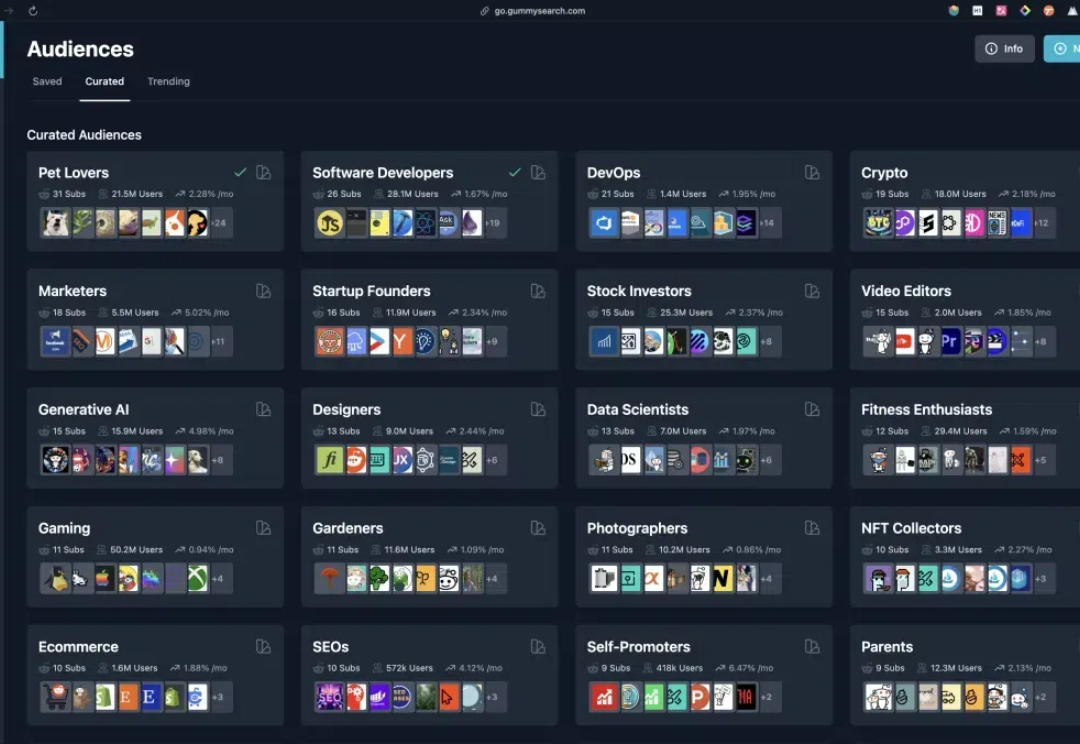
检验创业想法是否靠谱的AI神器!洞察市场机会,定位用户痛点,pmf验证…
检验创业想法是否靠谱的AI神器!洞察市场机会,定位用户痛点,pmf验证…Reddit 作为一个充满活力的全球社区平台,里面有非常丰富的兴趣小组和只有想不到没有找不到的话题,类似国内的百度贴吧、豆瓣,我们不仅可以从中发现灵感、验证想法,还可以找到对应的客户,非常适合验证创业想法。
来自主题: AI资讯
8461 点击 2024-12-30 10:30
 搜索
搜索
Reddit 作为一个充满活力的全球社区平台,里面有非常丰富的兴趣小组和只有想不到没有找不到的话题,类似国内的百度贴吧、豆瓣,我们不仅可以从中发现灵感、验证想法,还可以找到对应的客户,非常适合验证创业想法。
