# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
前段时间,谷歌DeepMind提出了一种全新的「Step-Back Prompting」方法,直接让prompt技术变得脑洞大开。
简单来说,就是让大语言模型自己把问题抽象化,得到一个更高维度的概念或者原理,再把抽象出来的知识当作工具,推理并得出问题的答案。

论文地址:https://arxiv.org/abs/2310.06117
结果也是非常不错的,在他们用PaLM-2L模型做了实验,证明这种新型的Prompt技巧对某些任务和问题的处理表现极佳。
比方说,MMLU物理和化学方面的性能提高了7%,TimeQA提高了27%,MuSiQue则提高了7%。
其中MMLU是大规模多任务语言理解测试数据集,TimeOA是时间敏感问题测试数据集,MusiQue则是多跳问答数据集,包含25000个2至4跳的问题。
其中,多跳问题指的是,需要使用多个三元组所形成的多跳推理路径才能够回答的问题。
下面,让我们来看看这项技术是如何实现的。
看完开头的介绍,可能读者朋友还没太理解。什么叫让LLM自己把问题抽象化,得到一个更高维度的概念或者原理呢。
我们拿一个具体的实例来讲。
比方说,假如用户想问的问题和物理学中的「力」相关,那么LLM在回答此类问题时,就可以后退到有关力的基础定义和原理的层面,作为进一步推理出答案的根据。
基于这个思路,用户在一开始输入prompt的时候,大概就是这样:
你现在是世界知识的专家,擅长用后退的提问策略,一步步仔细思考并回答问题。
后退提问是一种思考策略,为的是从一个更宏观、更基础的角度去理解和分析一个特定问题或情境。从而更好地回答原始问题。
当然,上面举的那个物理学的例子只体现了一种情况。有些问题下,后退策略可能会让LLM尝试识别问题的范围和上下文。有的问题后退的多一点,有的少一些。
首先,研究人员指出,自然语言处理(NLP)领域因为有了基于Transformer的LLM而迎来了一场突破性的变革。
模型规模的扩大和预训练语料库的增加,带来了模型能力和采样效率的显著提高,同时也带来了多步推理和指令遵循等新兴能力。
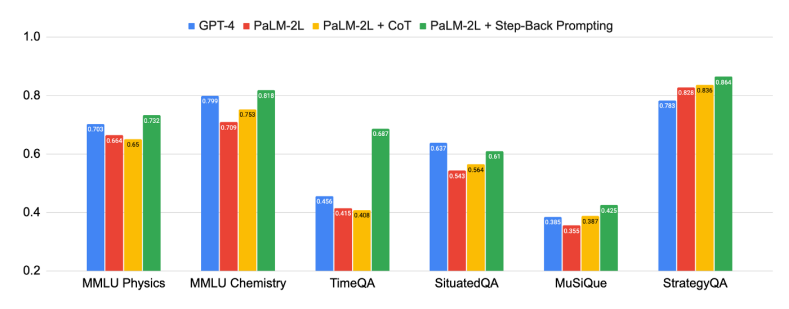
上图显示了后退推理的强大性能,本篇论文中所提出的「抽象-推理」法,在科学、技术、工程与数学和多跳推理等需要复杂推理的各种高难度任务中取得了重大改进。
有些任务非常具有挑战性,一开始,PaLM-2L和GPT-4在TimeQA和MuSiQue上的准确率仅为40%。而在应用了后退推理以后,PaLM-2L的性能全线提高。在MMLU物理和化学任务中分别提高了7%和11%,在TimeQA任务中提高了27%,在MuSiQue任务中提高了7%。
不仅如此,研究人员还进行了错误分析,他们发现大部分应用后退推理时出现的错误,都是由于LLMs推理能力的内在局限性造成的,与新的prompt技术无关。
而抽象能力又是LLMs比较容易学会的,所以这为后退推理的进一步发展指明了方向。。
