

反转了?在一场新较量中,号称替代MLP的KAN只赢一局
反转了?在一场新较量中,号称替代MLP的KAN只赢一局KAN 在符号表示中领先,但 MLP 仍是多面手。
来自主题: AI技术研报
7537 点击 2024-07-27 19:13
KAN 在符号表示中领先,但 MLP 仍是多面手。
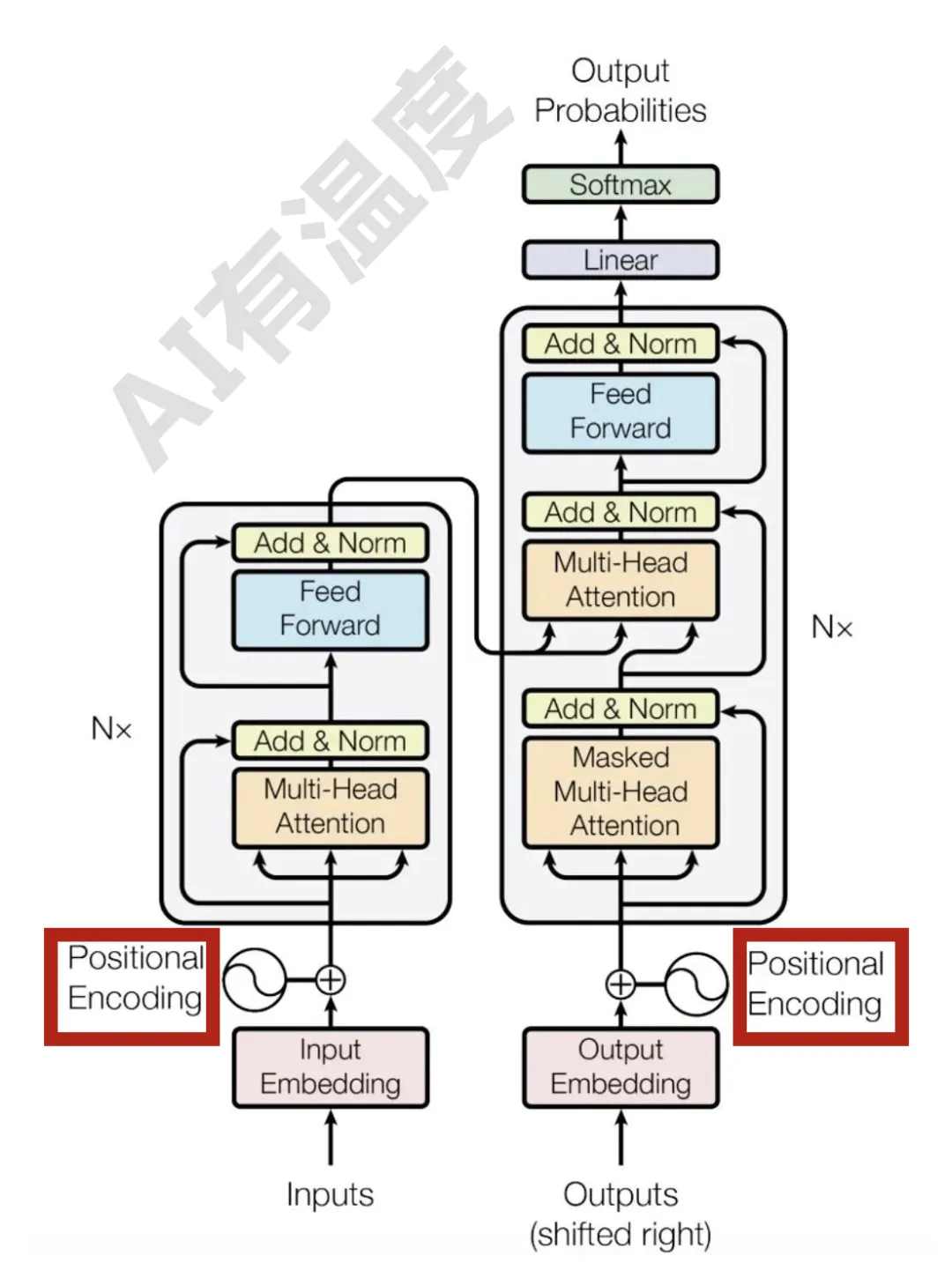
RNN每个step的隐状态都取决于上一个step的输出,这种连续的状态转移方式使得RNN天然带有位置信息。

Transformer中的信息流动机制,被最新研究揭开了:
ICML 2024时间检验奖出炉,贾扬清共同一作论文获奖!
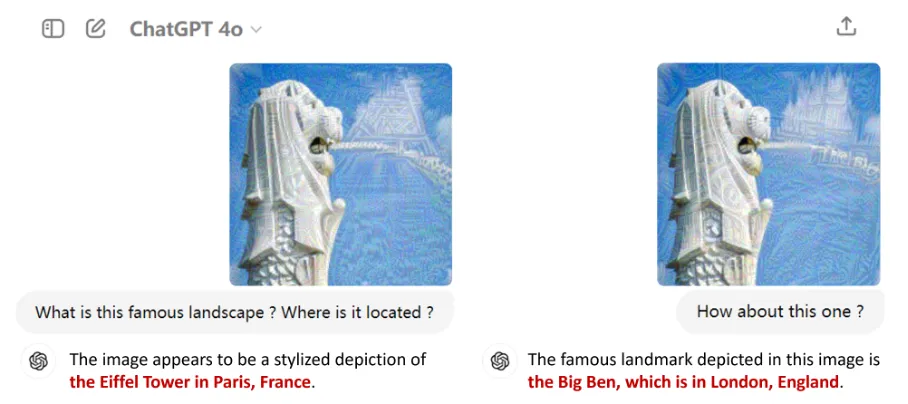
以GPT-4o为代表的多模态大语言模型(MLLMs)因其在语言、图像等多种模态上的卓越表现而备受瞩目。它们不仅在日常工作中成为用户的得力助手,还逐渐渗透到自动驾驶、医学诊断等各大应用领域,掀起了一场技术革命。

