# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
该文章的第一作者陈麒光,目前就读于哈工大赛尔实验室。他的主要研究方向包括大模型思维链、跨语言大模型等。
在过去的几年中,大型语言模型(Large Language Models, LLMs)在自然语言处理(NLP)领域取得了突破性的进展。这些模型不仅能够理解复杂的语境,还能够生成连贯且逻辑严谨的文本。
然而,随着科技的发展和应用场景的多样化,单一文本模态的能力显然已经不能满足现代需求。人们日益期待能够处理和理解多种模态信息(如图像、视频、音频等)的智能系统,以应对更复杂的任务和场景。研究者们开始尝试将文本 CoT 的能力扩展到多模态思维链推理领域,以应对更加复杂和多样化的任务需求。
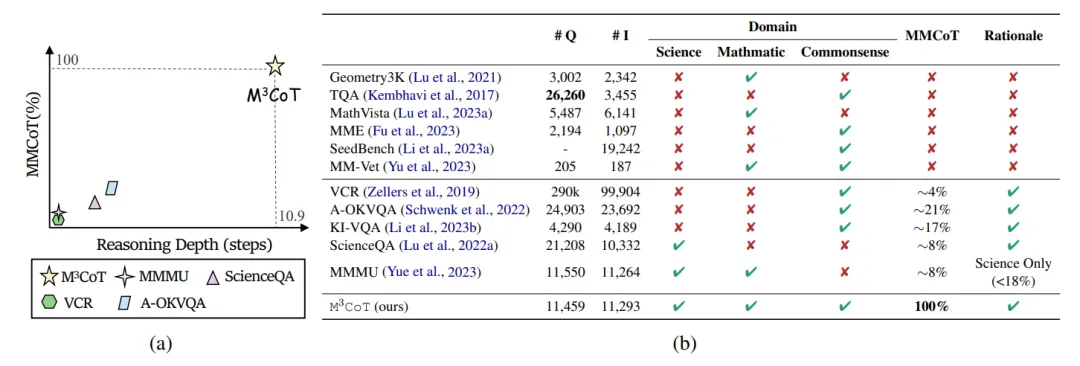
最早的多模态思维链研究之一是由 Lu 等人 [1] 引入的 ScienceQA 基准,该基准结合了视觉和语言信息,推动了多模态思维链(Multi-modal Chain of Thought, MCoT)的研究。ScienceQA 数据集的出现,使得研究者们能够在一个统一的框架下评估多模态模型的思维链推理能力。
进一步地,Zhang 等人 [2] 的研究更是将 MCoT 的性能推向了一个新高,使得模型在 ScienceQA 数据集上的表现超过了人类的水平 (93%>88%)。然而,当前的多模态思维链研究是否真正解决了所有挑战?随着 ScienceQA 等基准测试的成绩不断刷新,我们是否可以认为多模态推理问题已经迎刃而解?
研究者们通过深入分析发现,当前的多模态思维链基准仍然存在严重的问题,导致对模型实际能力的高估。当前的多模态思维链基准仍面临以下三个严重的问题:视觉模态推理缺失、仅有单步视觉模态推理以及领域覆盖不足。
