# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在人形机器人领域,有一个非常值钱的问题:既然人形机器人的样子与人类类似,那么它们能使用网络视频等数据进行学习和训练吗?
如果可以,那考虑到网络视频的庞大规模,机器人就再也不用担心没有学习资源了。
近日,德克萨斯大学奥斯汀分校和 NVIDIA Research 的朱玉可团队公布了他们的一篇 CoRL 2024 oral 论文,其中提出了一种名为 OKAMI 的方法,可基于单个 RGB-D 视频生成操作规划并推断执行策略。

先来看看演示视频:

可以看到,机器人在看过人类演示者向袋子中装东西后,也学会了以同样的动作向袋子中装东西。不仅如此,OKAMI 还能让人形机器人看一眼演示视频就轻松学会撒盐、将玩具放进篮子和合上笔记本电脑等任务。



和 AI 领域内的许多技术一样,OKAMI 也是一个缩写词,全称是 Object-aware Kinematic retArgeting for huManoid Imitation,即用于人形机器人模仿的物体感知型动力学重定向。
顾名思义,这是一种物体感知型重定向方法,可以让具有两个灵巧机器手的双手型人形机器人基于单个 RGB-D 视频演示模仿其中的操作行为。
OKAMI 采用了一种两阶段过程,可将人类运动重新定向成人形机器人的运动,从而可在不同初始条件下完成任务。
在第一个阶段,OKAMI 会处理视频并生成一个参考操作规划。

