# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
只要一个3B参数的大模型,就能控制机器人,帮你搞定各种家务。
叠衣服冲咖啡都能轻松拿捏,而且全都是由模型自主控制,不需要遥控。
关键是,这还是个通用型的机器人控制模型,不同种类的机器人都能“通吃”。
请看VCR:

这些操作背后的大模型叫做π0,参数量只有3B,来自今年刚成立的初创公司Physical Intelligence(简称π)。
创立之后不久,π公司就获得了7000万美元(约5亿人民币)的A轮融资,投资者中还包括OpenAI。
而公司的目标,就是开发通用的机器人控制模型,现在的π0,就是其首项成果。
有网友直言,π0控制的机器人,是他见过最接近真正的通用机器人的。
关键是,参数量只有3B,算力消耗非常小,如果和同规模的模型性能特征相近,廉价显卡就能带动。

Hugging Face的机器人团队领军人物、前特斯拉Optimus团队成员Remi Cadene也说,如果π0能开源的话,人们自己在家就能体验了。
在官宣当中,π团队展示了叠衣服、整理桌子、鸡蛋装盒等等复杂(对机器人来说)任务。
这些任务不仅需要长时间、多阶段的连续决策,还要求动作同时具备高频率与精细程度。
许多任务更是涉及了复杂的接触动力学,如衣物的变形塑性、纸箱的刚性、鸡蛋的脆弱性等。
机器人需要精准建模并控制这些动力学过程,甚至满足更多物理约束,如保持物体平衡、避免碰撞。
但总之最后π团队还是成功了,π0不仅能控制机器人,还能控制不同的机器人,出色地完成这些任务。