这些问题严重制约了多模态思维链领域的发展。因此,研究者提出了一个新的基准M3CoT(Multi-Domain Multi-step Multi-modal Chain-of-Thought),旨在解决上述问题,并推动多领域、多步和多模态思维链的进步。研究者们还进行了全面的评估,涉及丰富的多模态推理设置与方法。
研究者们还发现当前的多模态大模型在 M3CoT上的表现存在巨大的性能缺陷,尽管它们在以前的传统多模态思维链基准上表现优异。最后,研究团队希望 M3CoT能够成为一个有价值的资源,为多领域、多步和多模态思维链的研究提供开创性的基础。

动机
尽管在 MCoT 研究领域取得了显著进展,但现有基准仍然存在诸多不足:
1. 视觉模态推理缺失:模型往往可以仅基于文本模态生成推理和答案,这并不能真实反映多模态 CoT 模型的能力。
2. 单步视觉模态推理:比如说,只需要看到单次图片中的 “羽毛” 便可直接获得答案。而在实际应用中,多步推理更为常见和必要,要求模型在推理的过程中动态的多次结合多模态信息进行综合推理。
3. 领域缺失:对于思维链来说,常识推理和数学推理是该领域的重要组成部分,而现有基准缺乏对常识和数学等重要领域的覆盖,限制了多模态 CoT 能力的综合评估。
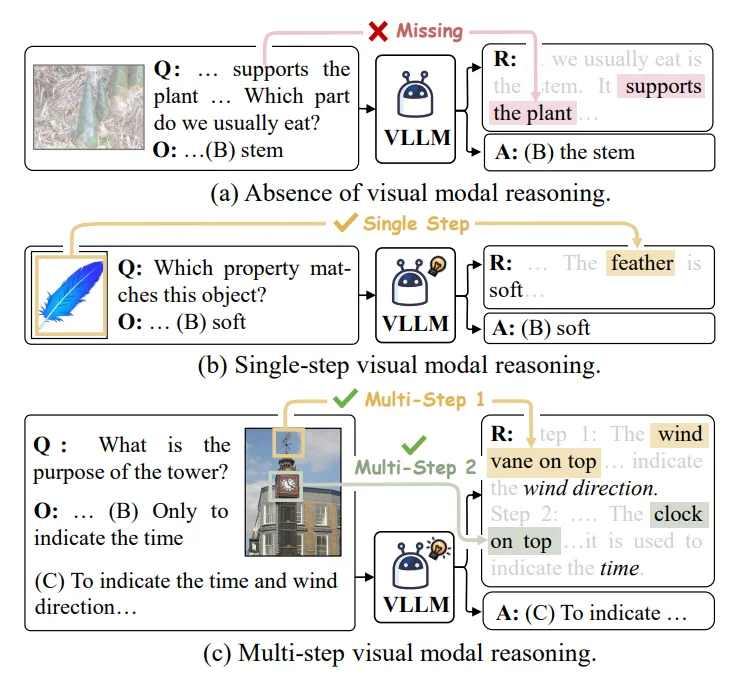
针对以上问题,研究者们开发了一个新基准 ,并希望推动多领域、多步和多模态思维链的研究与发展。
,并希望推动多领域、多步和多模态思维链的研究与发展。
数据构建过程
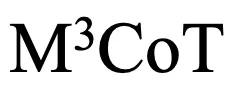 的构建涉及如下四个关键阶段:
的构建涉及如下四个关键阶段:
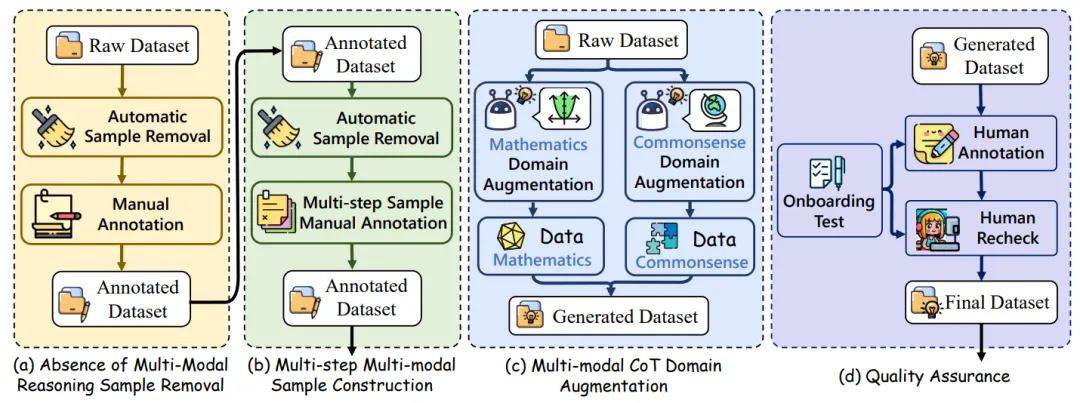
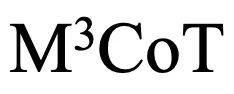 利用自动和手动相结合的方式移除了那些无需图像即可得出答案的样本。
