# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
近日,来自 CMU 的 Catalyst Group 团队发布了一款 PyTorch 算子编译器 Mirage,用户无需编写任何 CUDA 和 Triton 代码就可以自动生成 GPU 内核,并取得更佳的性能。
随着 GPU 加速器的不断发展以及以大语言模型为代表的生成式 AI 应用的不断推广,通过开发高性能 GPU 内核来优化 PyTorch 程序的计算效率变得越来越重要。目前,这项任务主要由专门的 GPU 专家来完成。在 NVIDIA CUDA 或 AMD ROCm 中编写高性能 GPU 内核需要高水平的 GPU 专业知识和大量的工程开发经验。目前的机器学习编译器(如 TVM、Triton 和 Mojo)提供了一些高级编程接口,以简化 GPU 编程,使用户可以使用 Python 而非 CUDA 或 ROCm 来实现 GPU 内核。
然而,这些语言仍然依赖用户自行设计 GPU 优化技术以达到更高的性能。例如,在 Triton 中实现一个 FlashAttention 内核大约需要 700 行 Python 代码(在 CUDA 中需要大约 7,000 行 C++ 代码)。在这些程序中,用户需要手动划分线程块之间的工作负载,组织每个线程块内的计算,并管理它们之间的同步与通信。

用 Triton 实现的 FlashAttention 算子
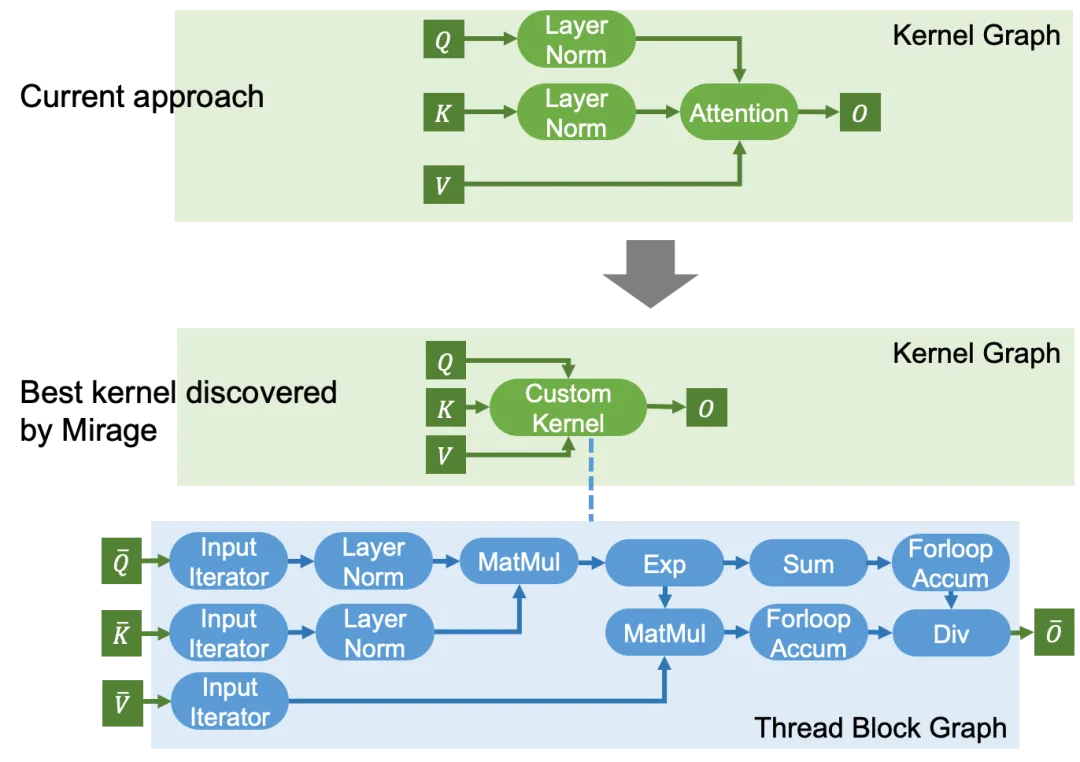
能否在不使用 CUDA/Triton 编程的情况下就获得高效的 GPU 内核呢?基于这一动机,来自卡内基梅隆大学的 Catalyst Group 团队发布了 Mirage 项目,基于 SuperOptimization 技术(https://arxiv.org/abs/2405.05751),为 PyTorch 自动生成高效 GPU 内核算子。例如,对于一个 FlashAttention 算子,用户只需编写几行 Python 代码来描述注意力(Attention)的计算过程而无需了解 GPU 编程细节,如下所示:
# Use Mirage to generate GPU kernels for attention
import mirage as mi