比如让双臂可移动机器人收拾洗好的衣服。
只见机器人站到洗衣机前,打开了舱门,然后将洗好的衣服取出放入筐内。

然后又来到一张桌子旁,将筐里的衣服取出、铺开然后叠好。

还有让另一种双臂机器人把盘子里的鸡蛋装入盒子中,之后再把盒子盖好。

甚至有条不紊地折叠好一个展开的纸盒。

而且知道利用工具,比如这个机器人,用叉子把剩余的食物装进了打包盒。

到了收拾桌子的任务当中,负责执行的机器人又变成了单臂。
它可以把要保留的物品放入收纳筐,将不需要的垃圾丢进垃圾桶。

并且在物品和垃圾混合放置时也能准确操作。

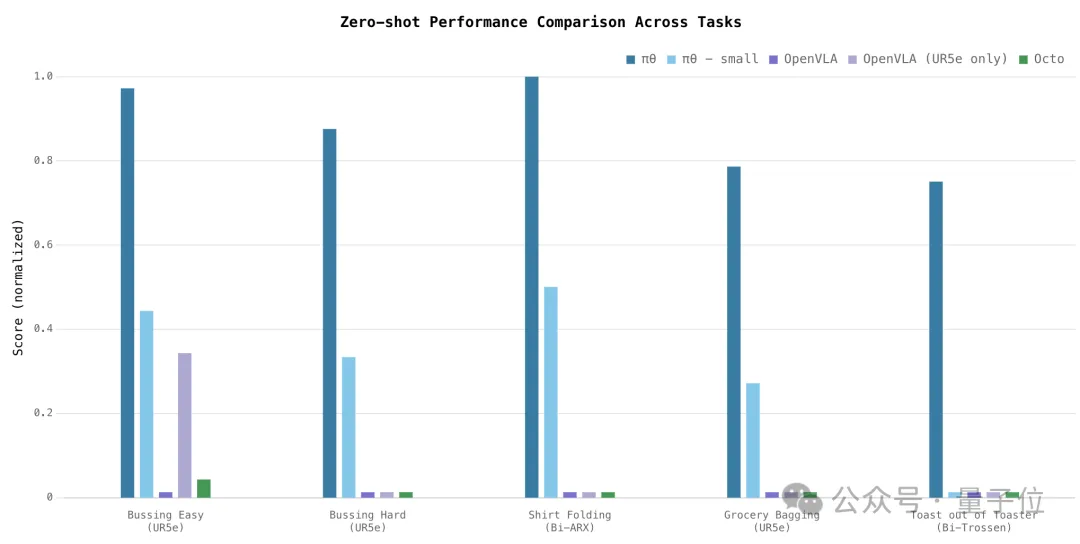
当然从数据上看,π0在零样本泛化能力、语言控制响应、新任务学习、多阶段任务等维度上也表现优异。
零样本泛化能力上,π0在所有任务上都显著超过了baseline模型,即使未加入预训练视觉模型的π0-small也比这些baseline表现优异。
指令处理上,π0在3个语言指令任务上,经人类指导取得了最好的自主表现,高层策略指导也有提升。
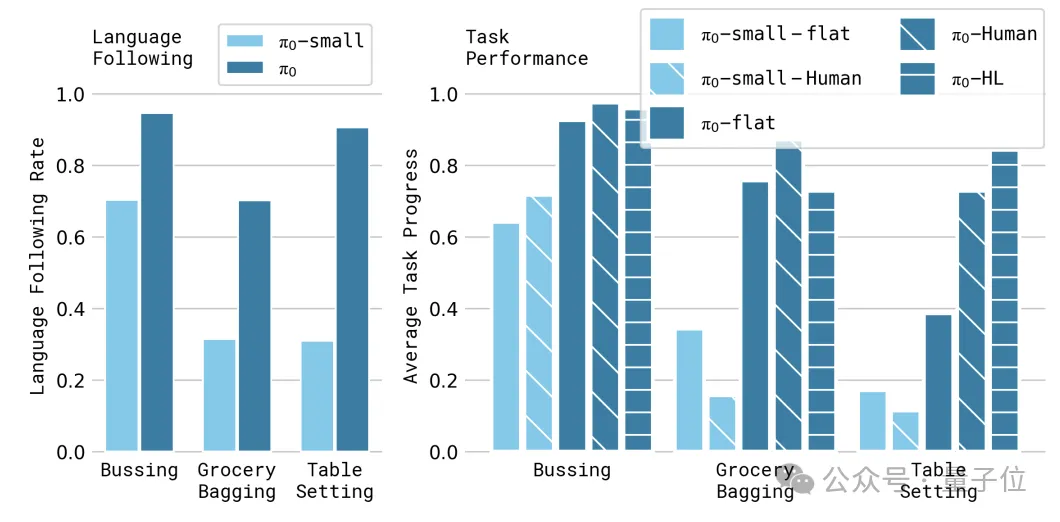
在与预训练数据差异较大的新任务上,π0在大多数任务上性能最好,尤其在微调数据量较小时优势明显。
这意味着,不需要专门训练,π0就能让机器人自动完成很多开放性任务。