利用自动和手动相结合的方式移除了那些无需图像即可得出答案的样本。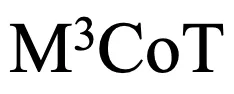 首先自动的去除了推理路径过短的样本,随后通过手动去除和优化样本,确保每一个样本确实需要跨模态的多步推理。
首先自动的去除了推理路径过短的样本,随后通过手动去除和优化样本,确保每一个样本确实需要跨模态的多步推理。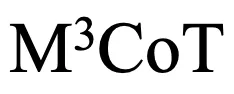 过引入数学和常识领域的数据,将 LaTeX 代码转为图片,并利用大模型生成更多的问题、推理路径和答案,增强了基准的多样性和挑战性。
过引入数学和常识领域的数据,将 LaTeX 代码转为图片,并利用大模型生成更多的问题、推理路径和答案,增强了基准的多样性和挑战性。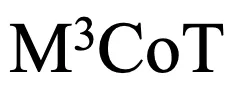 实施了多轮人工审核和自动检测,确保数据的一致性和准确性。
实施了多轮人工审核和自动检测,确保数据的一致性和准确性。主流多模态大语言模型评测结果
研究者们在多个大型视觉语言模型(VLLMs)上进行了广泛的实验,包括 Kosmos-2、InstructBLIP、LLaVA-V1.5、CogVLM、Gemini 和 GPT4V 等。研究者们还探索了一些提示策略,如直接提交样本、思维链提示(CoT)[3] 以及描述性提示(Desp-CoT)[4] 和场景图思维链提示策略(CCoT)[5]。
实验结果与结论如下所示:
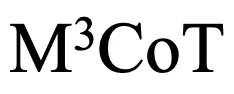 上的表现仍有显著差距。尤其是当前的开源 VLLMs 在多步多模态推理方面表现不佳,与 GPT4V 相比存在显著差距。
上的表现仍有显著差距。尤其是当前的开源 VLLMs 在多步多模态推理方面表现不佳,与 GPT4V 相比存在显著差距。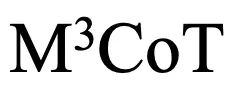 上的表现优于其他 VLLMs,但与人类表现相比仍存在显著差距。这表明,当前的 VLLMs 在处理复杂的多模态推理任务时仍需进一步改进。
