# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
这个假期有群友咨询我,不同的LLM执行相同的Prompt时,输出的内容为什么差异显著 ?恰巧,Mila、谷歌DeepMind和微软的研究团队近期联合发布了一项重要研究成果,揭示了LLM在推理能力上存在的显著差异。这项研究不仅挑战了我们对LLM推理能力的认知,也提醒我们在开发AI应用时,LLM的选择上要多考虑一些因素,尤其是需要注意Prompt的敏感性和一致性。


长期以来,业界普遍认为大型语言模型已经"掌握"了小学数学,特别是在GSM8K基准测试上的出色表现更是强化了这一观点。然而,这种表面上的"掌握"是否真的反映了模型对基础数学概念的深入理解?还是仅仅是表面模式识别的结果?带着这些疑问,研究团队设计了一个巧妙的实验——组合式GSM(Compositional GSM)测试。
研究团队创造性地提出了组合式GSM测试。这个测试将两个GSM8K测试问题串联在一起,使得第二个问题的答案依赖于正确解答第一个问题。这种设计巧妙地提高了问题的复杂度,同时保持了与原始GSM8K相同的数学难度水平。
具体来说,组合式GSM测试包含以下特点:
1. 每个测试项由两个问题(Q1和Q2)组成,这两个问题来自原始GSM8K测试集的1200个样本子集。
2. Q1的答案作为变量X在Q2中使用。
3. 最终答案通过将X代入Q2并解决得出。
4. 研究者精心选择了Q1和Q2,确保新的最终答案是一个正整数,且与原始Q2的答案不同但相近。
这种设计不仅保持了问题的逻辑性和合理性,还确保了组合式GSM测试与原始GSM8K测试在最终答案分布上的相似性。
研究团队对多个主流的开源和闭源LLM进行了全面评估,包括Gemini、Gemma2、LLAMA3、GPT、Phi、Qwen2.5和Mistral系列。评估结果揭示了以下关键发现:
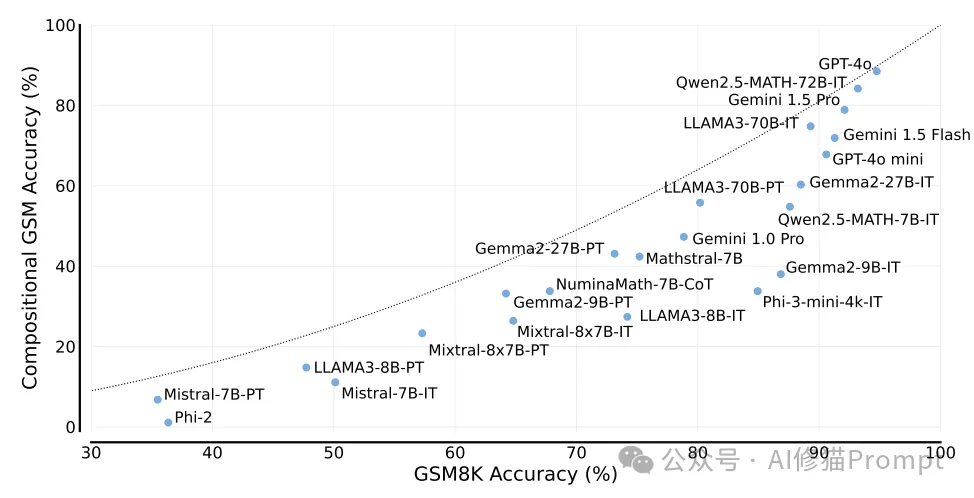
1. 普遍存在的推理能力差距
大多数模型在GSM8K和组合式GSM测试之间表现出明显的性能差距。这一差距不仅削弱了模型的可靠性,也暴露了其推理能力的局限性。研究者引入了"推理差距"(Reasoning Gap)的概念来量化这种差异:
推理差距 Δ = S_comp - S_1 × S_2
其中S_comp是模型在组合式GSM测试上的准确率,S_1和S_2分别是模型在原始GSM8K测试的Q1和Q2部分的准确率。
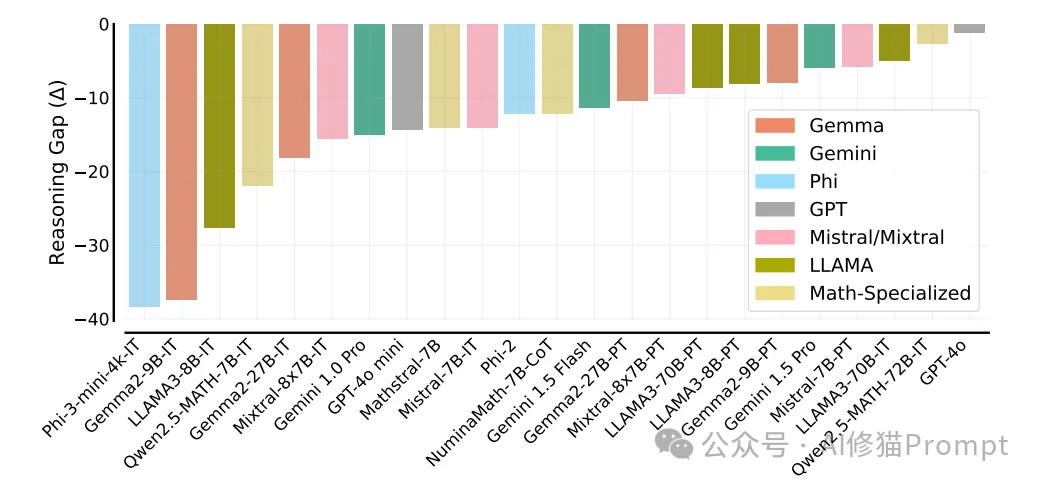
研究者用这张图展示了不同大型语言模型(LLMs)的推理能力差距(Reasoning Gap)。图中的纵轴表示推理差距(Δ),数值越接近0表示模型在组合式GSM测试和标准GSM8K测试中的表现差异越小,即推理能力越强。说明了:
1. 模型之间存在显著的推理能力差距。
2. 较小和专门化的模型(如Phi-3-mini-4k-IT, Gemma2-9B-IT, LLAMA3-8B-IT等)通常表现出较大的推理差距。
3. 大型通用模型(如GPT-4O, Gemini 1.5 Pro等)表现出较小的推理差距。
4. 同一系列的不同版本模型(如Gemma, Gemini, LLAMA等)往往表现出类似的推理差距模式。
5. 数学专门化模型(如Qwen2.5-MATH系列)在不同规模下表现各异。
2. 小型和高效模型的局限性
研究发现,小型、更具成本效益的模型以及专门为数学任务优化的模型表现出更大的推理差距。这一发现对实际应用中选择和使用这些模型提出了新的挑战。
具体来说,研究者比较了四个模型家族(GPT、Gemini、LLAMA3和Gemma2)中的高成本和低成本选项。结果显示,虽然低成本模型在原始GSM8K测试中表现相似或略差,但在组合式GSM测试中表现出2-12倍更大的推理差距。
这一发现特别值得注意,因为一些低成本模型(如GPT-4o mini)在标准数学推理基准测试中几乎能够匹配甚至超越其高成本对应版本。这表明,目前广泛使用的数学推理基准可能掩盖了成本效益型LLM的推理缺陷。
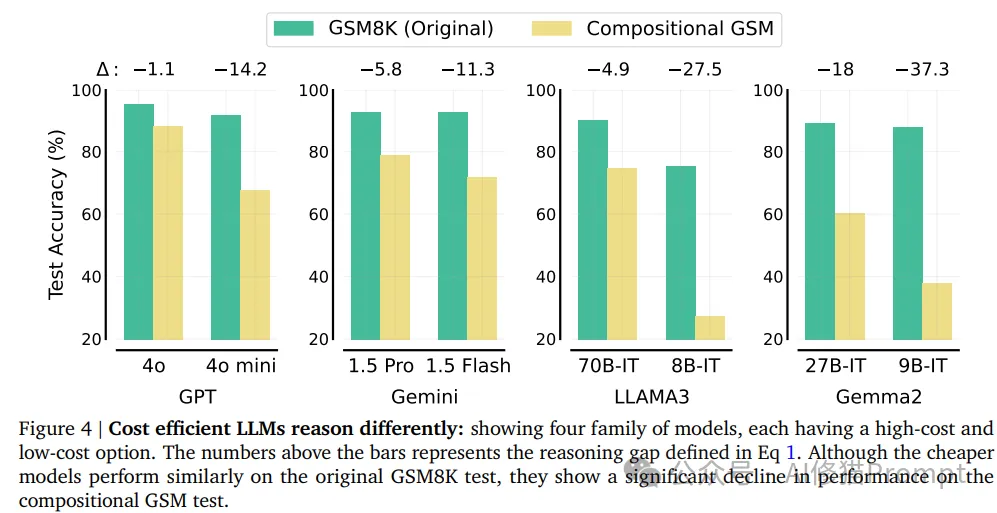
研究者用这张图展示了四个主要的LLM家族(GPT、Gemini、LLAMA3和Gemma2)中高成本和低成本选项在原始GSM8K测试和组合式GSM测试上的表现对比。上图说明:
1. 每个家族都展示了一个高成本和一个低成本选项。