最后在一系列极具挑战的复杂任务上,π团队通过结合微调和语言指令对π0进行了测试。
结果π0能够完成折衣服、整理餐桌、组装纸箱、装鸡蛋等长达5-20分钟的任务,取得了50%以上的平均得分。
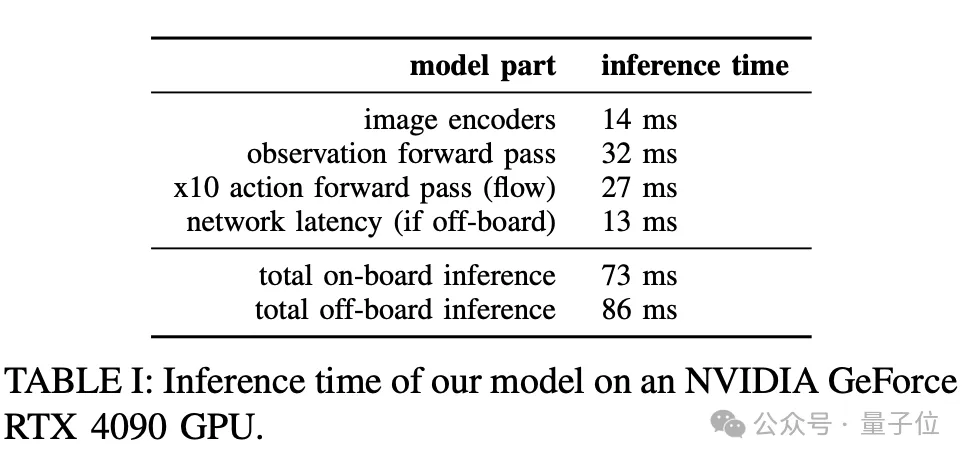
效率方面,官方技术报告中公布了π0在4090上的运行时间。
一次完整的前向传播也需要73-86毫秒,这对实时性要求高的场景可能还有挑战。
但考虑到流匹配过程能生成50个动作步,平均下来每个动作步的生成时间也并不高。这
所以从整体上看,π0的计算效率,或者说实时性,还是比较高的,当然离网友们期待的家家可用,可能还需要再提速一些。
那么,π团队在π0模型上,都运用了什么样的技术呢?
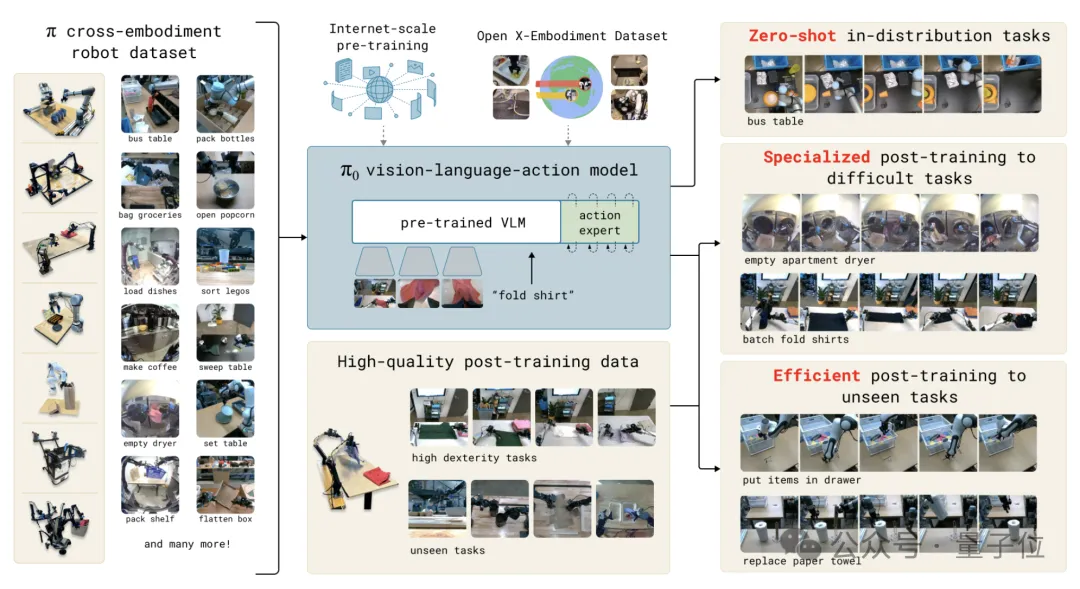
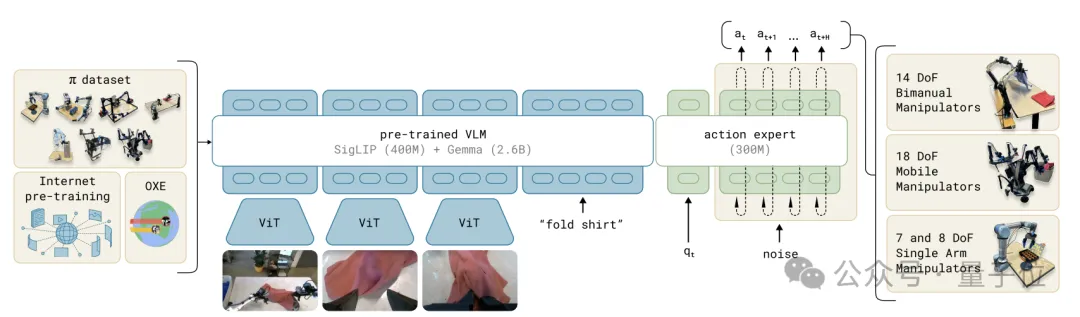
π0是基于视觉模型PaLM-ViT改造而成,在其基础上增加了一个投影层、一个多层感知机,以及一个较小的动作专家模块。
其中投影层用于处理机器人状态和动作的输入输出,多层感知机用于整合流匹配(flow matching)时间步信息,专家模块则用单独的权重处理机器人状态和动作tokens。
模型的输入包括图像、语言指令、机器人本体感受状态和噪声动作块。
图像和语言tokens送入VLM主干网络,状态和动作tokens送入动作专家模块。
最终,模型会输出动作块的向量场表示。
对于连续动作分布的建模,π0模型使用了条件流匹配(conditional flow matching)方法。
流匹配的工作方式和扩散模型有些类似,核心思想都是通过逐步添加噪声来简化数据分布,然后逐步去噪得到隐私数据——
训练时,随机对动作施加高斯噪声,并训练模型输出去噪向量场;推理时,从高斯噪声开始,通过数值积分向量场生成动作序列。
不同之处在于,流匹配直接对数据和噪声分布之间的映射场(vector field)进行建模,训练目标是匹配这一映射场,而扩散模型通常学习的是每个去噪步骤的条件分布。
流匹配方法能够高精度地建模复杂多峰分布,非常适合高频灵巧操作任务。
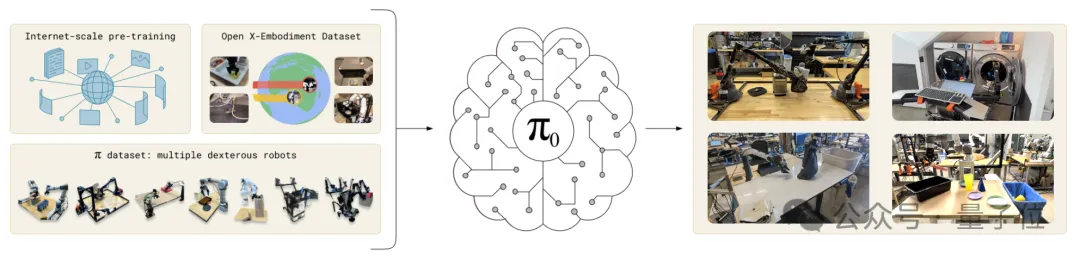
训练数据方面,π0是在迄今为止最大的机器人交互数据集上进行训练的。
预训练阶段的数据集中包括OXE、DROID、Bridge等开源数据,以及团队在8个不同的机器人平台中收集的大量灵巧类任务数据等内容。
团队自己收集的数据集括68个任务,涉及单臂任务106M步、双臂任务797M步,数据采用了50Hz高频控制。
开源数据和团队自己收集的数据,比例大约是1:9。
另外为了让π0掌握特定复杂技能,团队在20多个下游任务上进行了微调。
根据任务的难度和相似度,微调数据量从5小时到100多小时不等,一些任务还结合了高层语言策略模块来分解复杂目标。
用团队成员切尔西·芬(Chelsea Finn)的话说,预训练是为了让模型能够应对各种场景,后训练(微调)则是让π0掌握更多的策略。