graph = mi.new_kernel_graph ()
Q = graph.new_input (dims=(64, 1, 128), dtype=mi.float16)
K = graph.new_input (dims=(64, 128, 4096), dtype=mi.float16)
V = graph.new_input (dims=(64, 4096, 128), dtype=mi.float16)
A = graph.matmul (Q, K)
S = graph.softmax (A)
O = graph.matmul (S, V)
optimized_graph = graph.superoptimize ()
Mirage 会自动搜索可能的 Attention GPU 内核实现,搜索空间不仅包括现有的手动设计的注意力内核(如 FlashAttention 和 FlashDecoding),还包括在某些场景中比目前的手写版本快多达 3.5 倍的其他实现。Mirage 生成的 GPU 内核可以直接在 PyTorch 张量上操作,并可以在 PyTorch 程序中直接调用。
import torch
input_tensors = [
torch.randn (64, 1, 128, dtype=torch.float16, device='cuda:0'),
torch.randn (64, 128, 4096, dtype=torch.float16, device='cuda:0'),
torch.randn (64, 4096, 128, dtype=torch.float16, device='cuda:0')
]
# Launch the Mirage-generated kernel to perform attention
output = optimized_graph (input_tensors)
与使用 CUDA/Triton 编程相比,Mirage 提供了一种新的编程范式,包含三个主要优势:
