AI又一突破,解码人类思想,脑损伤患者能实现“无障碍”交流了?
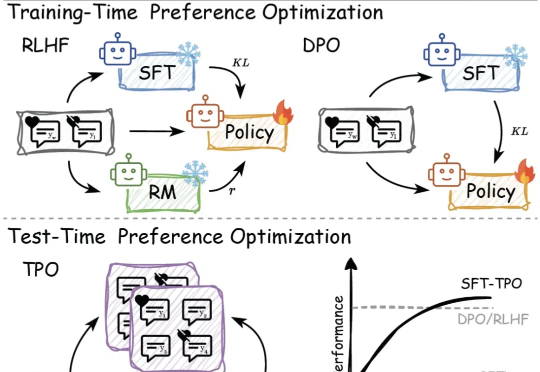
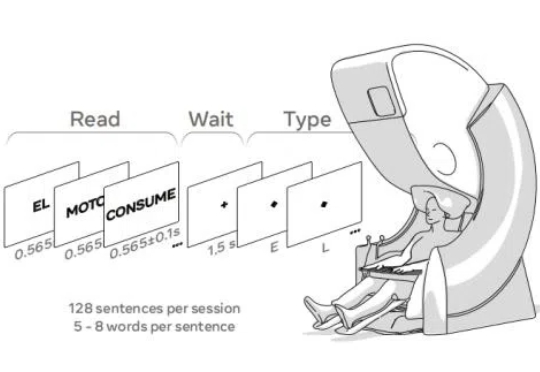
AI又一突破,解码人类思想,脑损伤患者能实现“无障碍”交流了?今天,Meta 公布了两项重磅研究,他们联合认知科学和神经科学顶尖研究机构巴斯克认知、大脑和语言中心(BCBL),采用非侵入式方法利用 AI 解码大脑语言、并进一步理解人类大脑如何形成语言。这两项突破性的研究成果也使得高级机器智能(Advanced Machine Intelligence, AMI)更加接近实现。
来自主题: AI资讯
9477 点击 2025-02-10 18:01