虽说确实取得了不小进步,但复杂的多步骤推理还是很有挑战性的。即使对最先进的LLMs来说也是如此。
论文表明,具有逐步验证功能的过程监督是提高中间推理步骤正确性的一种有效补救方法。
他们引入了思维链(Chain-of-Thought)提示等技术,以产生一系列连贯的中间推理步骤,从而提高了遵循正确解码路径的成功率。
而谈到这种promp技术的起源时,研究者指出,人类在面对具有挑战性的任务时,往往会退一步进行抽象,从而得出高层次的概念和原则来指导推理过程,受此启发,研究人员才提出了后退的prompt技术,将推理建立在抽象概念的基础上,从而降低在中间推理步骤中出错的几率。
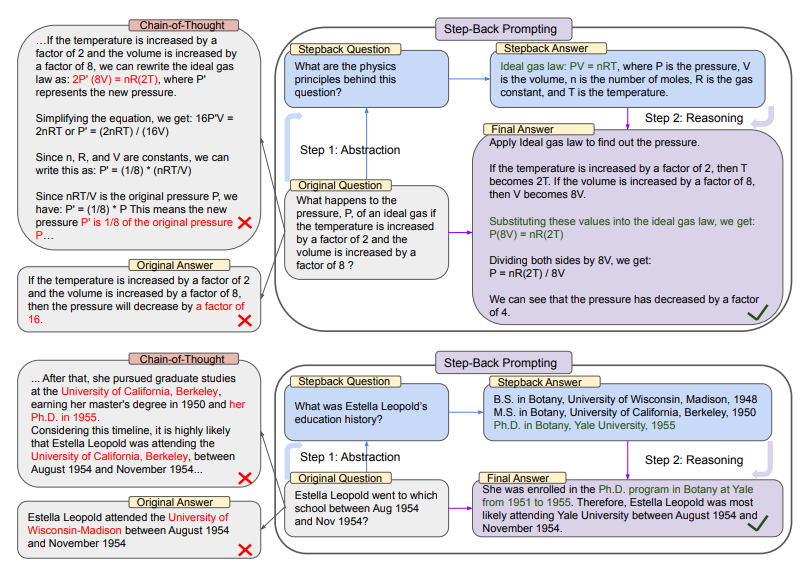
上图的上半部分中,以MMLU的高中物理为例,通过后退抽象,LLM得到理想气体定律的第一条原理。
而在下半部分中,是来自TimeQA的示例,教育史这一高层次概念是依照这种策略,LLM抽象出来的结果。
从整张图的左边我们可以看到,PaLM-2L未能成功回答原始问题。思维链提示在中间推理步骤中,LLM出现了错误(红色高亮部分)。
而右边,应用了后退prompt技术的PaLM-2L则成功回答了问题。
在众多认知技能中,抽象思考对于人类处理大量信息并推导出一般规则和原理的能力来说无处不在。
随便举几个例子,开普勒将成千上万的测量结果凝练成开普勒行星运动三定律,精确地描述了行星围绕太阳的轨道。
又或者,在关键决策制定中,人类也发现抽象是有帮助的,因为它提供了一个更广阔的环境视角。
而LLM是如何通过抽象和推理两步法来处理涉及许多低级细节的复杂任务,则是本篇论文的重点。
第一步就是教会LLMs退一步这个思路,让它们从具体实例中推导出高级、抽象的概念,如某领域内的基础概念和第一原理。
第二步则是利用推理能力,将解决方案建立在高级概念和第一原理的基础上。
研究人员在LLM上使用了少量的示例演示来执行后退推理这一技术。他们在一系列涉及特定领域推理、需要事实知识的知识密集型问题解答、多跳常识推理的任务中进行了实验。
结果表明,PaLM-2L的性能有了明显提高(高达27%),这证明了后退推理在处理复杂任务方面的性能十分显著。
在实验环节,研究人员对以下不同种类的任务进行了实验:
(1)STEM
(2)知识QA
(3)多跳推理
研究人员评估了在STEM任务中的应用,以衡量新方法在高度专业化领域中的推理效果。(本文中仅以此类问题进行讲解)
显然,在MMLU基准中的问题,需要LLM进行更深层次的推理。此外,它们还要求理解和应用公式,而这些公式往往是物理和化学原理和概念。
在这种情况下,研究人员首先要教会模型以概念和第一原理的形式进行抽象,如牛顿第一运动定律、多普勒效应和吉布斯自由能等。这里隐含的退一步问题是「解决这项任务所涉及的物理或化学原理和概念是什么?」
团队提供了示范,教导模型从自身知识中背诵解决任务的相关原理。
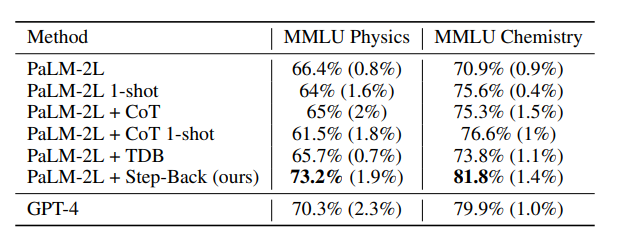
上表中就是应用了后退推理技术的模型性能,应用了新技术的LLM在STEM任务中表现出色,达到了超越GPT-4的最先进水平。