更高的生产力:随着 GPU 架构日新月异,现代 GPU 编程需要持续学习大量的专业知识。Mirage 的目标是提高机器学习系统工程师的生产力 —— 他们只需在 PyTorch 层面描述所需的计算,Mirage 便会自动生成适用于各种 GPU 架构的高性能实现。因此,程序员不再需要手动编写 CUDA/Triton 或特定架构的低级代码。
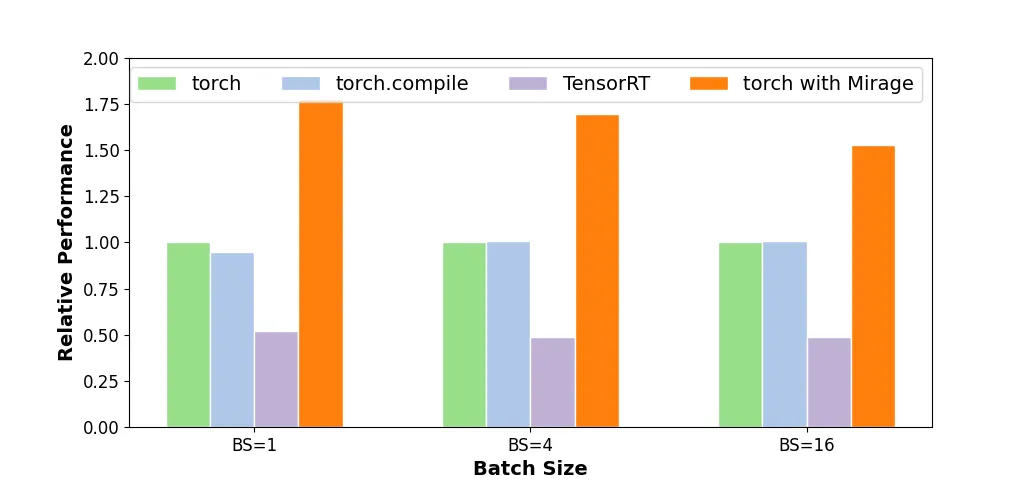
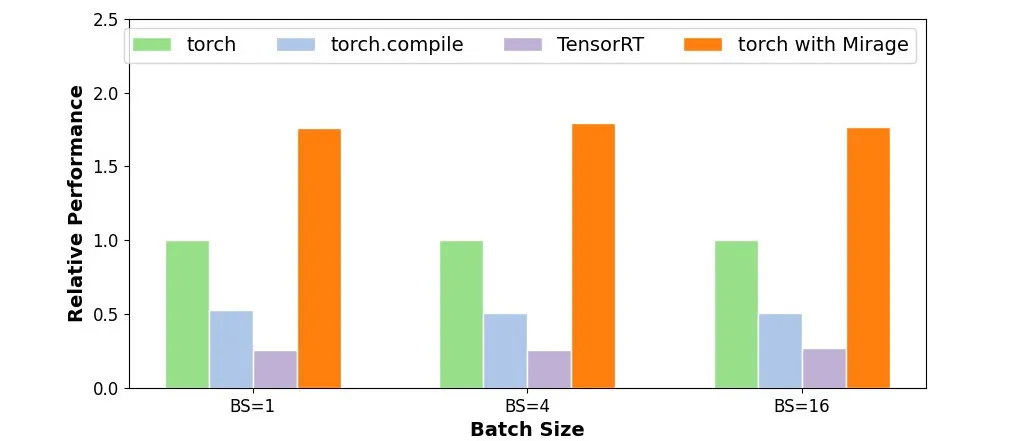
更好的性能:目前手动设计的 GPU 内核由于无法充分探索和利用各种 GPU 优化技术,往往只能达到次优性能。Mirage 可以自动搜索与输入的 PyTorch 程序功能等价的潜在 GPU 实现,探索并最终发现性能最优的内核。在多个 LLM/GenAI 基准测试中的测试结果显示,Mirage 生成的内核通常比 SOTA 的专家人工编写或编译器生成的替代方案快 1.2 至 2.5 倍。
更强的正确性:手动实现的 CUDA/Triton GPU 内核容易出错,而且 GPU 内核中的错误难以调试和定位,而 Mirage 则利用形式化验证(Formal Verification)技术自动验证生成的 GPU 内核的正确性。
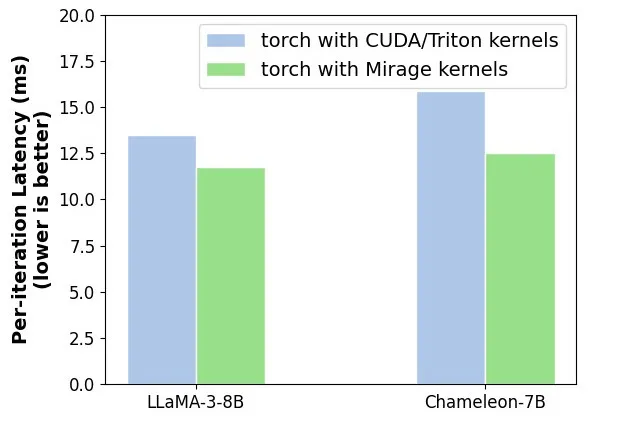
LLaMA-3-8B 和 Chameleon-7B 端到端推理延迟对比(NVIDIA A100,batch size=1,context length=4K),相比于 CUDA/Triton 的实现,Mirage 可以实现 15-20% 的加速
GPU 计算的内核函数以单程序多数据(SPMD)方式在多个流处理器(SM)上同时运行。GPU 内核(Kernel)借助由线程块(Thread Block)组成的网格结构来组织其计算,每个线程块在单个 SM 上运行。每个块进一步包含多个线程(Thread),以对单独的数据元素进行计算。GPU 还拥有复杂的内存层次结构,以支持这种复杂的处理结构。每个线程都有自己的寄存器文件(Register File),以便快速访问数据。线程块内的所有线程可以访问一个公共的共享内存(Shared Memory),这有助于它们之间高效的数据交换和集体操作。最后,内核内的所有线程可以访问分配给整个 GPU 的大型设备内存(Device Memory)。