2. 绿色柱代表原始GSM8K测试的准确率,黄色柱代表组合式GSM测试的准确率。
3. 图上方的Δ值表示推理差距,即组合式GSM测试相对于原始GSM8K测试的性能下降程度。
4. 在每个家族中,低成本选项在原始GSM8K测试上的表现与高成本选项相近,但在组合式GSM测试上表现出明显的性能下降。
5. 推理差距(Δ)随着模型规模的减小而增大,这一趋势在所有四个家族中都很明显。
3. 指令微调效果的不一致性
研究团队比较了Mistral、LLAMA3和Gemma2三个LLM家族中小型和大型模型的预训练版本和指令微调版本。结果显示,指令微调对不同规模的LLM产生了显著不同的影响:
- 对于小型模型,指令微调在原始GSM8K测试上带来了显著提升,但在组合式GSM测试上的改进相对较小。
- 对于大型模型,这种趋势并不明显,有时甚至出现相反的情况。
这一发现挑战了当前指令微调的标准训练方法,暗示我们需要重新审视这些方法对不同规模模型的适用性。
4. 数学专业化训练的局限性
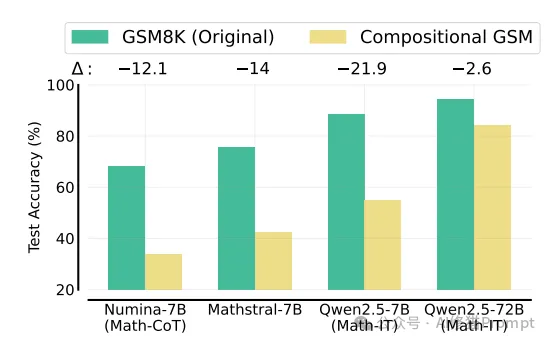
研究者还评估了专门为数学问题求解设计的模型,包括NuminaMath-7B-CoT、Mathstral-7B、Qwen2.5-Math-7B-IT和72B-IT。令人惊讶的是,这些数学专业化模型,尤其是小型模型,展现出与其他同等规模模型相似的推理差距。
例如,Qwen2.5-Math-7B-IT在MATH测试集(包含难度较高的高中竞赛级别问题)中能达到80%以上的准确率,但在组合式小学数学问题上的解决率不到60%。这一结果令人意外,因为MATH测试集中的大多数问题明显比简单串联两个小学问题更具挑战性。
5. 微调可能导致任务过拟合
研究团队对Gemma2 27B模型进行了微调实验,分别使用原始GSM8K训练数据集中的人工编写解决方案和合成数据。结果显示:
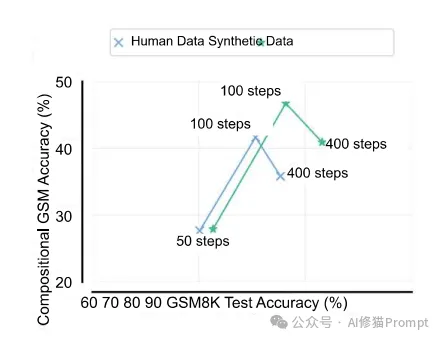
- 在初始训练阶段(约100步),组合式GSM测试性能有所提升。
- 随着训练的继续(400步),组合式GSM测试性能开始下降,而GSM8K测试性能持续提升。
- 使用合成数据训练通常能在GSM8K和组合式GSM测试上获得更高的性能。
