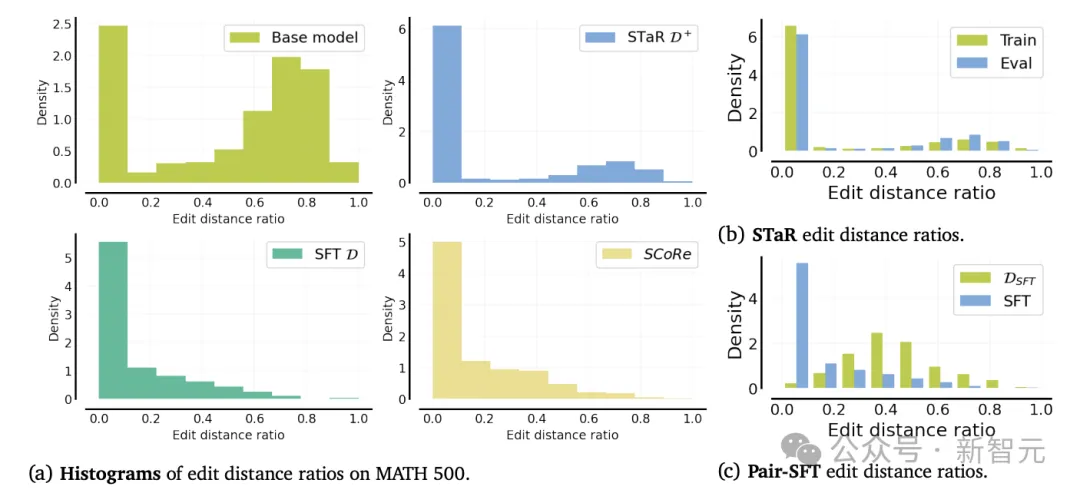
通过对训练过的模型进行探测,研究人员发现这些失败在很大程度上源于有监督微调放大了基础模型的初始偏见,导致模型只能对第一次尝试回复进行微小的编辑变化。
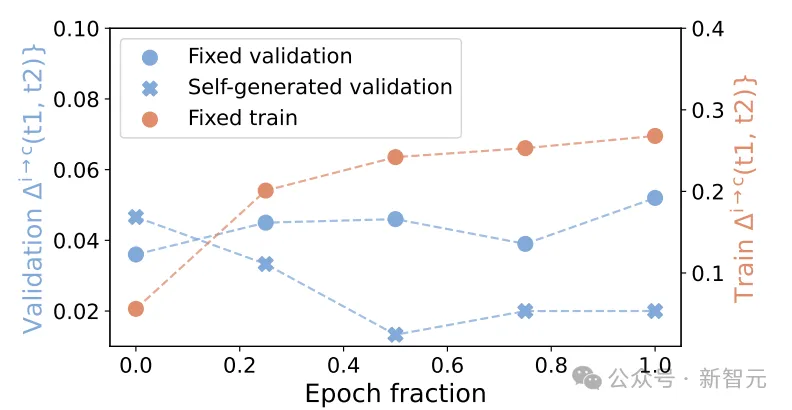
SCoRe通过使用在线多轮强化学习(RL)来解决SFT方法的缺陷,即在自生成的数据上运行多轮RL,以避免训练和推理之间分布不匹配。
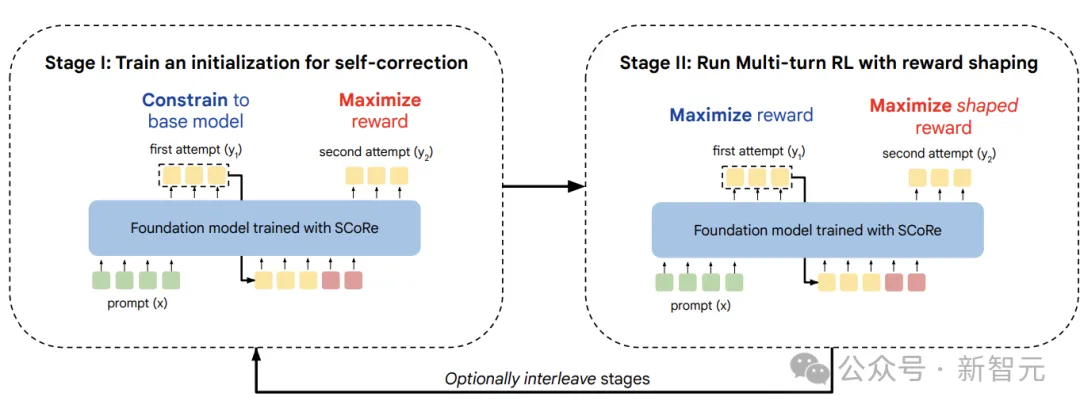
为了避免在基于策略的数据上训练时学习最小编辑策略的失败模式,研究人员分两个阶段训练SCoRe,每个阶段都通过正则化学习过程来防止行为崩溃(collapse its behavior)。
第一阶段
SCoRe第一阶段的目标是通过提高基础模型对第二次尝试回复的覆盖范围,从而获得良好的模型初始化,以便后续的自我纠正训练不易受到STaR/SFT崩溃的影响。
由于SFT训练模型仅依赖于一种修正行为模式,因此SFT初始化不会生成有信息量和探索性的学习轨迹,所以研究人员不使用SFT来初始化RL训练,而是开发第一阶段来产生一个不易崩溃的单独初始化。
为此,需要明确地对基础模型进行微调,以在第二次尝试时产生高奖励的纠正信号,同时通过使用KL散度将第一次尝试的回复分布约束得尽可能接近基础模型,限制模型不会改变第一次尝试回复的内容。
虽然这个策略看起来是次优的,但第一阶段的主要目标是减少基础模型简单地耦合第一次和第二次尝试分布的偏见,防止在实际运行多轮RL时陷入局部最优,优化目标为:
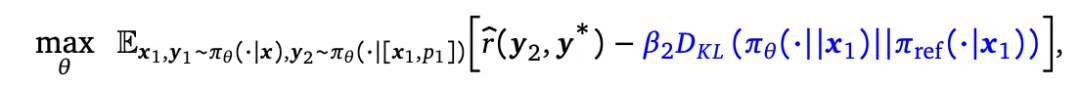
第二阶段
