

哈萨比斯:谷歌想创造第二个Transformer,还想把AlphaGo和Gemini强强联合
哈萨比斯:谷歌想创造第二个Transformer,还想把AlphaGo和Gemini强强联合当一家人工智能公司的首席执行官更像是计算机科学家而不是推销员时,我感觉更舒服
来自主题: AI资讯
4483 点击 2024-08-20 14:31
当一家人工智能公司的首席执行官更像是计算机科学家而不是推销员时,我感觉更舒服
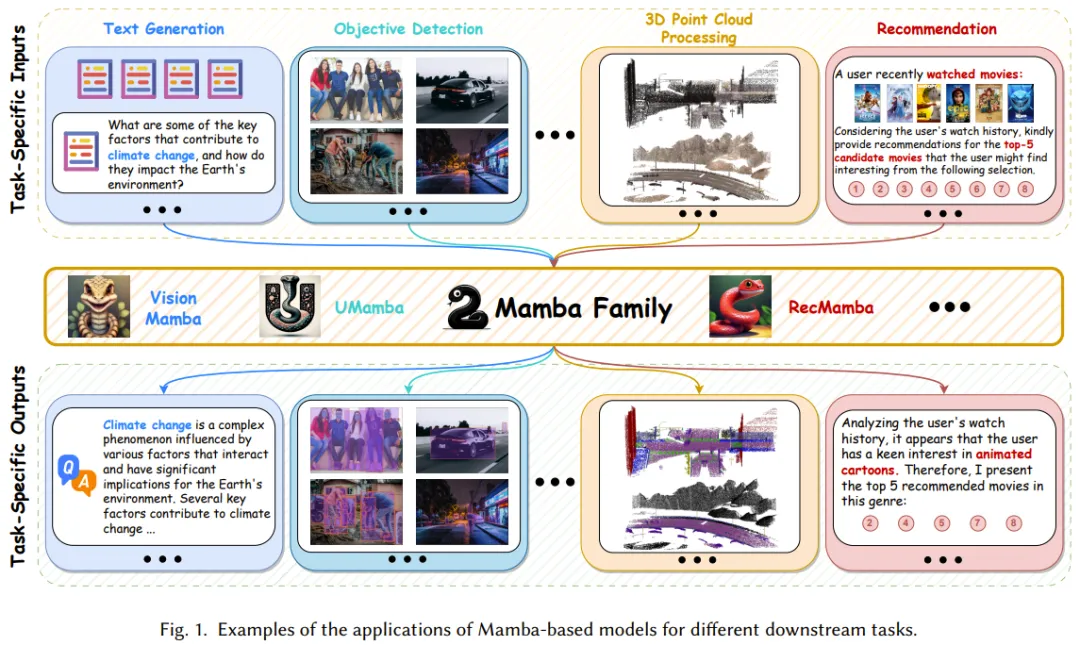
Mamba 虽好,但发展尚早。

Mamba 架构的大模型又一次向 Transformer 发起了挑战

TII开源全球第一个通用的大型Mamba架构模型Falcon Mamba 7B,性能与Transformer架构模型相媲美,在多个基准测试上的均分超过了Llama 3.1 8B和Mistral 7B。
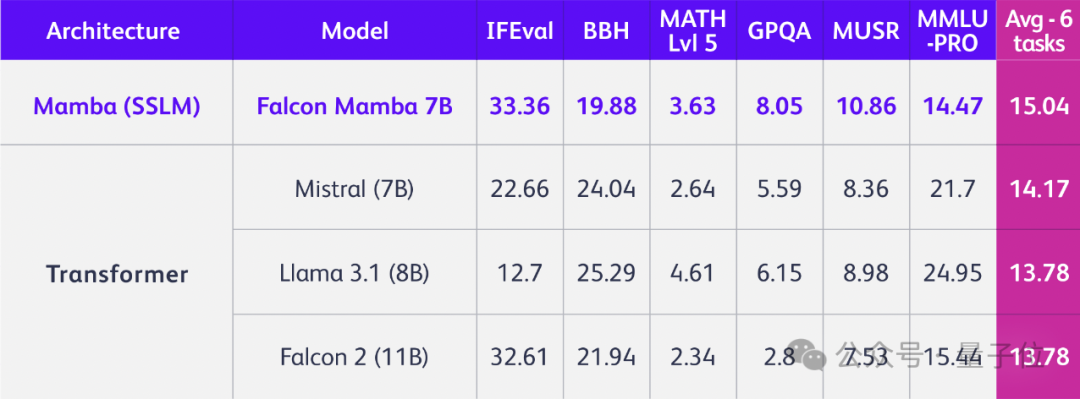
只是换掉Transformer架构,立马性能全方位提升,问鼎同规模开源模型!

2017 年,谷歌在论文《Attention is all you need》中提出了 Transformer,成为了深度学习领域的重大突破。该论文的引用数已经将近 13 万,后来的 GPT 家族所有模型也都是基于 Transformer 架构,可见其影响之广。 作为一种神经网络架构,Transformer 在从文本到视觉的多样任务中广受欢迎,尤其是在当前火热的 AI 聊天机器人领域。

Transformer架构层层堆叠,包含十几亿甚至几十亿个参数,这些层到底是如何工作的?当一个新奇的比喻——「画家流水线」,被用于类比并理解Transformer架构的中间层,情况突然变得明朗起来,并引出了一些有趣的发现。

七年前,论文《Attention is all you need》提出了 transformer 架构,颠覆了整个深度学习领域。

Transformer大模型尺寸变化,正在重走CNN的老路!

近年来,针对单个物体的 Text-to-3D 方法取得了一系列突破性进展,但是从文本生成可控的、高质量的复杂多物体 3D 场景仍然面临巨大挑战。之前的方法在生成场景的复杂度、几何质量、纹理一致性、多物体交互关系、可控性和编辑性等方面均存在较大缺陷。