在第二个阶段,OKAMI 会使用该规划来合成人形机器人的运动,这个过程会用到运动重定向,其作用是适应目标环境中的物体位置。

图 2 展示了其整个工作流程。
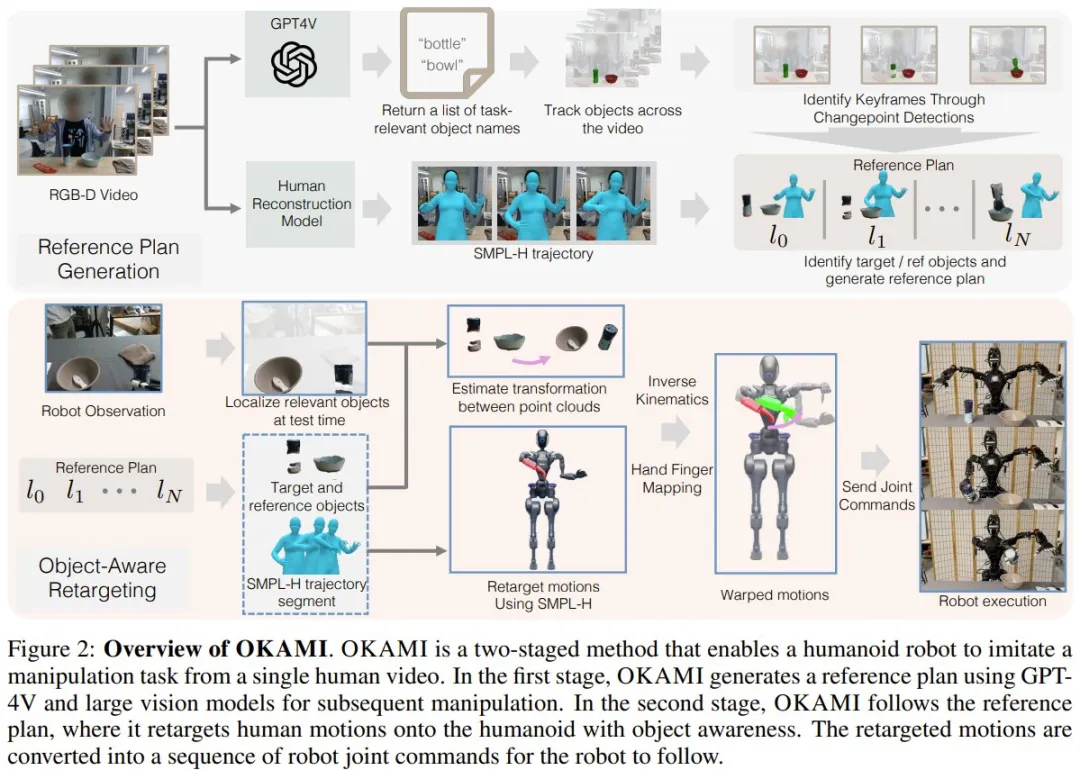
首先,该团队将人形机器人操作任务描述成了一个离散时间马尔可夫决策过程,并将其定义成了一个元组 M = (S, A, P, R, γ, µ)。其中 S 是状态空间、A 是动作空间、P (・|s, a) 是转移概率、R (s) 是奖励函数、γ ∈ [0, 1) 是折扣因子、µ 是初始状态分布。
在这里,S 就是原始 RGB-D 观察的空间,其中包含机器人和物体的状态;A 则是人形机器人的运动指令的空间;R 是一个稀疏的奖励函数 —— 当任务完成时,返回 1。对于一个任务,其目标是找到一个策略 π,使其可以在测试时间最大化大量不同的初始配置下的预期任务成功率。
他们考虑了「基于观察的开放世界模仿」设置。在该设置中,这个机器人系统会获得一段录制的 RGB-D 人类视频 V,然后其需要返回一个人形机器人操作策略 π,使机器人可以完成视频演示的任务。
为了实现物体感知型重新定向,OKAMI 首先会为人形机器人生成一个参考规划。规划生成需要了解有哪些与任务相关的物体以及人类如何操作它们。
识别和定位与任务相关的物体
为了模仿视频 V 中的操作任务,OKAMI 必须识别要交互的物体。之前的方法需要具有简单背景的无监督方法或需要额外的人工标注,而 OKAMI 则不一样,其使用了现成可用的视觉 - 语言模型(VLM)GPT-4V 来识别 V 中与任务相关的物体;这自然是用到了该模型中内化的常识性知识
具体来说,OKAMI 会通过采样 RGB 帧并使用 GPT-4V 来获取与任务相关的物体的名称。使用这些名称,OKAMI 再使用 Grounded-SAM 来分割第一帧中的物体并使用视频目标分割模型 Cutie 来跟踪这些物体的位置。
重建人类运动
为了将人类运动重新定向成机器人运动,OKAMI 会重建来自 V 的人类运动以获取运动轨迹。为此,他们采用了改进版的 SLAHMR,这是一种用于重建人类运动序列的迭代式优化算法。虽然 SLAHMR 假设双手平放,而新的扩展优化了 SMPL-H 模型的手部姿势,这些姿势使用来自 HaMeR 的估计手部姿势进行初始化。此修改使得单目视频中的身体和手部姿势可以进行联合优化。其输出是一个获取了全身和手部姿势的 SMPL-H 模型序列,让 OKAMI 可以将人类动作重新定向到人形机器人。
此外,SMPL-H 模型还能表示不同人类外观的人类姿势,从而可以轻松地将人类演示者的运动映射到人形机器人。
基于视频生成规划
有了任务相关的物体和重建出来的人类运动,OKAMI 就可以基于 V 生成用于完成每个子目标的参考规划了。
OKAMI 识别子目标的方式是基于以下流程执行时间分割:
 的点云。
的点云。有了来自演示视频的参考规划后,OKAMI 便可以让人形机器人模仿 V 中的任务。机器人会遵循规划中的每个步骤 l_i。然后经过重新定向的轨迹会被转换成关节指令。这个过程一直重复直到任务完成,之后基于任务特定的条件来评估是否成功。
在测试时间定位物体
为了在测试时间环境中执行规划,OKAMI 必须定位机器人观察中的相关物体,提取 3D 点云来跟踪物体位置。通过关注与任务相关的物体,OKAMI 策略可以泛化用于各不相同的视觉背景,包括不同的背景或任务相关物体新实例。
将人类运动重新定位到人形机器人
物体感知的关键是使运动适应新的物体位置。在定位物体后,OKAMI 会采用一种分解式重新定位过程,即分别合成手臂和手部运动。
OKAMI 首先根据物体位置调整手臂运动,以便将手指置于以物体为中心的坐标系内。然后,OKAMI 只需在关节配置中重新定位手指,以模仿演示者用手与物体交互的方式。
具体来说,首先将人体运动映射到人形机器人的任务空间,缩放和调整轨迹以考虑尺寸和比例的差异。然后,OKAMI 扭曲变形(warp)重新定位的轨迹,以便机器人的手臂到达新的物体位置。该团队考虑了两种轨迹变形情况 —— 当目标和参考物体之间的关系状态不变时以及当关系状态发生变化时,相应地调整变形。
在第一种情况下,仅基于目标物体位置执行轨迹变形。在第二种情况下,基于参考物体位置执行变形。
变形之后,使用逆动力学计算机器臂的关节配置序列,同时平衡逆运动学计算中的位置和旋转目标的权重以保持自然姿势。同时,将人类手部姿势重新定位到机器人的手指关节,使机器人能够执行精细的操作。
最后,可得到一套全身关节配置轨迹。由于机器臂运动重新定向是仿射式的,因此这个过程可以自然地适应不同演示者的情况。通过调整手臂轨迹以适应物体位置并独立重新定位手部姿势,OKAMI 可实现跨各种空间布局的泛化。
研究者在实验部分主要回答了以下四个研究问题:
任务设计。研究者在实验中执行了六项任务,分别如下:

硬件设置。研究者使用 Fourier GR1 机器人作为自己的硬件平台,配备了两个 6 自由度(DoF)的 Inspire 灵巧手以及一个用来录制视频和进行测试时观察的 D435i Intel RealSense 摄像头。此外还实现了一个以 400Hz 运行的关节位置控制器。为了避免出现抖动,研究者以 40Hz 来计算关节位置命令,并将命令插入 400Hz 轨迹。
评估方案。研究者针对每项任务运行了 12 次试验。过程中,物体的位置在机器人摄像头视野和人形手臂可触及范围的交点内进行随机初始化。
基线。研究者将 OKAMI 与基线 ORION 进行了比较。
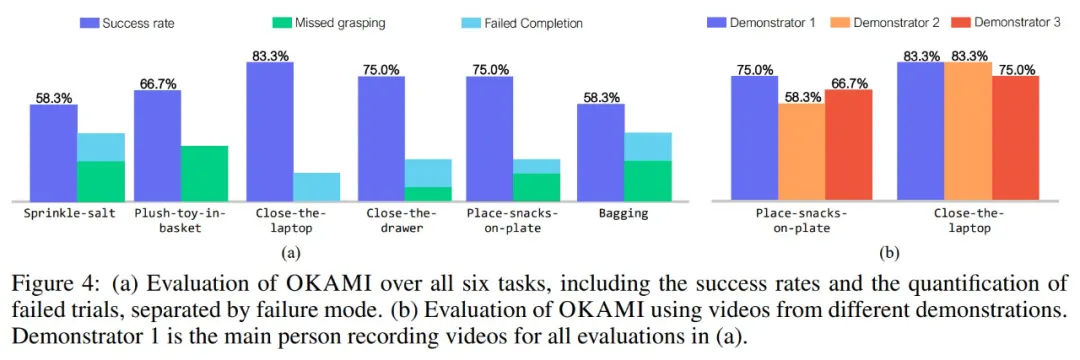
为了回答问题 1),研究者评估了 OKAMI 在所有任务中的策略,覆盖日常取放、倾倒和操纵铰接物体等多样性行为。结果如下图 4(a)所示,实验中随机初始化了物体位置,这样做让机器人需要适应物体的位置。从结果来看,OKAMI 可以有效地泛化到不同的视觉和空间条件。
为了回答问题 2),研究者在两项代表性任务上将 OKAMI 与 ORION 进行比较,分别是将 Place-snacks-on-plate 和 Close-the-laptop。二者的不同之处在于 ORION 不以人类身体姿态为条件。结果显示,OKAMI 在两项任务上分别实现了 75.0% 和 83.3% 的成功率,而 ORION 分别只有 0.0% 和 41.2%,拉开了很大的差距。
为了回答问题 3),研究者进行了一项受控实验,记录了不同演示者的视频,并测试 OKAMI 策略是否对所有视频输入都能保持良好的性能。同样地,他们选择的任务是 Place-snacks-on-plate 和 Close-the-laptop,结果如图 4(b)所示。
总体而言,OKAMI 能够在处理不同演示者的视频时保持相当不错的性能,不过处理这类多样性的视觉 pipeline 仍有改进的空间。
为了解决问题 4),研究者在 OKAMI rollout 上训练了神经视觉运动策略。他们首先在随机初始化的物体 rollout 上运行 OKAMI,并在收集一个包含成功轨迹的数据集同时丢弃失败的轨迹。此外他们通过行为克隆算法在该数据集上训练神经网络策略,并为 Sprinkle-salt 和 Bagging 两项任务训练视觉运动策略。
下图 5 展示了这些策略的成功率,表明 OKAMI rollout 可以成为有效的训练数据源。并且,随着收集到的 rollout 增多,学习到的策略会随之改进。这些结果有望扩展数据收集范围,从而无需费力远程操作也能学习人形机器人操作技能。
OKAMI 虽强,但也并不完美,下面展示了两个失败实例:


OKAMI 目前专注于人形机器人的上半身运动重定向,尤其是用于桌面工作空间的操控任务。因此未来有希望扩展到下半身重定向,以便在视频模仿期间实现运动行为。更进一步,实现全身运动操控则需要一个全身运动控制器,而不是 OKAMI 中使用的关节控制器。
此外,研究者在 OKAMI 中依赖 RGB-D 视频,这限制了他们使用以 RGB 记录的野外互联网视频。因此扩展 OKAMI 使用网络视频将是未来另一个有潜力的研究方向。最后,当前重定向的实现在面对物体的形状变化较大时表现出了较弱的稳健性。
未来的改进将是整合更强大的基础模型,使机器人能够总体了解如何与一类物体进行交互,即使这类物体的形状变化很大。
参考链接:
https://x.com/yukez/status/1848373529386860933
文章来自于微信公众号“机器之心”




【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