GPU 计算架构和编程抽象示意图

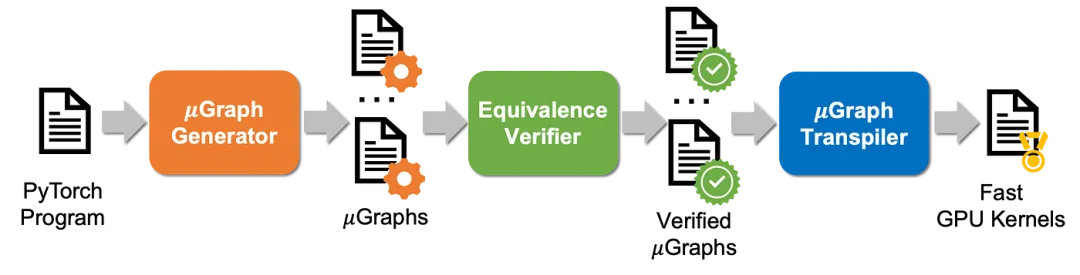
Mirage 工作流示意图

在多个 LLM/GenAI 基准测试中的测试结果显示,Mirage 生成的内核通常比现有的手写或编译器生成的内核快 1.2 至 2.5 倍。接下来,本文以 LLM 中的 Transformer 架构为例,展示现有系统中缺失的几项 GPU 程序优化技术:
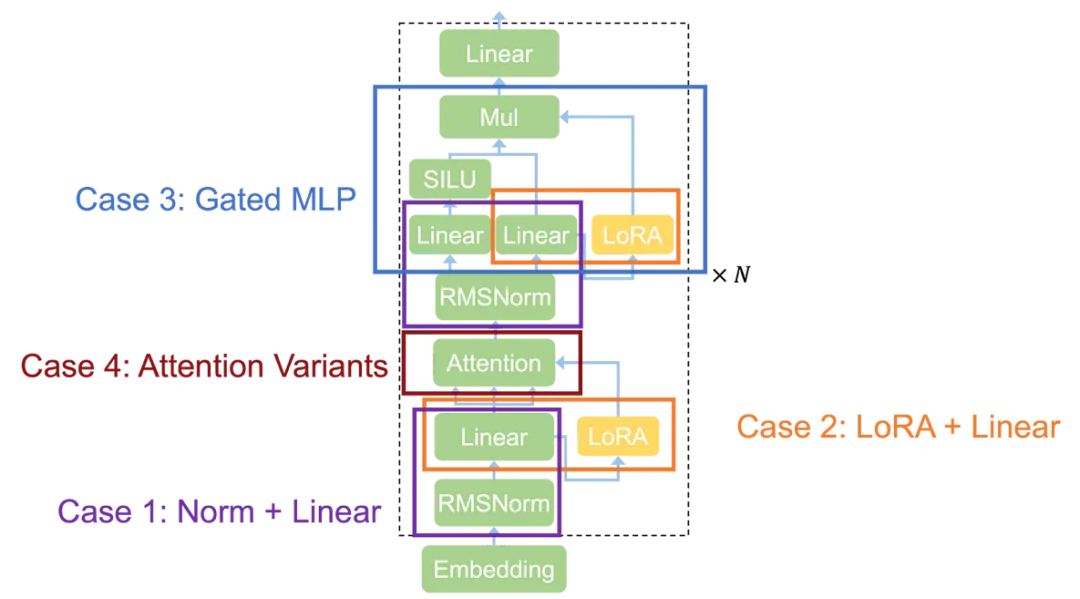
Transformer 架构示意图
归一化(Normalization)操作,如 LayerNorm、RMSNorm、GroupNorm 和 BatchNorm,广泛应用于当今的机器学习模型。当前的机器学习编译器通常在独立的内核中启动归一化层,因为归一化涉及到归约和广播,难以与其他计算融合。然而,Mirage 发现,大多数归一化层可以通过进行适当的代数变换,与后续的线性层(如 MatMul)融合。

Normalization + Linear 现有内核 v.s. Mirage 发现的内核
Mirage 发现的自定义内核利用了 RMSNorm 中的除法和 MatMul 中的乘法的可交换性,将除法移到 MatMul 之后。这一变换保持了功能等价性,同时避免了中间张量 Y 的实例化。该内核的性能比单独运行这两个操作快 1.5 到 1.7 倍。
Normalization + Linear 内核性能对比
LoRA 广泛用于预训练模型的微调场景,以适配到特定领域和任务。这些 LoRA 适配器通常会被插入到模型的线性层中,引入额外的矩阵乘法。现有系统通常为原始矩阵乘法和 LoRA 中的两个矩阵乘法启动独立的内核,从而导致较高的内核启动开销。

LoRA+Linear 现有内核 v.s. Mirage 发现的内核
如上图所示,Mirage 发现了一个将三个矩阵乘法和随后的加法融合为单个内核的内核。这是通过将计算重组为两个线程块级别的矩阵乘法实现的,利用了以下代数变换:W×X+B×A×X=(W|B)×(X|(A×X)),其中的两个拼接操作不涉及任何计算,而是通过在 GPU 共享内存中更新张量偏移量来完成。Mirage 发现的内核比现有系统中使用的内核快 1.6 倍。
LoRA+Linear 内核性能对比
Gated MLP 层目前在许多 LLM 中使用(如 LLAMA-2、LLAMA-3 及其变体),它的输入张量 X 与两个权重矩阵相乘,输出结果被组合以产生最终结果。Mirage 发现了一个内核,该内核执行两个矩阵乘法、SiLU 激活以及随后的逐元素乘法,从而减少了内核启动开销和对设备内存的访问。