运行多轮强化学习来优化两次尝试的奖励,同时使用一个额外奖励项(reward bonus term)来激励模型以改进回复。初始化和额外奖励都可以确保模型不只是简单地学会在第一次生成的时候模仿最佳回复内容,然后再进行一些微小的文本编辑。
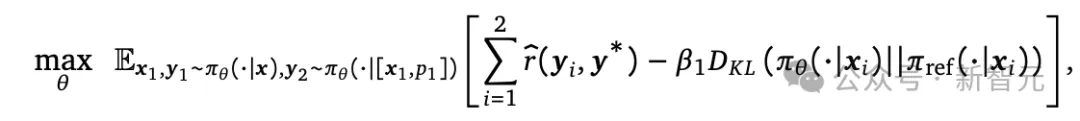
从效果来看,SCoRe能够从基础模型中引出知识,以实现积极的自我修正。
研究人员的目标是证明SCoRe在通过训练自身生成的数据可以有效地教导大型语言模型来纠正自己的错误,并深入分析SCoRe的每个组成部分对于这种能力的贡献。
主要关注数学和编程任务:MATH数据集上的数学问题,以及MBPP和HumanEval上的代码生成任务。
评估协议和指标
研究人员主要报告了自我纠正的准确性,有两次连续的问题尝试,即一轮自我纠正。
对于MBPP的评估协议,文中报告了MBPP-R的结果。MBPP-R是一个离线修复任务,需要修正PaLM 2生成的错误的第一次尝试程序。
模型
MBPP上的所有实验使用微调Gemini 1.0 Pro;MATH的实验微调Gemini 1.5 Flash
对于所有评估结果,使用贪婪解码(即温度0)的推理计算扩展,将温度设置为0.7
对于每个训练方法,使用固定的模型样本和梯度更新budget,在运行期间不改变学习率和批量大小等超参数;在强化学习时,选择训练奖励最高的检查点。
评估提示
在MATH上使用零样本CoT提示进行评估,在HumanEval上使用零样本提示进行评估,并在MBPP上使用三样本提示进行第一次尝试训练样本;

在第二次尝试时,使用一个不透露之前答案正确性的指令,要求模型尝试推断其第一次尝试回复中是否存在错误,如果存在错误,需要重写回复。
对比基线
基于提示的方法Self-Refine;基于微调的方法Pair-SFT及多轮STaR,通过最小化合成配对纠正轨迹和成功纠正轨迹上的负对数似然来微调模型。