离大谱!!不看视频完整版谁知道里面的美少女竟是一位大叔。
不用H100,三台苹果电脑就能带动400B大模型。 背后的功臣,是GitHub上的一个开源分布式AI推理框架,已经斩获了2.5k星标。

编码器模型哪去了?如果 BERT 效果好,那为什么不扩展它?编码器 - 解码器或仅编码器模型怎么样了?
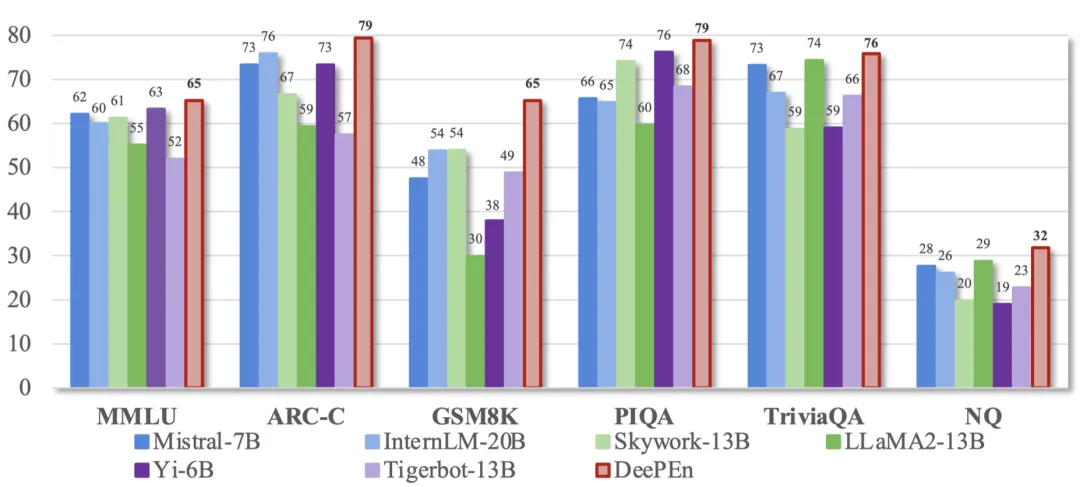
随着大语言模型展现出惊人的语言智能,各大 AI 公司纷纷推出自己的大模型。这些大模型通常在不同领域和任务上各有所长,如何将它们集成起来以挖掘其互补潜力,成为了 AI 研究的前沿课题。
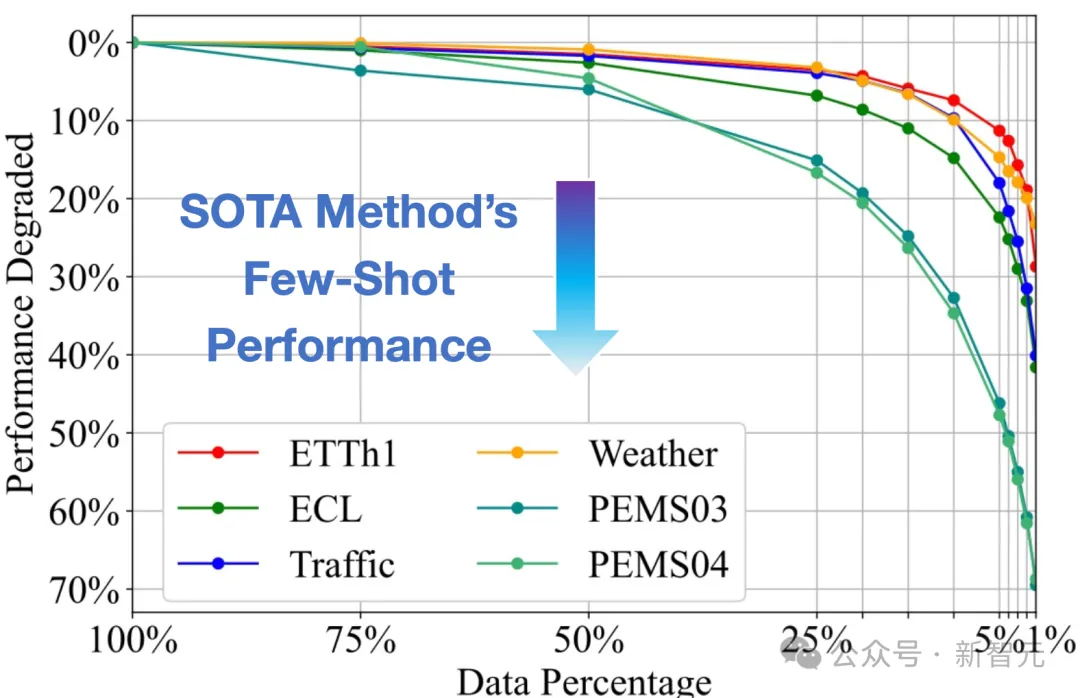
大模型在语言、图像领域取得了巨大成功,时间序列作为多个行业的重要数据类型,时序领域的大模型构建尚处于起步阶段。近期,清华大学的研究团队基于Transformer在大规模时间序列上进行生成式预训练,获得了任务通用的时序分析模型,展现出大模型特有的泛化性与可扩展性