Gated MLP 现有内核 v.s. Mirage 发现的内核

Gated MLP 内核性能对比
如今的大多数 LLM 基于注意力及其变体,虽然现有系统通常提供高度优化的注意力实现,如 FlashAttention、FlashInfer 和 FlexAttention,但支持注意力变体通常需要新的自定义内核。下面用两个例子来展示 Mirage 如何为非常规注意力计算发现自定义 GPU 内核。
Case 4.1: Attention with Query-Key Normalization
许多最近的 LLM 架构(包括 Chameleon、ViT-22B 等)在 LLaMA 架构中引入了 QK-Norm 来缓解训练过程中的数值发散问题。QK-Norm 在注意力之前对 Query 和 Key 向量应用 LayerNorm 层。现有注意力实现中并不支持这些额外的归一化层,并且它们还需要作为独立内核启动。
QK-Norm 注意力现有内核 v.s. Mirage 发现的内核
对于在注意力之前和 / 或之后引入计算的注意力变体,这些计算可以与注意力融合以提高 GPU 性能,而这需要自定义内核。对于带有 QK-Norm 的注意力,Mirage 发现了上述内核来融合计算,从而避免在 GPU 设备内存中实例化中间结果。这个自定义内核还对注意力进行了现有的 GPU 优化,实现了 1.7 至 2.5 倍的性能提升。
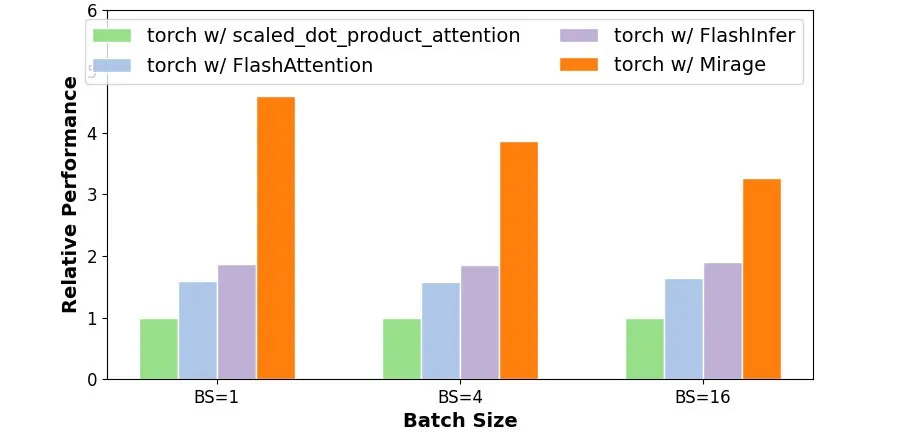
QK-Norm 注意力内核性能对比
Case 4.2: Multi-Head Latent Attention

MLA 的现有内核 v.s. Mirage 发现的内核
另一个常用的注意力变体是 MLA(Multi-Head Latent Attention),它将注意力的 KV Cache 压缩为一个向量,以减少存储 KV Cache 的内存开销。这一变化还在注意力之前引入了两个线性层,如下图所示。与 QK-Norm 类似,现有注意力实现中并不支持这些额外的归一化层,同样需要作为独立内核启动,而 Mirage 可以将线性层和注意力融合为一个单独的自定义内核。
Mirage 项目的长期目标是希望能够让未来的 AI 开发者无需学习 CUDA 或者 Triton 等复杂的 GPU 编程语言,只需指定所需的数学操作,就能在 GPU 上轻松实现 AI 模型。通过利用 Mirage 的 SuperOptimization 技术,各种计算任务可以自动转换为高度优化的 GPU 实现。随着 LLM 和其他生成式 AI 应用的飞速发展,在各种实际部署场景都需要高效的 GPU 支持,降低 GPU 编程门槛并提高程序效率也愈发重要。
文章来自于微信公众号“机器之心”




【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