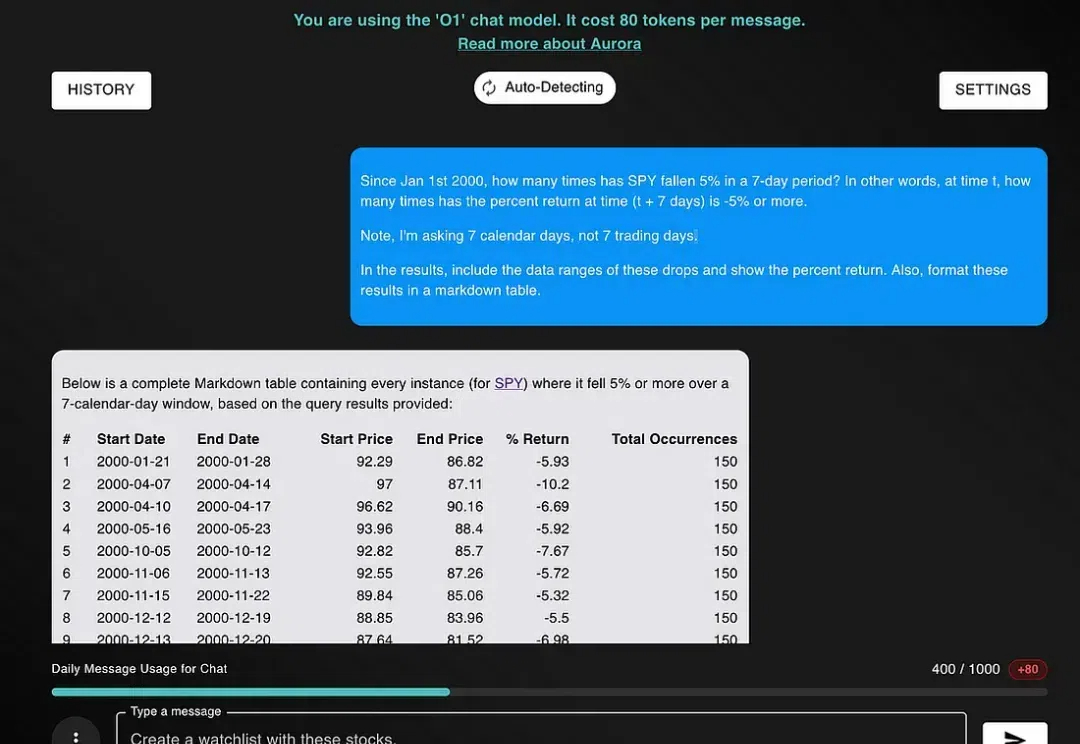
近期NexusTrade的创始人Austin Starks撰文介绍了他使用OpenAI o1模型构建投资组合的一些经验。并展示如何使用OpenAI o1彻底改变金融市场的研究、分析和交易方式。
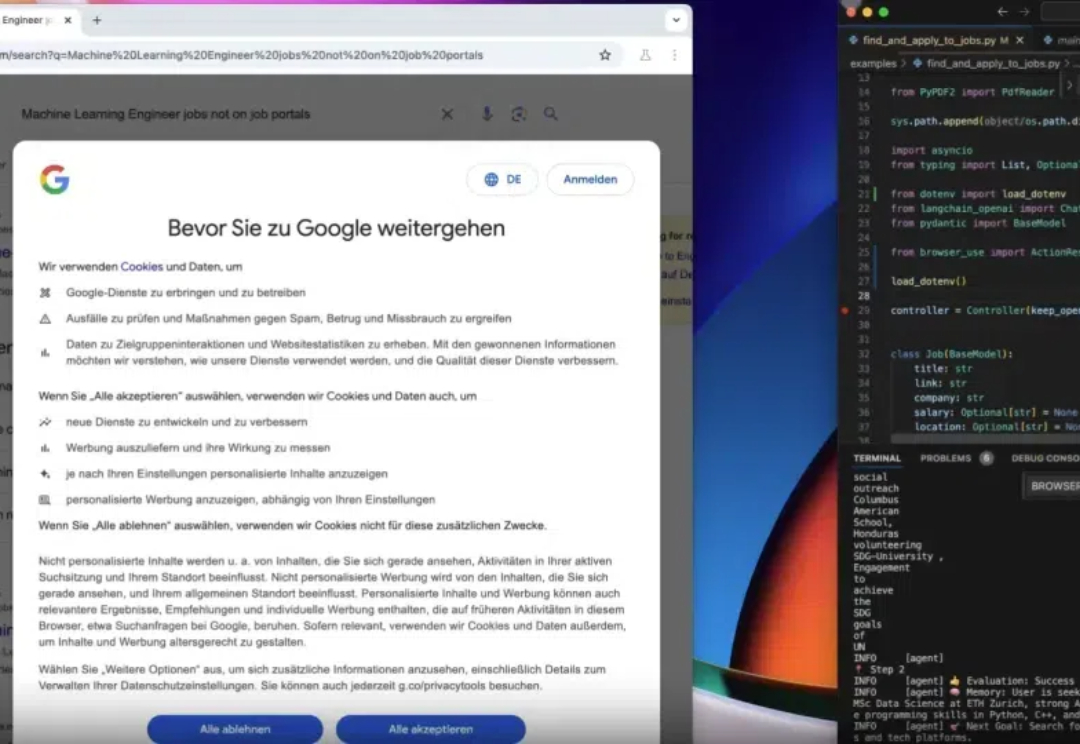
无论是语音助手解放双手,还是AI搜索节省时间,这些技术的普及无不在证明:AI 的价值不再只是科研实验室中的概念,而是实实在在融入了我们的日常生活。 然而,当我发现 Browser Use 这个工具时,还是被它的“开挂”能力给惊艳到了。

