moltbook爆火背后:人类操控?伪造截图?Karpathy发风险提醒
moltbook爆火背后:人类操控?伪造截图?Karpathy发风险提醒这个周末,整个科技圈都被 moltbook 刷屏了。 简单来说,这是一个专为 AI 设立的社交平台(类似 Reddit、知乎、贴吧),所有 AI Agent 都可以在上面发帖、交流,而人类只能围观。
来自主题: AI资讯
7239 点击 2026-02-01 13:32
 搜索
搜索
这个周末,整个科技圈都被 moltbook 刷屏了。 简单来说,这是一个专为 AI 设立的社交平台(类似 Reddit、知乎、贴吧),所有 AI Agent 都可以在上面发帖、交流,而人类只能围观。
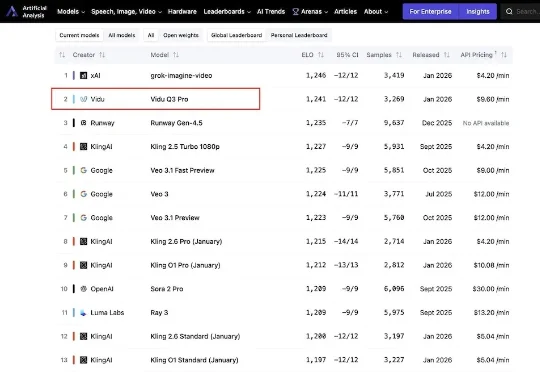
今日,来自生数科技的AI视频模型Vidu Q3 Pro登上国际权威AI基准平台Artificial Analysis榜单,位列中国第一,全球第二。这是最新榜单内,首个打入国际第一梯队的国产视频生成模型。
基于 Kimi K2.5 的能力,Kimi 现在能够提供单个性能的 Kimi Agent 和多个 Agent 协作的 Agent Swarm(多智能体集群),允许多个 AI Agent 并行协作处理复杂任务的架构。

周伯文还详细介绍了上海 AI 实验室近年来开展的前沿探索与实践,包括驱动 “通专融合” 发展的技术架构 ——“智者”SAGE(Synergistic Architecture for Generalizable Experts),其包含基础、融合与进化三个层次,并可双向循环实现全栈进化;支撑 AGI4S 探索的两大基础设施“书生”科学多模态大模型 Intern-S1、“

行业内许多人认为AI 模型市场的赢家早已确定:大型科技公司将主导市场(谷歌、Meta、微软,以及部分亚马逊业务)并联合其选择的模型开发商,主要是 OpenAI 和 Anthropic。

大模型的能力正在被不同的范式逐步解锁:In-Context Learning 展示了模型无需微调即可泛化到新任务;Chain-of-Thought 通过引导模型分步推理来提升复杂问题的求解能力;近期,智能体框架则赋予模型调用工具、多轮交互的能力。

AI 需要整个互联网来学习,而人类只需要一个童年。人类在成年之前,所接触的语言、文本与符号,顶多只有几十亿 token,相差几个数量级。正是从这个问题出发,一家几乎没有产品、没有盈利、也不急于商业化的 AI 创业公司,从 GV、Sequoia 和 Index 拿到了 1.8 亿美元融资,并获得了 Andrej Karpathy 的公开力挺。
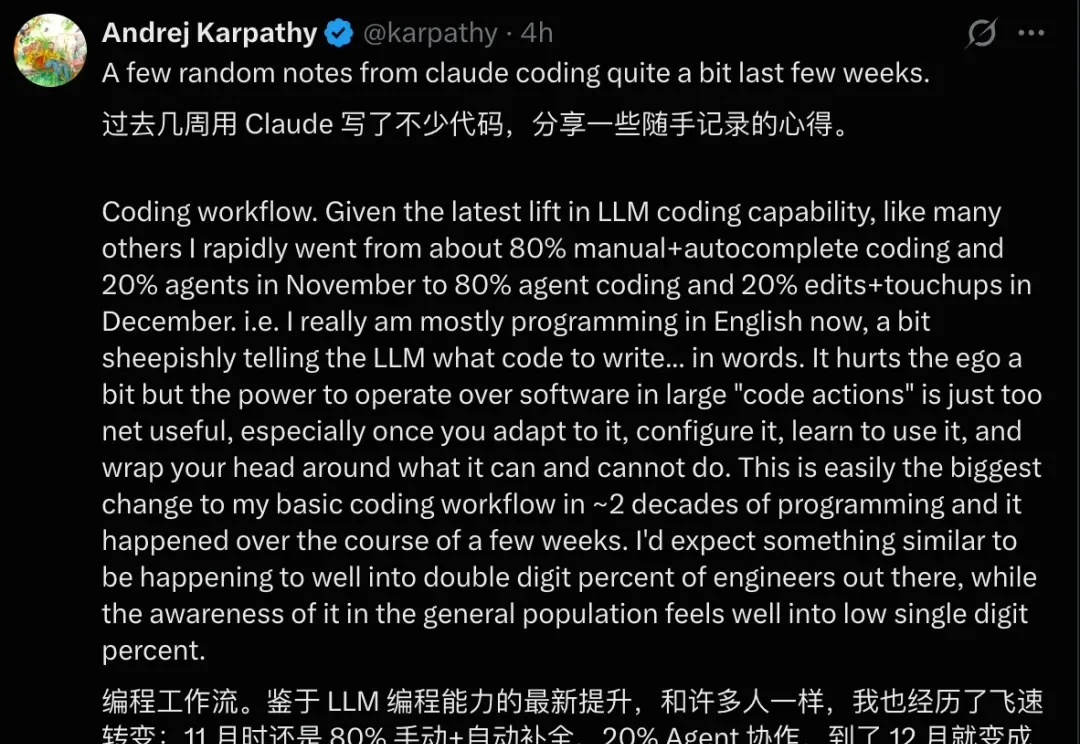
最近,OpenAI 创始成员 Andrej Karpathy 在推特上分享了他使用 Claude 进行数周高强度编程后的感受。

大模型的出现,给许多行业带来了颠覆性的改变,运维这个向来被视为稳定、保守的领域也不例外。虽然“AIOps”这个概念早在 2016 年由 Gartner 提出,但早期的智能运维更多是利用大数据和机器学习对传统运维流程进行效率上的提升。
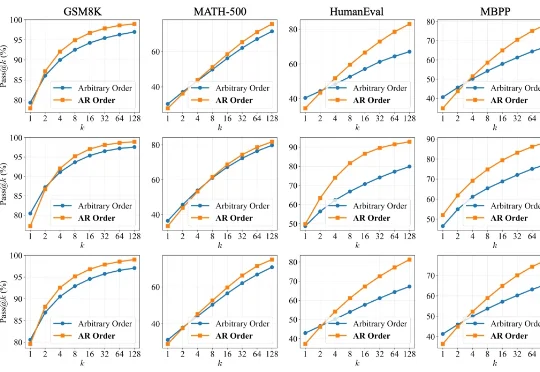
扩散语言模型(Diffusion LLMs, dLLMs)因支持「任意顺序生成」和并行解码而备受瞩目。直觉上,打破传统自回归(AR)「从左到右」的束缚,理应赋予模型更广阔的解空间,从而在数学、代码等复杂任务上解锁更强的推理潜力。