上的表现优于其他 VLLMs,但与人类表现相比仍存在显著差距。这表明,当前的 VLLMs 在处理复杂的多模态推理任务时仍需进一步改进。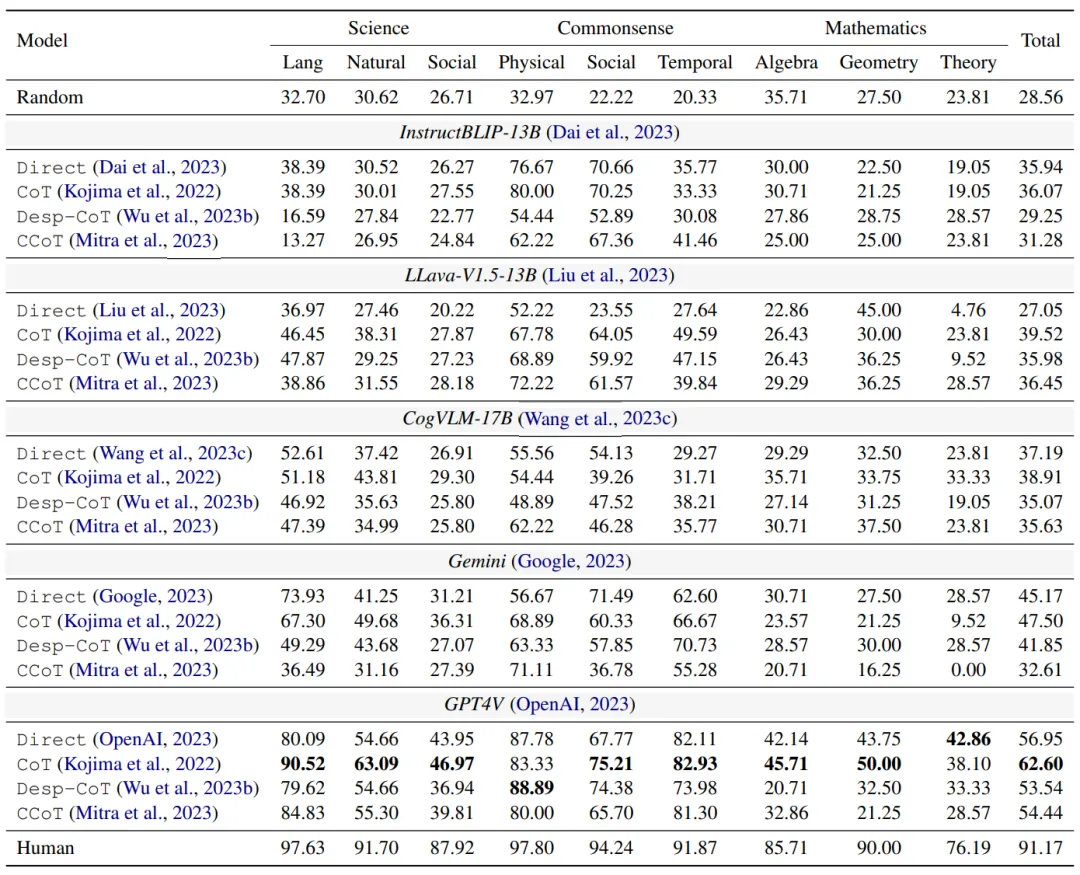
分析
此外,为了回答如何能够在 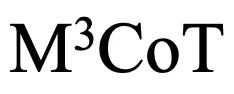 上获得更好的表现。研究者们提供了更全面的分析,从而揭示了当前 VLLMs 在多步多模态推理方面的显著不足,为未来的优化提供了方向。
上获得更好的表现。研究者们提供了更全面的分析,从而揭示了当前 VLLMs 在多步多模态推理方面的显著不足,为未来的优化提供了方向。
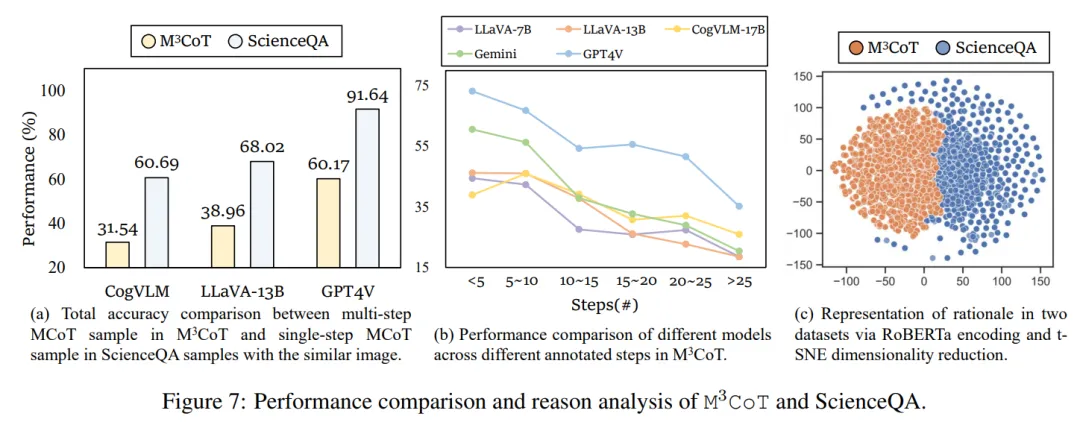
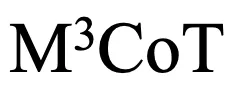 的表现至关重要。通过评估多维度的推理质量,研究者们观察到推理质量的提升与
的表现至关重要。通过评估多维度的推理质量,研究者们观察到推理质量的提升与 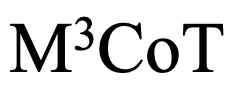 的性能呈现指数级相关关系。提升多模态推理的逻辑质量是解决
的性能呈现指数级相关关系。提升多模态推理的逻辑质量是解决 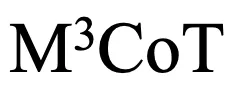 的关键瓶颈之一。
的关键瓶颈之一。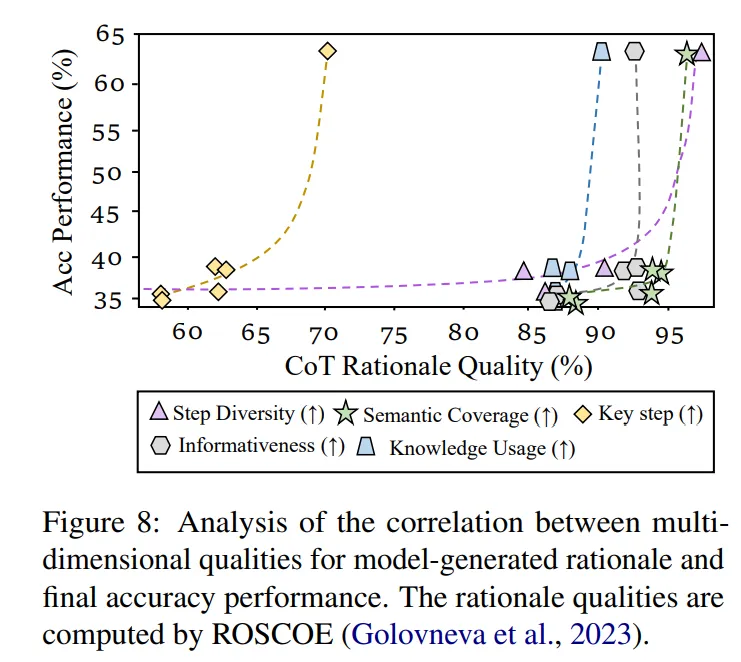
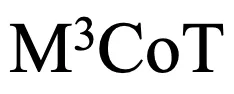 要求推理时动态的包含多个跨模态推理步骤,则至少有 2 步跨模态推理,而现有模型推理过程中,平均的跨模态推理步骤数小于 1。这说明未来的研究应注重提高推理过程的质量和多模态信息的交互,以解决当前模型在
