# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
朋友们,想了解为什么同一模型会带来大量结果的不一致性吗?今天,我们来一起深入分析一下来自微软和麻省理工学院的一项重大发现——不同的Prompt格式如何显著影响LLM的输出精度。这些研究结果对于应用Prompt优化设计具有非常重要的应用价值。

本文将详细介绍该研究的工作过程、研究结果及其在实际应用中的价值。整个研究通过源码分析和实验验证,提供了扎实的证据支持这些结论。
微软和麻省理工学院(MIT)的研究团队近期发布了一项开创性研究,首次系统性地探讨了提示词格式对大语言模型(LLM)性能的影响。随着大型语言模型的广泛应用,Prompt工程逐渐成为影响模型性能的关键因素之一。然而,业内对Prompt格式在模型性能中的影响却一直缺乏系统性的研究。
微软和麻省理工学院的研究团队意识到这一问题的重要性,决定对Prompt格式如何影响LLM的表现进行深入分析,以解决LLM输出不一致性和性能波动的问题。这项研究颠覆了以往认为提示词格式无关紧要的观点,为Prompt工程实践带来了重要启示。
1.格式影响显著:研究发现,仅仅改变提示词的格式,就能导致模型性能产生高达42%的差异。在国际法相关的多项选择题测试中,使用JSON格式比Markdown格式的准确率提升了42%。
2.模型敏感度差异:
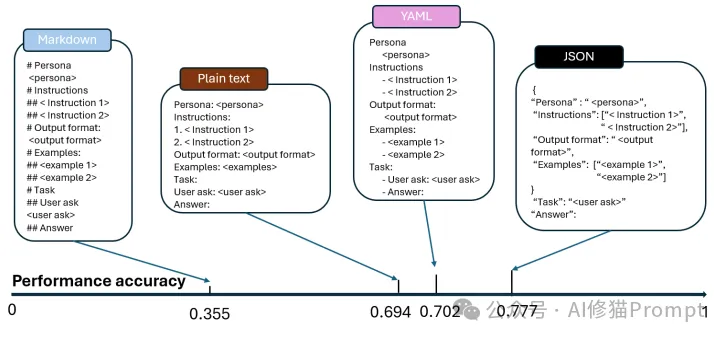
这张图展示了在国际法相关的MMLU基准测试中,JSON格式相比Markdown格式带来的显著性能提升。图中清晰地显示了42%的准确率差异,直观地证明了提示词格式选择的重要性。
研究团队明确了几个关键问题:
通过回答这些问题,研究团队希望为Prompt工程师提供指导,帮助他们选择最优的Prompt格式,以提升模型的性能和稳定性。
研究团队使用了多个数据集,涵盖了自然语言理解(NLU)、代码生成(Code Generation)和代码翻译(Code Translation)等任务。主要的数据集包括:
这些数据集的选择旨在确保实验结果的广泛适用性,涵盖了自然语言处理和代码任务的不同场景。
研究团队设计了四种不同的Prompt格式:
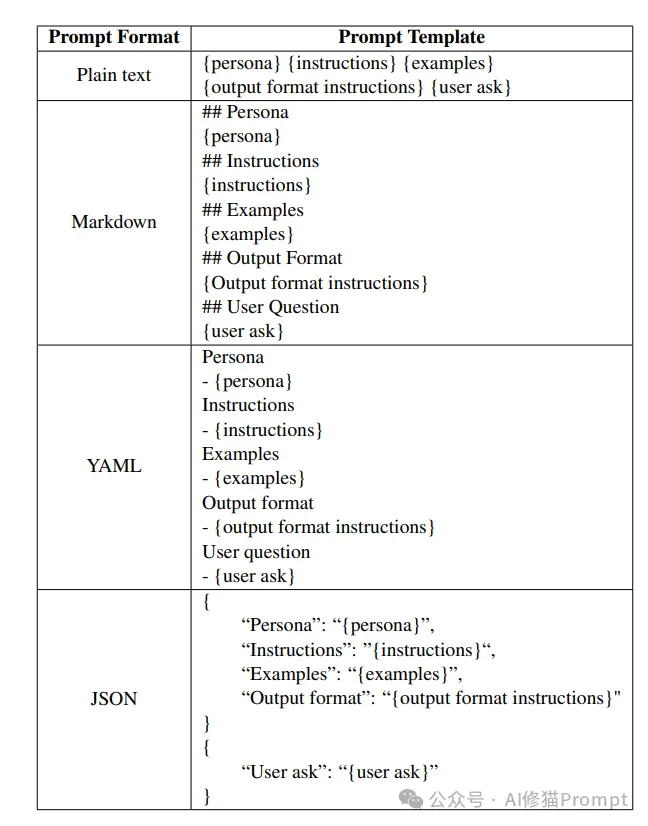


