DojoAgents 一周多狂揽1000+Star!金融Agent开始进入真实工作流
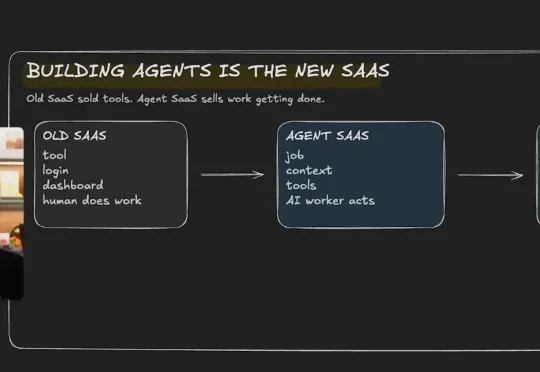
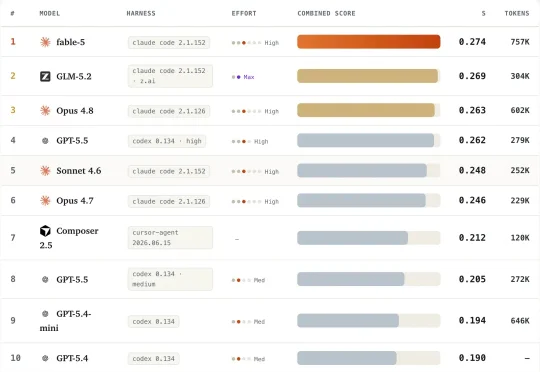
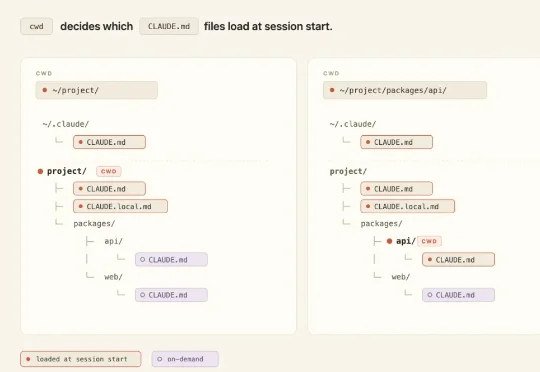
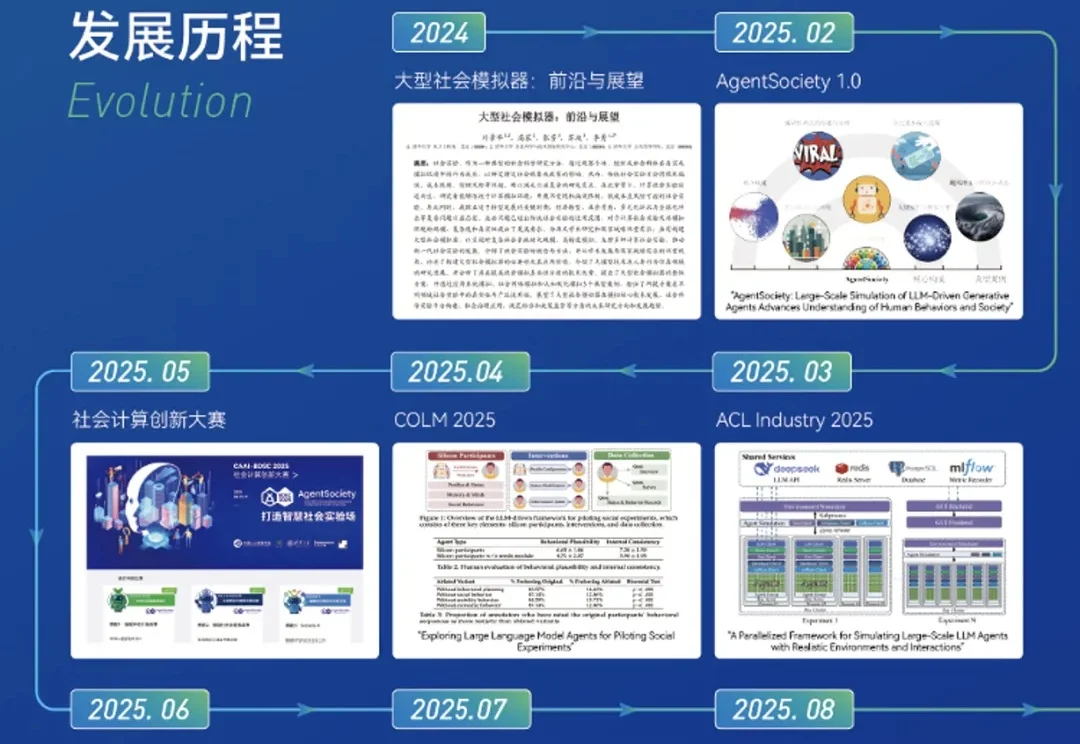
DojoAgents 一周多狂揽1000+Star!金融Agent开始进入真实工作流开源一周多,DojoAgents 已经在 GitHub 获得超过 1000 个 Star。DojoAgents 项目受到关注,是因为其并不只是一个能回答投资问题的 Agent,而是一种新的金融决策辅助方式:让 AI 不再停留在生成答案,而是形成对金融世界持续更新的理解,并在数据、工具、权限和风险边界内,长期且持续主动地推进研究与决策辅助任务。
来自主题: AI资讯
9252 点击 2026-07-23 21:20