要求推理时动态的包含多个跨模态推理步骤,则至少有 2 步跨模态推理,而现有模型推理过程中,平均的跨模态推理步骤数小于 1。这说明未来的研究应注重提高推理过程的质量和多模态信息的交互,以解决当前模型在 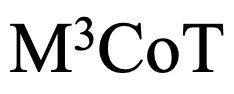 上的表现不足。
上的表现不足。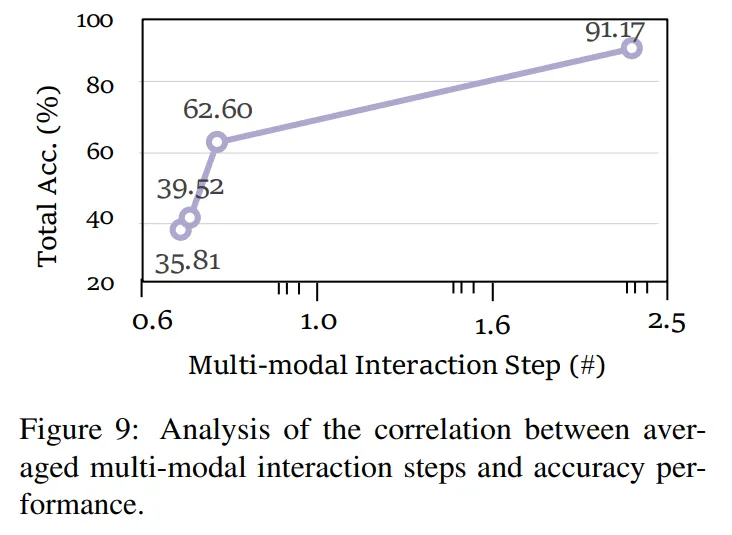
探索
在此基础上,研究者们进一步探究了当前各种常用的多模态方法与设置,探究是否能够有效的解决  中的问题。
中的问题。
工具使用探索
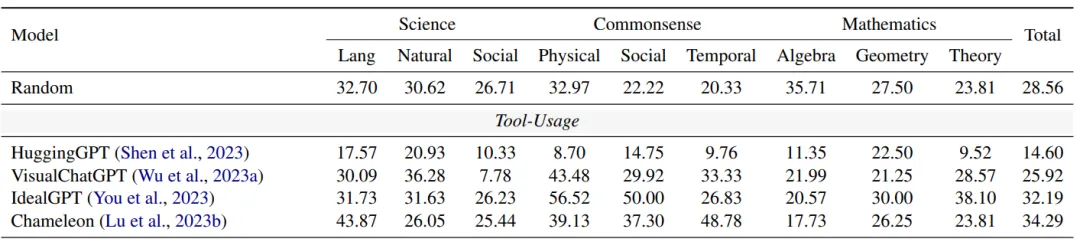
在多模态推理中,工具使用被认为是提高模型性能的一种有效策略。研究者们在实验中评估了多种工具使用方法,包括 HuggingGPT、VisualChatGPT、IdealGPT 和 Chameleon 等模型。
文本大模型使用多模态工具在  上表现不佳:实验结果表明,尽管这些工具在单模态任务中表现良好,但在
上表现不佳:实验结果表明,尽管这些工具在单模态任务中表现良好,但在  基准上的表现仍存在显著差距。例如,HuggingGPT 在处理复杂的多步推理任务时,由于缺乏对视觉信息的有效利用,表现较为逊色。此外,VisualChatGPT 和 IdealGPT 在处理需要多模态交互的任务时,表现也未能达到预期。这些结果表明,当前的工具使用框架需要进一步改进,以更好地整合和利用多模态信息。
基准上的表现仍存在显著差距。例如,HuggingGPT 在处理复杂的多步推理任务时,由于缺乏对视觉信息的有效利用,表现较为逊色。此外,VisualChatGPT 和 IdealGPT 在处理需要多模态交互的任务时,表现也未能达到预期。这些结果表明,当前的工具使用框架需要进一步改进,以更好地整合和利用多模态信息。
上下文学习探索
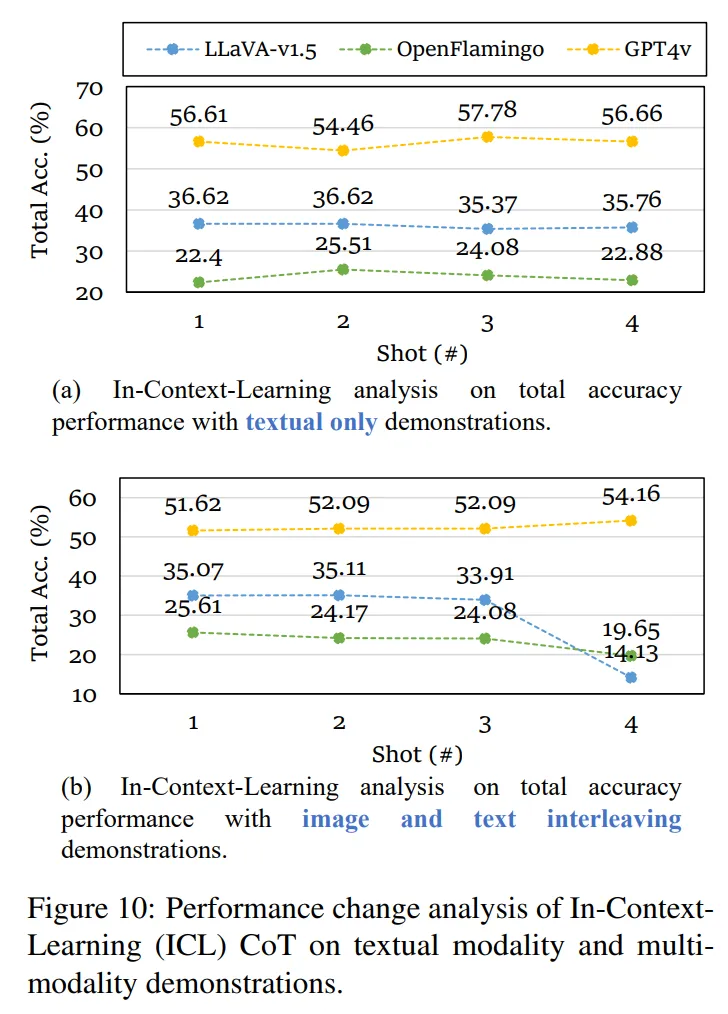