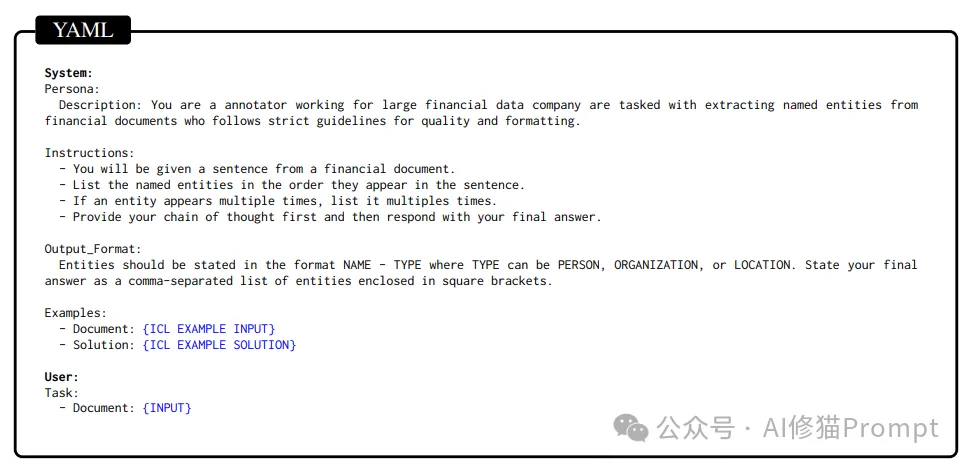

每种格式的Prompt内容保持一致,仅在格式和语法上有所区别,以确保实验结果仅反映格式本身对模型性能的影响。Prompt的设计包括五个主要组件:角色设定、任务说明、示例、输出格式指令和用户问题。
实验在OpenAI的GPT-3.5和GPT-4模型上进行,使用了Azure OpenAI平台。研究团队选择了多个模型版本,包括“gpt-35-turbo-0613”、“gpt-35-turbo-16k-0613”、“gpt-4-32k-0613”和“gpt-4-1106-preview”,以比较不同模型在Prompt格式上的表现差异。
为确保实验的公平性,所有Prompt在内容上完全相同,唯一的变量是格式的变化。研究团队通过对每个任务的表现进行评分,并使用配对t检验来判断不同格式间的性能差异是否显著。
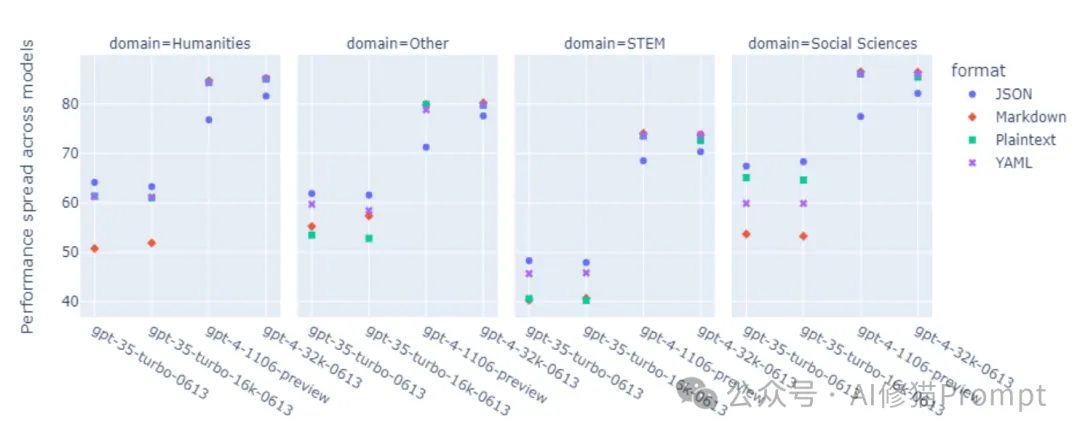
图2:不同GPT模型对格式变化的敏感度对比
这张图展示了不同GPT模型在各种任务中的性能表现。从图中可以清楚地看到:
研究发现,格式的影响程度与任务类型密切相关:
2.代码生成:
3.翻译任务:

图3:使用单侧配对t检验评估模型对Prompt格式的敏感性
表中显示了每个数据集/模型的最佳和最差格式(最大值/最小值)以及p值。除GPT-4-1104-preview在HumanEval任务上的p值外,其他所有p值均低于0.05,证实了Prompt格式对模型性能的广泛影响。
实验结果表明,不同的Prompt格式对LLM的性能有显著影响。在代码翻译任务中,JSON格式的Prompt相比Markdown格式提高了42%的准确性。这一发现颠覆了以往对Prompt格式无关紧要的假设。
在具体任务中,JSON格式通常表现最佳,尤其是在代码相关任务中表现尤为突出。而Markdown格式的表现则相对较差,特别是在涉及复杂结构化信息的任务中。
实验还发现,较小的模型(如GPT-3.5系列)对Prompt格式的敏感性更高,而较大的模型(如GPT-4)则表现出更好的稳健性。例如,GPT-4在不同Prompt格式下的性能差异较小,这表明更大的模型在处理不同格式时具有更强的鲁棒性。
研究团队进一步分析了不同Prompt格式对模型输出一致性的影响。通过一致性指标计算,发现GPT-4的输出一致性显著高于GPT-3.5。这意味着在使用不同Prompt格式时,GPT-4生成的答案更为统一和可靠。
此外,团队还评估了Prompt格式在不同模型之间的可传递性。结果表明,同一系列的模型(如GPT-3.5的不同版本)在最佳Prompt格式上具有较高的一致性,而不同系列的模型在最佳格式上则存在显著差异。这提示我们,Prompt工程需要针对具体的模型进行优化,而不能一概而论。这一点也是我在多篇文章中反复强调的,很多研究都突出了这一点。
对于需要处理代码的任务,例如代码生成和代码翻译,建议优先使用JSON格式的Prompt。这种格式能够更好地帮助模型理解结构化信息,从而提高任务的准确性和一致性。
对于自然语言处理任务,例如文本生成和问答,虽然JSON格式在多数情况下表现较好,但具体任务的需求可能不同,Prompt工程师应根据任务的复杂性和模型的特点选择合适的格式。
实验结果表明,不同的模型对Prompt格式的敏感性存在差异。因此,Prompt工程师在设计Prompt时应充分考虑所使用的模型类型,并进行相应的格式优化。例如,对于GPT-3.5,应更加注重Prompt格式的选择,而对于GPT-4,则可以在格式选择上更加灵活。
尽管本研究揭示了Prompt格式对LLM性能的显著影响,但仍有一些值得进一步探索的方向。如果您对这个实验感兴趣,也可以讲实验扩展到其他类型的LLM(如Claude的Sonnet,LLaMA和Gemini)上,以验证这些发现是否具有普遍性。此外,未来的研究还可以考虑引入更多类型的Prompt格式(如pesudo、SVG、HTML或XML等等),以进一步探究不同格式对模型性能的影响。
微软和麻省理工学院的这项研究向我们揭示了Prompt格式在LLM性能中的重要性。对于正在开发AI产品的读者来说,这些发现具有重要的指导意义。通过合理选择Prompt格式,我们可以显著提高LLM的输出精度和一致性,从而在实际应用中获得更好的性能。希望本文的分析能够为各位在实际工作中提供有价值的参考。
文章来自于“AI修猫Prompt”,作者“AI修猫Prompt”。




【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