Physical Intelligence公司成立于今年,已经获得总计7000万美元的A轮融资。
融资由红杉资本领先,此外还有包括OpenAI在内的6家公司参投。
公司还有个简称叫做π,因为Physical Intelligence的缩写pi,刚好是π的拉丁转写。
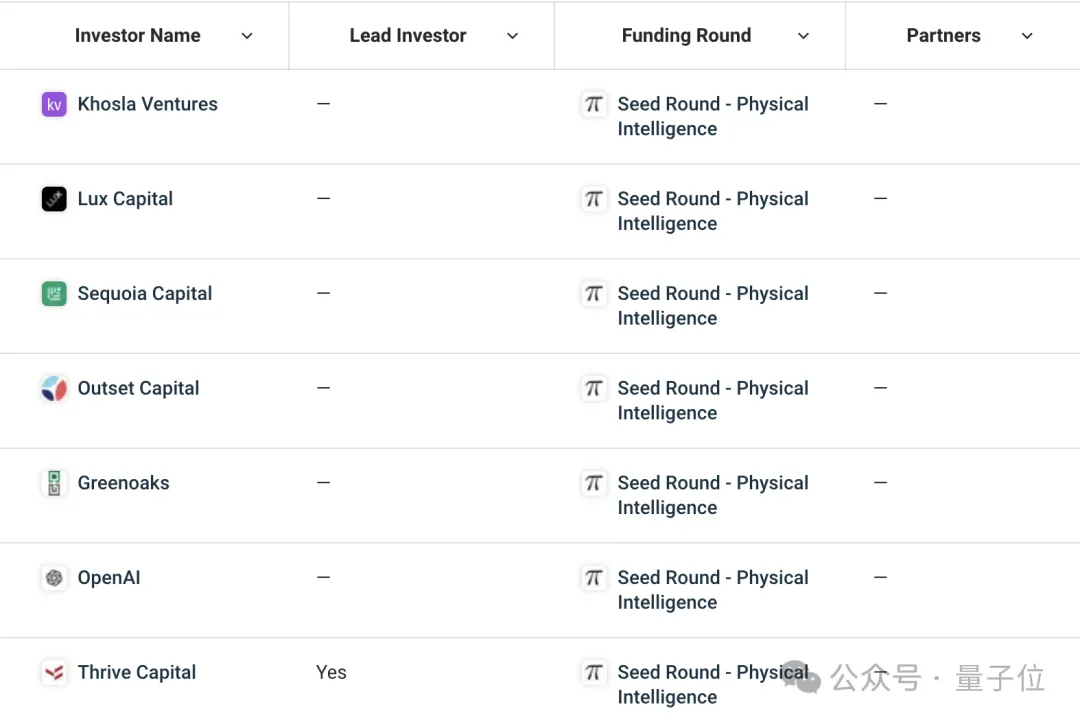
虽然是家机器人公司,但π并不生产机器人硬件,只负责训练模型,目标是构建能够通用的机器人模型。
对此,π的联合创始人兼CEO卡罗尔·豪斯曼(Karol Hausman)在公开场合解释:
我们的目标是通过一个通用模型将AI带入物理世界,这个模型可以为任何机器人或任何物理设备提供动力,基本上适用于任何应用。
对于此事的意义,公司另一名联创谢尔盖·莱文(Sergey Levine)在推特上举例说明,π创业要做的事之于机器人控制,其重要程度就像NLP之于大模型。