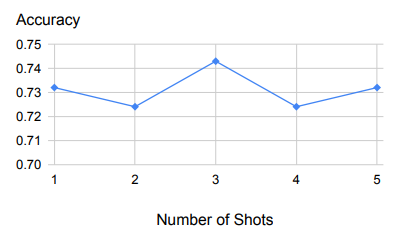
上表是针对少数几个样本的示例,展示了样本数量变化时的稳健性能。
首先,从上图中我们可以看出,后退推理对用作示范的少量示例具有很强的鲁棒性。
除了一个示例之外,增加更多的示例结果也还会是这样。
这表明,检索相关原理和概念的任务相对来说比较容易学习,一个示范例子就足够了。
当然,在实验过程中,还是会出现一些问题。
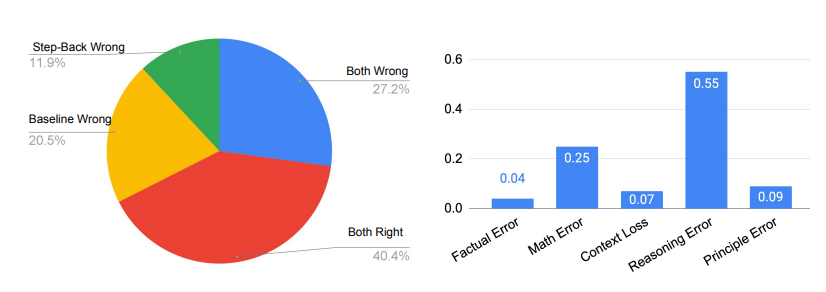
其中除原则错误外,所有论文中出现的五类错误都发生在LLM的推理步骤中,而原则错误则表明抽象步骤的失败。
如下图右侧所示,原则错误实际上只占模型错误的一小部分,90%以上的错误发生在推理步骤。在推理过程中的四种错误类型中,推理错误和数学错误是主要的失误所在地。
这与消融研究中的发现相吻合,即只需要很少的示例就能教会LLM如何进行抽象。推理步骤仍然是后退推理能否很好地完成MMLU等需要复杂推理的任务的瓶颈。
特别是对于MMLU物理来说,更是如此,推理和数学技能是成功解决问题的关键。意思就是说,哪怕LLM正确地检索了第一原理,也还是得通过典型的多步骤推理过程得出正确的最终答案,也就是还需要LLM有深入的推理和数学能力。
之后,研究人员在TimeQA的测试集上对模型进行了评估。
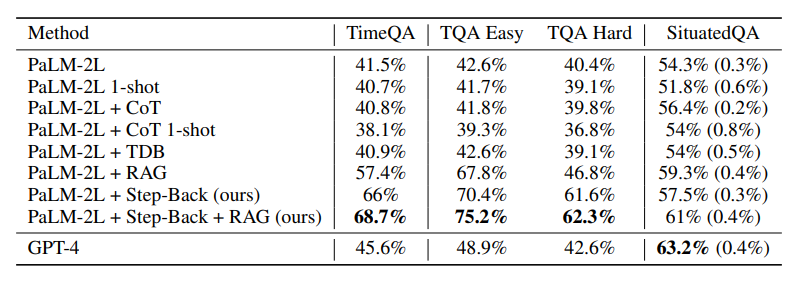
如下图所示,GPT-4和PaLM-2L的基线模型分别达到了45.6%和41.5%,凸显了任务的难度。
在基线模型上应用CoT或TDB零次(和一次),prompt没有任何改进。
相比之下,通过常规检索增强(RAG)对基线模型进行增强后,准确率提高到了57.4%,凸显了任务的事实密集性。
Step-Back + RAG的结果显示了后退推理中,LLM回到高级概念这一步是很有效的,这会让LLM的检索环节更为可靠,我们可以看到,TimeQA的准确率达到了惊人的68.7%。
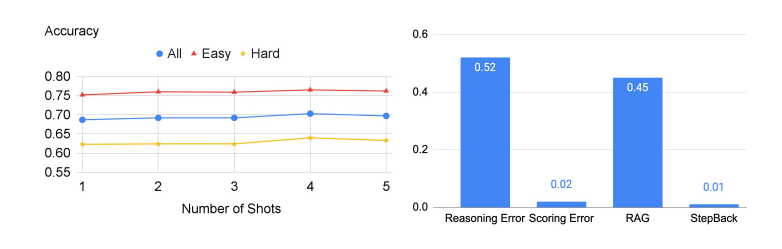
接下来,研究人员又将TimeQA分成了原始数据集中提供的简单和困难两个难度级别。
不出意外的是,LLM在困难这个级别上的表现都较差。虽然RAG可以将简单级的准确率从42.6%提高到67.8%,但对困难级准确率的提高幅度要小得多,数据显示仅从40.4%增加到了46.8%。
而这也正是后退推理的prompt技术的真正优势所在,它能检索到高层次概念的相关事实,为最终推理奠定基础。
后退推理再加RAG,就能进一步将准确率提高到62.3%,超过了GPT-4的42.6%。
当然,在TimeQA类问题上,这项prompt技术还是存在一些问题的。
下图就显示了在这部分实验中LLM的准确性,右侧则是错误发生的概率。
参考资料:
https://arxiv.org/abs/2310.06117
文章来自于微信公众号 “新智元”,作者 “拉燕”


【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