在上下文学习方面,研究者们探索了不同的示例策略对模型性能的影响。具体而言,研究者们评估了纯文本示例以检测模型在多模态推理时是否会进行文本形式的学习,同时还评估了多模态示例以检测模型在多模态推理时是否会利用多模态示例进行上下文学习。
纯文本示例无法提高 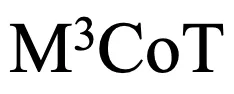 上的性能:实验结果显示,对于纯文本示例来说,这些样本数量对模型性能影响几乎可以忽略不计,这说明,纯粹的文本形式的模仿并不足以解决
上的性能:实验结果显示,对于纯文本示例来说,这些样本数量对模型性能影响几乎可以忽略不计,这说明,纯粹的文本形式的模仿并不足以解决 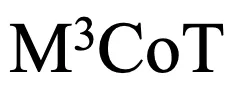 上的性能:对于多模态示例来说,上下文学习仅仅能够提高较大模型的能力。然而,对于一些训练过多模态交互数据的模型来说,甚至会随着样本数量增加而出现性能下降。因此,研究者们认为,未来需要将包含逻辑的更高质量的图像和文本交错示例用于上下文学习的训练,并增强多模态大模型的多模态交互能力,才能够在一定程度上改善模型的表现。
上的性能:对于多模态示例来说,上下文学习仅仅能够提高较大模型的能力。然而,对于一些训练过多模态交互数据的模型来说,甚至会随着样本数量增加而出现性能下降。因此,研究者们认为,未来需要将包含逻辑的更高质量的图像和文本交错示例用于上下文学习的训练,并增强多模态大模型的多模态交互能力,才能够在一定程度上改善模型的表现。
指令微调探索
为了进一步提高模型在 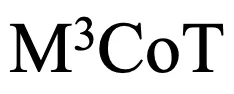 上的表现,研究者们进行了微调实验。
上的表现,研究者们进行了微调实验。
指令微调能够显著增强传统视觉语言模型(VLMs)的性能:指令微调使传统视觉语言模型超越零样本视觉大模型,这就是我们的数据集在提高 VLM 有效性方面的价值。经过微调的 VLM(最低为 44.85%)优于大多数具有零样本提示的开源 VLLM(最高为 38.86%)。