这一发现暗示,当前流行的使用大量训练数据(尤其是合成数据)来过度训练小型模型的做法,可能主要针对标准基准测试的性能优化,而牺牲了模型在更广泛任务上的泛化能力。
6. 代码生成vs自然语言推理
研究还比较了模型在生成Python代码和自然语言链式思考(Chain of Thought, CoT)解决方案时的表现差异。结果显示:
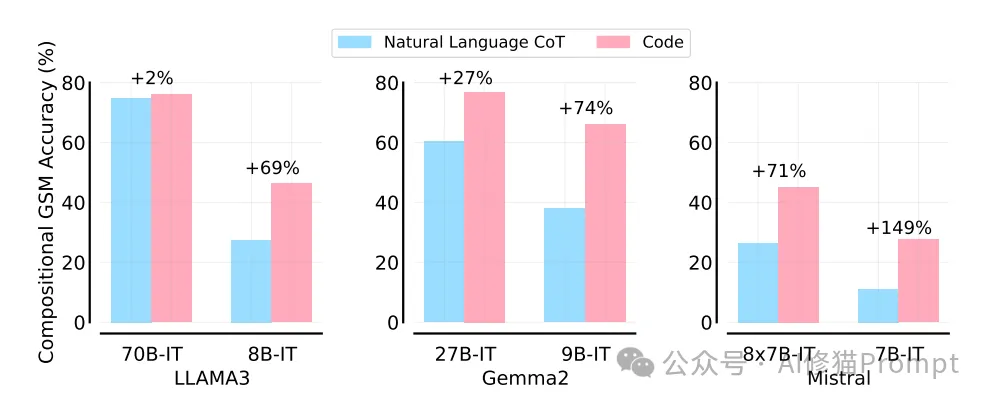
- 代码生成通常能提高模型在组合式GSM问题上的表现。
- 小型模型从代码生成中获得的相对改进更为显著。
这一发现再次强调了小型模型在推理能力上存在系统性差异。
为了更好地理解LLM在组合式GSM测试中表现不佳的原因,研究团队进行了深入分析:
1. 排除基准测试泄露的影响
研究者比较了模型在原始GSM8K测试和修改后的GSM问题(组合式GSM中的Q2)上的表现。结果显示,大多数模型在这两类问题上的准确率相近,这表明测试集泄露并不是导致性能下降的主要原因。
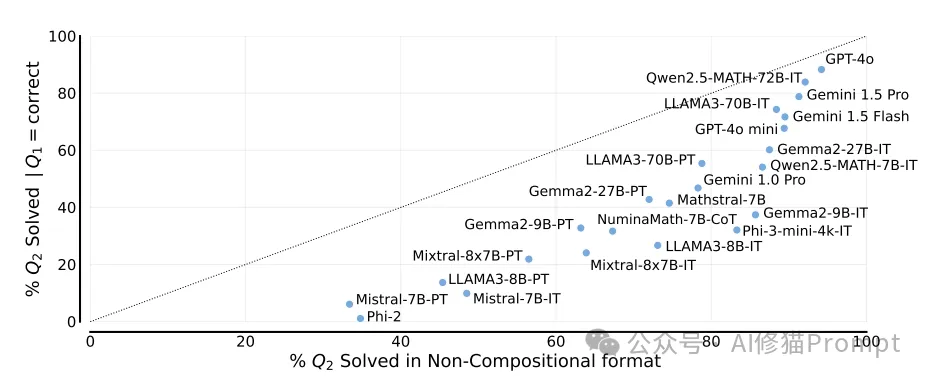
2. 易受额外上下文干扰
通过比较模型独立解答问题和在组合式格式中解答同一问题的能力,研究发现许多模型容易受到额外上下文的干扰。一些模型在组合式格式中解答Q1的能力明显低于独立解答时,这种干扰来自于提示中存在Q2。
具体来说,模型在处理组合式问题时经常忽视重要细节,如漏掉与问题中"每个"相关的推理步骤,或在问题涉及"月"或"每月"时遗漏算术步骤。这种注意力分散导致模型无法正确回答Q1,进而影响Q2的解答。
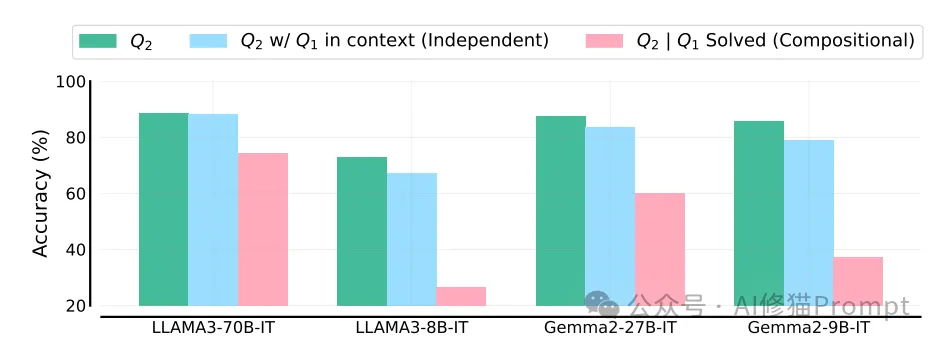
3. 二阶推理能力的不足
研究还发现,即使模型正确解答了Q1,也不能保证能够成功解答Q2。通过比较模型独立解答问题的能力和在正确解答Q1的前提下解答Q2的能力,研究者发现:
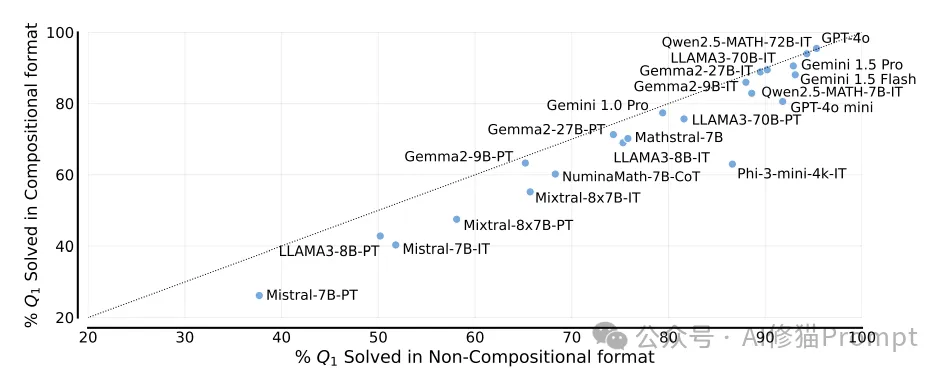
- 当Q2独立于Q1时,Q1造成的干扰相对有限。
- 但当Q2依赖Q1的答案时,即使Q1已正确解答,模型在准确解答Q2时仍面临困难。
这一发现与先前研究一致,即在面对多跳知识检索问题时,LLM能够执行第一跳推理,但在第二跳推理上表现不佳。