基准结果
MATH
实验结果显示,SCoRe在直接和自我纠正准确率方面都表现出显著更强的性能。
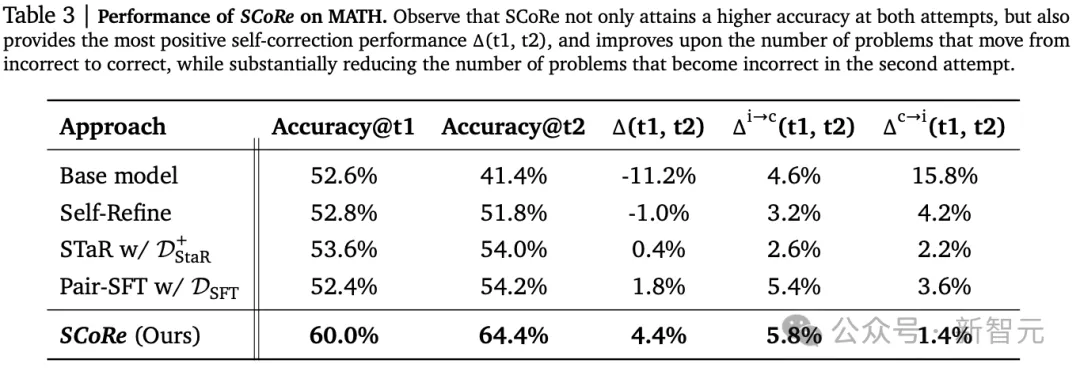
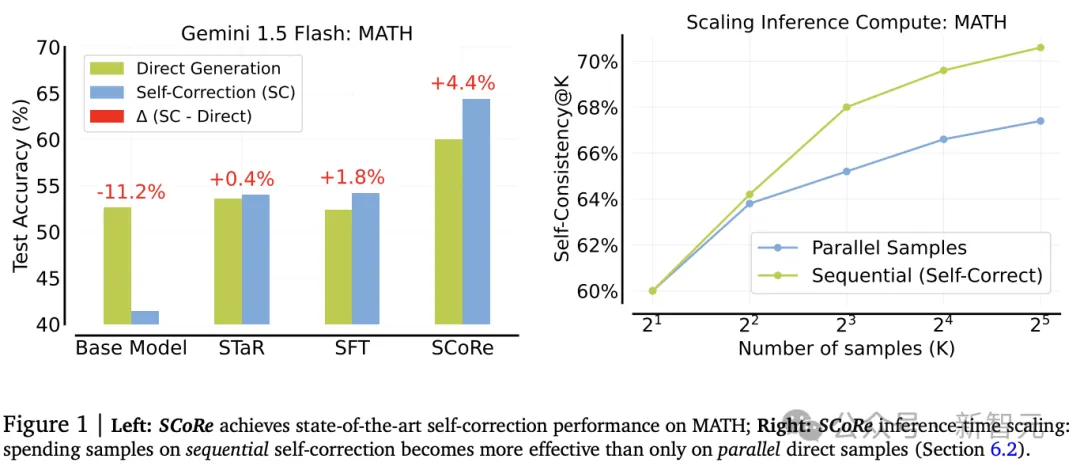
值得注意的是,内在自我纠正增益Δ(t1, t2)为4.4%,是第一个显著为正的增量,并且准确率Accuracy@t1更高,所以需要修正的错误问题更少。
与基础1.5 Flash模型相比,SCoRe将Δ(t1, t2)提高了15.6%,将Accuracy@t2提高了23.0%,比最接近的基线Pair-SFT分别提高了10.2%和2.6%
通过观察问题从第一次尝试不正确变为第二次尝试正确的频率,可以看到SCoRe提高了修正错误答案的比率(14.5% vs 基础模型9.5%),并减少了改变正确答案的比例。
代码生成
研究人员发现SCoRe不仅实现了更高的自我纠正性能,而且还具有强大的离线修复性能。
对于MBPP-R,发现SCoRe将基础模型的准确率从47.3%提高到60.6%,与GPT-3.5到GPT-4之间的差距相当(分别为42.9%和63.2%)。
虽然模型仅在MBPP上进行训练,仍然可以观察到SCoRe有效地泛化到了HumanEval基准,实现了12.2%的内在自我纠正增量,比基础模型高出9%
相比之下,Pair-SFT在静态纠正任务MBPP-R上的表现几乎和SCoRe一样好,但在自我纠正设置评估时实际上降低了基础模型的性能,证明了自我纠正中基于策略采样的重要性。
文章来源于“新智元”,作者“新智元”




【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