Orr Zohar的指导老师Serena Yeung-Levy教授于2018年获得斯坦福大学博士学位,师从李飞飞和Arnold Milstein。2017年至2019年期间,Serena Yeung-Levy曾与Justin Johnson和李飞飞共同教授斯坦福大学卷积神经网络课程。

在大语言模型(LLM)蓬勃发展的今天,提示词工程(Prompt Engineering)已经成为AI应用开发中不可或缺的关键环节。

随着Gemini家族的日趋完善、阵容的发展壮大,谷歌大模型将可代表用户完成更多现实工作。
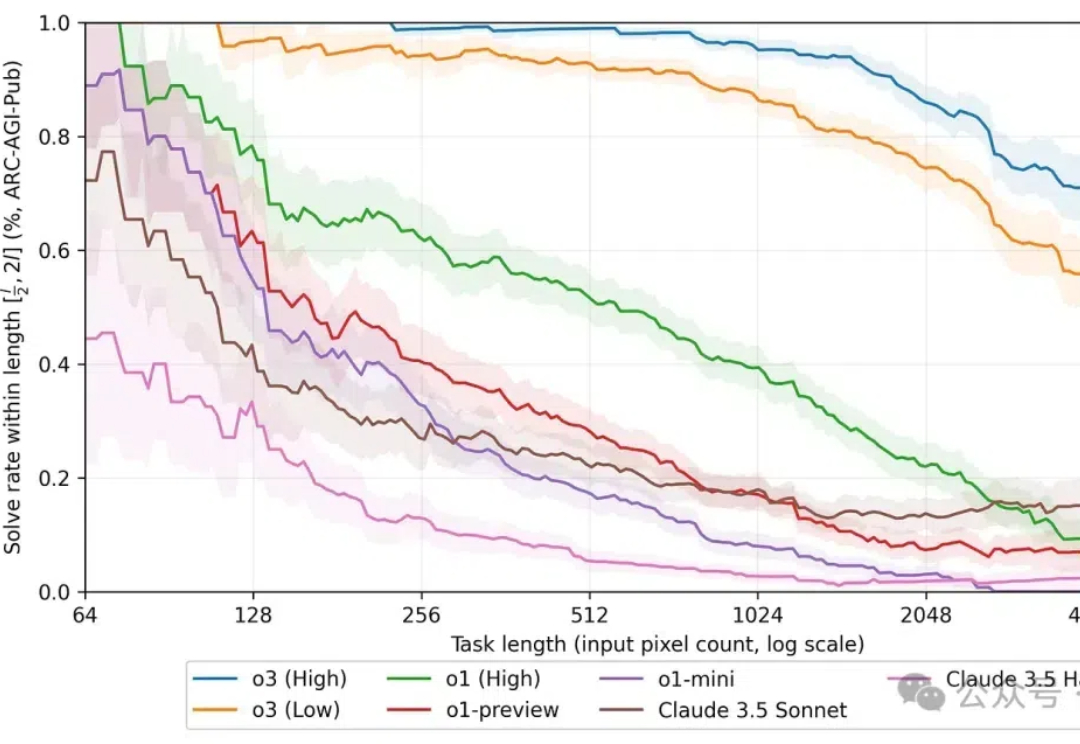
o3在超难推理任务ARC-AGI上的成绩,属实给人类带来了不少震撼。 但有人专门研究了它不会做的题之后,有了更有趣的发现—— o3之所以不会做这些题,原因可能不是因为太难,而是题目的规模太大了。

Mindgard 宣布完成800万美元的融资,旨在加速其研发进程,并推动其在美国市场的扩展。此次融资由.406Ventures 领投,参与投资的还有 Atlantic Bridge、Willowtree Investments 及现有投资者 IQ Capital 和 Lakestar。同时,Mindgard 还任命了两位行业领军人物,分别担任产品负责人和市场副总裁,以强化公司的产品开发和市场推广。

AI语言学习的第一个独角兽来了。
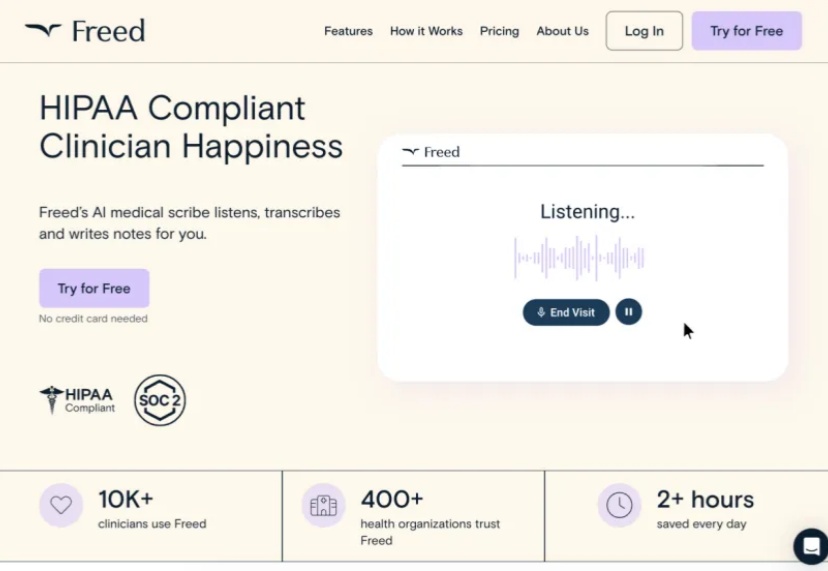
Freed AI 是一款创新的医疗文档智能工具,通过 AI 转录系统记录患者就诊讨论内容,识别关键术语并创建结构化的病历记录,帮助医生将文档工作时间减少 73%。