这项研究不仅揭示了LLM推理能力的局限性,也为未来AI产品开发和评估提供了重要启示:
1. 重新审视评估方法:当前广泛使用的数学推理基准可能无法全面反映LLM的真实推理能力。我们需要设计更加复杂和多样化的评估方法,如组合式任务,以全面测试模型的推理能力。
2. 关注小型和高效模型的局限性:在选择和使用小型、高效模型时,需要特别注意其在复杂推理任务上的表现。这些模型虽然在标准基准测试上表现良好,但在实际应用中可能面临更大挑战。
3. 优化指令微调策略:研究表明,当前的指令微调方法对不同规模的模型效果不一。我们需要为不同规模的模型开发更加定制化的微调策略。
4. 平衡专业化训练和泛化能力:数学专业化训练虽然能提高模型在特定数学任务上的表现,但可能无法显著改善其整体推理能力。在模型训练时,需要在专业化和泛化能力之间找到平衡。
5. 警惕过拟合风险:在模型微调过程中,需要密切关注模型在不同类型任务上的表现变化,避免出现对特定任务的过拟合。
6. 探索多模态推理:研究发现,代码生成有助于提高模型的推理能力。这启示我们可以探索结合自然语言和代码的多模态推理方法,以增强模型的整体推理能力。
7. 增强注意力机制:研究显示LLM容易受到额外上下文的干扰。改进模型的注意力机制,提高其对关键信息的识别和处理能力,是提升推理能力的重要方向。
8. 强化多步推理能力:LLM在二阶推理任务上的表现不佳,说明我们需要开发新的训练方法和模型架构,以增强模型的多步推理能力。
9. 注意Prompt的适用性:根据不同LLM写不同的Prompt框架,尤其是要注意Prompt的敏感性和一致性,具体可以参考这篇文章《Prompt工程师的反思:我做错了什么?搞AI应用,终究躲不过Prompt的敏感性和一致性》
对于正在开发AI产品的Prompt工程师来说,这项研究的意义尤为重大。它提醒我们,在设计提示和评估模型性能时,不能仅仅依赖于标准基准测试的结果。我们需要考虑更加复杂和多样化的场景,特别是那些需要多步推理和组合能力的任务。
文章来自于微信公众号“ AI修猫Prompt”,作者“ AI修猫Prompt”




【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