π的创始人背景也都十分亮眼,都是机器人和AI专家,在机器人、工程和许多其他领域拥有深厚经验。
CEO卡罗尔·豪斯曼(Karol Hausman),此前曾是谷歌大脑机器人操作研究主管,2021年至今兼任斯坦福客座教授。
联合创始人谢尔盖·莱文(Sergey Levine),UC伯克利电气工程和计算机科学系副教授,谷歌学术被引用量为超过12.7万。
而且还是不折不扣的顶会狂魔,据不完全统计,莱文2018年在ML和NLP顶会上共发表22篇论文,与另外两人并列全球第一……
莱文在UC伯克利还是个网红教授,此前推出的深度学习课程Deep Reinforcement Learning(深度强化学习,课程代号CS 285)非常受欢迎。
同时,在斯坦福家务机器人ALOHA的相关论文中,莱文的名字也经常出现。

联创切尔西·芬(Chelsea Finn),斯坦福计算机科学和电气工程系助理教授,谷歌学术论文引用数超4.7万。
在ALOHA团队的论文当中,芬经常以通讯作者的身份出现。
此外,还有谷歌大脑机器人团队前科学家布赖恩·伊希特(Brian Ichter)、丰田研究院ML研究团队的研究科学家苏拉吉·奈尔(Suraj Nair)等。
可以说阵容是非常豪华了。
拥有超级团队的π,也仍在继续招兵买马,在研究科学家、ML工程师、数据工程师等多个岗位招聘员工和实习生。

技术报告:
https://www.physicalintelligence.company/download/pi0.pdf
参考链接:
[1]https://www.physicalintelligence.company/blog/pi0
[2]https://www.reddit.com/r/singularity/comments/1ggm6za/a_3b_pretrained_generalist_model_trained_on_8/
[3]https://twitter.com/chelseabfinn/status/1852043351366996449
文章来自于微信公众号“量子位”,作者“克雷西”



【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