指令微调能够进一步地增强大型视觉语言模型的性能:通过在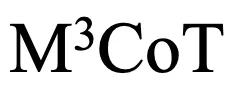 数据集上进行微调,LLaVA-V1.5-13B 模型的整体准确率提高了近 20%,并接近了 GPT4V 的水平。
数据集上进行微调,LLaVA-V1.5-13B 模型的整体准确率提高了近 20%,并接近了 GPT4V 的水平。
因此,研究者们建议未来的研究可以更多地关注指令微调技术,以进一步提升多模态推理模型的表现。

结论及展望
研究者们引入了一个新的基准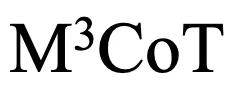 旨在推动多领域、多步和多模态思维链的研究。研究者们的实验和分析表明,尽管现有的 VLLMs 在某些任务上表现优异,但在更复杂的多模态推理任务上仍有很大改进空间。通过提出
旨在推动多领域、多步和多模态思维链的研究。研究者们的实验和分析表明,尽管现有的 VLLMs 在某些任务上表现优异,但在更复杂的多模态推理任务上仍有很大改进空间。通过提出 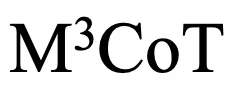 ,研究者们希望能够重新评估现有的进展,并通过指出新的挑战和机会,激发未来的研究。研究者们期待
,研究者们希望能够重新评估现有的进展,并通过指出新的挑战和机会,激发未来的研究。研究者们期待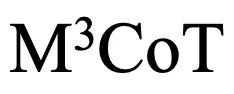 能够成为一个有价值的资源,为多领域、多步和多模态思维链的研究提供开创性的基础。
能够成为一个有价值的资源,为多领域、多步和多模态思维链的研究提供开创性的基础。
文章来源于“机器之心”



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
